
LDA模型在专利文本分类中的应用
2017-04-07 16:18廖列法勒孚刚朱亚兰
现代情报 2017年3期
廖列法+勒孚刚+朱亚兰


〔摘要〕对传统专利文本自动分类方法中,使用向量空间模型文本表示方法存在的问题,提出一种基于LDA模型专利文本分类方法。该方法利用LDA主题模型对专利文本语料库建模,提取专利文本的文档-主题和主题-特征词矩阵,达到降维目的和提取文档间的语义联系,引入类的类-主题矩阵,为类进行主题语义拓展,使用主题相似度构造层次分类,小类采用KNN分类方法。实验结果:与基于向量空间文本表示模型的KNN专利文本分类方法对比,此方法能够获得更高的分类评估指数。
〔关键词〕LDA;主题模型;专利文本分类;主题相似度
DOI:10.3969/j.issn.1008-0821.2017.03.007
〔中图分类号〕G25553;G2541〔文献标识码〕A〔文章编号〕1008-0821(2017)03-0035-05
〔Abstract〕A new text classification method based on LDA model is proposed to solve the problem of traditional VSM text categorization.The LDA topic model was used to model the patent text corpus,and the document-topic and topic-feature word matrix of the patent text was extracted to achieve the purpose of dimension reduction and to extract semantic links between documents.The class-topic matrix was introduced,Topic semantic extension,hierarchical classification using theme similarity,and KNN classification by subclass.Experimental results:Compared with the KNN patent text classification method based on vector space text representation model,this method can obtain higher classification evaluation index.
〔Key words〕LDA;topic model;patent text classification;topic similarity
根据2016年世界知识产权组织(WIPO)在日内瓦总部发布的《世界知识产权指标》年度报告显示,2015年中国国家知识产权局受理的专利申请数量超过110万件,相当于美国、日本和韩国的专利申请数量总和。从全球排名来看,中国位居首位;美国居于第二,数量为589万件;日本第三,数量为318万件。我们国家实施创新驱动发展战略,对于科研人员的科技成果转化方面的激励和科技创新企业的纳税政策优惠等都有效地推动了专利申请数量的提升。面对如此海量的专利文献数据,仅仅依靠工作人员采用传统的手工分类不仅效率低下,而且人力和物力资源耗费量巨大。因此,专利文献的自动分类方法研究显得极为重要和迫不及待,它已成为科研人员现阶段一个研究热点和重点[1]。与一般的文本相对,专利文本具有结构特殊、专业性强、领域词汇较多等特点,因此相对传统的文本分类而言,专利文本需要采用更加针对的分类方法[2]。
在文本分类中,文本的表示直接影响到特征值的选取,好的特征值选取方法可以有效提高分类方法的效率,目前的专利文本分类方法的文本表示都是基于向量空间模型(Vector Space Model,VSM)算法[3],并没有涉及概率主题模型。例如:李程雄、丁月华和文贵华[4]提出并分析结合SVM算法和KNN算法的组合改进算法SVM-KNN,当样本和SVM最优超平面的距离大于给定的阙值,即样本离分界面较远,则用SVM分类,反之用KNN算法对测试样本分类,比单一的算法取得了更优的分类效果。蒋健安、陆介平、倪巍偉等[5]设计的层次分类算法先采用Rocchio算法进行专利大类的区分,再对各个大类之间的文本采用KNN方法进行小类的细分,由于大类之间的区分度较大,故可以使用Rocchio算法,而相同大类之间的小类分别较小,采用KNN算法更能区分。郭炜强、戴天、文贵华[6]根据改进的词语权重计算方法构造给定文本的特征向量,从分类表IPC中直接提取类别的概念向量和待分类专利文本的特征向量,然后采用向量空间模型实现专利的自动分类。
结合计算机语言学,概率空间模型在文本表示上具有更加优异的效果,能够提取变现力更强的特征词汇,能使文本的分类效果更好。则概率空间模型代替词向量模型运用在文本表示中是一种趋势,故本文提出一种基于LDA(Latent Dirichlet Allocation)模型[7]的专利文本分类方法,LDA模型是符合文本生成规律的全概率生成模型,具有好的文本表示能力,提取具有语义信息的主题,运用在专利文本分类中,能够有效提升分类效率。
31向量空间模型用于专利文本分类的不足分析[8]
在对专利文本进行分类时,文本表示一般采用向量空间模型算法,该算法把对文本内容处理简化为向量空间中的向量运算。在向量空间模型中,文档被映射成由向量组成的多维向量空间,其中每个词表示1个维度。假设向量的空间维数为n,则每篇文档d映射为由二元组组成的特征向量V(d)=(t1,w1(d);…tn,wn(d)),其中ti(i=1,2,…,n)为一列互不相同的特征词,wi(d)为特征词ti在文档d中的权重。传统的特征词权重计算普遍采用TF-IDF算法[9],TF-IDF算法考虑了特征词的词频、逆文本频、归一化等因素,这些都是文本权重计算中很重要的概念。
但是,在专利文本自动分类中,该算法在处理专利数据时有二个明显的不足:
1)向量空间模型是依据语料库中的特征词,使用TF-IDF算法计算它们的权重,构造文档-特征词向量,并将整个文档集构造为一个高维、稀疏的特征值-文档矩阵。其中模型的对向量的维数难以控制,语料库特征词越多则矩阵维数越高、越稀疏,矩阵的高维稀疏使得实际用来计算的数值很少,大部分数值都为0,增加了算法的计算开销,降低了算法的效率。维数过大对于算法的产生巨大的计算量,时间和空间复杂度会提高。
2)对于专利的分类,不仅要考虑专利词汇上的相似性,还要考虑专利的语义内容上的相似性。由于专利文本中使用的词汇都比较专业化,因此产生的词汇集相对比较狭窄,产生的专利文本在词集上会有很多的相似,而VSM模型是根据词的频率及逆文本频来计算特征词的权重,并不能很好的对文本进行区分,所以基于VSM模型的专利文本分类方法的效果很差。应该考虑特征词间的语义联系,及特征词与类的关联,从专利文本所表达的语义层面上去理解文本,在语义层面上对专利文本进行分类,这样才能取得更好的分类效果。
基于上面的两种问题,传统的基于VSM模型的专利文本分类方法已经不能很好地应用在专利文本分类中了。
2LDA主题模型
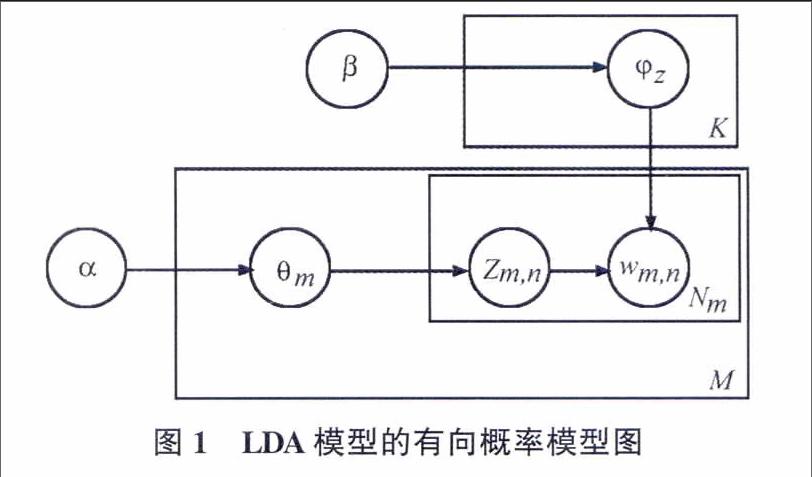
LDA模型是一种对文本数据进行有效降维和发掘潜藏主题信息的方法[10]。它是一个三层贝叶斯概率生成模型,把文档表示成隐含主题的概率分布,主题表示成词汇的概率分布,其中主题是对文档内容的汇集,因此模型可以很好地模拟大规模语料的语义信息。模型的把文档由主题构成,而主题的数量是一定的,对文档具有良好的降维能力。LDA的概率模型图如图1所示:
LDA模型的生成过程较好地模拟了在生成实际文本的大体思维过程,其具体的数学化描述如下:
1)对每一篇文档dm,根据N~Poisson(ξ)生成文档dm中词的数目Nm;
2)对于每一篇文档dm,根据θm~Dir(α)生成文档dm关于主题多项式分布的参数θm;
3)对于每一个主题z,根据φz~Dir(β)生成主题z关于语料库中词多项式分布的参数φz;
4)对于文档dm的第n个词wm,n:
a)根据多项式分布zm,n~Multi(θd),抽样得到词wm,n所属的主题zm,n;
b)根据多项式分布wm,n~Multi(φz),抽样得到具体的词wm,n。
参数估计是LDA模型的关键步骤,假如要直接计算LDA模型的参数是不能实现的,需要使用间接推理算法来估算模型的参数值,LDA模型常用的算法有Gibbs抽样、EM算法、Expectation-Propagation方法、变分推理算法等。其中因为Gibbs抽样算法具有快速、高效等优点,故常被用于LDA模型的参数估算。
Gibbs抽样算法详述如下:
1)初始化。zi被初始化为1到K之间的某个随机整数。i从1循环到N,N是语料库中所有出现于文本中的词汇记号个数。
2)迭代。i从1循环到N,根据公式(1)将词汇分配给主题,获取Markov链的下一个状态。
3)估算φ和θ的值。迭代第(2)步足够次数以后,认为Markov链已经接近目标分布,遂取zi(i从1循环到N)的当前值作为样本记录下来。为了保证自相关较小,每迭代一定次数,记录其他的样本。舍弃词汇记号,以w表示惟一性词,对于每一个单一样本,可以按下式估算φ和θ:
3基于LDA模型的专利文本分类算法
31确定语义主题数
LDA模型要进行Gibbs抽样就要先确认所有的参数,但是主题参数事先无法确定的,而主题数的多少对模型的影响非常大,主题数目过多,将会产生很多不具有明显语义信息的主题,反之数目过少将会出现一个主题包含多层语义信息的状况,两种状况都很糟糕,所以科学的确定主题的个数非常重要。本文采用LDA标准的评价函数Perplexity(困惑度)来确定最优主题数。
困惑度衡量主题模型对于未观测数据的预测能力,困惑度越小,模型预测能力越强,模型的推广性越高。其中:Dtest为测试集;wd为文档d中的可观测单词序列;Nd为文档d的单词数目。困惑度公式如下:
32文档的主题向量提取
对于专利文本数据,有意义的文本内容是标题、摘要、主权项,而标题中出现的特征词往往更具有代表性,其次是摘要。在不同位置的特征词对文档的贡献程度是不同的,假如直接利用LDA模型对语料库建模,不考虑特诊词汇在文档中的位置信息对该文本的区分度影响,将严重影响文本的分类效果。故结合专利文本数据的结构特殊性,体现特征词汇的位置信息因素,使用一种位置加权来计算文本的主题向量。将标题、摘要和主權项分为3篇文档,即一篇专利文献包含3个子文档,定义为一个三元组D=D(P1,P2,P3),其中P1表示标题,P2表示摘要,P3表示主权项,将3篇子文档中的主题向量按位置权重计算,从而得到该专利文档的主题向量,其中θP1表示标题文档的主题向量,θP2表示摘要文档的主题向量,θP3表示主权项的主题向量,计算公式如下:
33类-主题矩阵
LDA模型将文档表示成三层模型,即文档层、主题层和词汇层,文档由主题向量构成,主题由词汇向量构成,从而对文档进行降维表示。根据已有的LDA模型讨论:文档集是由各种类别的文档组成,文档集和类别之间存在一对多映射关系,类别和文档之间也存在一对多映射关系,可理解为类别就是一个子文档集,由主题和文档的关系,用主题向量对子文档集降维,即类和隐含主题之间存在着一定的概率分布,向标准的LDA模型中添加一层即文档类别层。类的隐含主题信息拓扑结构如图2所示:
从带类别标签训练文档的文档-主题矩阵中提取类-主题矩阵。把带相同类别标签的文档建立成一个文档-主题矩阵,计算这个矩阵每列的平均值,得到该类的类-主题向量,所有的类-主题向量构成类-主题矩阵。其中γci表示类别c关于主题i的概率,M表示关于类别c的文档数,θmi是类别c中第m篇文档关于主题i的概率,计算公式如下:
在上面的公式中,若主题i在c类文档中出现的概率高,则表示这一隐含主题对于类别i具有强表现性,在类间具有较强的类别区分能力,概率较小的主题,则表示与该类具有弱变现性,与该类的关联程度较低。
34基于LDA模型的专利文本分类算法
专利分类拥有一套国际专利分类体系(简称IPC分类),它是我国常用的分类体系,IPC分类[11]号包括了与发明创造有关的全部知识领域。IPC分类号采用层级的形式,将技术内容注明:部-分部-大类-小类-大组-小组,逐级形成完整的类别体系。故需要对专利文本进行层次分类,部属于专利分类的最高级,属于不同学科领域,较好分类,大类属于同一学科里的不同方面,类别区分难度一般,故部和大类的分类都采用类间相似度构造分类器进行分类;而小类属于同一技术的不同研究方向,较难区分,故采用普遍认为具有高分类性能的KNN方法。
具体的算法步骤描述如下:
输入:带类别标记的训练文本集,测试文本
输出:测试文本的所属类别
步骤1:获取专利文本数据,并将文本分为训练文本集和测试文本集。
步骤2:对训练文本和测试文本进行预处理,包括:分词、去停顿词,及使用TF-IDF算法对词汇过滤,将权重小于01的词除去,建立训练文本的语料库。
步骤3:利用LDA模型对语料库建模,提取语料库的文档-主题和主题-词汇矩阵。
步骤4:根据带标签的文档-主题矩阵提取部-主题矩阵和大类-主题矩阵。计算每一篇待测试专利文本的主题与各个部和类别主题间的相似度,相似度度量采用余弦相似度算法来计算。其中Cz为类别的主题向量,θz为测试文档的主题向量。计算公式如下:
步骤5:部。将待分类文档与各部的部-主题向量计算相似度,相似度最大的为文本所属部号。
步骤6:大类。将具有部号的待分类文本与本部的各大类计算主题相似度,其中相似度值最大的为文本所属大类。
步骤7:小类。对确定大类的文本与属于该大类的训练文本计算主题相似度,KNN分类方法确定该专利所属小类。
步骤8:实验结果评价。
具体专利文本分类算法基本框架如图3所示:
4实验及结果分析
41实验数据集
为验证此方法的有效性,本文利用从专利局获取的稀土专利数据进行实验。实验数据集包含2007-2015年共31 000篇稀土专利文本,每个部选取大类和小类数量较均匀的1 000篇专利文档进行训练和测试,实验将数据集的80%用来训练模型,20%用来验证分类算法性能。数据具体分布情况见表2。
42评估指标
文本分类性能结果的评估指标采用F值。F度量值是信息检索中的一种组合P(准-确率)和R(召回率)指标的平衡指标。计算公式如下:
F的值越与1靠近说明P和R的平衡性越好。相反F的值与0越靠近,则两个参数的平衡性越差。
43参数设定
在LDA建模过程中,确定最优主题数采用Perplexity函数,参数估计采用MCMC方法中的Gibbs抽样算法,在LDA建模过程中,根据经验设置α=50/K、β=001,Gibbs抽样的迭代次数参数Iteration为2000,保存迭代参数Save Step为1000。其中主题数K的取值依次为5、10、25、50、100直到200,利用不同的主题数进行Perplexity函数分析,获得最小困惑度得到最优主题数K。
从图4看出,随着主题数目的增加,模型的困惑度值慢慢收敛到一个较小较稳定的值,在图中可以发现当主题数K=100时模型的困惑度值开始最小且平稳,则此时模型的性能最好,所以本实验的主题数目取值为100。
44实验结果分析
实验分两组进行,第一组采用基于向量空间模型的专利文本分类方法,首先采用向量空间模型表示文本,然后运用TF-IDF计算特征值的权重,最后采用KNN方法分类;第二组采用本文提出的基于LDA模型的专利文本分类方法,首先运用LDA方法对语料库建模,提取各文档、部和类的主题分布,然后部和大类的分类采用相似度构造分类器,计算主题相似度,最后小类的分类采用KNN分类方法。实验分词采用的是基于R软件Rwordseg包segmentCN分词方法。实验结果见表3、表4和图5。
由实验结果可以得知,基于LDA模型的分类方法在正确率、召回率和F值方面均优于基于VSM模型的分类方法,故基于LDA模型的专利文本分类方法是有效的,大大提高了专利文本的分类效率。
5结语
本文主要从文本表示方向对专利文本分类进行改善。
将LDA主题模型应用到专利文本分类中,使得文档和类由低维具有语义汇集的主题向量表示,达到了较好的降维效果,并引入类-主题矩阵用于文本分类,有效提高分类准确性,使模型的分类性能更加优越。本文运用LDA模型专利文本分类时,存在专利文本的标题文本过短的问题,本文并没有考虑到,下一步工作将结合短文本的特性设计更优的分类方法,进一步提高专利文本分类效率和分类精度。
参考文献
[1]屈鹏,王惠临.专利文本分类的基础问题研究[J].现代图书情报技术,2013,(3):38-44.
[2]刘红光,马双刚,刘桂锋.基于机器学习的专利文本分类算法研究综述[J].图书情报技术,2016,(3):79-86.
[3]庞剑锋,卜东波.基于向量空间模型的文本自动分类系统的研究与实现[J].計算机应用研究,2001,18(9):23-26.
[4]李程雄,丁月华,文贵华.SVM-KNN组合改进算法在专利文本分类中的应用[J].计算机工程与应用,2006,42(20):193-195.
[5]蒋健安,陆介平,倪巍伟,等.一种面向专利文献数据的文本自动分类方法[J].计算机应用,2008,28(1):159-161.
[6]郭炜强,戴天,文贵华.基于领域知识的专利自动分类[J].计算机工程,2005,31(23):52-54.
[7]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of machine Learning research,2003,3(1):993-1022.
[8]胡冰,张建立.基于统计分布的中文专利自动分类方法研究[J].现代图书情报技术,2013,(Z1):101-106.
[9]施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009,29(s1):167-170.
[10]姚全珠,宋志理,彭程.基于LDA模型的文本分类研究[J].计算机工程与应用,2011,47(13):150-153.
[11]缪建明,贾广威,张运良.基于摘要文本的专利快速自动分类方法[J].情报理论与实践,2016,(8):103-105.
(本文责任编辑:孙国雷)
