
本体对齐技术概述及其在中医领域的应用探讨*
2017-04-10 13:06郝伟学周雪忠
世界科学技术-中医药现代化 2017年1期
郝伟学,于 剑,周雪忠
(北京交通大学计算机与信息技术学院/交通数据分析与挖掘北京市重点实验室 北京 100044)
本体对齐技术概述及其在中医领域的应用探讨*
郝伟学,于 剑,周雪忠**
(北京交通大学计算机与信息技术学院/交通数据分析与挖掘北京市重点实验室 北京 100044)
本体对齐技术是实现不同来源本体概念和关系整合的知识工程方法,鉴于相同范围的本体(如疾病本体)往往由多个不同领域或机构的研究人员各自独立研发,其术语表述和概念关系都存在较大差异。因此,如何通过对齐处理以实现多源本体的整合成为重要的方法学问题。本文就本体对齐的概念、技术、方法及其相应的工具进行了详细阐述。重点阐述了基于语言学特征的和基于结构特征的本体对齐技术。结合国际上两个实际疾病本体:Disease Ontology和Orphanet,采用本体对齐技术进行了实验及分析,并详述对齐技术的应用问题。针对中医领域本体库研发中也存在的多源性问题,进一步探讨本体对齐应用的必要性和应用前景。
本体对齐 本体预处理 相似性计算 疾病本体 中医本体对齐应用
大数据时代的到来,人们对于智能搜索的相关研究不断深入,语义网正是这其中的一个重要分支,而本体正是语义网的核心。为此出现了很多语义丰富、实用的本体库,如WordNet、DBpedia[1]。众所周知,医学和大数据紧密相连,在本体领域也有一定建树,如生物医学本体[2]、Gene Ontology[3]、MeSH、OMIM、HPO等的出现。在医学领域,中医药在中国古老的大地上已经应用了数千年,这几千年来的临床实践证实了中医药无论是在治病、防病方面,还是在养生领域,都确实有效、可行。历代老中医也将毕生积累沉淀的经验及实际数据构成了自己的本体,国家知识基础设施(National Knowledge Infrastructure,NKI)课题将中医本体分为诊断方法、术语、证、治则治法、脉象、病机等30多个类别,中医领域的本体多是从这些本体的子领域进行探索研究的。但是,随着本体数量的不断增加,相应的问题接踵而至。由于本体构建并没有严格的要求和规范,必然会导致相同知识被诸多本体利用,而概念不规范或多重性概念,使本体更加复杂,导致本体异构现象。而本体对齐技术是解决该问题的有效方法之一。
1 本体对齐
1.1 本体的概念及内涵
本体(Ontology)是一个源于哲学领域的概念,相当于存在论。最早给出本体定义的是Neches等,他们将本体定义为:给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成,规定这些词汇外延规则的定义。本体中包含的基本单元应该分为5类:①函数(Functions):特殊的关系;②公理(Axioms):一种断言;③类(Classes):类似于面向对象中的类的概念,是一个对象的集合;④实例(Instances):某个类的实现,也就是类的一个对象;⑤关系(Relations):概念之间的相互作用。其中,本体间最基本的关系分为4类:整体与部分的关系(Part-of)、父子关系(Kind-of)、概念与实体间的关系(Instance-of)、概念与属性间的关系(Attributeof)。本体的大致元素构成如图1所示。
一般来说,构建本体的语言有RDF和OWL。用这两种语言构建的本体中都会定义本体最基本的5类元素,这5类元素也就是各种实体以及实体间的关系,而类别(Class)、属性(Property)、实例(Instance)是最基本的元素,它们也就是本体中的实体。
1.2 本体对齐概念
简单的来说,本体对齐就是发现不同本体的实体语义关系,判断来自不同本体的两个实体是否指向现实世界中的同一种对象,从而实现本体之间的匹配映射。其实质就是相似度的匹配,输入待匹配的本体,经过相似度计算以及参数的设置,最终得到本体对齐的结果。需要进行对齐的实体可以分为3种类型:概念、属性、关系词。实体对齐结果类型也分为一对一、一对多、多对一3种,大部分情况都是一对一的匹配。本体匹配的结果可以用四元组来表示:(id,e1,e2,s),其中id表示这一映射的标号,e1和e2分别来自不同本体中的实体,s表示该实体对的相似度。
1.3 体对基本齐过程
本体对齐的过程大致可以分为5个步骤:①本体的选择;②本体预处理;③解析本体,并进行特征提取;④相似性的计算;⑤相似实体对的输出。该过程简单流程如图2所示。
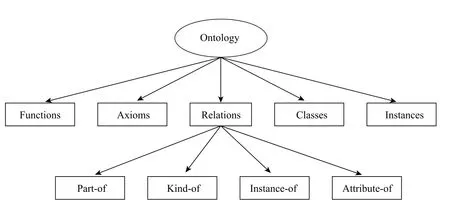
图1 本体基本组成元素图
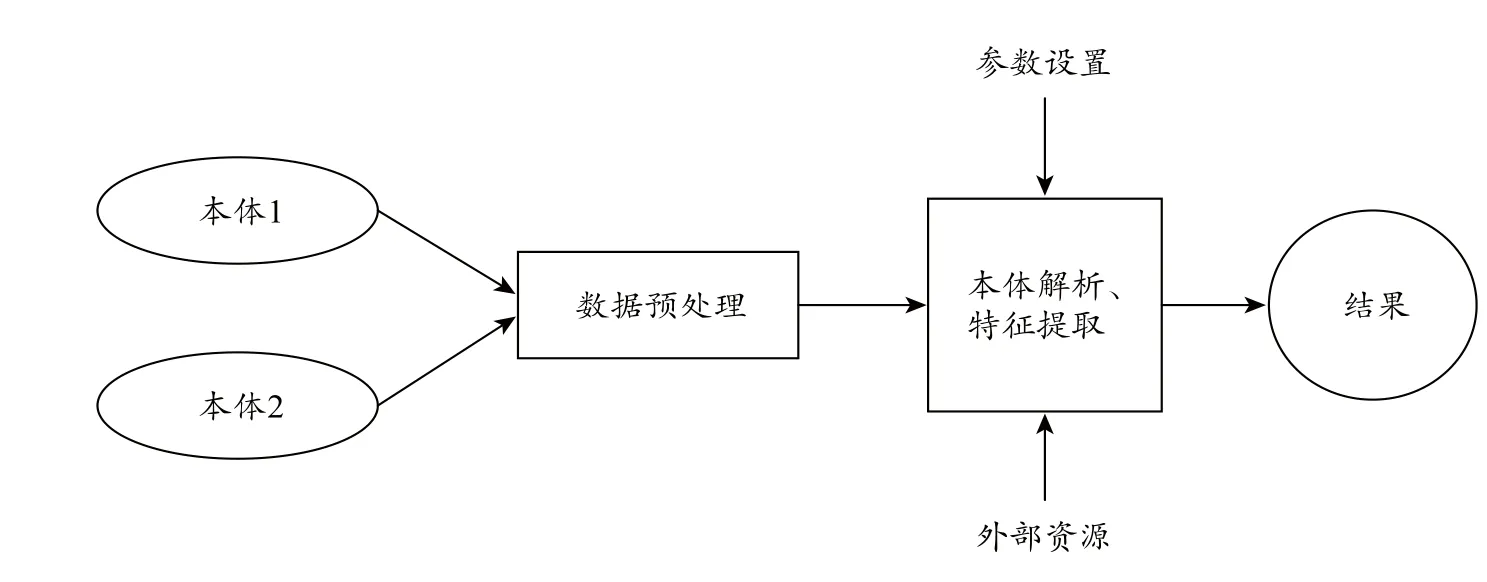
图2 本体对齐基本流程图
1.3.1 本体的选择
本体的选择首先是根据需求和目的,寻找相关领域的本体。如果不能判断本体的好坏,可以根据相应的方法(专家调查法)对本体进行评估。其次,既然是实体匹配,那么这两个本体必定有相似的元素,这需要简单的人工审查来确定。当然也可以自己搭建本体,自己构建的本体的数据量可以控制,结构也可以把控,这样处理的时候可以更加简单。
1.3.2 本体预处理
因为本体是异构的,所以需要本体预处理,本体预处理就是为了本体对齐的顺利进行以及提高对齐的效率以及准确率。实际上本体预处理就是对将要进行对齐的两个本体进行格式的调整,将本体统一成相同的格式,然后对本体中的词汇进行标准化处理,例如:将不同本体中描述实体的不同标签表述成同一种形式,更方便处理;将不同本体中实体IRI调成相同的格式,以方便操作,还可以使得对齐结果更加清晰明了等。本体预处理可以是自己手工进行的,也可以利用如今比较通用的本体编辑器进行。
1.3.3 解析本体并进行特征提取
本体解析可以使用Jena[7],这个开源包可以实现全方位的对大多数本体的解析,可以得到本体中的类别、对象属性、数据值属性以及所有的三元组等,这样就可以提取出本体中的所有实体。其次就是对实体特征的提取,如概念实体的实例、属性、关系,也就是对进行实体对相似度计量时所需的信息的提取,所以在提取实体的特征信息需要考虑到在相似度计算过程中所需要的方法。如:利用基于文本的方法,就可以提取出本体中实体的label关键字部分信息,这样就可以进行基于编辑距离的相似度计算;再如:利用基于结构的方法,就本体存在着很多的上下位关系,就可以把本体当成树状结构来处理,这样解析本体的可以得到,如层次、父子节点个数、邻居节点个数等特征信息,用这些信息来构建向量,也就可以进行相似度比较了。
1.3.4 相似性的计算
语义相似度的计算是本体对齐的关键。既然,本体对齐是实体对的对齐,那么两个本体中肯定会有些实体是不相似的,为了省去一些不必要的计算,本体对齐之前可以利用算法找到待匹配的实体对,这样就没有必要用源本体中的实体去和待匹配本体中的全体实体进行一一比较了,目前比较前沿的寻找待匹配实体对的技术是分区索引技术[12]。本体对齐的相似度计算方法有很多,分别是基于文本信息的和基于结构。基于文本的相似度计算可以计算实体的名称的相似度,实例的相似度以及属性的相似度,基于文本的相似度计算有时可以利用到一些外部资源,比如:WordNet,已有学者提出了基于WordNet的英文实体对相似度计算的方法[11]。基于结构的相似度计算可以把本体视作模型结构来采取实体的结构信息,比如RDF图模型,这样就可以计算实体的邻居节点以及邻居节点个数的相似度。一般来说,本体对齐进行相似度计算时,基于文本和基于结构的方法都要用到,并且国内很早就有学者提出了综合的语义相似度计算方法[13],目前国内外很多本体对齐系统也都是采取的综合语义相似度比较来进行实体对齐,这样的效果会有很大的提高。
1.3.5 相似实体对的输出
在得到了匹配实体对的综合相似度后,需要做的是设定一个阈值T,来将相似度与该阈值比较,通常情况下实体对的语义相似度大于T,则相似;小于T,则不相似。通常情况下阈值会设置为0.5,但是特别情况下,专家会根据实际需求以及对本体的解析,自定义该阈值。
1.4 相似性计算方法
相似性计算的方法大体可以分为2类:基于语言学特征的方法,基于结构特征的方法。基于语言学特征的相似度计算方法,最常用的有:编辑距离方法,基于WordNet的方法,基于环境信息的特征向量的方法。基于结构特征的相似度计算方法,最常用的有:Jaccard相关系数法,基于RDF树状结构的方法。
1.4.1 编辑距离
编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
1.4.2 基于Wordnet的相似性计算
基于WordNet的词语相似度计算是从WordNet词典中提取同义词并采取向量空间方法计算英语词语的相似度,构建的词语信息向量包括3个方面:①WordNet的同义词词集(Synset);②类属信息(Class);③意义解释(Sense Explanation)。
1.4.3 Jacaard相关系数法
Jacaard相关系数法是很常用的计算相似度的方法,思想也很简单,就是两个集合的交集与并集的比值,比值越大,说明相同点越多,也就越为相似。用在本体中的话,可以就实体的邻居而言,实体的邻居就是在本体与其有关系词进行关联的其他实体,这样就可以通过比较不同实体的相同邻居数与两实体的总邻居数来确定它们的相似度。
1.4.4 基于RDF树状结构法
本体是一种结构化的知识存储,基于本体内的上下位关系,可以把本体理解为树状结构,每个实体都有自己的层次,还有父子节点,兄弟节点。这样就可以统计出实体的层次,父子节点数,兄弟节点数,以及实体的所有邻居节点中包含的概念、实例、属性的个数等结构特征,利用这些特征信息可以通过构建向量的方法进行比对。
1.5 对齐系统
对齐系统(Ontology Alignment Evaluation Initiative,OAEI)是一个评价并比较本体对齐系统的比赛。在OAEI中取得不错对齐效果的系统,有Falcon-AO[8]、Rimom[9]、Logmap[10]等。
1.5.1 Rimom
Rimom是清华大学的李涓子和唐杰研发的本体对齐系统。Rimom最大的特点就是采用了多策略对齐方法,所谓的多策略就是基于语言特征与基于结构特征相似性方法的综合使用。Rimom在采用方法前,会对用于对齐的本体进行人工的比较,计算两个本体在语言特征相似和结构特征相似上的权重,根据此权重对不同的方法再次赋予不同的权重,这样也使得Rimom在2006年的OAEI上取得了不错的对齐效果。目前该系统已经很完善,但还是在持续的更新中,最新的版本可以的Rimom的官网上下载到。
1.5.2 Logmap
Logmap的全称是Logic-based Methods for Ontology Mapping,顾名思义,该系统是采取各种基于逻辑的方法,拥有自己的内在推理机制以及诊断能力。这个系统最初是为了方便生物学、医药学上信息的交互而建立的,可以对大型本体进行对齐,这是很多本体对齐系统不能实现的,并且可以分析和改善对齐的结果。
2 Orphanet和Disease Ontology对齐
2.1 本体介绍
2.1.1 Orphanet
Orphanet[5]是比较重要的疾病本体,它可以提供一个较容易理解、高质量的,关于稀有疾病和罕用药的大型语义网。Ophanet可以下载到7种语言的数据。Orphanet中的基因与Orphanet中的疾病做有交叉映射,并且Orphanet中的术语与HGNC、OMIM、MeSH、GAtlas、UniProtKB、Ensembl、IUPHAR-DB、Reactome 中的术语有交叉映射(ID对应)关系。其中,基因与疾病的关系是根据基因在一种疾病的发病机制中的作用而被限定的。
2.1.2 Disease Ontology
DiseaseOntology(DO)[4]是由西北大学的研究人员,遗产医药学中心以及马里兰大学医学院基因科学研究所的人员共同努力下所建成的一个西医疾病本体。该本体对其包含的医学术语都有详细描述,本体内包括疾病术语、表型特征术语以及相关医药学词汇的疾病概念。并且,DO所集汇的疾病或者医药术语都与MeSH、ICD、thesaurus、SNOMED、OMIM的术语做了广泛的交叉映射(ID映射),作为一个属性存储在本体术语信息之中。
2.2 实现过程
2.2.1 数据获得
这两个本体均可在网上下载得到,在Orphanet中下载得到ordo_orphanet.owl,在DO中下载得到doid.owl。
2.2.2 数据预处理
(1)标签处理
标签处理,首先是分别找到两个本体中用来描述本体实体的标签,将其中表示意义相同但是表示形式不同的标签统一为同一种标签;其次,找出本体对齐的方法所不能转化的标签,将它们进一步处理,处理为意义不变并且方法可以识别的标签;最后是对一些冗余标签的处理,比如:Orphanet本体描述实体的关系标签可以表示Orphanet中实体与Reactome库中的实体的对应关系,但是在DOID中并不存在这种关系标签,那么就可以去除这种标签,这样适当的减少数据信息,也可以提高对齐准确率。
(2)IRI处理
尽量将两个本体的IRI统一成最基本的形式,类如doid实体IRI如:http://purl.obolibrary.org/ obo/DOID_#####的格式,ordo_orphanet中实体IRI如:http://www.orpha.net/ORDO/Orphanet_#####的格式。不仅方便处理,而且最终的显示结果也更加清晰明了。
2.3 数据分析结果
(1)语言特征信息对比
DOID中的部分数据的信息如表1,Orphanet中的部分数据的信息如表2。根据表格1、表2中给出的部分实体的文本信息比照,可以判断出给出的数据中可以找出三对实体映射:①Orphanet_35和DOID_14701,Orphanet_35与DODI_14701具有相同的MeSH映射ID,OMIM映射ID以及Label字段;②Orphanet_976和DOID_0060350,Orphanet_976与DOID_0060350具有相同的OMIM映射ID以及Label;③Orphanet_309005和DOID_3146,虽然Orphanet_309005和DOID_3146没有相同的OMIM或者MeSH映射ID,但是它们的Label关键字段信息基本相同。
(2)结构特征信息对比:
DOID中的部分数据的结构图如图3,Orphanet中的部分数据的结构图如图4。就结构信息来说,以上的三对实体映射:①Orphanet_35和DOID_14701均是图中叶子节点,但是它们位于的层次并不相同;②Orphanet_976和DOID_0060350也均是图中的叶子节点,但是他们位于的层次并不相同;③Orphanet_309005和DOID_3146则不然,Orphanet_309005仍是叶子节点,DOID_3146具有子节点,实际上它们在本体中的父节点个数也是不一样的。
(3)结果分析
实际上,Orphanet和DO中概念大多是疾病概念,本体中存在的关系大都是以SubClassOf关联的父子类上下位关系。而Orphanet本体中的父子类上下位关系大致也就三层,定义了几大类,再细分为几小类,然后就是具体的疾病或者临床特征了。而DOID中的上下位关系比较丰富,所以它的本体结构层次也就会更多。总的来说,Orphanet与DOID的结构上相似性并不大,该对齐主要是依靠的本体中实体的文本信息。实际的对齐结果如表3。
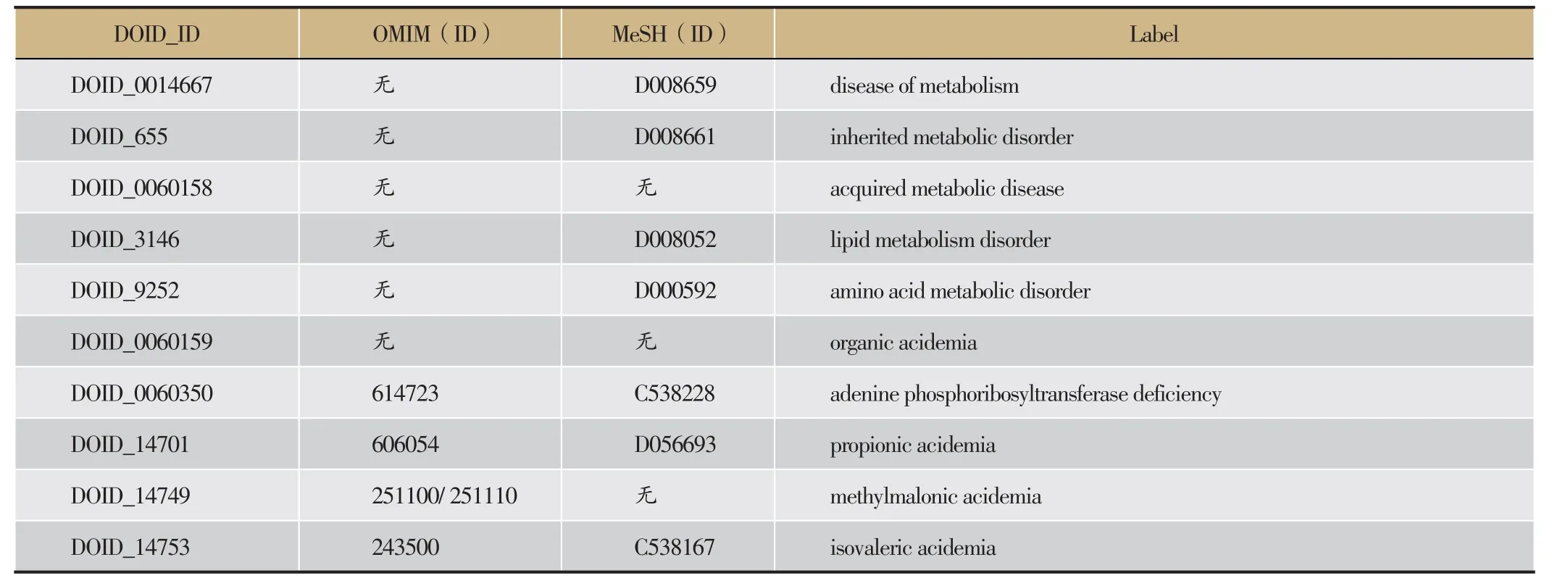
表1 DOID本体中部分概念实体的信息
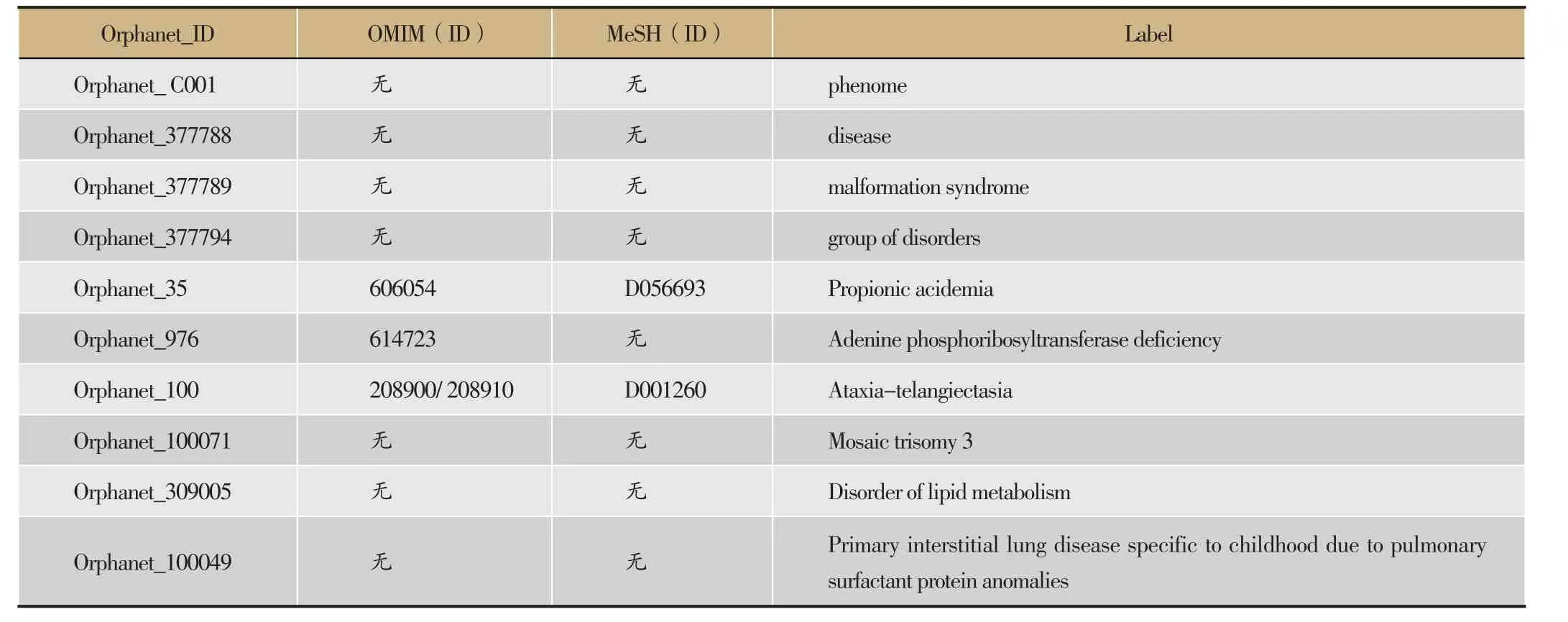
表2 Orphanet本体中部分概念实体的信息
3 探讨
本体仅仅是实现了Orphanet 和DO两个西医疾病本体中的简单对齐,找出了疾病概念匹配对,没有对疾病的具体分类做探讨研究。实际上,DO,Orphanet这些本体都和其他的一些本体(MeSH,OMIM)做有交叉映射,也就是这些本体中的概念存在与其他本体的概念的映射ID,这为本体交互提供了很大的方便,这也说明本体对齐问题的解决在部分西医本体中有所体现。本体对齐问题的普遍化,越来越多的本体对齐工具的出现,不少学者尝试利用本体对齐工具与更合适的算法来进行医学本体的对齐,比如:药物领域本体RxNorm与NDF-RT的映射[14],这也显示了医学人员对本体对齐的看重。
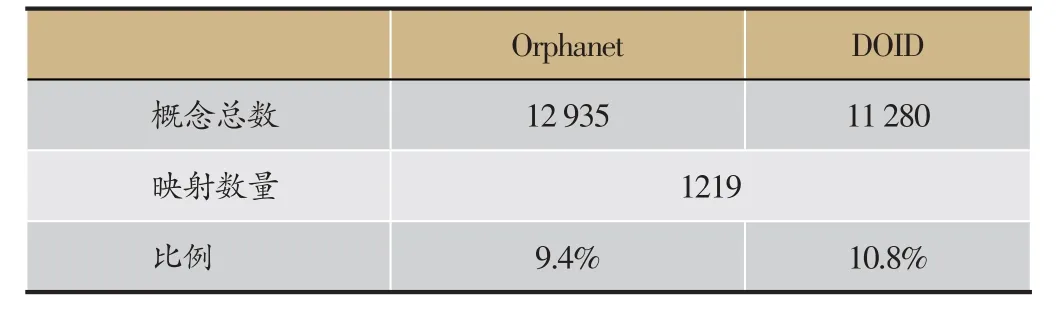
表3 Orphanet和DOID的对齐结果
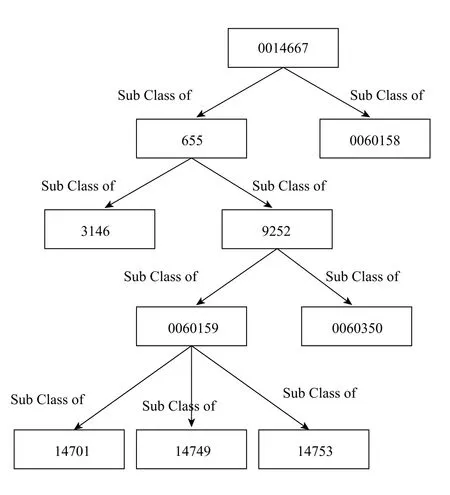
图3 DOID部分概念结构图
目前本体对齐已经在西医相关研究中有一定的成效,但是对中医来说,因中医药理论知识体系的复杂性使得中医在知识传承、知识共享、知识交流方面存在较大的障碍,这也是长期以来制约中医发展的“瓶颈”之一,本体对齐问题尤为关键。目前,国内拥有了一些中医知识系统,比如:自2001年起,中国中医科学院联合全国其他30多家中医研究单位,开始建立“中医药学一体化语言系统”,一个中医药术语本体系统,目前,该系统共编录了16个一级项目,12 800多个类[15],已是最大的传统的中医医药本体,该系统的建立是一项创新性的工作,对实现中医药知识的标准化起到了很重要的作用。此外,还有老中医根据多年的经验构建的中医药本体,例如:老年性痴呆中医药本体、失眠中医药本体等,我们可以采用以上讲述的本体对齐方法来进行中医药上的术语对齐,这样也对中医药知识再发现有很大的促进作用。本体对齐还可以应用在中医疾病本体上,比如:曹宇峰等[6]构建了中医舌诊本体与中医肝病本体,还有张梅奎等[16]构建的中医脑疾病本体,这些本体都可以用来与大型的疾病本体进行对齐,也有利于中医疾病的再发现。此外,目前还有很多的中医证、诊断方法本体,也可以进行本体对齐,以便知识更好的交流以及融合。
综上所述,由于中医本体的复杂性,本体对齐问题在中医领域还没有得到很好的解决,大部分相关中医本体之间没有映射,中医本体对齐问题需进一步完善。近年来,中医重要性的日益显著,为了更好地促进中医的知识交流,本体对齐问题会受到越来越多的中医人员的重视,该问题也会得到更好的解决。
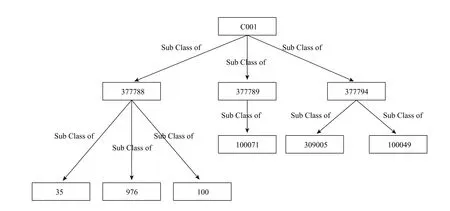
图4 Orphanet部分概念结构图
参考文献
1 Auer S, Bizer C, Kobilarov G,et al. DBpedia: A Nucleus for a Web of Open Data.SemanticWeb, 2007, 4825:11-15.
2 吴正荆,黄薇,牟冬梅,等. 生物医学领域本体开发项目比较研究.中华医学图书情报杂志,2010,19( 5):16-19.
3 Consortium G O. The Gene Ontology (GO) database and informatics resource.Nucleic Acids Research, 2004, 32(suppl_1):D258-D261.
4 Schriml L M, Arze C, Nadendla S,et al.Disease Ontology:a backbone for disease semantic integration.NucleicAcidsResearch, 2012, 40(Database issue):940-946.
5 Aymé S. Orphanet, an information site on rare diseases.Soins Chirurgie,2003,672:46-47.
6 曹宇峰,曹存根,CAOYu-feng,等. 基于本体的中医舌诊知识的获取. 计算机应用研究, 2006, 23(3):31-34.
7 Labs H, Labs H. Jena Semantic Web Framework for Java.WorldWide WebConferenceSeries, 2003.
8 Hu W, Qu Y. Falcon-AO: A practical ontology matching system.Web Semantics Science Services & Agents on the World Wide Web, 2008, 6(3):237-239.
9 Li J, Tang J, Li Y,et al. RiMOM: A Dynamic Multistrategy Ontology Alignment Framework.IEEE Transactions on Knowledge & Data Engineering, 2009, 21(8):1218-1232.
10 Jiménezruiz E, Grau B C. LogMap: Logic-Based and Scalable Ontology Matching. International Conference on the Semantic Web.Springer-Verlag, 2011:273-288.
11 翟延冬,王康平,张东娜,等. 一种基于WordNet的短文本语义相似性算法. 电子学报, 2012, 40(3):617-620.
12 庄严,李国良,冯建华. 知识库实体对齐技术综述. 计算机研究与发展, 2016, 53(1):165-192.
13 张忠平,田淑霞,刘洪强. 一种综合的本体相似度计算方法. 计算机科学, 2008, 35(12):142-145.
14 王丽伟,王伟,高玉堂,等. 领域本体映射的语义互联方法研究——以药物本体为例. 图书情报工作, 2013, 57(17):21-25.
15 李兵,裘俭,张华敏. 中医药领域本体研究概述. 中国中医药信息杂志, 2010, 17(3):100-101.
16 李毅,张梅奎,杜侃,等. 中医脑病学本体的探讨及其构建. 世界科学技术—中医药现代化, 2007, 9(6):96-101.
The Overview of Ontology Alignment techniques and Their Applications to Traditinoal Chinese Medicine (TCM)
Hao Weixue,Yu Jian, Zhou Xuezhong
(College of Computer Science and Information Technology, Beijing Key Lab of Traffic Data Analysis and Mining, Beijing Jiaotong University, Beijing 100044, China)
Ontology alignment technology is a knowledge engineering method to realize the concept and relationship integration of different ontologies. In view of the same scope of ontology, such as disease ontology,developed by researchers from a number of different areas or institutions of independent research and development, there is a big difference between the term expression and the concept of the relationship. Thus,how to achieve the integration of multi-source ontology through alignment processing has been recognized as a significant methodological problem. In this paper, the concept, technology, method and corresponding tool of ontology alignment were expounded at full length. The technique of ontology alignment based on linguistic features and structural features was emphasized. Combined with the two international disease ontology: Disease Ontology and Orphanet, the experiment and analysis of the technique of ontology alignment were carried out and detailed the application of alignment technology. Furthermore, for the existing multi-source problems on TCM ontology database, the necessity and application of ontology alignment were discussed.
Ontology alignment, ontology preprocessing, similarity calculation, disease ontology, traditional Chinese medicine ontology alignment application
10.11842/wst.2017.01.009
R229
A
(责任编辑:马雅静,责任译审:朱黎婷)
2016-12-29
修回日期:2017-01-05
* 国家自然科学基金委青年基金项目(61105055):表型与基因型功能关联的数据整合和网络分析方法研究,负责人:周雪忠。
** 通讯作者:周雪忠,本刊编委,教授,主要研究方向:复杂网络、数据仓库、数据挖掘。
猜你喜欢
现代临床医学(2021年3期)2021-07-16
中国民间疗法(2021年5期)2021-06-09
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
知识经济·中国直销(2017年7期)2017-07-24
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
制造业自动化(2017年2期)2017-03-20
中国卫生(2016年11期)2016-11-12
文学教育(2016年27期)2016-02-28
