
日本国立国会图书馆网络资源收集保存事业(WARP)及其启示
2017-03-21 06:06:22,,,,,
中华医学图书情报杂志 2017年12期
, ,,,,
随着信息技术和互联网的迅速发展,人们已经习惯并依赖通过网络发布和获取各类信息。但是网络信息资源更新快、所依赖的载体不稳定,其长期保存问题备受关注。20世纪90年代以来,以欧美为首的发达国家相继开展了网络信息资源保存项目,具有代表性的有英国国家图书馆的UK Web Archive项目、英国国家档案馆的UK Government Web Archive项目、美国国会图书馆(Library of Congress)的LC Web Archives 项目、澳大利亚国家图书馆(National Library of Australia)的PANDORA项目、新西兰国家图书馆的Web Archive项目和瑞典的Kulturarw3项目及日本国立国会图书馆(National Diet Library,NDL)的WARP项目。
日本国立国会图书馆是日本最大的公共图书馆,肩负着保存日本文化财产的使命。网络信息资源收集和保存实验项目(Web Archiving Project,WARP)是NDL于2002年开始实施的网络信息资源收集和保存项目。本文拟通过对WARP的基本情况、具体特点、特色保存项目及取得成效的分析及介绍,希望为我国信息资源收集与保存提供些许借鉴。
1 日本国立国会图书馆WARP的产生与进展
NDL于2002年开始实施网络信息资源收集和保存实验项目WARP,之后为实现更广范围的收集,开展了“关于日本网页的收集、累积及保存方法的调查(2004年10月至2005年3月)”、“网络信息收集保存相关制度的意见征集(2005年7月)”等多项调查,并就收集方法、收集对象等进行了多次研讨。2009年7月10日,日本公布了修订后的《国立国会图书馆法》,规定NDL可收集、保存国家等公共机构的网站信息。伴随着该法的实施,2010年4月1日,该项目正式更名为“网络资源收集保存事业”。2012年7月NDL制定了《我们的使命·目标2012~2016》计划书,将“各类资料、信息的收集与保存”列为未来5年要实现的6个战略性目标之一。该目标是继“辅佐国会活动”之后的第二大目标,进一步明确规定了要广泛收集、保存各公共机构的网站和收集这些网站提供的各类资源的任务。
2 WARP的工作机制
2.1 收集对象
《国立国会图书馆法》第24条规定,WARP的收集对象包括国家机关、都道府县、政令指定的都∕市、市町村、市町村合并后的法定合并协议会、独立行政法人及特殊法人等法人、机构、大学、地方公共团体、地方公社等网站,各类活动的相关信息及电子期刊等。
2.2 收集过程
WARP的收集过程包括选定、收集、组织、保存、公开等环节(图1)。随着网络信息资源不断更新,WARP定期进行收集、组织和记录各类信息资源的变化并进行长期保存,视情况提供利用。

图1 WARP的收集过程
2.3 收集方法
WARP利用网络机器人对网页进行自动收集。机器人首先确定收集对象网站,设置起点网址URL。在收集该网页html文件的同时,对文件内的信息资源进行解析,然后收集文字、图片、视频、音频等。
接着移动到该网页链接的其他网页,继续重复相同的工作(图2)。
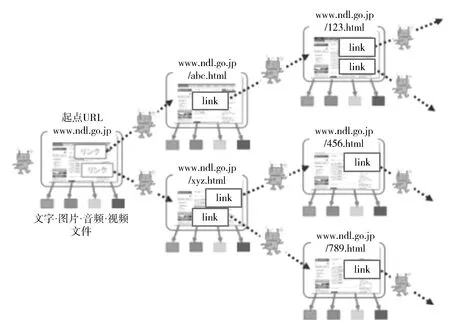
图2 WARP网络机器人的网页收集流程[1]
2.4 收集频率
针对不同的收集对象,WARP的收集频率具体如表1所示。
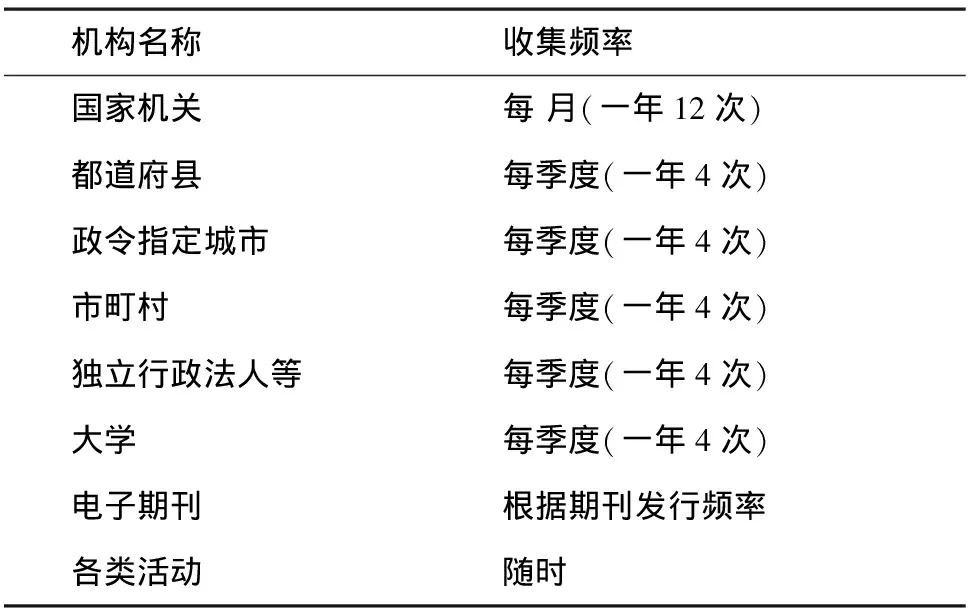
表1 WARP的收集频率[1]
2.5 收集策略
NDL针对不同的情况采取了全面收集和选择性收集两种策略。首先,对于法律有明文规定、无须获得所有权人许可即可收集的网站,采取全面收集策略,全面系统地获取资源内容;其次,对于需要取得所有权人许可才能收集的网站,则选定收集主题,进行选择性的收集[2]。这样既能全面系统地获取公立网站的资源和尽可能多地获取各个方面的资源,又能有重点地选择其他机构网站的资源和有针对性地获取有价值的私有网站的信息资源。
3 WARP的特色保存项目
WARP自实施以来,产生了许多特色保存项目,以下4项最具代表性。
3.1 消失的市町村网页
1999-2010年,被称为“平成大合并”的市町村合并运动在日本全国大规模地兴起。根据总务省的统计,市町村数量由3 232个减少到1 719个,约1 500个市町村网站在网络上消失了。WARP将这些失效的网页以及合并协议会网站,在取得发布者许可后保存下来,部分网页依据著作权者的意向供读者在馆内阅读[3]。
3.2 网络出版物
日本国内的机关、自治体、大学等机构的网站,发布了大量有价值的电子文件,包括白皮书、会议资料、报告书、年报、论文等。NDL从这些网站中选择性收集白皮书、会议资料、报告书、年报、论文等出版物及著作并保存,添加题名及著作者信息等,方便用户查找及阅读。
3.3 都道府县公报
都道府县的公报除登载地方公共团体制定和颁布的条例及法规外,还发布相关的公告、告示等信息。通过NDL的WARP项目,用户可以在网上浏览全国各地所有的都道府县公报。
3.4 东日本大地震网页存档项目
2011年3月11日,日本东北部海域发生里氏9.0级地震并引发海啸,造成重大人员伤亡和财产损失。4月1日,日本内阁会议决定将此次地震称为“东日本大地震”。WARP对东日本大地震的相关网页进行重点收集与保存,并建立了存档项目——“雏菊”。除了高频率地收集震后国家机关、受灾地区自治体的网页,还积极地收集与保存NPO(Non-profit organization)、NGO(Non-govern mental organization)、志愿者团体、各类学会及协会、企业等进行相关支援活动的机构的网页信息,包括数字化的文本、图片、音频、视频等。
4 WARP所取得的成效
4.1 资源保存数量大、类型多、范围广
由表2和表3可以看出,WARP保存的网络信息资源数量大、类型多,达到了《我们的使命·目标2012~2016》计划书中第二大目标——“各类资料、信息的收集与保存”提出的广泛收集、全面保存的目的[4]。仅2015年一年,WARP保存的文件数量就近40亿。
WARP项目自2002年实施以来,收集的主题数量和数据量逐年递增,已逐渐成为NDL数字资源长期保存及资源建设的重要组成部分,对全面保存国家文化财产及数字文化遗产发挥了不可替代的作用。
WARP用户浏览量不断增加,取得了良好反响。因为WARP保存的网络信息资源,用户可以通过浏览永久保存的历史网页,欣赏旧时网页的风采(如消失的市町村网页等);通过对事件的搜索,关注重大历史事件,览尽历史的发展历程,感受时代的进步(如国会网页等);还可通过关注网页数据,研究深层联系、进行数据分享、挖掘信息世界的潜在秘密(如各类学会及学会统计数据网页等)。

表2 WARP收集的文件数量及数据量(2002-2015年)[5]
注:以网页文件中具体包括的pdf、png等格式的文件数量计

表3 WARP保存的文件类型、数量及所占比例(2015年)[5]
4.2 资源保存针对性、专业性强
WARP的特色保存项目,如消失的市町村网页、都道府县公报及大地震网页保存等,都是WARP针对性进行收集与保存的体现,同时也体现了其超强的专业性。日本是一个自然灾害多发的国家,NDL通过“东日本大地震”网页存档项目,不仅对此次地震、海啸、核泄漏、复兴重建、核电站事故等内容进行了收集与保存,还对各类学术研究、防灾对策、灾害救援、志愿支持、自救互救等信息进行了保存与记录[6]。通过对“东日本大地震”这类自然灾害原始记录的收集、救灾过程及方法的记录、灾后重建过程的保存,既可为专家、学者进行科学分析与学术考察提供丰富的资料,又可为今后的灾害救援提供专业性指导和后世及各国提供借鉴。
5 WARP的特点及启示
5.1 积极进行技术开发
WARP项目的实施离不开技术支持,资源收集机器人(Heritrix)、全文搜索引擎(Solr)、文件保存格式(WARC)、浏览应用(Wayback)等各项技术的开发与应用,为WARP的顺利实施提供了技术保障。
网络信息资源管理人员要根据项目的实施情况,不断研发技术、完善系统,改进网络信息资源收集与保存的技术与环境,为项目的顺利实施提供坚实的技术保障。在资源选择及收集策略上,做到具体情况具体分析,根据不同网站采取不同策略,尽可能全面收集,确保网络信息资源收集与保存的全面性和代表性。
5.2 加快推进立法工作
NDL在实施WARP项目的过程中,积极推进相关法律法规的颁布,为大规模收集和保存网络信息提供了法律保障。如2009年日本修订了《国立国会图书馆法》,2010年修订了《著作权法》。《国立国会图书馆法》第二十五条第三款规定,为了达到协助国政审议的目的,NDL有权收集国家与地方公共团体等公有机构发布在网站上的资料;《著作权法》第四十二条第四款规定,国会图书馆基于法律收集网络信息资料,无须取得著作权人的许可[5]。新法的实施为NDL的WARP项目提供了明确的法律依据与保障。
由此可见,网络信息资源的收集与保存离不开立法工作。很大一部分网络信息属于公共领域资源,但随着版权、知识产权问题越来越受到重视,网络信息也逐渐被纳入知识产权的保护范围。我国也应强化这方面的立法工作,重视版权及知识产权问题,将版权法中的相关条文合理地利用到网络信息资源收集与保护项目中。
5.3 完善健全呈缴本制度
《国立国会图书馆法》(1948年法律第5号)规定,凡是日本国内发行的出版物,都有向国立国会图书馆呈缴的义务。缴送的出版物包括图书、杂志、报纸、DVD、乐谱、地图等。这些出版物是国民共有的文化财产,为现在及将来的读者所有并将代代传承。2008年,日本为纪念呈缴本制度实施60周年,规定每年的5月25日为“呈缴本日”。1949年、2000年和2004年,《国立国会图书馆法》在修订时多次对呈缴本制度的对象、义务及相关规定进行补充,不断完善健全呈缴本制度。此外,日本还设计了专门的“呈缴本制度普及标志”,并设有专门的呈缴本制度审议会。审议会与NDL就网络资源的保存、规定等定期召开会议进行研讨,确保了网络信息资源的收集与保存有法可依。
我国对传统印刷出版物和实体电子出版物的呈缴都有相关的规定,但并没有一部完整的呈缴法规,网络信息呈缴的普及率也不是很高。为了更好地保护网络信息资源,应将其列入法定呈缴的行列,明确规定呈缴的范围、数量、时间、方式等,使其得到相关的法律保障。
5.4 主动开展协同合作
网络信息资源的收集与保存是一个复杂的过程,单靠一个机构或部门是很难完成的。WARP主动借鉴其他国家网络信息资源收集与保存的相关技术,与世界各国的国立图书馆、国会图书馆及图书馆相关机构合作,进行信息共享、经验交流,积极推进电子信息时代与海外各国的协作。
我们要加强与国内外各相关机构的联系,积极了解其做法与措施、学习先进经验,取长补短,探索出适合我国网络信息资源收集与保存事业发展的技术与方法、适合中文互联网的收集保存方案,为保留中华文明优秀文化遗产做出贡献。
6 结语
中国国家图书馆2003年着手进行网络信息资源保存的试验,启动了网络信息资源收集与保存实验项目(Web Information Collection and Preservation,WICP)[7]。该项目以500家网站(政府网站、电子期刊网站、大学网站、企业网站及其他相关网站各100家)为收集对象,通过对网络信息的发现、选择、描述、分类、整合及编目,旨在探索适合中国国情的网络信息收集与保存方法及路径。该项目目前已经保存了大量专题信息并在继续完善[8]。此外,北京大学网络实验室在国家“973”和“985”项目的支持下,于2002年开发建设了中国网页历史信息存储与展示系统“中国Web信息博物馆”(Web of Infomall)[9]。目前已经有90亿以中文为主的网页,但网页信息只更新到2011年,在更新维护上与国外相比还有些差距。与日本相比,我国在网络信息资源收集与长期保存研究方面,存在资源选择不够全面、更新维护速度较慢等问题,特别是在技术开发、立法工作及协同合作方面有一定差距。
NDL的WARP项目起步较欧美稍晚,但自该项目实施以来,在技术开发、资源选择、立法工作、协同合作等方面认真探索,立足本馆实际、结合本国国情,逐渐形成具有本国、本馆特色的网络信息收集保存事业,在国内外取得良好反响,也成为NDL网上在线服务的生力军。借鉴日本国立国会图书馆WARP项目的经验,对我国发展网络信息资源的收集保存事业具有重要的参考意义。
猜你喜欢
近代史学刊(2018年2期)2018-11-16 09:20:04
电子制作(2018年10期)2018-08-04 03:24:38
小太阳画报(2018年1期)2018-05-14 17:19:25
电子制作(2017年2期)2017-05-17 03:54:56
少年博览·小学低年级(2016年10期)2016-11-24 06:48:23
电子测试(2015年18期)2016-01-14 01:22:58
环球时报(2015-01-09)2015-01-09 21:38:51
小天使·一年级语数英综合(2014年8期)2014-06-26 14:42:04
计算机与网络(2014年7期)2014-03-25 10:57:07
