
我国网络舆情热点话题发现研究综述
2017-04-07 23:09游丹丹陈福集
现代情报 2017年3期
游丹丹+陈福集


〔摘要〕随着互联网的快速发展,网络舆情对社会的影响不容忽视。若能够及时从海量数据中发现热点话题,追踪热点话题演变以及预测话题的倾向,对于帮助相关部门及时有效地对其引导和控制具有较大意义。本文通过对我国网络舆情热点话题发现的相关文献进行收集、整理及分析,归纳其中的主要研究思想和方法,同时发现存在的不足,并提出进一步的展望,以期对后来研究者提供参考。
〔关键词〕网络舆情;热点话题发现;发现模型;综述
DOI:10.3969/j.issn.1008-0821.2017.03.029
〔中图分类号〕G2062〔文献标识码〕A〔文章编号〕1008-0821(2017)03-0165-07
〔Abstract〕With the rapid development of the Internet,the impact of network public opinion on society can not be ignored.If we can timely find the hot topic,track the evolution of hot topics and predict the tendency of hot topics,it will be of great significance to help the relevant departments guide and control the development of network public opinion.The paper studied and reviewed the related literatures of the hotspot topic detection of network public opinion in China,analyzed and summarized the main ideology,key technology and existing problems,besides,gave the working directions of next steps.
〔Key words〕network public opinion;hotspot topic detection;detection models;review
随着互联网的快速发展,网络信息交互与传播迅速且敏捷,网络中重要的信息常淹没在海量数据中,因此如何有效地从不断涌现的海量非结构化数据中发现热点话题、追踪热点话题演变以及预测话题的发展倾向,为相关单位部门及时提供有效网络舆情信息、舆情监控和竞争情报具有较大意义。
本文在文獻调研的基础上,对我国网络舆情热点话题发现的相关文献进行统计分析和回顾整理。然后从数据采集、文本处理以及热点话题发现模型等方面对现有研究进行整理归纳,意在发现网络舆情热点话题发现中有待解决的难点,以期为未来深入研究奠定基础,最后分析总结网络舆情热点话题发现研究中存在的问题与不足,并指出下一步的展望方向。
1文献统计及分类
为了充分掌握我国网络舆情热点话题发现研究的现况,截至2016年6月对中国学术期刊网CNKI、万方学位论文期刊网以及维普等数据库进行检索搜集,采用“微博”、“舆情”、“网络”、“论坛”与 “热点话题发现”关键字组合作为检索条件进行模糊搜索,检索2005-2016年期间的相关文献。检索命中135条,其中期刊论文64篇,学位论文66篇,会议论文5篇。从图1可以看出,从2007-2014年,网络舆情热点话题发现研究的相关文献逐年增多,2014年相关文献数量达到高峰,近两年有所减少。随着互联网的迅速壮大,网名规模的持续扩大,网络舆情事件的不断爆发,相关部门对网络舆情的监控越来越加大重视力度,并且随着相关研究不断深入,学术成果不断呈现。
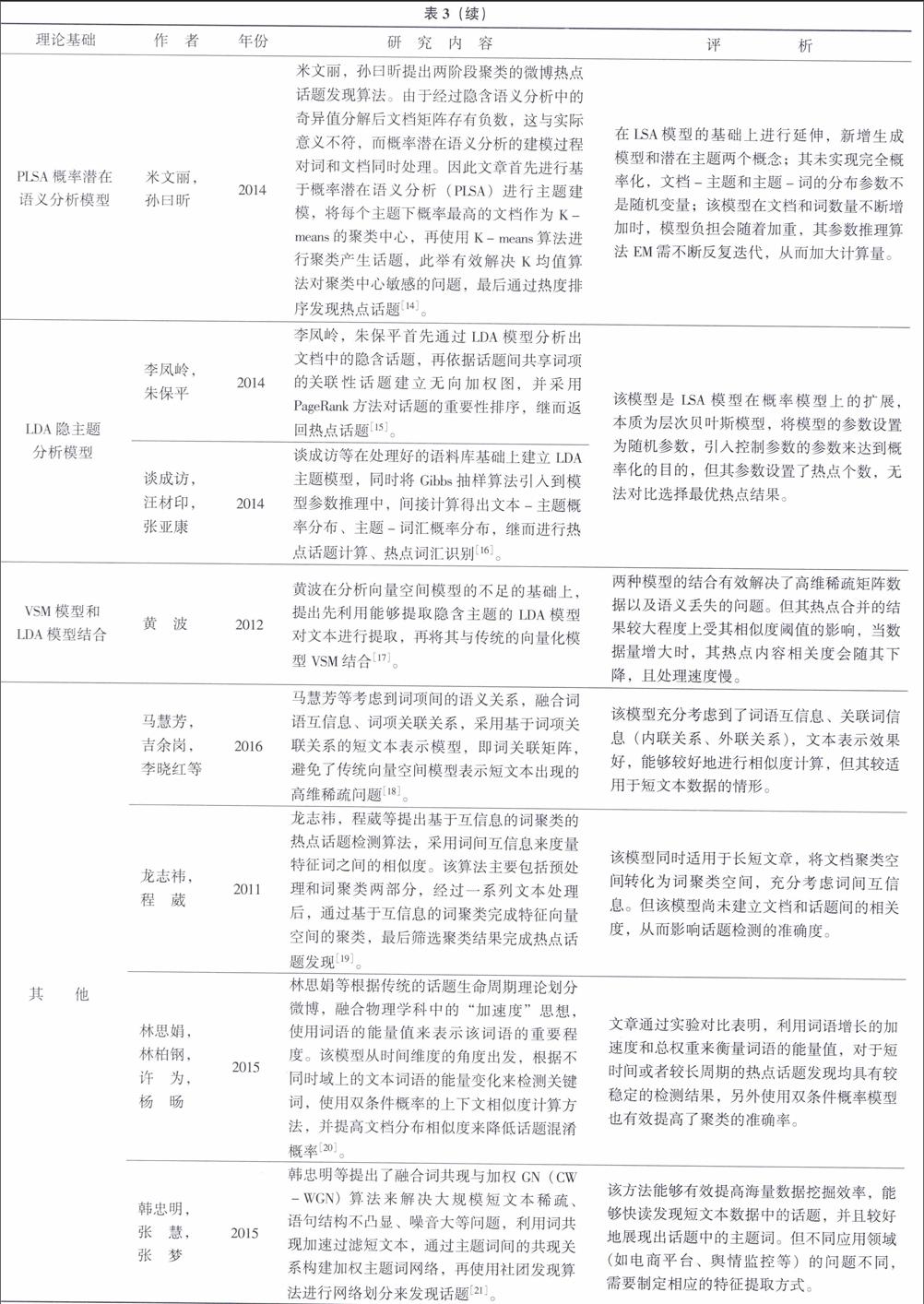
2我国网络舆情热点话题发现分析
21热点话题发现研究路线
热点话题指的是在某个时间段内人们比较关注的话题,涉及民生、政治、经济以及文化等方面。网络舆情热点话题发现过程一般遵循数据采集、数据处理以及话题识别3个大步骤,具体流程如图2所示。
22热点话题数据采集
作为网络舆情热点话题发现的前提,数据采集是网络舆情热点话题发现的重要一部分,主要通过数据采集工具,对目标站点的数据进行监测和数据采集。目前数据源主要来自微博、新闻网站、论坛以及相关网页等。从数据采集方式上,目前主要是采用网络爬虫技术从互联网中抓取下来。从网络爬虫的功能和结构上分类,可分为通用类型的网络爬虫、专用型的网络爬虫以及增量型网络爬虫[1]。关于网页信息抽取技术,大体上分为基于DOM树的抽取方法、基于统计的抽取方法以及基于模板的抽取方法。
孙胜平提出基于时间判断的广度优先网页采集技术,在网页采集流程中添加时间分析器来判断页面内容的时效性,从而决定是否对该页面进行广度采集,避免了采集无用信息,提高了采集效率和覆盖率[2]。罗磊针对微博信息在内部传播时易于扩散至其他新媒体,提出基于改进的Shark-Search的主题扩散跟踪方法,通过主题爬虫参数来逆向测评主题在网络中的密度,另外对主题爬虫算法进行修改,解决在短期小规模搜索时易陷入粘滞状态的问题[3]。衣波在分析网络舆情数据的主要来源和抓取模块中的网络爬虫的基础上,对开源网络爬虫进行改进,采用多个哈希码映射弥补原算法高内存消耗的不足,从而提高内存的利用率,以及在一定程度上减少误判率[4]。
23文本处理
231文本分词
采集的数据经过数据清洗后,进行文本分词、词性标注、识别命名实体、特征选择等数据处理步骤,进而建立文档表示模型,最后进行热点话题发现与更新。
其中目前比较常用的分词方法有基于词典匹配、基于理解以及基于统计3种[5]。以下表1对3类方法优缺点进行简单归纳[6]。
232文本表示
文本表示指的是将文本转换为电脑可识别的结构化形式的过程。目前比较常见的文本表示模型有向量空间模型、概率模型以及布尔模型[7]。其中向量空间模型应用最为广泛。向量空间模型经过不断改进,常见的VSM扩展模型有广义向量空间模型(GVSM)、潜在语义标引、概率向量处理模型以及基于语义分析的向量空间模型(SVSM)等。三大类模型优缺点归纳如表2所示,常见的文本表示应用模型归纳如表3所示。
24热点话题发现模型
热点话题发现的核心部分实质上是文本聚类的过程,不同的聚类算法对应不同的有效性。从聚类内容上看,可大致分为基于词、基于内容以及基于信息3个角度;从聚类方法上来看,目前比较常见的具聚类算法有:基于划分、层次、密度、网格及其他聚类算法,归纳如表4所示。
在热点提取方面,比较常见的有基于改进的聚类算法、多层次聚类、遗传算法、粒子群算法等模型。按照时间顺序对收集的相关文献的主要研究内容进行简单归纳列举,如表5所示。
3研究结论及展望
31研究中存在的不足
通过对现有网络舆情热点话题发现的研究进行分析归纳,尚存在以下几点不足:
1)微博是全中国主流、具人气以及较火爆的互联网产品,平台上具有较为全面、及时的中文资讯,因此常被学者们作为网络舆情热点话题发现研究的数据采集源。微博中网络用语呈现较大随意性、碎片化、语言非结构化等特点,导致分词准确率受影响,使得热点话题发现受一定程度的影响。
2)虽然目前关于网络舆情热点话题发现的研究比较多,其中的方法和模型也比较成熟,但是比较系统、成体系的网络舆情热点话题发现应用不是很多,从数据采集、热点话题发现以及话题追踪的整套解决方案较少。
3)另外,针对数据采集的专门研究较为缺乏,大多文献侧重文本挖掘研究,大多聚类算法只针对较单一类型的数据,较少的文献关注到数据源中的图片、音频以及视频等的数据采集。而现实中的数据多是混合数据类型的数据,而简单的忽略其中的一种数据类型或者转换为同种数据类型都会影响话题发现的准确率。
32研究展望
通过对网络舆情热点话题发现的相关文献进行总结,本文认为接下来可从以下几方面改进:
1)分词的准确性直接影响到主题分析的准确性,目前在中文分词上,基于词典匹配的机械分词方法和基于统计的分词方法比较成熟,其二者结合使用也可使分词达到较好的效果,但基于语义的分词是较为理想的分析方法,如专家系统分词、神经网络分词等,这也是未来发展的方向。
2)在数据采集方面,大数据背景下数据呈爆发式增长,海量数据的抓取分析会使得热点话题发现更为精确。而当今大数据存储和分析的主流技术Hadoop是解决这一问题有效途径,采用基于API和结构树网页正文抽取解析结合的方案,可实现海量数据的高效处理和深度并行化的分析。另外,在数据预处理方面,当前的海量数据大而杂乱,对数据进行有效的去噪处理页是提高聚类效果的关键所在。
3)热点话题发现的重要部分在于聚类,其聚类结果的准确性直接影响热点话题发现的准确度,在尽量减少聚类所需时间的同时,保证聚类的精确度也是重点。另外,在面对动态变化的数据时,传统的聚类方法效率较低,应提高聚类动态数据的效率。
参考文献
[1]陈震.基于云平台的网络新闻热点话题检测与发现[D].北京:北京邮电大学,2013.
[2]孙胜平.中文微博客热点话题检测与跟踪技术研究[D].北京:北京交通大学,2011.
[3]羅磊.微博舆情热点检测与跟踪方法研究[D].杭州:杭州电子科技大学,2013.
[4]衣波.网络舆情信息的话题发现和追踪技术的研究与应用[D].广州:广东工业大学,2013.
[5]冯颖.网络舆情敏感话题发现平台的研究[D].北京:北京交通大学,2009.
[6]中文分词技术(中文分词原理)[EB/OL].http:∥www.cnblogs.com/flish/archive/2011/08/08/2131031.html,2011-08-08.
[7]夏立新,金燕,方志,等.信息检索原理与技术[M].北京:科学出版社,2009:21-37.
[8]王娟琴.三种检索模型的比较分析研究:布尔,概率,向量空间模型[J].情报科学,1998,16(3):225-230.
[9]刘奕群.搜索引擎技术基础[M].北京:清华大学出版社,2010.
[10]张海东.基于论坛的热点话题识别与趋势预测研究[D].上海:上海师范大学,2015.
[11]王巍,杨武,齐海凤.基于多中心模型的网络热点话题发现算法[J].南京理工大学学报,2009,33(4):422-426.
[12]马雯雯.基于隐含语义分析的微博热点话题发现策略[D].重庆:重庆大学,2013.
[13]吴妮,赵捧未,秦春秀.基于语义分析和相似强度的微博热点发现方法[J].现代图书情报技术,2015,31(5):57-64.
[14]米文丽,孙曰昕.利用概率主题模型的微博热点话题发现方法[J].计算机系统应用,2014,(8):163-167.
[15]李凤岭,朱保平.基于LDA模型的微博话题发现技术研究[J].计算机应用与软件,2014,(10):24-26.
[16]谈成访,汪材印,张亚康.基于LDA模型的中文微博热点话题发现[J].宿州学院学报,2014,29(4):71-73.
[17]黄波.基于向量空间模型和LDA模型相结合的微博客话题发现算法研究[D].成都:西南交通大学,2012.
[18]马慧芳,吉余岗,李晓红,等.基于离散粒子群优化的微博热点话题发现算法[J].计算机工程,2016,42(3):208-213.
[19]龙志,程葳.基于词聚类的热点话题检测算法[J].计算机工程与设计,2011,32(6):2214-2216.
[20]林思娟,林柏钢,许为,等.一种基于词语能量值变化的微博热点话题发现方法研究[J].信息网络安全,2015,(10):46-52.
[21]韩忠明,张慧,张梦,等.大规模短文本的快速话题发现方法与评价研究[J].计算机应用研究,2015,32(3):717-722.
[22]丁若尧.基于博客的网络话题发现及追踪的研究[D].北京:北京交通大学,2011.
[23]税仪冬,瞿有利,黄厚宽.周期分类和Single-Pass聚类相结合的话题识别与跟踪方法[J].北京交通大学学报,2009,33(5):85-89.
[24]方星星,吕永强.基于改进的single-pass网络舆情话题发现研究[J].计算机与数字工程,2014,(7):1233-1237.
[25]杨长春,周猛,叶施仁,等.基于改进CURE算法的微博热点话题发现[J].计算机仿真,2013,30(11):383-387.
[26]路荣,项亮,刘明荣,等.基于隐主题分析和文本聚类的微博客中新闻话题的发现[J].模式识别与人工智能,2012,25(3):382-387.
[27]馬雯雯,魏文晗,邓一贵.基于隐含语义分析的微博话题发现方法[J].计算机工程与应用,2014,50.
[28]杨菲,黄柏雄.词共现网络的遗传聚类在话题发现中的应用[J].计算机工程与应用,2013,49(14):126-129.
[29]马慧芳,吉余岗,李晓红,等.基于离散粒子群优化的微博热点话题发现算法[J].计算机工程,2016,42(3):208-213.
[30]黄敏.网络舆情热点挖掘算法研究与实现[J].安徽大学学报:自然科学版,2012,36(6):67-72.
[31]杨亮,林原,林鸿飞.基于情感分布的微博热点事件发现[J].中文信息学报,2012,26(1):84-90.
(本文责任编辑:郭沫含)
猜你喜欢
石油沥青(2018年6期)2018-12-29
NBA特刊(2018年21期)2018-11-24
电子制作(2018年14期)2018-08-21
大学教育(2016年11期)2016-11-16
经营者(2016年12期)2016-10-21
今传媒(2016年9期)2016-10-15
功能高分子学报(2016年1期)2016-04-26
法医学杂志(2015年2期)2015-04-17
江苏年鉴(2014年0期)2014-03-11
