
High Quality Audio Object Coding Framework Based on Non-Negative Matrix Factorization
2017-04-09 05:52TingzhaoWuRuiminHuXiaochenWangShanfaKeJinshanWang
China Communications 2017年9期
Tingzhao Wu, Ruimin Hu*, Xiaochen Wang, Shanfa Ke, Jinshan Wang
1 National Engineering Research Center for Multimedia Software, School of Computer Science, Wuhan University, Wuhan 430072, China
2 Hubei Key Laboratory of Multimedia and Network Communication Engineering, Wuhan University, Wuhan 430072, China
3 Collaborative Innovation Center of Geospatial Technology, Wuhan 430079, China
* The corresponding author, email: hrm@whu.edu.cn.
I. INTRODUCTION
Audio encoding technology has been rapidly developed from the traditional mono, stereo to more immersive multi-channel audio coding technology, such as MPEG Surround /Spatial audio coding [1-3], NHK22.2 [4], Ambisonics[5] and WFS [6], etc. In recent years, based on the multi-channel audio coding technology, the coding and reconstruction of 3D audio scene has been realized. However, the channel-based audio scene coding technology [7, 8] provides low flexibility, so it cannot meet the requirement of personalized reconstruction as well as the accuracy demand for individual object trajectory. While, the object-based audio coding method with corresponding metadata [9] can make up for the deficiencies.
Many scholars and research institutions have started to work on object-based audio coding, and there are some methods have been proposed.
Nikunen proposed an audio object coding method based on nonnegative matrix factorization [10]. In his method, the spectrogram of each audio object is factorized into two decomposed matrices, and the phase information of each time-frequency point is additionally encoded separately. However, this method encodes the audio objects separately, so the bitrate increases linearly with the number of objects. As a result, the bitrate of a complicated audio scene would beyond the capacity of bandwidth.
Maoshen Jia proposed a new compression framework for encoding multiple simultaneously occurring audio objects based on the intra-object sparsity [11]. In the framework,he assumes that one audio object is active only in particular frequency components. So the framework extracts the active frequency components for every object within the same frame to compose a frame of mixed signal.And in order to reconstruct audio object, it also records that where the frequency components are extracted. But, it should be noticed that the frame size is fixed, so the frequency components which can be preserved are limited, especially when objects are too many. In other words, the spectral energy loss is serious and the reconstructed sound quality isn’t good enough to support audio scene coding.
Besides, the most popular object-based coding method is the Spatial Audio Object Coding method (SAOC), which is proposed by German research institution Fraunhofer [12-15]. At the encoding stage, the Objects Level Difference (OLD) is extracted as the object parameters, and transmitted to decoding stage along with down-mix signal. At the decoding stage, the parameter OLDs are firstly used to calculate the gain factors, and then the object signal can be reconstructed with down-mix signal and gain factors. More details about SAOC are shown in section II. The SAOC method can transmit multiple audio object signals at conventional mono or stereo bitrate,greatly improving the efficiency of audio object coding. However, in order to ensure a low bit rate, every frame signal is grouped into a few sub-bands and OLD is extracted for each sub-band. So the parameter frequency domain resolution is relatively low. As a result, the reconstructed object signals is usually not pure.In other words, the reconstructed object A will contain other objects, such as object B, etc.We call it frequency aliasing, and the frequency aliasing can lead to serious sound quality degradation, especially when playing alone or completely eliminating an object signal.
To deal with the extreme case, Kwangki Kim proposed a two-step coding structure based on SAOC [16]. In the structure, the object which needs to be extremely processed is signed as target object, while the rest objects are normal objects. In the first step, normal audio objects are mixed into normal downmix signal, and the OLDs of normal objects are extracted as step I parameters. In the second step, normal down-mix signal and target object are mixed into final down-mix signal,and the Channel Level Differences (CLDs) are extracted as step II parameters. Besides, the structure encodes the residual of target object to improve the reconstructed quality of target object. However, the bitrate cost of residual coding is too high. When the available bitrate for two-step structure is equal to conventional SAOC, the structure can guarantee high quality of the target object, but there will be more serious frequency aliasing among the normal audio objects.
In summary, with the limitation of high bitrate or poor sound quality, existing objected-based audio coding methods cannot meet the requirement of audio scene coding. Therefore, we propose the NMF-SAOC coding framework, which can provide high coding quality and low bitrate at the same time. In the framework, we extract object parameters with higher frequency domain resolution, which can reduce the frequency aliasing effectively.While at the same time, the size of parameter matrix becomes larger than conventional SAOC because of increased frequency domain resolution. Thus, we apply NMF method to decompose the large size object parameter matrix into smaller size matrices, thereby reducing the bitrate of object parameter coding. Compared with the conventional SAOC method at the same bitrate, the proposed NMF-SAOC framework can achieve higher reconstructed sound quality of audio objects,and the recovered audio scene is closer to real condition. We also verify the coding performance of the framework by subjective and objective experiments.
The remainder of the manuscript is organized as follows: Section II introduces the conventional SAOC coding method. Section III elaborates the framework of proposed NMF-SAOC method. And Section IV involves objective and subjective experiments and data analysis. Finally, the conclusion is drawn in Section V.
II. OVERVIEW OF CONVENTIONAL SAOC
SAOC evolves from the Spatial Audio Coding technology (SAC) [15]. As shown in figure 1,unlike SAC, the input of SAOC is no longer multi-channel signal, but a number of individual audio objectssuch as guitar,piano, flute, etc. And parameters are the object parameter OLDs. Besides, the renderer in SAOC framework converts the reconstructed multi-object signals to multi-channel signals,which are fed to loudspeakers. In this manuscript, we mainly focus on the encoding and reconstruction of audio object, so the renderer is not discussed in depth here.
The input audio objects are first converted to frequency domain in the encoder. And the converted signals on the one hand are mixed to get down-mix signal, on the other hand,used to extract parameters.
It should be noticed that before extracting parameters, the converted signals are divided into sub-bands to achieve low bitrate. A typical sub-band division is near twice width of the equivalent rectangular bandwidth (ERB)[16, 17], as shown in table 1.
After sub-band division, the object parameter OLD is calculated for each sub-band by[16]:

At the decoder, the gain factors of audio objects are first calculated with OLDs, as follows:

In fact, the square of the gain factors represents the energy ratio between the jth object and the sum energy of all the objects, at subband b of the nth frame. Therefore, the audio object can be approximately reconstructed with down-mix signal and gain factors, as shown below:
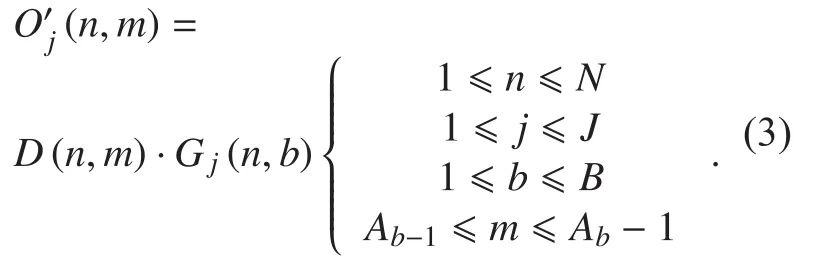
All frequency points involved in one subband share the same gain factor. Therefore,when the sub-band division is finer, the higher the parameter frequency domain resolution,and the better the reconstructed signal quality.

Fig. 1 The block diagram of SAOC framework
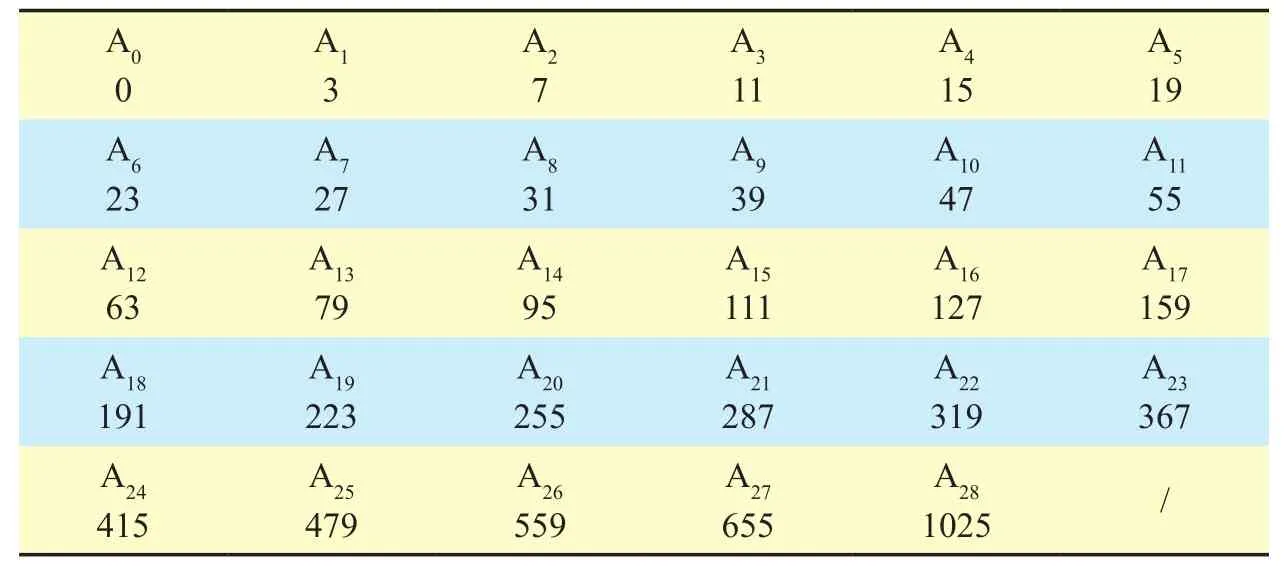
Table I Partition boundaries for bandwidths of 2 ERB, MDCT size of 2048, and sampling rate of 48 KHz.
However, the bitrate is linearly proportional to the number of sub-band. To ensure the coding efficiency, SAOC adopts small number of subbands, so the parameter frequency domain resolution is too low, which finally results in the frequency aliasing and sound quality degradation.
III. PROPOSED NMF-SAOC FRAMEWORK
In order to relieve the frequency aliasing and further improve the audio object coding quality, this manuscript presents a new object coding framework based on NMF, as shown in figure 2. In the proposed framework, the subband is divided in a finer way to improve the parameter frequency domain resolution. And simultaneously, because the NMF method can achieve dimension reduction and compression,we apply it into our framework to compress the increased number of parameters to maintain low bitrate.
3.1 Parameter extraction with high frequency domain resolution
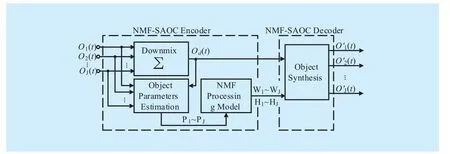
Fig. 2 The block diagram of NMF-SAOC method
Based on the 2ERB band, we subdivide each band to get more sub-bands. For example, if we divide each sub-band into two smaller subbands, we can get 56 sub-bands, as shown in table 2. Besides, we can divide into more small sub-bands to further improve the frequency domain resolution. In this paper, the sub-band number we adopt ranges from 85 to 242 corresponding to different bitrates.
After subdivision, we will get a finer group of sub-bands. Then the object parameters are calculated based on the finer sub-bands.During our research, we found the method to extract parameters of SAOC could be modified to achieve better performance.
The parameter extraction and down-mix procedure are parallel and separate in SAOC framework, while the down-mix signal and parameters are used to reconstruct audio objects by multiplication. In fact, this approach does not guarantee the conservation of energy between the original audio object and its reconstructed version, since the gain factor is actually the energy ratio between an object and the sum of all objects, and the down-mix signal energy is not equal to the energy of all objects. So the down-mix signal multiplied by the gain factors cannot accurately obtain the energy of the audio object signal.
Therefore, this manuscript adopts an energy conservation method to extract parameters. As shown in figure 2, in the encoder of NMF-SAOC framework, the input audio objects are first down-mixed in the frequency domain to get down-mix signal. And then, instead of OLDs, the gain factors for each object are directly extracted in Object Parameter Estima-tion Module with individual object signal and down-mix signal, as in the following equation:

Table II Partition boundaries for bandwidths of higher frequency resolution

3.2 Parameter coding based on NMF
In order to improve coding quality, we extract the object parameters for more sub-bands,but the bitrate will increase linearly with the number of sub-bands. Therefore, we introduce the NMF method to cope with the increased parameter coding bitrate. By NMF method,a parameter matrix with large size can be expressed by two matrices with smaller size, as shown below [18-21]:

The derivation of matrix H and W can be considered as an optimal iterative solution [20,21]. As shown in the following formula:
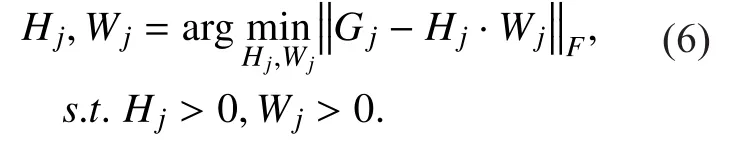
The optimal solution of Eq.6 can be found by the following multiplicative updates:

Through the iterations, we get a set optimal H and W for every audio object. Then the matrices are transmitted to the decoder as side information, and used to reconstruct audio object signals along with the down-mix signal.
The NMF method can greatly compress the bitrate required for encoding the object parameters. For SAOC, the number of parameter needed to transmit for each audio object is, while for the NMF-SAOC framework, the number of parameter required to transmit isFor example, if a signal has 300 frames, and each frame is divided into 256 sub-bands, then the parameter number of SAOC required to transmit iswhile when settingthe parameter number of NMF-SAOC framework isonly about one-seventh of SAOC.
3.3 Reconstruction of audio object
In proposed framework, the decoder receives the uniformly quantized matricesandand the gain factor matricescan be calculated by:

And then we use the calculated gain factor matrices and down-mix signal to reconstruct the audio object signals, as follows:

Compared with the conventional SAOC,proposed method can relieve frequency aliasing and retain more spectral details. The reconstruction results are shown in figure 3.We can see that the object spectrogram reconstructed by SAOC method contains many frequency components which belong to other objects, and it causes serious distortion, as shown in the marked area of figure 3 (c). In contrast, the object spectrogram recovered by proposed method is closer to the original signal, as shown in figure 3 (b). It contains less components of other objects and has more lightly distortion. So the proposed method can further meet the requirement of high quality audio scene coding.

Table III Description of two test cases

Fig. 3 The spectrogram comparison of original and decoded object signals
IV. EXPERIMENTS & RESULTS
In the experiment part, we carries out a series of subjective and objective experiments to verify the performance of proposed method in encoding multiple audio object signals. The experimental reference method includes the conventional SAOC [12-15] and the enhanced TwoStep-SAOC method [16].
4.1 Test conditions
The time-frequency transform in the experiments is achieved based on MDCT, with 2048 sample points per frame and 50% overlapping.The test excerpts are selected from the MPEG standard test database [12], which was created by the MPEG organization in 2010 and dedicated to testing SAOC coding performance.The database includes various types of audio object signals, such as flute, piano, wind chimes, etc. And the sampling frequency is 48 KHz, duration is no longer than 20s.
We use signal-to-distortion ratio (SDR) as metrics of objective experiment [22-23]. SDR expresses the distortion between the reconstructed signal and the original signal, and it can be calculated by:
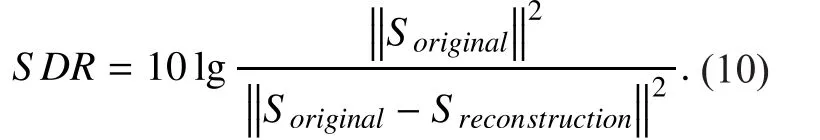
While for subjective experiments, all tests are conducted conforming to the MUSHRA test method [24], and we select total of 20 experienced listeners to participate in. In order to demonstrate the performance of proposed method, we design two test cases, as shown in table 4.
4.2 Experiment I: comparison of NMF-SAOC and SAOC at different bitrates
In this part, we take SAOC as the reference method and compare the coding performance with proposed method at different bitrates. We select six excerpts from the standard database,including bagpipes, piano, etc. All the selected excerpts are processed by the two methods,and the results are analyzed and compared.
The objective results at different bitrates are shown in figure 4. We can see that for a fixed bitrate, the audio object signals reconstructed by NMF-SAOC have higher SDR values for majority objects. But, for excerpt e03 the SAOC method has higher SDR, which is because the active frequency components of the third object signal is too many, as shown in figure 5 (b), and it is beyond the express ability of NMF-SAOC with the given K. In contrast, for the excerpt e01, the NMF-SAOC method raises SDR by up to 7dB. Which can be attributed to that the first audio object has a relatively smaller amount of active frequency components, as shown in figure 5 (a), and it can be well reconstructed by NMF-SAOC method.
The average SDR value are also calculated and as shown in table 4. It can be seen that the average SDRs obtained by the NMF-SAOC method is superior to that obtained by SAOC method at the same bit rate. And with the increase of the bitrate, the SDR of two methods both increases, besides the difference value between the NMF-SAOC and SAOC method shows an increasing trend. When the bitrate is 7kbps, as shown in table 4, the difference value is the largest, reaching about 2dB.
The conclusions we can draw through the first objective experiment are as following:
● For majority objects, the NMF-SAOC method obviously has better coding performance than the conventional SAOC method at the same bitrate, but the coding performance of the NMF-SAOC method decreases slightly when the audio object has too many active frequency components.
● Within a certain bitrate range, the advantages of the NMF-SAOC coding framework become more pronounced as the bitrate increases.
And we verify our conclusions by the subjective experiment. We select 15 experienced listeners to judge according to the sound quality of reconstructed object signals.
The result is as shown in figure 6, when the bitrate is the same, the score of NMF-SAOC method is obviously higher than that of SAOC method. That is to say, the reconstructed signal quality of proposed method is better than SAOC method. Moreover, the difference between the two methods increases as the bitrate increases. As shown in the figure, the difference value grows up to nearly 20 points at 7kbps from 12 points at 3kbps.
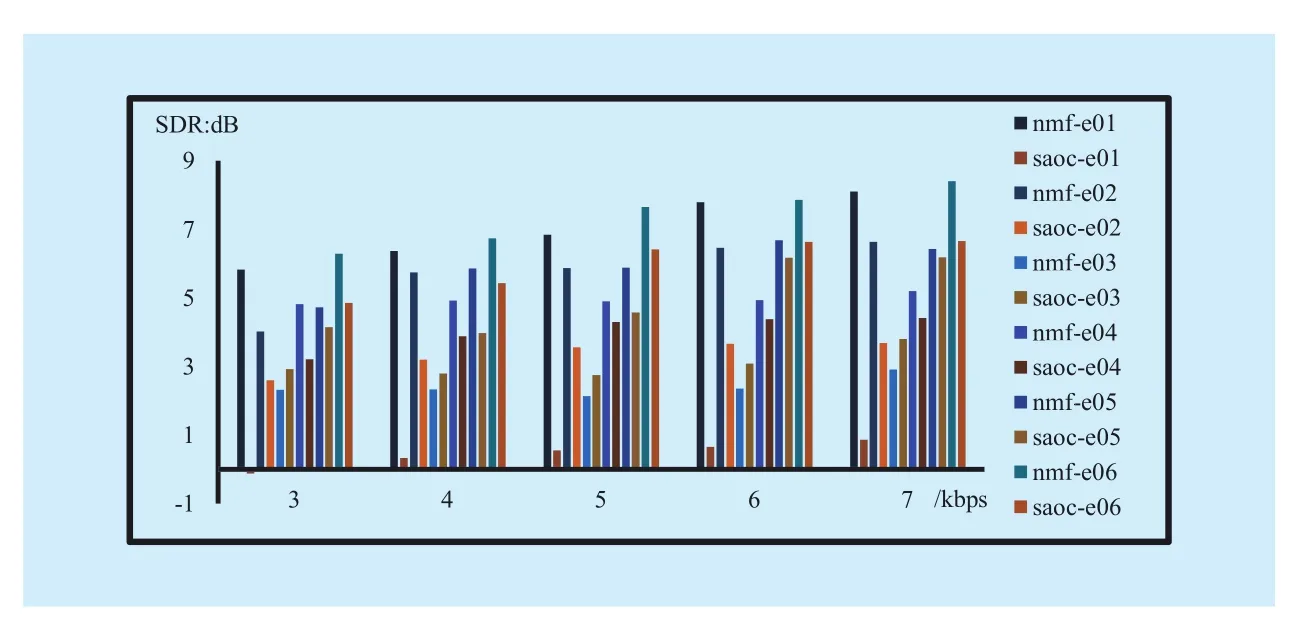
Fig. 4 The SDR values of the excerpts at different bitrates. The nmf-e01~ e06 are the SDR of excerpts reconstructed by NMF-SAOC method (proposed method),while the saoc-e01~ e06 are the SDR of excerpts reconstructed by SAOC method(reference method)
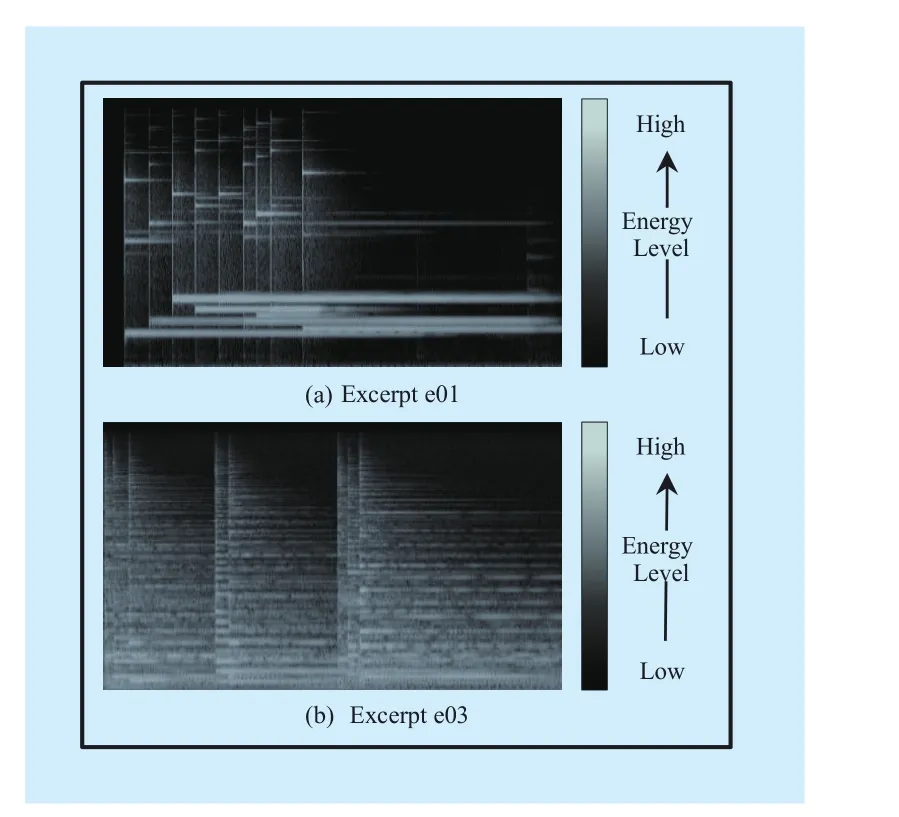
Fig. 5 The spectrogram of original excerpt e01 and e03
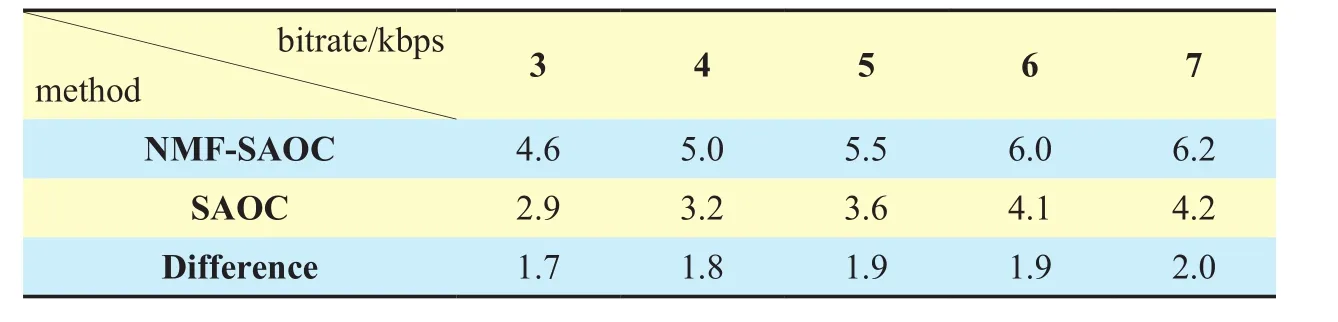
Table IV Comparison of average SDR (dB) between the two methods

Fig. 6 The MUSHRA scores of two methods corresponding to each bitrate with 95% confidence interval. The anchor is obtained by filtering the down-mix signal with 35 kHz low-pass filer

Fig. 7 The SDR of the excerpts decoded by different methods
The result of the subjective experiment is consistent with the result of objective experiment, so it can effectively support our conclusions drawn after the objective experiment.
4.3 Experiment II: comparison of NMF-SAOC, SAOC and TwoStep-SAOC at fixed bitrate
The first experiment have proved that the coding performance of NMF-SAOC method is superior to conventional SAOC method at different bitrates.
In this part, we added Kim’s TwoStep-SAOC method [16] as the second reference method, and then compared the coding performance of the three methods at a specific bitrate. We selected additional six unused excerpts from the standard database as test sequences, and set the bitrate for each object parameter coding to 5kbps. The objective experiment results are shown in figure 7.
As can be seen from the figure, the NMF-SAOC method has the highest SDR for most of the audio object excerpts. In particular, for the excerpt e09, the SDR of the NMF-SAOC method is about 8dB higher than that of the other two methods, because the e09 active frequency components number is relatively small. While for the excerpt with large active frequency components number, such as excerpt e10, NMF-SAOC coding performance is weaker than SAOC. It is worth noting that,for excerpt e12, the TwoStep-SAOC method has the best coding performance, but for the rest excerpts the performance of TwoStep-SAOC method is the worst. That because excerpt e12 is the target object of the TwoStep-SAOC method, so the bitrate used to encode the e12 residual signal takes a large part of the total bitrate, resulting in that the bitrate for other object parameters coding is even lower than the conventional SAOC. As a result, the Two-Step-SAOC method provides the best quality for target object, but the worst quality for the rest objects. Therefore, taking the overall coding quality into account, the NMF-SAOC method has the best coding performance.
We also validate it by subjective experiment. 10 experienced listeners (half of them have been selected in Experiment I) are chose to take part in the test, and the experimental result is shown in the figure 8.
As we can see, for most audio object excerpts, the NMF-SAOC method gets the highest score among the three methods. Especially for e09, NMF-SAOC gets about 20 points higher than SAOC and nearly 30 points higher than TwoStep-SAOC. While, because e12 is the target object of TwoStep-SAOC method,the NMF-SAOC score is about 10 points lower than TwoStep-SAOC.
Besides, the results of the second subjective and objective experiment are also consistent,so the superiority of the NMF-SAOC method can be further proved.
V. CONCLUSION
Existing object-based coding methods are subject to the limitation of high bitrate or low quality, so they cannot enable the personalized and high quality reconstruction of individual object or audio scene. In this manuscript, we applied NMF method to object parameter coding, and proposed the NMF-SAOC framework.The framework is able to improve the coding quality of audio objects and audio scene without increasing the bitrate. Compared with other methods at the same bitrate, NMF-SAOC can relieve frequency aliasing significantly,and the sound quality of reconstructed signals is closer to original versions. And extensive experimental results demonstrate the superior performance of proposed NMF-SAOC method when simultaneously encode multiple audio objects. In summary, the NMF-SAOC framework makes it possible to achieve high quality and personalized demanded audio scene coding for low bitrate case.
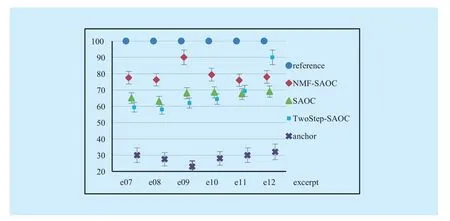
Fig. 8 The MUSHRA scores of additional six excerpts with 95% confidence interval. The anchor is obtained by filtering the down-mix signal with 35 kHz low-pass filer
ACKNOWLEDGEMENTS
The authors would like to thank the reviewers for their detailed reviews and constructive comments, which would help improve the quality of this paper.
The research was supported by National High Technology Research and Development Program of China (863 Program) (No.2015AA016306); National Nature Science Foundation of China (No. 61231015); National Nature Science Foundation of China (No.61671335).
[1] Breebaart J, Faller C. “Spatial audio processing:MPEG Surround and other applications” [M].John Wiley & Sons, 2008.
[2] Breebaart J, Disch S, et al. “MPEG spatial audio coding/MPEG surround: overview and current status”, Proc. Audio Engineering Society, 2005,USA.
[3] Disch S, Ertel C, Faller C, et al. “Spatial audio coding: Next-generation effi cient and compatible coding of multi-channel audio,” Proc. Audio Engineering Society, 2004, USA.
[4] Ando A. “Conversion of multichannel sound signal maintaining physical properties of sound in reproduced sound field,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19,no. 6, 2011, pp. 1467-1475.
[5] Ward D B, Abhayapala T D. “Reproduction of a plane-wave sound field using an array of loudspeakers,” IEEE Transactions on speech and audio processing, vol. 9, no. 6, 2001, pp. 697-707.
[6] Berkhout A J, Diemer de V, Vogel P. “Acoustic control by wave field synthesis,” The Journal of the Acoustical Society of America, vol. 93, no. 5,1993, pp. 2764-2778.
[7] Goodwin M M, Jot J M. “Primary-ambient signal decomposition and vector-based localization for spatial audio coding and enhancement,”Proc. IEEE ICASSP, 2007, pp. I9-I12.
[8] Jot J M, Krishnaswami A, Laroche J, et al. “Spatial audio scene coding in a universal two-channel 3-D stereo format,” Proc. Audio Engineering Society, 2007 , USA.
[9] Fueg S, Hoelzer A, Borss C, et al. “Design,coding and processing of metadata for object-based interactive audio,” Proc. Audio Engineering Society, 2014, USA.
[10] Nikunen J, Virtanen T. “Object-based audio coding using non-negative matrix factorization for the spectrogram representation,” Proc. Audio Engineering Society, 2010, UK.
[11] Jia Maoshen, Yang Ziyu, Bao Changchun, et al. “Encoding multiple audio objects using intra-object sparsity,” IEEE Transactions on Audio,Speech, and Language Processing, vol. 23, no. 6,2015, pp. 1082-1095.
[12] Herre J, Purnhagen H, Koppens J, et al. “MPEG spatial audio object coding—the ISO/MPEG standard for effi cient coding of interactive audio scenes,” Journal of the Audio Engineering Society, vol. 60, no. 9, 2012, pp. 655-673.
[13] Herre J, Hilpert J, et al. “MPEG-H 3D audio—the new standard for coding of immersive spatial audio,” IEEE Journal of Selected Topics in Signal Processing, vol. 9, no. 5, 2015, pp. 770-779.
[14] Engdegård J, Falch C, et al. “MPEG spatial audio object coding-the ISO/MPEG standard for effi -cient coding of interactive audio scenes,” Proc.Audio Engineering Society, 2010, USA.
[15] Herre J, Disch S. “New concepts in parametric coding of spatial audio: From SAC to SAOC,”Proc. IEEE ICME, 2007, pp. 1894-1897.
[16] Kim K, Seo J, Beack S, et al. “Spatial audio object coding with two-step coding structure for interactive audio service,” IEEE Transactions on Multimedia, vol. 13, no. 6, 2011, pp. 1208-1216.
[17] Faller C, Baumgarte F. “Binaural cue coding-Part II: Schemes and applications,” IEEE Transactions on Speech and Audio Processing, vol. 11, no. 6,2003, pp. 520-531.
[18] Kim J, He Yunlong, and Park H. “Algorithms for Nonnegative Matrix and Tensor Factorizations:A Unified View Based on Block Coordinate Descent Framework,” Journal of Global Optimization, vol. 58, no. 2, 2014, pp. 285-319.
[19] Kim J and Park H. “Fast Nonnegative Matrix Factorization: An Active-set-like Method and Comparisons,” SIAM Journal on Scientific Computing,vol. 33, no. 6, 2011, pp. 3261-3281.
[20] Lee DD, Seung HS. “Learning the parts of objects by non-negative matrix factorization,” Nature, vol. 401, no. 21, 1999, pp. 788-791.
[21] Lee D D, Seung H S. “Algorithms for non-negative matrix factorization,” Proc. Advances in neural information processing systems, 2001, pp.556-562.
[22] Vincent E, Gribonval R, Févotte C. “Performance measurement in blind audio source separation,”IEEE transactions on audio, speech, and language processing, vol. 14, no. 4, 2006, pp. 1462-1469.
[23] Wu Tingzhao, Hu Ruimin, Wang Xiaochen, et al.“Head Related Transfer Function Interpolation Based on Aligning Operation,” Proc. Pacific Rim Conference on Multimedia, 2016, pp. 418-427.
[24] Recommendation ITU-R BS.1534-3, “Method for the subjective assessment of intermediate quality levels of coding systems”. Proc. International Telecommunications Union, 2015, Switzerland.

- China Communications的其它文章
- A Privacy-Based SLA Violation Detection Model for the Security of Cloud Computing
- Empathizing with Emotional Robot Based on Cognition Reappraisal
- Light Weight Cryptographic Address Generation (LWCGA) Using System State Entropy Gathering for IPv6 Based MANETs
- A Flow-Based Authentication Handover Mechanism for Multi-Domain SDN Mobility Environment
- An Aware-Scheduling Security Architecture with Priority-Equal Multi-Controller for SDN
- Homomorphic Error-Control Codes for Linear Network Coding in Packet Networks