
面向智慧民生领域的增量交互式数据集成方法
2017-04-07 07:01王亚沙赵梓棚
计算机研究与发展 2017年3期
夏 丁 王亚沙 赵梓棚 崔 达
1(高可信软件技术教育部重点实验室(北京大学) 北京 100871)2(北京大学信息科学技术学院 北京 100871)3 (软件工程国家工程研究中心(北京大学) 北京 100871) (fabkxd@foxmail.com)
面向智慧民生领域的增量交互式数据集成方法
夏 丁1,2王亚沙1,3赵梓棚1,2崔 达1,2
1(高可信软件技术教育部重点实验室(北京大学) 北京 100871)2(北京大学信息科学技术学院 北京 100871)3(软件工程国家工程研究中心(北京大学) 北京 100871) (fabkxd@foxmail.com)
智慧民生作为智慧城市的重点领域,包含众多应用系统,积累了大量层次结构数据.为了形成城市范围完整数据集,需要集成并统一异构的数据模式,向用户提供统一的数据视图.针对智慧民生领域的领域知识宽泛、缺乏中文语义匹配支持、模式数量众多、元素标签缺失但实例数据丰富等几方面特点,提出了一种增量交互式模式集成方法.该方法采用增量迭代的方式逐步完成多模式集成任务,大幅降低集成计算量;在模式匹配阶段,综合利用模式信息和实例数据构造了多种适用于中文且能力互补的匹配器,并通过相似度熵来度量机器的决策置信度,适度引入人工干预;在中介模式生成阶段,处理模式间可能出现的各种冲突,最终输出全局统一的中介模式.利用从互联网爬取的多源二手房数据设计并完成实验,实验结果表明:此方法在人工干预程度足够小的前提下,具有较好的模式匹配准确性.
模式匹配;模式集成;数据集成;智慧城市;智慧民生
智慧民生是智慧城市建设的重要领域,涉及服务于市民“衣、食、住、行”等生活服务的众多应用系统.这些应用在向市民提供服务的同时,积累了大量的数据,层次结构数据占这些数据的主体部分.典型的层次结构数据包括:在Web应用中广泛使用的XML文档,以及在系统后台普遍使用的关系型数据等.通常单一应用系统中的数据并不完整,只有充分集成多个系统中的数据才能形成整个城市范围内较为全面的数据集,以满足智慧城市中集成化、智能化的应用的需求.以二手房交易领域为例,目前在中国城市中应用较多的二手房交易信息交流平台众多,包括:专业二手房交易平台(如链家、安居客、我爱我家、搜房网、爱屋吉屋、房通网等)、本地生活服务类网站(如赶集网、58同城、百姓网等)以及城市本地论坛(如新浪乐居、西祠胡同房产、大量以城市名称命名的本地综合论坛等).这些系统中都包含大量待售二手房的数据,然而单一系统中的数据都不完整.某个城市中,有购房需求的市民,往往需要逐一浏览多个系统,并人工实现数据的集成,才能对此城市中二手房的信息有较为全面的了解,效率很低.另外,城市管理规划部门或市场调研机构,若要对某城市二手房交易情况进行调研分析,也必须从多个系统获取数据并实现数据的集成.
源自不同系统的数据往往具有不同的数据模式(data schema),要实现数据的集成,必须首先为来自不同系统的数据构造一个全局、统一的数据模式,即实现数据模式的集成(schema integration).传统的模式集成技术[1-5]的典型应用场景包括:电子商务领域的产品目录等数据模式的演化、公司并购过程中的数据系统集成等.这些场景中,待集成的源数据模式个数较少,结构较为规范,预置的领域知识较为丰富,相较而言,智慧民生领域的数据存在3个特征:
1) 领域范围宽泛,缺乏解决术语语义匹配的支持机制.智慧民生领域尚缺乏数据相关标准,模式元素标签所使用的术语差异巨大.例如二手房数据中,关于交易中介人就存在“代理”、“经纪人”、“顾问”、“秘书”、“管家”等10余种同义词.由于民生领域涉及市民生活的方方面面,范围十分宽泛,如果试图建立领域词典或知识库来解决元素标签的语义匹配问题,工作量巨大,且难以在短期内完成.而现有的通用知识库均以英文为主,对中文支持不足.已有的基于字符串的模式匹配算法,如公共前缀长度、公共后缀长度、编辑距离等,也无法适用于中文标签.
2) 模式数量众多,传统集成方式效率低.智慧民生领域中需要集成的数据源众多.以二手房领域为例,对普通大中型城市而言,包含本城市二手房数据的信息系统超过20个.传统的两两模式集成方式,要求每个已知源模式或者新加入的源模式都要与其他源模式进行1次集成,这种处理方式的复杂度与源模式数量的平方成正比例,且可扩展性不好,效率太低.另外,传统的模式集成中,部分工作会引入人工参与以解决算法难以判定的元素匹配和冲突解决问题.在模式数量大幅增加的情况下,何时选择人工参与的标准必须严格控制,否则将导致大量的人工任务,从而导致方法效率降低和成本的增加.
3) 模式元素标签部分缺失,而实例数据较为丰富.智慧民生领域待集成的数据很多都是从互联网抓取的Web表格,存在部分模式元素标签缺失的情况,这是传统的元素级别匹配算法效果不佳的另一个重要原因.而另一方面,实例数据是比较丰富的,可以通过对实例数据的分析辅助模式匹配.然而,进一步分析表明不同系统中数据源的实例数据并不是完全的重合,例如:某些在链家网上发布房源的房主并不会同时将房源发布在我爱我家网上.因此通过数据实例的重复度来判断元素之间的相似性也是不够准确的.
本文针对以上问题,结合民生领域数据特征以及传统的模式匹配技术和模式集成技术,提出并实现了一种“面向智慧民生领域层次结构数据的增量交互式模式集成方法”.该方法采用增量迭代的方式,每次集成2个模式,并将集成的结果表达为中介模式,后续集成基于前序集成的结果进行,在源模式数量较多的情况下,大大减少了源模式间集成的次数;而在每一次集成迭代内部,通过元素聚类等预处理工作,大大缩小元素匹配的搜索空间和比对次数,进一步减少了工作量.在模式匹配阶段,针对智慧民生领域数据的特点,综合利用模式信息和实例数据,构造了多种适应于中文处理、且能力互补的匹配器进行元素匹配,并通过计算相似度熵度量候选元素相似度的差异性,仅在差异性不够明显时才引入人工参与,较好地权衡了人工参与工作量和最终结果的准确性.而中介模式生成过程则控制模式中元素遍历的顺序,并处理匹配完成之后源模式间可能出现的各种复杂冲突,综合考虑了效率和中介模式的质量.算法最终的输出是全局统一的中介模式以及各源模式与中介模式元素之间的匹配映射关系.本文利用从互联网爬取的二手房源信息数据设计并完成实验,对本文的数据集成方案的有效性和高效性进行了验证.
1 模式集成技术
模式集成可分解成2部分内容:模式匹配(schema matching)与中介模式生成(mediated schema generation).
1.1 模式匹配技术
模式匹配主要目标是针对2个待匹配的数据模式(称为源模式)中的元素集合S1,S2,构造S1与S2之间的映射M以描述具有相同或相似语义的元素对应关系.模式匹配问题中有多种匹配标准(matching criteria),比如字符串相似性、词汇语义相似性、结构相似性等.能够按照一个既定的匹配标准,独立完成2个元素间相似度计算的算法称为基本匹配器(elementary matcher)[6].基本的模式匹配技术按照所依赖信息的不同,可分为基于模式信息的匹配技术(schema level matching)和基于实例数据的匹配技术(instance data matching).
基于模式信息的匹配技术关注数据模式的元信息,其从匹配粒度的角度,可分为基于元素(element level)与基于结构(structure level)的技术[7].基于元素的匹配算法忽略节点之间的层次结构关系,独立地分析挖掘单个元素对的相似性,又可细分为3类:
1) 基于字符串相似度.计算字符串相似度的算法包括相同前后缀长度[2,6]、编辑距离[1-2,6]和n-gram[1-2]等,这类算法对中文标签的处理效果欠佳;
2) 基于语言学资源的匹配器.这类技术很好地挖掘了字符串背后丰富的语言学涵义,但依赖外部可用的语义知识词典资源[8],如WordNet[9];
3) 基于词共现关联的匹配器.这种模式匹配技术从源模式中节点标签的关联规律来挖掘节点的语义相似性[10-11],能够同时处理大量待匹配源模式,但通用性较差.
基于结构的匹配算法关注包含目标节点及邻近元素的子结构间的相似性,一般将输入的源模式转换为有向图的形式,具体算法包括:
1) 图(树)匹配算法[12-13];
2) 路径匹配算法[3,14];
基于模式信息的匹配技术,算法运行效率较高,但是该技术要求数据模式的元信息完整且仅适用于英文标签,而智慧民生领域的数据中,主要采用中文标签且标签术语使用随意,甚至存在标签缺失的情况,因而导致该技术的匹配准确性难以保障.
基于实例信息的匹配技术直接从数据实例中挖掘模式元素的相似性,可以使用于数据模式元信息不足、缺失或不可靠的应用场景,但同时也会带来较大的系统开销.其从信息提取的角度,可分为基于统计数据和基于内容的方法.基于统计数据的方法忽略实例数据的具体内容,统计元素所有实例的统计特征形成元素的特征向量,然后利用机器学习相关技术来将匹配问题转化为分类问题[16],这种方法由于没有考虑实例的具体内容,准确率较低,但召回率相对较高,且训练速度快,计算效率高;基于内容的方法通过字符串匹配、TF-IDF文档相似度等算法计算实例之间的相似度,然后加权平均得到元素之间的实例相似度[17-18],这种方法的匹配准确率较高,但由于存在实例子集合问题,即2个表达相同概念的元素,其实例都不全面且恰好互补,会导致计算出的相似度偏低,故召回率低,且计算复杂度高.智慧民生领域的多源数据实例丰富,但不同子领域中不同源数据的实例重合度差异明显,因此应该综合基于统计和基于内容2类方法,才能提供稳定的匹配准确性.
1.2 中介模式生成技术
中介模式生成技术一般先利用模式匹配技术确定元素之间的相似度或匹配关系,然后通过制定一系列算法和策略,发现并解决源模式中元素命名、元素定义、元素结构关系不一致等冲突,整合所有源模式的元素,完成中介模式的生成,向数据用户屏蔽模式的异构性[4].中介模式的生成过程中需要解决同义词、数据类型、结点子结构、嵌套路径4类冲突,并针对问题场景制定冲突解决策略[4-5,19-20].另外,除了冲突解决策略,输入源模式的数量也对全局中介模式的构造带来影响.传统的解决方案如XSIQ[4],面向2个源模式,只需要进行1次集成,但当输入的源模式有多个时,直接利用面向2个源模式的技术会导致计算复杂度过高,因此需要设计整体的集成方案.XINTOR[20]是一种基于统计的整体式模式集成技术,它面向多个XML源模式,以元素结构的统计特征为依据,构造中介模式,这种方案效率有所提高,但可扩展性差,新加入的源模式仍然难以处理.另一种思路是以中介模式为媒介,让所有源模式都与中介模式进行集成,这样不仅算法效率提高而且可扩展性也较强.在一些方法[21]中,专家会预先制定一个中介模式,但这种方法在民生领域存在大量不规范同源异构模式的背景下,专家负担太重.实际上若有某种算法可以自动根据所有源模式生成中介模式,完全可以避免这部分人工工作,如PORSCHE[19]就是自动完成中介模式的构建,每次迭代集成1个源模式,同时增量地对中介模式进行更新和扩充,其缺陷体现在模式匹配技术只利用了模式上的信息,准确率有限,而且冲突解决策略简单,部分冲突并没有加以考虑,导致中介模式质量不高.
2 本文方法结构
本文所设计的解决方案框架如图1所示.系统的主要输入是n个源模式的模式信息和实例数据,同时还有专家的人工干预作为辅助输入,主要输出是中介模式.在算法运行过程中,中介模式作为媒介,所有其他源模式依次与中介模式进行匹配和集成,并增量式地更新和扩充中介模式.系统中的核心组成部分是预处理模块和增量式模式集成迭代模块.

Fig. 1 Method framework图1 本文方法框架
预处理模块接受源模式的输入,负责调用元素级别匹配器,计算所有源模式元素中每2个元素之间的元素级别相似度,然后基于相似度结果对所有元素进行聚类,将标签字符串上相似或者语义上相似的元素聚为同一类,聚类的目的是降低后续计算的复杂度.
模式集成模块在聚类结果以及专家的人工参与的支持下,以源模式、中介模式和数据实例为输入,实施模式集成过程.首先需要从n个输入源模式中选出1个作为初始中介模式,然后让剩下的n-1个源模式依次与中介模式进行融合,即共n-1轮迭代过程.每轮迭代都是一个完整模式集成过程,该过程由中介模式生成模块和模式匹配模块结合完成:在候选匹配模式元素选择与集成子模块(后简称“元素集成子模块”)的指导下,以深度优先的顺序从根元素开始遍历当前源模式,对当前源模式上的每个元素,利用前面的聚类结果找出当前中介模式上与之属于同一聚类的所有元素作为候选元素,然后调用模式匹配模块对这些候选元素进行综合相似度计算并选出最合适的一个,由此达到降低复杂度的效果.
模式匹配模块中,模式匹配算法使用了利用模式信息的元素级别匹配器、祖先路径匹配器和树编辑距离匹配器,以及利用实例信息的基于统计匹配器、基于内容匹配器,其中的一些匹配器针对中文特点进行了修正或替代,且匹配器之间的结合方式都针对每种匹配器的性能特点进行了合理且高效的设计;基于相似度熵的人工干预决策选择模块针对候选元素的这些综合相似度,通过相似度熵的计算可以判断是否需要人工干预,若需要,系统就会向专家抛出问题.匹配结果仲裁子模块综合各候选元素的综合相似度以及专家的反馈结果确定待匹配元素的最终匹配对象.
匹配对象确定之后,冲突解决子模块将被调用以处理匹配完成之后模式之间可能出现的各种复杂冲突.每轮迭代完成,中介模式都会有所更新和扩充,其中的元素映射表也会不断扩展,直到n-1轮迭代都完成,所得到的中介模式和元素映射表就是最终的模式集成的结果.
若有新的源模式加入,只需要重新进行1次元素聚类工作,并额外运行1次模式集成的迭代过程将新加入的源模式集成到中介模式即可,已有的结果不会发生逆转,所有的更新和补充都是增量式的,系统增加的额外开销非常小,可扩展性非常高.
3 本文模式匹配与集成算法
本节将介绍本文方法中核心的预处理模块、模式匹配模块和中介模式生成模块中所涉及到的具体算法.
3.1 预处理模块
预处理模块负责基于速度最快的元素级别匹配器的结果来完成所有元素的聚类工作.具体的聚类算法本文选择使用计算最小生成树的kruskal算法:1)计算所有元素对的相似度,并对这些相似度以从大到小的顺序进行排序;2)每次选取相似度最大的元素对,若二者本来不属于同一个聚类,则将他们聚在一起,否则跳过它们检查下一个相似度最大的元素对,运行算法直到目前相似度最大的元素对的相似度低于某一阈值.此聚类算法能保证不同类之间的差别尽可能的大,可以有效避免2个表达同一概念的元素被分到不同的类别.
3.2 模式匹配算法
本文方法中一共使用了5种匹配器,利用了模式信息和实例数据,并根据不同匹配器的特点以一定的策略结合这5种匹配器来综合计算元素对之间的相似度.最后本文方法中还设计了基于相似度熵的交互式人工干预方案,以提高算法准确率.
3.2.1 元素级别匹配器
传统的元素级别匹配器主要通过元素字符串上的相似性以及语义上的相似性来表达元素之间的相似度.字符串相似度的通用算法对于中文准确率很低,而语义上的相似性则依赖外部近义词词典.针对这样的现状,本文所设计的元素级别匹配器将利用Word2Vec工具来计算相似度.Word2Vec可用于将词映射到K维实数向量空间,于是可通过向量之间的余弦值来表达相似度,且这种相似度在经过某一子领域下大量语料的训练后,既可以表达字符串上的相似性,又能涵盖语义上的相似性.此算法特点是在准备阶段完成训练后,计算相似度的速度很快,多数情况也能单独使用,但准确度一般.算法流程见算法1.
算法1. 元素级别匹配器.
输入:str1,str2;
输出:element_similarity.
①token_list1←tokenize(str1);
②token_list2←tokenize(str2);
③element_similarity←0;
④ foreachtoken1intoken_list1do
⑤ foreachtoken2intoken_list2do
⑥element_similarity+=wtvSim(token1,token2);
⑦ end foreach
⑧ end foreach
⑨element_similarity=|token_list1|×|token_list2|.
3.2.2 祖先路径匹配器
祖先路径匹配器属于结构级别匹配器的一种,其思想是关注元素的祖先元素,认为2个元素若其祖先元素有相匹配的且距离它们越近,则它们之间的相似度越大.此算法特点是依照祖先元素的匹配关系严格控制子孙元素的匹配关系,能够有效避免“置业经理”下方的“姓名”元素与“业主”下方的“姓名”元素被错误的匹配在一起的这种问题.算法流程算法2.
算法2. 祖先路径匹配器.
输入:a,b;
输出:ancestor_similarity.
①c←parentOf(a);
②element_similarity←0;
③ whilec≠null do
④d←matchingNodeOf(c);
⑤ ifisAncestorOf(d,b)=true
⑥ break;
⑦ else
⑧c←parentOf(c);
⑨ end if
⑩ end while

3.2.3 树编辑距离匹配器
树编辑距离匹配器也属于结构级别匹配器的一种,其思想是关注元素的子孙元素,认为2个元素若其子树具有越类似的结构,则它们之间的相似度越大.子树结构的相似性则通过树的编辑距离来衡量,树的编辑距离定义为2棵异构树通过插入、重命名、删除结点3种操作转换为相同结构树的操作代价[12],通过动态规划算法求解.此算法速度较慢,但能够通过子结构判断2个元素的相似性,例如“购房经纪人”和“置业经理”可能通过其他方式难以判断其表达同一概念,但由于二者都有“姓名”、“电话”、“公司”等子元素,故可以通过树的编辑距离获得较高的相似度,缺点是对于无子结构的叶结点不适用.
3.2.4 基于统计匹配器
基于统计匹配器是利用实例数据的一种匹配器,其考察元素所附带实例的统计参数.本文采用反向传播(back propagation)神经网络算法,对输入的每个源模式,根据实例数据计算每个叶结点的特征向量,构造出训练集并进行训练以获得分类模型;进行模式匹配时,将其他源模式B中某叶结点lb的特征向量输入待匹配源模式A的分类模型,输出的分类即代表lb应该匹配的A中的叶结点.
本文挑选了13个特征,对于数字类型的实例,特征值是对其数值的统计,对于实体类型(字符串)的实例,特征值是对其所占字节数的统计.特征包括整型、浮点型、统一资源标识符、日期、字符串和长文本这6个数据类型特征以及最大值、最小值、均值、标准差、均方差系数、字节数、精度这7个统计特征.
计算2个输入的叶子元素la,lb的相似度时,将la放入lb所在的模式B的分类模型中,获取la与lb的相似度值,再将lb放入la所在的模式A的分类模型中,获取lb与la的相似度值,二者取平均值作为la与lb的基于统计相似度.
此算法利用了元素的实例数据,但对于实体类型(字符串)的实例,只考察了字符串的字节长度,没有关注字符串的具体内容.此算法单独使用时匹配结果的召回率高但准确率低,计算相似度时速度较快.
3.2.5 基于内容匹配器
基于内容匹配器也是利用实例数据的一种匹配器,其考察元素所附带的实例的具体内容,对于2个叶结点,若二者的实例数据重叠程度比较大,则认为二者有可能代表同一个概念.本文所设计的算法首先按照数据类型对叶结点进行分类:1)长文本类型,即平均长度大于30的字符串;2)实体类型,即平均长度小于等于30的字符串;3)数值类型.计算2个叶结点la和lb的相似度的规则为:1)若la和lb的数据类型不同,则相似度为0;2)若la和lb都是长文本类型,则将实例合并为文档并统计词表和词频,采用空间向量模型VSM将文档映射为向量,以向量余弦值作为其相似度;3)对于实体类型,采用贪心算法:对la的每个实例,在lb中寻找与其编辑距离最小的实例并累加编辑距离值,最后将累加值除以la的实例数量即可评估la和lb的相似度.编辑距离利用动态规划求解;4)对于数值类,分别统计2个实例集合的标准差std1与std2、平均值avg1与avg2,则相似度为
(1)
此匹配器利用了元素的实例数据且关注字符串的具体内容,但由于实例子集合问题的影响,算法单独使用时匹配结果的准确率高但召回率低,在算法效率上,由于需要对所有实例进行遍历,故计算速度较慢.
3.2.6 综合匹配器
本文所设计的5个匹配器具有各自的特点,需要针对它们的特点进行高效的结合,给每一对元素计算出一个综合的相似度.
首先由于元素级别匹配器计算效率最高,且大多数情况下准确率可以接受,故本文在预处理模块使用该匹配器计算所有元素之间的相似度,预先对所有元素做1次聚类,而其他匹配器计算效率稍低,就可以基于聚类的结果来减少计算量,不需要对所有元素对都实施计算,极大地增加了整体算法的效率.
利用实例数据的2个匹配器其特点正好互补,可以先进行1次整合.基于统计匹配器召回率高,准确率低,计算出的相似度高时,实际上是不太可信的,而基于内容匹配器恰好相反,其召回率低,准确率高,计算出的相似度低时,实际上是不太可信的.又考虑到基于统计匹配器速度远快于基于内容匹配器,故可以以基于统计匹配器为主,当其计算出来的相似度较高时再去考察基于内容匹配器的结果并作出调整,这样的组合方式可以保证计算效率足够高且准确率得到较大提高.计算为

(2)
其中,sta_sim是基于统计匹配器,con_sim是基于内容匹配器,d是0~1之间的一个经验阈值.
按上述方法计算出来的基于统计匹配器和基于内容匹配器所结合的相似度ins_sim称之为实例信息相似度,接下来将结合实例信息相似度以及树编辑距离匹配器.由于前者只对叶结点有效,而后者主要对中间结点有效,故可以做互补形式的结合,当2个元素均为叶结点时,取实例信息相似度,否则取树编辑距离匹配器所计算的相似度,此结合后的相似度称之为实例及子树相似度.
最后,对实例及子树相似度、元素级别匹配器计算的相似度和祖先路径匹配器计算的相似度这3个相似度值取加权平均值,即得到任意2个元素之间的综合相似度similarity.
即便是综合考虑了各方面信息、高效的结合了各种匹配器所计算出的综合相似度,有时候也不足以判断某一元素的正确的匹配对象,此时可以引入人工干预,我们认为专家的决策一定是正确的,但人工干预的程度必须受到控制,必须以机器的自动化算法为主.
对于待匹配的元素,其候选集合中每个候选元素都有1个与之对应的综合相似度,针对这些综合相似度,人工干预的基本思路就是若这些相似度中有1个特别突出的高,则匹配对象就是综合相似度高的那个候选元素,但若这些相似度比较接近,实际上就不能直接取综合相似度最高的候选元素作为匹配对象.此时即可向专家抛出问题,让专家从这些候选元素中选出与当前元素真正匹配的元素,然后算法继续运行.
本文选择利用相似度熵来衡量候选元素的综合相似度之间的不确定性,计算公式为
(3)
对于具有k个候选元素的情况,计算出来的相似度熵entropy(x)的值域为[0,lnk],引入阈值T,当entropy(x)>T×lnk时,则向专家抛出问题请求协助,否则直接选择综合相似度最大的候选元素来匹配.
3.3 模式集成算法
此模块负责每一轮模式集成迭代中的集成任务,分为元素集成子模块和冲突解决子模块.
3.3.1 元素集成子模块
在一次迭代过程中,需要将当前源模式集成到当前的中介模式上,本文算法采用深度优先的顺序来遍历当前源模式的所有元素,保证在处理每个元素时,其祖先元素都已经完成匹配.具体流程如下:
算法3. 元素集成流程.
步骤1. 默认所有源模式的根元素都直接匹配,因为输入的同源异构模式都是同一子领域下的.以DFS顺序,从根元素的第1个子元素开始遍历.
步骤2. 当前遍历到的元素为x,在聚类结果中取出x所在类别X,|X|=1,跳至步骤7.
步骤3. 从X中取出在当前中介模式上存在的元素,获得x的候选集合Y,若Y=∅,跳至步骤7.
步骤4. 对Y中的每个元素,调用模式匹配模块计算其与x的综合相似度.
步骤5. 对步骤4中得到的所有综合相似度,计算相似度熵entropy(x),若entropy(x)>T×ln|Y|,则向专家抛出问题请求协助,若专家认为候选集合中没有x的真正匹配对象,跳至步骤7,否则,设专家给出x的真正候选元素为y;若entropy(x)≤T×ln|Y|,则选择最大相似度所对应的元素为候选元素,同样设为y.
步骤6. 将x与y匹配,调用冲突解决子模块解决冲突,更新中介模式,记录匹配关系,跳至步骤8;
步骤7. 若中介模式中没有元素与x匹配,则考察x的父元素p,设中介模式中与p匹配的元素是q,则将x作为q最右边一个子元素加入到中介模式中,扩充中介模式.
步骤8. 若x不是叶结点,则取x的第1个子元素,否则取x的下一个兄弟元素,重复步骤2.
步骤9. 若x是DFS顺序的最后一个元素,则算法结束.
3.3.2 冲突解决子模块
当确定了当前源模式下某一元素的匹配对象后,需要按照冲突解决策略解决可能出现的策略,策略如下(转行定格):
① 同义词冲突.本文的解决方式为先来后到,选择旧的标签作为中介模式相应元素的标签,但保留新匹配元素的标签,记录在该元素标签可替换的同义词集合中.

Fig. 4 Nested path conflict type three图4 嵌套路径结构冲突3
② 数据类型冲突.本文的解决方式为保留精度更高的数据类型(如浮点型)或含义更宽泛的数据类型(如字符串类型).其中会涉及到实例数据的数据类型转换问题.
③ 元素子结构冲突.本文的解决方式为:当叶结点与具有子结构的内部结点相匹配时,无论叶结点来自源模式还是中介模式,都直接保留内部结点的子结构.在算法3中此冲突将自然得到解决,不需要额外进行冲突调整.
④ 嵌套路径结构冲突1.嵌套路径结构冲突是最为复杂的冲突,其来源是2个模式中已经匹配的祖先元素和当前匹配的子孙元素之间路径的不一致问题.这种问题可细分为3类,其中嵌套路径结构冲突1产生于中介模式的路径中有嵌套元素.如图2所示,中介模式比源模式多1层“交通”元素,正确的解决方法是保留分级更多的结构,此冲突不需要额外进行冲突调整,按照算法3运行可以自然地解决,生成正确的新中介模式.
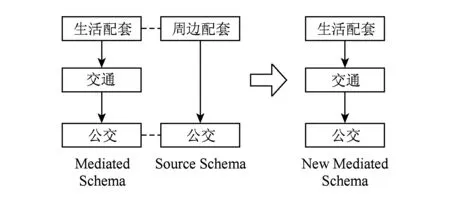
Fig. 2 Nested path conflict type one图2 嵌套路径结构冲突1
⑤ 嵌套路径结构冲突2.此冲突产生于源模式的路径中有嵌套元素.如图3所示,源模式比中介模式多1层“交通”元素,正确的解决方法应该是保留分级更多的结构,但若按照算法3的算法运行,最终生成的中介模式将如图3中新中介模式1,因为匹配“交通”元素时没找到匹配对象,被当做生活配套最后一个子元素插入到中介模式中,导致错误,需要进行调整.但这种错误马上可以检测出来,接下来匹配源模式的“公交”元素时,发现其原本父元素“交通”成为其兄弟元素,解决方法是斩断中介模式中“公交”元素与其父元素“生活配套”的连线,补充其与源模式中父元素所匹配的“交通”元素的连线,最终形成正确的新中介模式2,冲突消除,算法可以继续运行.
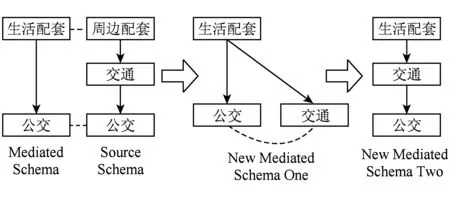
Fig. 3 Nested path conflict type two图3 嵌套路径结构冲突2
⑥ 嵌套路径结构冲突3.此冲突产生于源模式和中介模式的路径中都有嵌套元素,但两边的嵌套元素在实际匹配中错误的匹配失败.如图4所示,实际算法运行时,由于“购房经纪人”和“置业经理”的字符串不相似,使得二者的相似度较低,导致匹配“置业经理”时未找到匹配对象而被当做二手房的最后一个子元素插入到中介模式中,生成了错误的新中介模式1,需要进行调整.但这种错误依然马上可以检测出来,接下来匹配源模式的“名字”元素时,发现其原本父元素“置业经理”成为其父亲的兄弟元素,解决方法是撤销之前 “置业经理”的匹配结果,依据子元素的匹配情况将“置业经理”与 “购房经纪人”匹配,最终形成正确的新中介模式2,冲突消除,算法可继续运行.
4 实验评估
4.1 实验数据
本文实验所使用的数据集是来自二手房领域的多源异构数据集,其中包含2015年1月的安居客①、我爱我家②、链家网③3个二手房交易网站上所发布的北京地区二手房源信息,三者的XML模式中分别包含51,50,46个元素.本文首先对这3个数据模式进行人工的数据融合,得到标准中介模式以及元素匹配映射表,用于进行实验结果的对比.数据集的基本信息见如表1所示:

Table 1 Basic Information of Data Set
4.2 实验方法
本文实验方法是对4.1节数据运行本文整体算法,获得最后记录的元素匹配表,比较算法做出的匹配判断与实际人工标注的匹配结果之间的差别,主要评价指标为准确率precision、召回率recall和F值,其计算为
(4)
(5)
(6)
其中,TP为实际匹配且算法也判断为匹配的元素对数量,FP为算法判断为匹配而实际不匹配的元素对数量,FN为实际匹配但算法未能判断为匹配的元素对数量.
由于POSCHE的相关工作也是增量迭代式进行数据融合,与本文最为相似,因此本文的对比对象选择POSCHE的算法,同时本文方法将分为无人工干预和有人工干预2种,前者没有任何人工干预,算法完全自主决策.另外本文还针对人工参与的程度与算法准确率的关系进行了实验,实验变量为相似度熵的阈值大小.
4.3 实验结果
1) 人工干预效果实验.
本文将相似度熵的阈值T分别设置为0.0,0.5,0.6,0.7,0.8,1.0进行了6次实验,比对每次实验的人工干预的次数(即算法抛出问题的次数)以及算法最终的F值评估.其中T=0.0代表全部工作都由人工完成,T=1.0则代表没有任何人工参与.实验结果如图5所示.由实验结果可以看出,人工干预程度越高(相似度阈值越低),算法匹配的效果就越好,综合考虑效果提升的程度和人工干预的程度,本文选择T=0.7的阈值,在此阈值下,人工干预次数的绝对数量和上升幅度都很低但算法匹配效果的提升足够明显.

Fig. 5 Manual intervention experiment result图5 人工干预效果实验结果
2) 模式匹配效果实验.
本文针对PORSCHE的解决方案、无人工干预的本文方法(T=1.0)以及有人工干预的本文方法(T=0.7)进行了3次实验,比对了3种解决方案的准确率、召回率和F值.实验结果如图6所示.
由实验结果可以看出,无论通过哪个指标看都是有人工干预的本文方法好于无人工干预的本文方法,无人工干预的本文方法好于PORSCHE的解决方案.其中有人工干预的方法中,算法向专家抛出了52个问题,只占总搜索空间(7 196对元素对)的0.7%,占全人工抛出问题(420个)的12.4%,而F值高达97.7%.

Fig. 6 Schema matching experiment result图6 模式匹配效果实验结果
5 结 论
文本针对智慧民生领域中数据模式的特点,结合传统的模式匹配技术和模式集成技术,提出并实现了一种“面向智慧民生领域层次结构数据的增量交互式模式集成方法”.该方法采用增量迭代的方式,每次集成2个模式,并将集成的结果表达为中介模式,后续集成基于前序集成的结果进行,在源模式数量较多的情况下,大大减少了源模式间集成的次数;而在每一次集成迭代内部,通过元素聚类等预处理工作,大大缩小元素匹配的搜索空间和比对次数,进一步减少了工作量.在模式匹配阶段,针对智慧民生领域数据的特点,综合利用模式信息和实例数据,构造了多种适应于中文处理,且能力互补的匹配器进行元素匹配,并通过计算相似度熵度量候选元素相似度的差异性,仅在差异性不够明显时才引入人工参与,较好地权衡了人工参与工作量和最终结果的准确性.而中介模式生成过程则控制模式中元素遍历的顺序,并处理匹配完成之后源模式间可能出现的各种复杂冲突,综合考虑了效率和中介模式的质量.算法最终的输出是全局统一的中介模式以及各源模式与中介模式元素之间的匹配映射关系.本文利用从互联网爬取的二手房源信息数据设计并完成实验,实验结果表明,本文的数据集成方案效果优秀.
本文解决方案的局限性体现在,虽然人工参与可以控制到很低的程度,但完全没有人工参与的准确率还有所欠缺.本文未来工作一方面将继续研究自动化的模式匹配算法,力图改善没有人工参与时的全自动算法的有效性;另一方面将着手进行实体匹配方面的研究工作(entity matching),实体匹配的任务是在利用中介模式集成各个源模式的数据时必须对不同源模式中的数据进行识别,判断并删除重复数据.实际上模式集成是实体匹配的基础,只有当实体匹配也完成之后才能真正实现数据的集成,从而形成城市范围的完整数据集.
[1]Madhavan J, Bernstein P A, Rahm E. Generic schema matching with cupid [C]Proc of the 27th Int Conf on Very Large Data Bases. San Francisco: Morgan Kaufmann, 2001: 49-58
[2]Aumueller D, Do H H, Massmann S, et al. Schema and ontology matching with COMA++ [C]Proc of the 11th ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2005: 906-908
[3]Noy N, Natalya F, Mark A M. Anchor-PROMPT: Using non-local context for semantic matching [C]Proc of the Workshop on Ontologies and Information Sharing at the Int Joint Conf on Artificial Intelligence (IJCAI). San Francisco: Morgan Kaufmann, 2001
[4]Madria S, Passi K, Bhowmick S. An XML schema integration and query mechanism system [J]. Data & Knowledge Engineering, 2008, 65(2): 266-303
[5]Pottinger R A, Bernstein P A. Merging models based on given correspondences [C]Proc of the 29th Int Conf on Very Large Data Bases. San Francisco: Morgan Kaufmann, 2003: 862-873
[6]Shvaiko P, Euzenat J. A survey of schema-based matching approaches [G]LNCS 3730: Journal on Data Semantics IV. Berlin: Springer, 2005: 146-171
[7]Bernstein P A, Madhavan J, Rahm E. Generic schema matching, ten years later [J]. Proc of the VLDB Endowment, 2011, 4(11): 695-701
[8]Giunchiglia F, Yatskevich M. Element level semantic matching [C]Proc of the 3rd Int Semantic Web Conf (ISWC2004) Workshop on Meaning Coordination and Negotiation. Berlin: Springer, 2004
[9]Bouquet P, Serafini L, Zanobini S. Semantic coordination: A new approach and an application [C]Proc of the 2nd Int Semantic Web Conf (ISWC2003). Berlin: Springer, 2003: 130-145
[10]He B, Chang C C, Han J. Discovering complex matchings across Web query interfaces: A correlation mining approach [C]Proc of the 10th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2010: 148-157
[11]Su W, Wang J, Lochovsky F. Holistic query interface matching using parallel schema matching [C]Proc of the 22nd Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2006: 122-131
[12]Zhang Kaizhong, Dennis S. Simple fast algorithms for the editing distance between trees and related problems [J]. Journal on Computing, 1989, 18(6): 1245-1262
[13]Dennis S, Wang J T-L, Giugno Rosalba. Algorithmics and applications of tree and graph searching [C]Proc of the 21st ACM SIGMOD-SIGACT-SIGART Symp on Principles of Database Systems. New York: ACM, 2002
[14]Liu Chen, Wang Jianwu, Han Yanbo. Mashroom+: An interactive data mashup approach with uncertainty handling [J]. Journal of Grid Computing, 2014, 12(2): 221-244
[15]Do H H, Rahm E. COMA—A system for flexible combination of schema matching approaches [C]Proc of the 28th Int Conf on Very Large Data Bases. San Francisco: Morgan Kaufmann, 2002: 610-621
[16]Li W S, Clifton C, Liu S Y. Database integration ssing neural networks: Implementation and experiences [J]. Knowledge & Information Systems, 2000, 2(1): 73-96
[17]Massmann S, Rahm E. Evaluating instance-based matching of Web directories [C]Proc of Int Workshop on the Web and Databases. New York: ACM, 2008
[18]Fan J, Lu M, Ooi B C, et al. A hybrid machine-crowdsourcing system for matching Web tables [C]Proc of the 30th IEEE Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2014: 976-987
[19]Saleem K, Bellahsene Z, Hunt E. PORSCHE: Performance oriented schema mediation [J]. Information Systems, 2008, 33(78): 637-657
[20]Nguyen H Q, Taniar D, Rahayu J W, et al. Double-layered schema integration of heterogeneous XML sources [J]. Journal of Systems & Software, 2011, 84(1): 63-76
[21]Aboulnaga A, El Gebaly K. μBE: User guided source selection and schema mediation for internet scale data integration [C]Proc of the 23rd IEEE Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2007: 186-195

Xia Ding, born in 1992. Master candidate of the School of Electronics Engineering and Computer Science, Peking University. His main research interest is ubiquitous computing.

Wang Yasha, born in 1975. Received his PhD degree in Northeastern University, Shenyang, China, in 2003. Professor of National Engineering & Research Center of Software Engineering in Peking University, China. His main research interests include urban data analytics, ubiquitous computing, software reuse, and online software development environment.

Zhao Zipeng, born in 1988. Received his master degree from Peking University in 2015. His main research interests include ubiquitous computing and schema matching.

Cui Da, born in 1993. Master candidate of the School of Electronics Engineering and Computer Science, Peking University. His main research interest is ubiquitous computing.
Incremental and Interactive Data Integration Approach for Hierarchical Data in Domain of Intelligent Livelihood
Xia Ding1,2, Wang Yasha1,3, Zhao Zipeng1,2, and Cui Da1,2
1(KeyLaboratoryofHighConfidenceSoftwareTechnologies(PekingUniversity),MinistryofEducation,Beijing100871)2(SchoolofElectronicsEngineeringandComputerScience,PekingUniversity,Beijing100871)3(NationalEngineering&ResearchCenterofSoftwareEngineering(PekingUniversity),Beijing100871)
Intelligent livelihood is an important domain of the smart city. In this domain, there are many application systems that have accumulated a large number of multi-source hierarchical data. In order to form an overall and unified view of the multi-source data in the whole city, variant data schemas should be integrated. Considering the distinct characteristics of the data from intelligent livelihood domain, such as lacking support for semantic matching of Chinese labels, numerous quantities of schemas, missing element labels, the existing schema integration approaches are not suitable. Under such circumstances, we propose an incremental and iterative approach which can deduce the massive computation workload due to the big number of schemas. In each iteration, both meta information and instance data are used to create more precise results, and a similarity entropy based criteria is carefully introduced to control the human intervention. Experiments are also conducted based on real data of second-hand housing in Beijing fetched from multiple second-hand Web applications. The results show that our approach can get high matching accuracy with only little human interventions.
schema matching; schema integration; data integration; smart city; intelligent livelihood
2015-12-09;
2016-05-03
国家“八六三”高技术研究发展计划基金项目(2013AA01A605);质检公益性行业科研专项(201510209) This work was supported by the National High Technology Research and Development Program of China (863 Program) (2013AA01A605), and the National Public Benefit Research Foundation (201510209).
王亚沙(wangyasha@pku.edu.cn)
TP391
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
小学生学习指导(低年级)(2021年12期)2021-12-31
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
汽车与新动力(2012年1期)2012-03-25
