
基于Hadoop技术的广电大数据平台构建
2017-04-10 03:48卢建丽杨
数字传媒研究 2017年2期
卢建丽杨 轩
1.2.内蒙古新闻出版广电局841台 内蒙古 呼和浩特市 010050
基于Hadoop技术的广电大数据平台构建
卢建丽1杨 轩2
1.2.内蒙古新闻出版广电局841台 内蒙古 呼和浩特市 010050
随着互联网时代传播载体和传播内容的快速增长,特别是网络电视和视频网站的快速发展,广播电视体系受到了强烈的冲击。在大数据时代背景下,如何利用大数据为用户提供更加优质的服务,成为摆在广电人面前的一个新课题。本文就如何基于Hadoop技术构建广电大数据平台,通过挖掘海量数据,为用户提供个性化服务,增强广电行业的核心竞争力,提出建议。
Hadoop技术 大数据 广电网络
引言
随着大数据时代的来临,网络电视和视频网站蓬勃发展,受此冲击广电媒体的受众、开机率和广告份额均出现下滑。广电媒体受限于传统媒体播送形式,“不知道用户在哪里,也不知道用户的需求是什么”。为提高在大数据时代的竞争力,广电媒体加快了大数据技术应用的脚步,开始积累海量用户数据,以提供更加人性化、更加优质的服务。
本文将探讨如何基于Hadoop技术构建广电大数据分析平台,逻辑上包含:数据采集模块、数据存储模块、数据分析模块、数据应用模块四个主要部分,利用数据挖掘算法,为广电用户提供更优质的服务,提升广电媒体的市场竞争力。
1 广电大数据分析平台架构
广电用户每天产生大量的数据,例如,观看节目时间、广告时段、调台频率等,针对这些海量数据,我们选择全部采集记录,全量数据分析,这符合大数据特点。数据采集后进入由Hadoop技术架构支撑的存储模块,对采集到的数据进行预处理,并存储在HBase数据库。HBase是一个在HDFS上开发的面向列的分布式数据库。分析模块将对存储的数据进行数据挖掘,借助诸如聚类分析、分类器等算法,对海量数据中有价值的数据进行挖掘分析。应用模块是顶层模块,提供诸如视频推荐、广告精准投放、节目动态调整等高端应用。如图1所示:

图1 广电大数据分析平台架构
2 广电大数据分析平台的实现
2.1 Hadoop部署
Hadoop技术提供了可靠的共享存储和分析系统,其核心是HDFS和MapReduce。HDFS实现数据的存储,MapReduce实现数据的分析和处理。
HDFS即Hadoop Distributed File System,是一个分布式文件系统,特点为:(1)适用于对几百TB甚至PB级数据的存储,(2)采用流式数据访问模式,即一次写入,多次读取,是最高效的访问模式,(3)不需要在专用服务器上运行,可以在普通服务器上运行。
MapReduce是一个软件架构,用于大规模数据集的并行运算。一个大数据若可分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度的最好办法就是并行计算。“Map(映射)”和“Reduce(规约)”借鉴函数式编程语言,指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(规约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。Map函数对所划分的数据并行处理,从不同的输入数据产生不同的中间结果输出。同样,Reduce各自并行计算,各自负责处理不同的中间结果数据集合进行reduce处理之前,必须等到所有的map函数做完。因此,在进入reduce前需要有一个同步障(barrier),这个阶段也负责对map的中间结果数据进行收集整理(aggregation&shuffle)处理,以便reduce更有效地计算最终结果。最终汇总所有reduce的输出结果,即可获得最终结果。
目前,Hadoop仅支持Linux作为产品平台,Windows仅限于作为开发平台,但需要借助其他软件。本文以Linux平台为例,介绍Hadoop及相关软件的安装部署。Hadoop以Java语言编写,因此,部署Hadoop需要先安装Java 6或更新版本。
2.2 Hadoop安装
从http://hadoop.apache.org/releases.html页面可以下载Hadoop发布包。
本文下载文件为:hadoop-2.7.2.tar.gz,% tar xcf hadoop-2.7.2.tar.gz
将Hadoop的安装目录添加到环境变量中,本文中Hadoop解压到/usr/software下,将环境变量添加到/etc/profile文件中。保存后,在命令行输入source profile以执行操作:
% exportHADOOP_INSTALL=/usr/software/ hadoop-2.7.2
%export PATH=$PATH:$HADOOP_INSTALL/ bin:$HADOOP_INSTALL/sbin
%source./profile
可通过输入以下指令来判断Hadoop是否工作:
%hadoop version
Hadoop 2.7.2
Subversion https://git-wip-us.apache.org/repos/asf/ hadoop.git-r b165c4fec792ce23f546c64604acf0e41
Compiled by jenkins on 2016-01-26T00:08Z
2.3 Hadoop配置
Hadoop各个组件均可利用XML文件进行配置。在hadoop-2.7.2/conf目录下,有core.site.xml文件用于配置通用属性,hdfs-site.xml文件用于配置HDFS属性,mapred-site.xml文件用于配置MapReduce属性。
Hadoop有三种运行模式:(1)独立模式:无需运行任何守护进程,所有程序都在同一个JVM上执行。在独立模式下测试和调试MapReduce程序很方便,因此该模式适合于开发阶段;(2)伪分布模式:Hadoop守护进程运行在本地机器上,模拟一个小规模的集群。(3)全分布模式:Hadoop守护进程运行在一个集群上。不同模式下的关键配置属性,如表1所示。
(1)配置SSH
本文采用伪分布模式。在伪分布模式下工作必须启动守护进程,而启动守护进程的前提是已经成功安装SSH。同时,需要确保用户能够远程登录到本机,并且可以不输入密码登录。在命令行中输入:
%sudo apt-get install ssh——安装ssh
之后,需要基于空口令创建一个SSH秘钥,以实现无密码登录。
%ssh-keygen-t rsa——创建一个以rsa算法加密的秘钥。
输入命令后,系统会连续提问,全部选择默认值,就可以创建空口令的SSH秘钥。
之后,输入%cat~./ssh/id_rsa.pub>>~/.ssh/ authorized_keys——将id_rsa.pub文件内容添加到authorized_keys文件末尾,且不删除文件中的原有信息,用以下命令测试:
%ssh localhost
Welcome to Ubuntu 14.04.4 LTS(GNU/Linux 3.16.0-71-generic x86_64)
Last login:web Jun 22 16:00:18 2016 from localhost
表示SSH安装配置成功
(2)格式化HDFS文件系统
在使用Hadoop前必须格式化生成一个全新的HDFS系统。该过程创建一个空文件系统,仅包含存储目录和namenode的初始版本。由于namenode管理文件系统的元数据,并且datanode可以动态地加入或离开集群。因此,这个格式化过程不针对datanode。
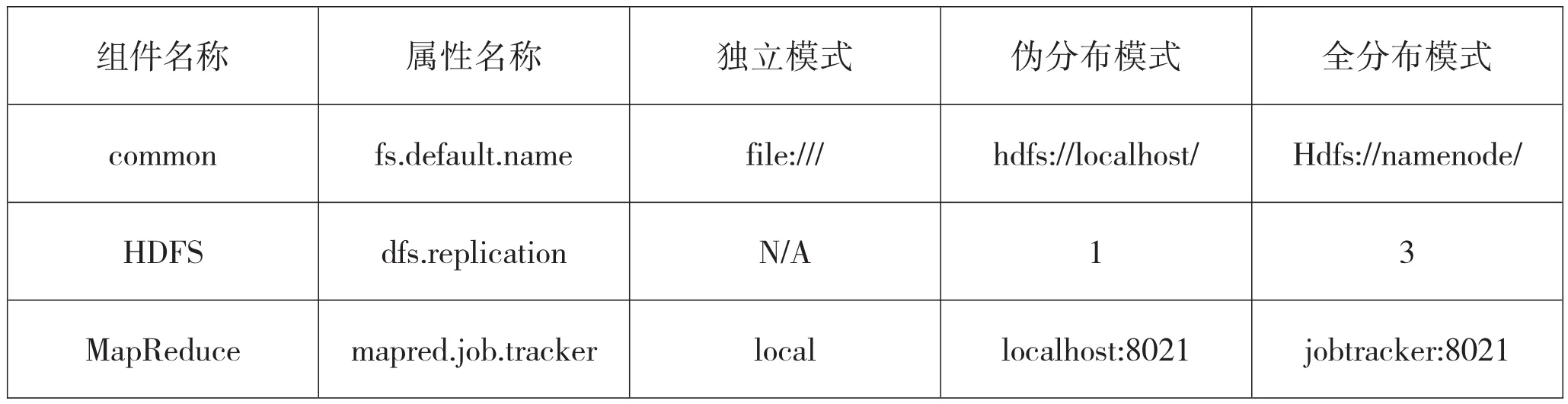
表1 不同模式下的关键配置属性
在命令行中输入:
%hadoop namenode-format
(3)启动守护进程
为启动HDFS和MapReduce守护进程,输入如下命令:
%start-dfs.sh
%start-mapred.sh
本地计算机将启动以下守护进程:一个namenode,一个辅助namenode,一个datanode,一个jobtracker和一个tasktracker。可以通过Web界面查看:在 http://localhost:50030/查看 jobtracker或在http://localhost:50070/查看namenode。
以上Hadoop部署完毕。Hbase分布式数据库和Zookeeper分布式协调服务的安装与Hadoop安装类似,这里不再赘述。安装完Hbase和Zookeeper,就完成了广电大数据分析平台的框架搭建工作。接下来将在这个框架基础上进行数据分析。
3 广电大数据的分析挖掘
大数据的核心在于对拥有的数据进行数据挖掘。数据挖掘是指从大量数据中挖掘模式和获取知识的过程。数据挖掘的一般流程包括:数据准备、信息挖掘、结果表达三个处理阶段。数据准备是指从相关的数据源中选取所需的数据样本,将其整合成用于数据分析的样本集。信息挖掘是指利用各种数据挖掘算法,将所得的样本集中包含的规律信息或潜在模式挖掘出来。结果表达是指尽可能以用户可理解的方式,将找出的规律或模式表示出来。
虽然在逻辑上将广电大数据分析平台分为数据分析和数据应用,但在实际应用中,数据分析与数据应用往往是相互联系的,本文以视频推荐系统为例,详细介绍如何使用算法对Hadoop中的大数据进行分析。视频推荐系统根据用户的历史行为数据和视频的内容特征数据进行挖掘和分析,构建出用户画像和视频的物品画像,同时,利用各种上下文信息,做出对用户未来选择行为的预测,完成对特定用户的推荐。如果你喜欢一件东西X,而另一个东西Y与之十分相似,就很可能喜欢Y,这就是基于物品的协同过滤算法思想。本文重点阐述基于物品的协同过滤算法ItemCF。
3.1 基于物品的协同过滤算法ItemCF
基于物品的协同过滤,是指通过用户对不同物品的评分来评测物品之间的相似性,并基于物品之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。如表2所示:
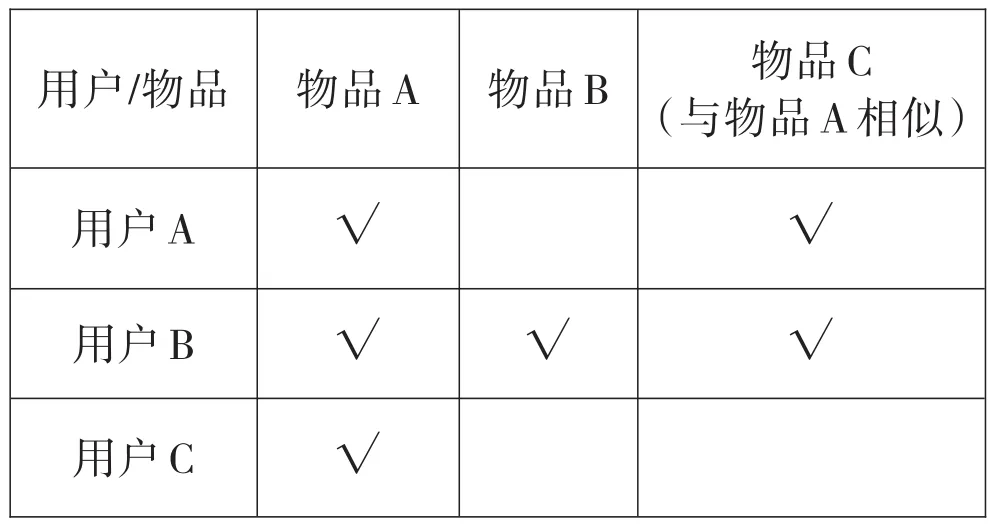
表2 基于物品的协同过滤算法
基于物品的视频推荐算法流程,如图2所示:
假设用户为Ui(i=1,2,3,...,n),视频 Mj(j=1,2,3,...,m),Ui对Mj的评分为。以物品Ij为例,基于物品的协同过滤算法可分为两步:
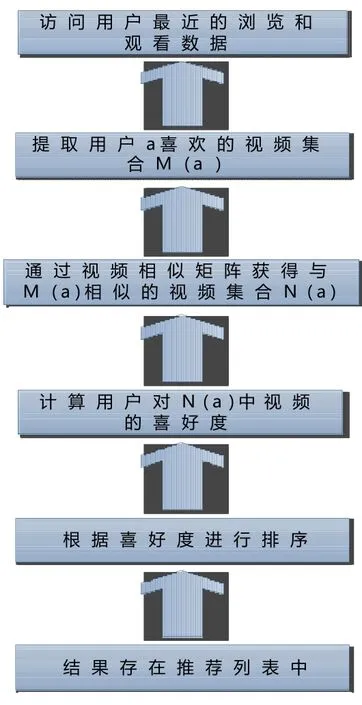
图2 基于物品的视频推荐算法流程
(1)对于目标用户及其待评分的视频,根据用户对视频的历史偏好数据,计算视频与其他已评分视频之间的相似度Sim(j,i),找到与视频相似度高的视频集合N(u)。
(2)根据所有视频N(u)的评分情况,选出N(u)中目标用户Ui可能喜欢的且没有看过的项目进行推荐,并预测评分。
视频间的相似度一般采用修正后的余弦度计算公式Sim(j,i)

公式中,表示用户u对视频i的评分,表示用户u对他所看过的视频的平均打分。
用户对视频的喜好程度用以下公式表示:
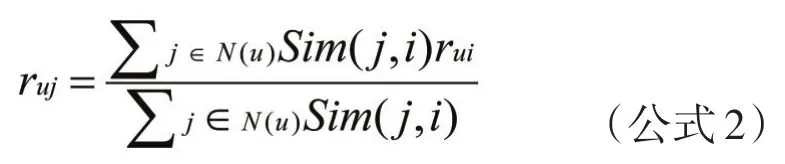
公式中,表示用户u对视频j的喜好程度,视频i是用户看得较多的视频,表示用户u对视频i的偏好程度,之后根据来对候选的视频进行排序,为用户推荐分值高的视频。
3.2 Mahout的安装配置
Mahout开源项目,是一个分布式机器学习算法的集合,它基于Hadoop实现,把很多运行于单机上的算法,转化为MapReduce模式,大大提升了算法可处理的数据量和处理性能。
3.2.1 下载Mahout
http://archive.apache.org/dist/mahout/
3.2.2 解压
tar-zxvf apache-mahout-distribution-0.12.2.tar. gz
3.2.3 配置环境变量
配置Mahout环境变量
#set mahout environment export
MAHOUT_HOME=/usr/software/mahout/mahoutdistribution-0.12.2
export MAHOUT_CONF_DIR=$MAHOUT_ HOME/conf
export PATH=$MAHOUT_HOME/conf:$MA HOUT_HOME/bin:$PATH
执行命令mahout。若列出一些算法,则表示安装成功。
我们可以利用开源的mahout实现基于物品的视频推荐算法。这里仅举例视频推荐系统,还可以根据实际业务需要来扩展广电大数据平台的分析和应用模块,做到服务于实际工作。
结束语
本文探讨了广电大数据分析平台的总体建设思想,介绍了如何搭建Hadoop数据平台。随着大数据Hadoop的不断完善和广电在互联网业务上的持续发力,基于Hadoop的大数据分析应用平台必将发挥越来越重要的作用。
[1]Tom Wbite.Hadoop权威指南[M].北京:清华大学出版社,2015:3-4
[2]Jiawei Han Michelime Kamber Jian Pei.数据挖掘概念与技术[M].北京:机械工业出版社,2012:6.
[3]牛温佳,刘吉强,石川.用户网络行为画像——大数据中的用户网络行为画像分析与内容推荐应用[M].北京:电子工业出版社,2016:8
审稿人:魏朝辉 内蒙古新闻出版广电局监管中心正高级工程师
责任编辑:王学敏
TP312
B
2096-0751(2017)02-0016-05
卢建丽 内蒙古新闻出版广电局841台 工程师
杨 轩 内蒙古新闻出版广电局841台 助理工程师
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
大众投资指南(2021年35期)2021-02-16
疯狂英语·初中天地(2021年11期)2021-02-16
河北画报(2020年10期)2020-11-26
少年漫画(艺术创想)(2019年2期)2019-06-06
电力与能源(2017年6期)2017-05-14
新闻传播(2016年21期)2016-07-10
西部广播电视(2015年3期)2016-01-15
信息通信技术(2015年6期)2015-12-26
小天使·一年级语数英综合(2015年8期)2015-07-06
