
基于CryptDB的选择加密策略研究
2017-03-29 05:00张成果
计算机技术与发展 2017年3期
张成果,杨 庚,王 伟
(南京邮电大学 计算机学院,江苏 南京 210003)
基于CryptDB的选择加密策略研究
张成果,杨 庚,王 伟
(南京邮电大学 计算机学院,江苏 南京 210003)
针对云中数据隐私保护问题,采用加密存储是一可行的选择。而在未解密的情况下,如何对密文进行计算成了近年来研究的热点。为提高密文计算效率,节约密文数据的存储空间,将选择加密策略与CryptDB密文数据库系统相结合,设计并实现了支持选择加密策略的CryptDB密文数据库系统。由于CryptDB使用多个洋葱加密模型,需将数据加密成多份以适用不同场景,对不敏感字段加密增加了计算时间及存储空间。针对这些问题,提出一种用户自定义的敏感字段检测算法,并且在原系统中创建和注册明文洋葱,修改元数据表,以及对自定义SQL语句的拦截和改写,实现选择加密策略。实验结果表明,在满足用户对数据表安全性要求的前提下,随着加密字段减少,密文计算时间和存储空间显著减少,提高了CryptDB系统的效率和实用性。
选择加密;密文计算;CryptDB;密文数据库;洋葱加密
0 引 言
随着云计算的快速发展,云安全成为亟待解决的问题,并且引起了业界的高度重视。例如:Cisco结合云计算网络应用无边界的特点,提出自防御云安全技术架构(SDC);八百客推出传输协议加密和URL数据访问安全码技术等措施来加强企业数据安全。在云计算的模式下,大量个人及企业用户将私有的数据在不加密的情况下,通过网络传输存储在云服务器上。这种模式带来三个方面的安全问题:一是如何保证在网络传输过程中数据不被非法截取;二是如何确保存储在第三方云服务器上的数据不被非法访问;三是如何保证用户在任何时候都能安全访问到自身的数据[1]。
解决上述问题较好的方法之一就是用户对其私有数据进行加密。用传统的加密算法对数据加密后存储在云服务器上,用户无法直接对数据进行查询、计算及修改等操作。必须将服务器端的密文下载到本地进行解密后,才能对数据进行操作,再对修改后的数据加密并且传输到云端存储。显然,在面对大规模的数据库存储需求时,该方案在执行效率上远低于明文数据库。密文计算相关算法的提出解决了上述问题。文中从提高密文计算效率以及减少密文存储空间角度出发,提出一种选择加密算法,并通过实验验证了算法的有效性。
1 相关工作
自20世纪90年代起,一些密文搜索和计算的方案被相继提出。1995年,Chor等[2]首次提出私有信息检索的概念,并在不泄露检索信息的前提下,实现从数据库中检索到用户所需的信息。2000年,Song等[3]首次提出一种对称可查询加密(SSE)方案,开创了在未解密的情况下查询密文的先例。用户使用该机制对数据进行加密后,将密文数据交由服务器端存储;当用户需要根据关键字检索文件时,将该关键字的搜索凭证(search capability)发给服务器,服务器根据这个凭证在密文数据上直接进行检索,将包含该关键字的文件返回给用户,用户只需对返回的文件进行解密即可。近年来,可查询加密机制得到广泛的研究,Li等[4]解决了关键字的模糊查询问题,Cao等[5]提出了查询多关键字的解决方案。
可查询加密机制的研究侧重于文本文件查询,对于数据库中密文数据存储及查询等问题,以往的可查询加密机制则无法满足需求。如不支持一些基本的SQL查询,不支持数值之间的大小比较,不支持JOIN操作以及求和操作等。
同态加密算法[6]的提出解决了在未解密的情况下对密文数据进行操作的问题,且全同态算法允许在密文数据上执行任意的操作,并得到与明文下操作相同的结果。其缺陷在于当前全同态算法的执行效率低,时间开销大,不具有实际应用价值。
2011年,MIT人工智能实验室(CSAIL)研发了世界上首个可实际使用的开源密文数据库系统—CryptDB[7]。该系统以中间代理的形式为数据库提供加解密功能。与直接在明文数据库中进行操作的时间相比,只增加了15%~20%的额外开销。CryptDB对数据表全部字段进行加密后存储在数据库中,并且能够直接在密文上执行SQL操作。由于CryptDB采用多层加密的洋葱加密方案来加密数据,并把数据加密成多份以适用于多种检索场景,所以其加密存储对服务器的运算和存储开销是巨大的。为解决大规模数据加密时间开销巨大的问题,选择加密策略是一种可行的方法。2013年,Fu等[8]提出一种安全高效的云备份服务Pangolin,将选择加密集成到数据压缩中来保证敏感应用数据的安全性,以降低数据安全风险。2016年,张伯雍等[9]提出一种适用于移动终端的动态选择加密方案,动态选择加密算法对部分数据加密,既保护了数据隐私又提高了加密效率。
在数据库存储中,并不是所有的字段都是敏感的。对大量不敏感的字段进行加密,不仅不能增加数据表安全性,还耗费大量的加密时间和存储空间。针对这些问题,文中提出了一种用户自定义敏感字段检测算法,并在CryptDB源码的基础上,通过创建及注册明文洋葱,修改元数据表和拦截及改写自定义SQL语句,构建了一个支持选择加密策略的CryptDB系统。该系统可对用户指定的敏感字段进行加密,其余字段直接保存为明文。在保证原系统所有功能正常工作及满足用户对数据表安全性需求的基础上,降低了加密的计算量和密文的存储空间,从而增加了系统的实用性和灵活度。
2 选择加密策略及实现
2.1 CryptDB密文数据库系统
为支持不同的SQL操作,CryptDB系统将明文数据进行多层加密,每层使用不同加密算法,每种加密算法支持不同的SQL操作,且从内向外加密算法的安全等级越来越高。因其构造层次类似于洋葱,所以又称为洋葱加密[7]。
CryptDB设计了四种洋葱。其中,DET洋葱(Onion Eq)支持对密文数据的等值比较操作,包含等值比较和等值连接操作;OPE洋葱(Onion Ord)支持对密文数据的大小比较和排序等操作;HOM洋葱(Onion Add)支持对密文数据的加法运算;SEARCH洋葱(Onion Search)支持对密文数据的关键字匹配。即如要插入一个字段明文数据,经过Proxy的改写之后,会将其转化成上述的四个洋葱即四个字段,然后再保存到数据库中。基于优化的目的,对数值型数据不需要进行关键词匹配,对字符型数据不需要进行加法操作。所以CryptDB对数值型数据只保存其DET洋葱、OPE洋葱和HOM洋葱;而对字符型数据,除DET、OPE洋葱外,只保存其SEARCH洋葱(但实验结果表明,在MIT官网下载公开的CryptDB的版本,对于字符型数据只会创建DET和OPE洋葱,并不会创建SEARCH洋葱)。
CryptDB对于不同表,不同列,不同洋葱,不同的加密等级,使用的加密密钥K也各不相同。加密密钥K是由MK计算得到。其中,MK是主密钥,保存在Proxy中,PRP是伪随机序列[10]。计算公式如下所示:
K= PRPMK(tablet,columnc,oniono,layerl)
(1)
CryptDB对数据表中所有字段进行加密。设一张表有n个字段,每个字段可以表示成(attri,enci),i∈[1,n]。其中,attri表示第i个字段的属性值;enci表示第i个字段是否加密且enci≡true。CryptDB的数据模型表示为:
MCryptDB={(attr1,true),(attr2,true),…,(attrn,true)}
(2)
2.2 数据模型
为比较具有选择加密功能的CryptDB系统与原系统在功能及灵活性上的差异,设具有选择加密功能CryptDB的数据模型为MSel-CryptDB。
定义1:SelectiveCryptDB数据模型。设表中有n个字段,SelectiveCryptDB的数据表中每一字段可以表示成(attri,enci),则数据表模型表示为:
MSel-CryptDB={(attr1,enc1),(attr2,enc2),…, (attrn,encn)}
(3)
其中,attri表示第i个字段的属性值;enci表示第i个字段是否加密且enci∈{true,false},i∈[1,n]。
性质1:对于任意数值i∈[1,n],都有MCryptDB⊆MSel-CryptDB成立。
证明:由定义1易得MCryptDB⊂MSel-CryptDB,即原系统是新系统的一个真子集。当且仅当∩enci=true(i∈[1,n])时,MCryptDB=MSel-CryptDB,综上证得MCryptDB⊆MSel-CryptDB。
由性质1可得,SelectiveCryptDB系统不仅包含原系统的全部功能,还增加了系统灵活性,降低了系统存储空间。可以根据用户不同的需求,自由选择字段进行加密,充分给予用户自主性且能提高系统运行的效率。
2.3 策略实现
2.3.1 用户自定义敏感字段检测


表1 S参数等级
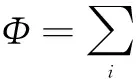
用户可以根据自身的安全性需要,设置每个字段的安全等级Si、权重Pi、敏感阈值η、数据表安全等级Φset。计算出哪些字段是敏感的,并且当Φ≥Φset,即可认为达到用户对数据表隐私保护的需求。如果当前的Φ<Φset,说明不能达到用户对数据表安全等级的要求。那么,用户必须动态调整Si和Pi,重新计算出敏感和非敏感字段,使得数据表的安全性达到用户设定的安全等级,保证了选择加密之后的数据表的安全性。
2.3.2 选择加密算法
定义数据库的选择加密为用户创建表时,可以指定需要加密和不需要加密的列[11]。对于指定要加密的部分,系统将一个字段加密成三个洋葱保存在数据库中。而对于非敏感数据即无需加密的部分,只为其创建明文洋葱(oPlain),该洋葱直接将明文数据保存于数据库,并且将该列所处的加密状态保存于元数据表,为之后插入和检索数据提供基础信息。而对于敏感字段,元数据表记录了当前各个洋葱所处的加密等级等信息。在执行SQL操作之前,先查询该元数据表,获取各个字段是否加密,以及当前所处加密等级等信息,然后再利用获取到的元数据信息对当前字段值进行相对应的加密。其伪代码实现如算法1所示。选择加密系统执行流程如图1所示。
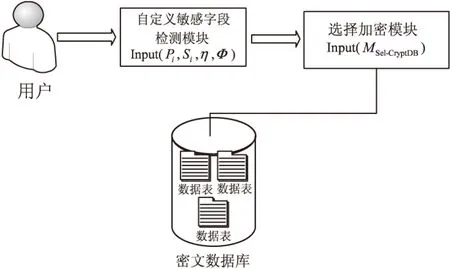
图1 选择加密系统执行流程
算法1:选择加密算法SelectiveEncryption(sql)。
输入:原始SQL语句;
输出:加密后的SQL语句。
SelectiveEncryption(sql)
//LEX()函数对sql语句进行词法解析
token←LEX(sql)
encsql←null
iftoken←CREATE_TABLE_CLAUSEthen
foreachk∈MSel-CryptDB
ifk.enc←TRUEthen
encsql←encsql+CreateEncryptOnion(k)
secretkey←CalcKey(table,onion,layer)
else
encsql←encsql+CreatePlainOnion(k)
secretkey←NULL
endif
WriteToMetaTable(k,secretkey)
endfor
elseiftoken←INSERT_CLAUSEthen
p←SearchMetaTable()
foreachp∈MSel-CryptDB
ifp.enc←TRUEthen
encsql←encsql+OnionEncrypt(p)
else
encsql←encsql+OnionPlaint(p)
endif
endfor
endif
returnencsql
3 系统性能分析
通过2.1节可知,对于数值型数据,CryptDB为其创建DET洋葱、OPE洋葱和HOM洋葱;对于字符型数据,创建DET洋葱和OPE洋葱。
对于数值型数据,RND采用的是添加初始化向量IV的Blowfish算法,DET采用的是Blowfish加密算法,DETJOIN采用的是基于椭圆加密ECC的ECJoin算法。对于字符型数据,RND采用的是带初始化向量IV(即salt值)处于CBC模式的AES加密算法,它能保证密文加密的随机性,即相同明文加密后密文不相同;DET采用初始向量相同的CMC模式(即初始化向量都为“0”的CBC模式)AES加密算法,所以相同的明文加密后得到相同的密文;OPE采用mOPE加密算法;HOM采用Paillier加密算法。
设Blowfish加密算法的复杂度为RBlowfish,AES加密算法的复杂度为RAES,ECJoin加密算法的复杂度为RECJoin,mOPE加密算法的复杂度为RmOPE,HOM加密算法的复杂度为Rpaillier,n为待加密明文的规模。
对于数值型数据,DET洋葱的复杂度为:
UDET_NUM=RECJoin+2RBlowfish
(4)
OPE洋葱的复杂度为:
UOPE_NUM=RmOPE+RBlowfish
(5)
HOM洋葱的复杂度为:
UHOM_NUM=Rpaillier
(6)
对于字符型数据,DET洋葱的复杂度为:
UDET_STR=RECJoin+2RAES
(7)
OPE洋葱的复杂度为:
UOPE_STR=RmOPE+RAES
(8)
由式(4)~(6)可知,加密一个数值型数据的复杂度为:
UNUM=UDET_NUM+UOPE_NUM+UHOM_NUM= RECJoin+3RBlowfish+RmOPE+Rpaillier
(9)
由式(7)、(8)可知,加密一个字符型数据的复杂度为:
USTR=UDET_STR+UOPE_STR=RECJoin+ 3RAES+RmOPE
(10)
由文献[12]可知,ECJoin复杂度为O(n+logn)。由文献[13-14]可知,AES,Blowfish,Paillier算法时间复杂度为O(n)。由文献[10]可知,mOPE编码的时间复杂度为O(logn),且经过mOPE编码之后,还需要对B树上的叶子节点进行DET加密,所以mOPE算法的时间复杂度为O(n+logn)。
假设创建一张有N个字段的数据表,其中有X个数值型字段需要加密,Y个字符型字段需要加密。设执行一条Insert语句的通信时间为Ttrans,一个字段明文的计算时间为Tplain,设浮点计算的时间为Tfc。则
Tinsert(N,X,Y)={X·UNUM+Y·USTR+Ttrans+ (N-X-Y)·Tplain}·Tfc
(11)
当减少k(k∈[0,N])个数值型加密字段时,执行一条Insert语句的时间为:
Tinsert(N,X-k,Y)={(X-k)·UNUM+ Y·USTR+Ttrans+(N-(X-k)- Y)·Tplain}·Tfc
(12)
所以,减少k个数值型加密字段时,插入一条提高数据效率:
(13)
同理,减少k个字符型加密字段,插入一条提高数据效率:
(14)
在实际实验中,为避免通信时间的影响,采用批处理方式进行插入。每次插入150条数据,所以Ttrans≈0。在较为理想的情况下,相对于加密时间,明文的计算时间可以忽略不计,即Tplain≈0。
综上:
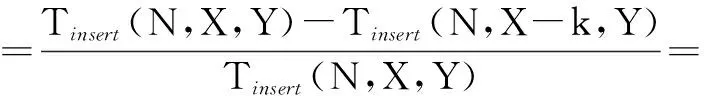
(15)
同理:
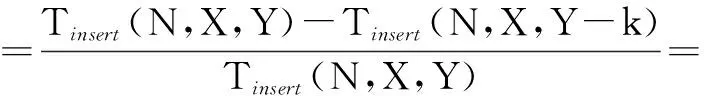
(16)
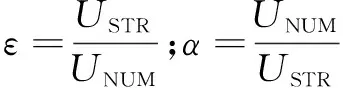
由式(15)和式(16)可以得出如下结论:插入语句执行效率的提高与加密字段的减少个数成正比。即在总字段不变的前提下,随着加密字段数的减少,执行插入语句提高的效率是递增的。
4 实 验
4.1 实验环境
文中实验的硬件环境为:
CPU:Intel(R) Xeon E3,Memory为16 GB (2x8 GB) 1 333 MHz Dual Ranked RDIM;
Disk:1 TB 3.5-inch 7.2 K RPM SATA II Hard Drive。
软件平台为:ubuntu-12.04,CryptDB。
4.2 实验方案
运行CryptDB密文数据库系统,建立两张表。第一张表中包含10个字段,字段均为int类型;第二张表包含10个字段,均为varchar类型。然后,通过软件生成不同规模的insert语句。每条insert语句中每个字段的值随机生成。规模分为三个等级:100条insert语句,1 000条insert语句,10 000条insert语句。
因为分为int和varchar类型两张表,所以最终一共生成6个sql脚本文件。分别是:int-100.sql,int-1000.sql,int-10000.sql,varchar-100.sql,varchar-1000.sql,varchar-10000.sql。
通过为敏感字段检测模块设置不同的参数,动态计算出敏感与非敏感字段,分别运行上述六个测试脚本文件,记录每个脚本的执行时间及存储空间。
4.3 实验数据及分析
分别运行int-100.sql,int-1000.sql,int-10000.sql三个脚本,并且记录其运行时间和存储空间,如表3所示。
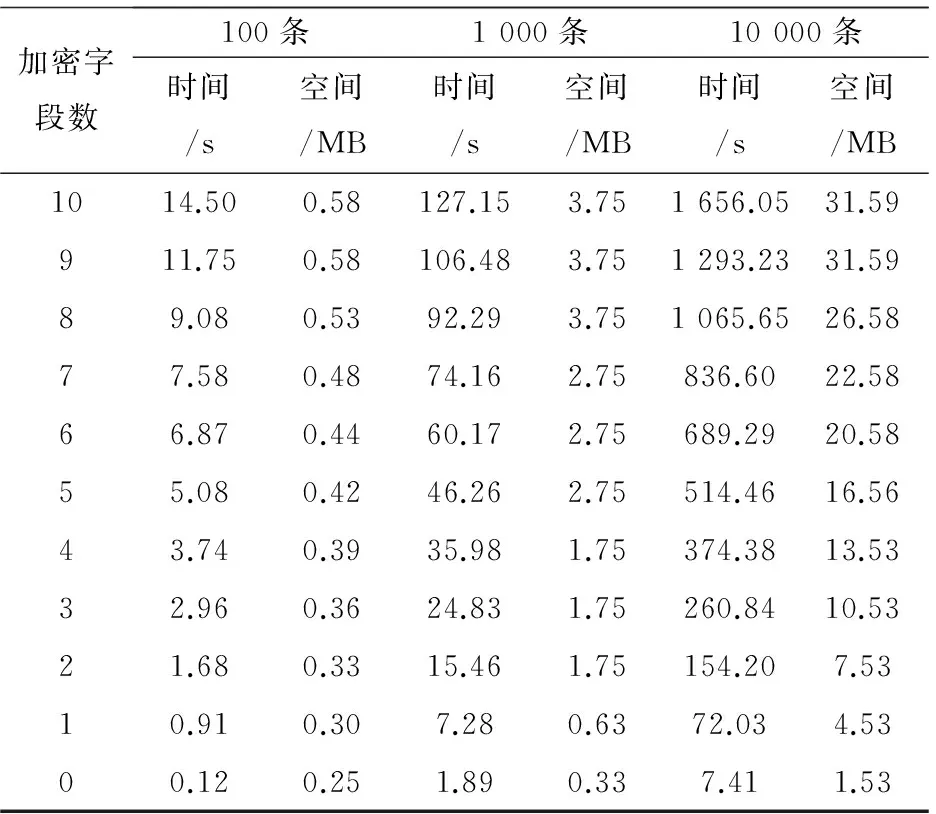
表3 数值型数据插入时间及存储空间
分别运行varchar-100.sql,varchar-1000.sql,varchar-10000.sql三个脚本,并且记录其运行时间和存储空间,如表4所示。
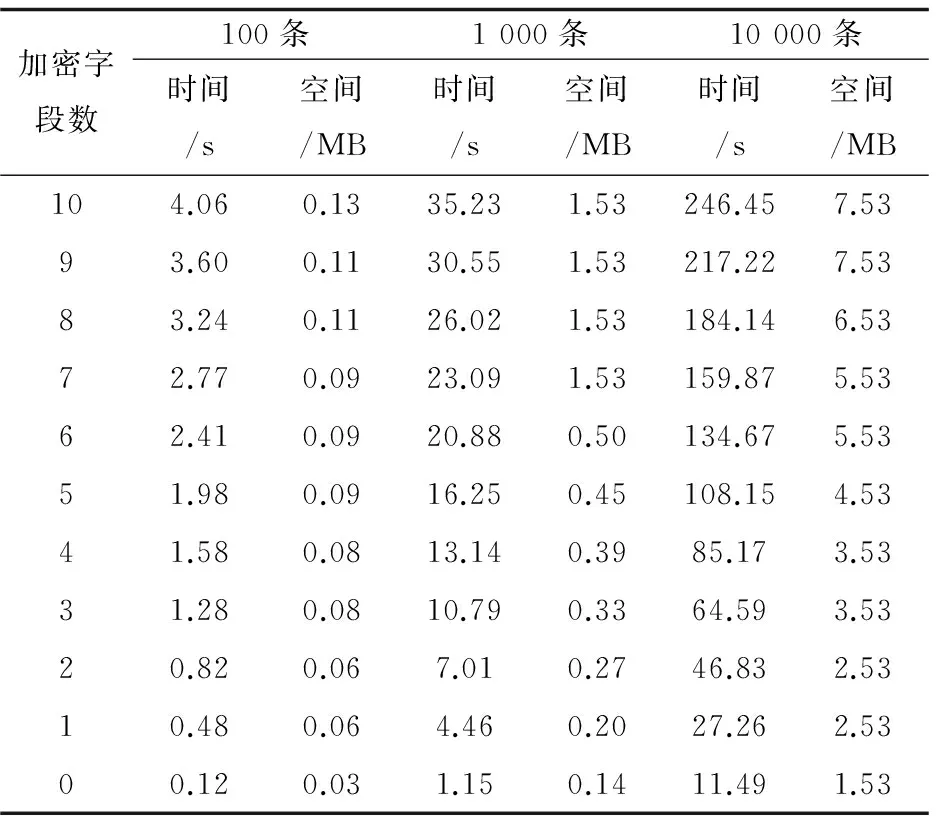
表4 字符型数据插入时间及存储空间
由于数据库按照设定的值进行增长,该数值不能设置太小。如果太小,则易产生碎片,并且影响IO性能。所以,两个表存储空间相差不大时,值可能相同,但是实际大小并不相同。所以,存储空间表中的值是有一些误差的。
表3和表4记录了随着加密字段数的减少,插入语句的加密时间和存储空间变化。从中可以得到如下结论:
(1)随着数据表中加密字段个数的减少,加密的时间和存储空间显著递减。
(2)字符型数据的加密时间远小于数值型数据的加密时间。这是由于数值型数据比字符型数据多创建一个HOM洋葱。
(3)字符型数据加密之后所占存储空间远小于数据型的密文数据。这是由于HOM加密需占用较多的存储空间。
图2是在加密字段减少个数递增的情况下,数值型数据插入语句效率提高的曲线图。
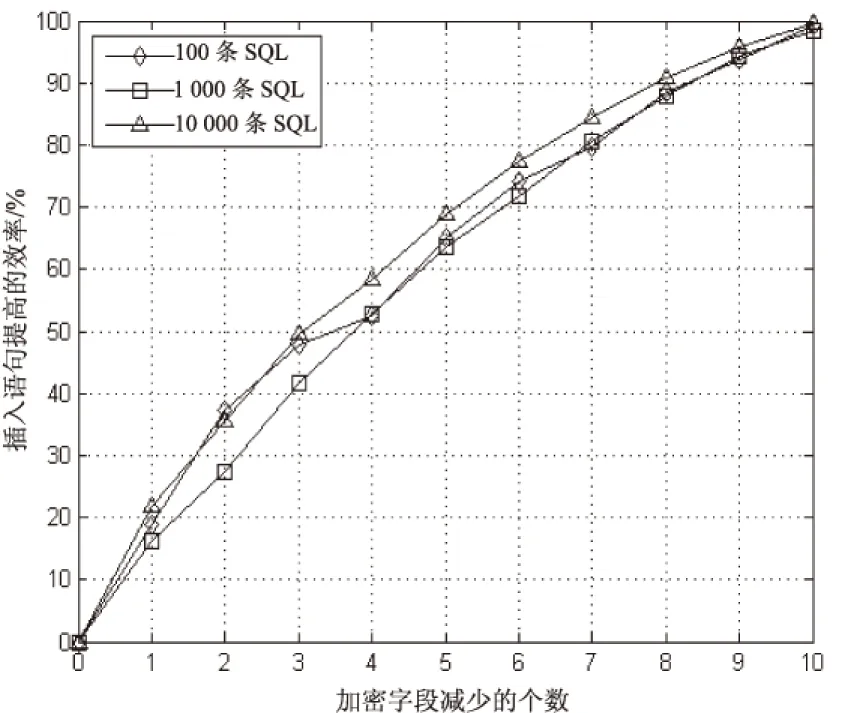
图2 数值型数据插入语句提高的效率
图3是在加密字段减少个数递增的情况下,字符型数据插入语句效率提高的曲线图。
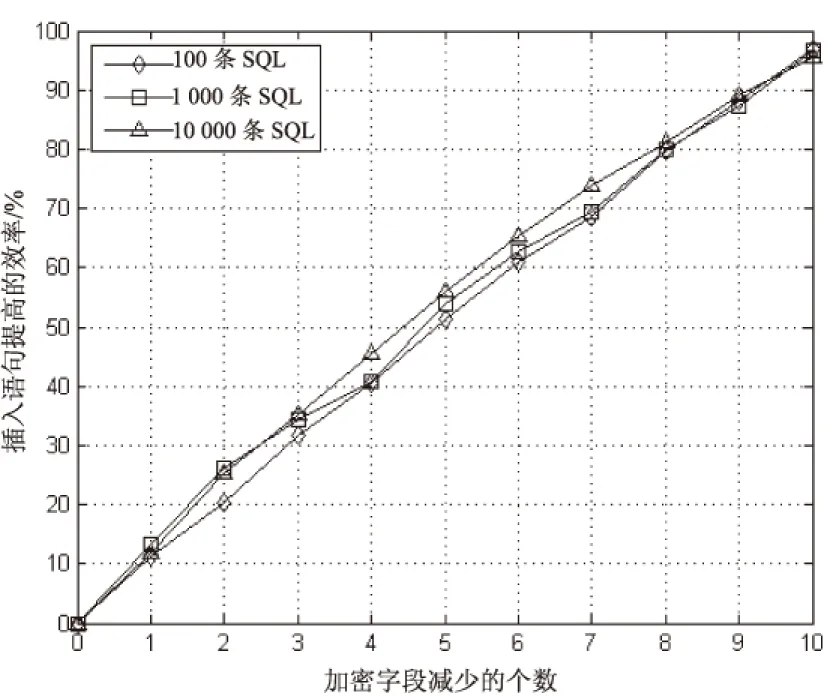
图3 字符型数据插入语句提高的效率
从图2和图3的变化趋势可以直观看到,加密字段减少个数与插入语句提高的效率成正比,与之前的理论分析相符。
5 结束语
针对开源密文数据库系统CryptDB必须对数据库全部字段进行加密而导致性能过低的问题,提出了一种用户自定义敏感字段检测算法,在满足用户对数据表安全性需求的基础上动态计算出敏感字段,并依此在CryptDB系统中实现选择加密策略并且取得了理想的实验结果。实验结果表明,在保证原系统所有功能正常工作且不降低安全性的前提下,能够提高密文计算的效率,使得执行插入语句提高的效率与加密字段减少的个数成正比,且能减少数据表存储空间,增加CryptDB的实用性和灵活度。
未来的工作重点将围绕以下几点展开:将CryptDB部署在并行环境中,进一步提高密文计算效率;CryptDB中只支持对整形的加法,可以构造支持浮点计算的洋葱,进一步完善CryptDB。
[1] 王于丁,杨家海,徐 聪,等.云计算访问控制技术研究综述[J].软件学报,2015,26(5):1129-1150.
[2] Chor B,Goldreich O,Kushilevitz E,et al.Private information retrieval[J].Journal of the ACM,1998,45(6):965-981.
[3] Song D X,Wagner D,Perrig A.Practical techniques for searches on encrypted data[C]//IEEE symposium on security and privacy.[s.l.]:IEEE,2000:44-55.
[4] Li J,Wang Q,Wang C,et al.Fuzzy keyword search over encrypted data in cloud computing[C]//International conference on computer communications.New Jersey:IEEE Press,2010:441-445.
[5] Cao N,Wang C,Li M,et al.Privacy-preserving multi-keyword ranked search over encrypted cloud data[J].IEEE Transactions on Parallel and Distributed Systems,2014,8(6):222-233.
[6] Rivest R L,Adleman L,Dertouzos M L.On data banks and privacy homomorphisms[M]//Foundations of secure computation.New York:Academic Press,1978:169-179.
[7] Raluca A,Popa N,Zeldovich H,et al.CryptDB:a practical encrypted relational DBMS[R].[s.l.]:[s.n.],2011.
[8] Fu Y J,Xiao N,Liao X K,et al.Application-aware client-side data reduction and encryption of personal data in cloud backup services[J].Journal of Computer Science and Technology,2013,28(6):1012-1024.
[9] 张伯雍,何泾沙.基于安全策略的动态加密技术研究[J].电子设计工程,2016,24(5):19-21.
[10] Curino C A,Jones E P C,Popa R A,et al.Relational cloud:a database-as-a-service for the cloud[C]//Fifth Biennial conference on innovative data systems research.Asilomar,CA,USA:[s.n.],2011:235-240.
[11] Li M,Yang C,Tian J.Video selective encryption based on Hadoop platform[C]//IEEE international conference on computational intelligence and communication technology.[s.l.]:IEEE,2015:208-212.
[12] Popa R A,Li F H,Zeldovich N.An ideal-security protocol for order-preserving encoding[C]//IEEE symposium on security and privacy.[s.l.]:IEEE,2014:463-477.
[13] Liu B,Baas B M.Parallel AES encryption engines for many-core processor arrays[J].IEEE Transactions on Computers,2013,62(3):536-547.
[14] He X,Machanavajjhala A,Ding B.Blowfish privacy:tuning privacy-utility trade-offs using policies[C]//Proceedings of the 2014 ACM SIGMOD international conference on management of data.[s.l.]:ACM,2013:1447-1458.
Investigation on Selective Encryption Strategy with CryptDB
ZHANG Cheng-guo,YANG Geng,WANG Wei
(College of Computer Science,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
In order to protect privacy of sensitive data stored on the cloud,encrypting data is a feasible way.Computing on the encrypted data without decrypting is becoming a research hotspot.Combining selective encryption strategy with CryptDB,an encrypted database system which supports selective encryption strategy is proposed to improve the performance of encrypting and decrease the storage space.Since the use of multiple onion encryption models,data should be encrypted into several copies by CryptDB to adapt different situations.Encrypting non-sensitive fields will experience high computation time and increase storage space.A user-defined sensitive field detection algorithm is proposed and implemented through creating and registering the plain onion within original system,modifying the metadata tables,and intercepting and revising the SQL queries.With the context meeting the user’s requirements of data security,the experimental results show that the scheme decreases the time of computation and storage space with the number of encrypted fields decreasing and makes the system more efficient and practical.
selective encryption;cipher computing;CryptDB;encrypted database;onion encryption
2016-05-22
2016-09-08
时间:2017-02-17
国家自然科学基金资助项目(61572263,61272084)
张成果(1991-),男,硕士研究生,研究方向为密文数据库、数据隐私保护;杨 庚,博士,教授,博士生导师,CCF高级会员,研究方向为网络与信息安全、分布与并行计算、大数据隐私保护。
http://www.cnki.net/kcms/detail/61.1450.TP.20170217.1634.088.html
TP302
A
1673-629X(2017)03-0136-06
10.3969/j.issn.1673-629X.2017.03.028
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17
电脑爱好者(2021年23期)2021-12-08
综艺报(2020年21期)2020-11-30
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
电脑爱好者(2019年17期)2019-10-30
办公室业务(2019年13期)2019-08-01
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
