
基于大数据技术的告警日志数据分析
2017-03-07 16:39应俊
移动通信 2016年23期
应俊
摘要:为了更好地满足运营商对海量非结构化数据的处理需求,主要以网络告警日志数据为例,详细阐述如何利用Hadoop+Spark大数据技术挖掘和分析海量的数据,进而提高网络监控效率。
关键词:告警数据 Hadoop Spark
1 引言
随着电信网络的不断演进,全省数据网、交换网、接入网设备单月产生告警原始日志近亿条。以上告警通过网元网管、专业综合网管、智能网管系统[1]三层收敛,监控人员每月需处理影响业务或网络质量的告警事件为20万条,但一些对网络可能造成隐患的告警信息被过滤掉。如何从海量告警数据中获取与网络性能指标、运维效率相关的有价值的数据,对于传统的关系型数据库架构而言,似乎是一个不可能完成的任务。
在一般告警量情况下,ORACLE数据处理能力基本可以满足分析需求,但当告警分析量上升到亿级,如果采用传统的数据存储和计算方式,一方面数据量过大,表的管理、维护开销过大,要做到每个字段建索引,存储浪费巨大;另一方面计算分析过程耗时过长,无法满足实时和准实时分析需求。因此必须采用新的技术架构来分析处理海量告警信息,支撑主动维护工作显得尤为必要,为此我们引入了大数据技术。
2 分析目标
(1)数据源:电信运营商网络设备告警日志数据,每天50 G。
(2)数据分析目标:完成高频翻转类(瞬断)告警分析;完成自定义网元、自定义告警等可定制告警分析;完成被过滤掉的告警分析、TOPN告警分析;核心设备和重要业务监控。
(3)分析平台硬件配置:云计算平台分配8台虚拟机,每台虚机配置CPU16核;内存32 G;硬盘2 T。
3 制定方案
进入大数据时代,行业内涌现了大量的数据挖掘技术,数据处理和分析更高效、更有价值。Google、Facebook等公司提供可行的思路是通过类似Hadoop[2]的分布式计算、MapReduce[3]、Spark[4]算法等构造而成的新型架构,挖掘有价值信息。
Hadoop是Apache基金会用JAVA语言开发的分布式框架,通过利用计算机集群对大规模数据进行分布式计算分析。Hadoop框架最重要的两个核心是HDFS和MapReduce,HDFS用于分布式存储,MapReduce则实现分布式任务计算。
一个HDFS集群包含元数据节点(NameNode)、若干数据节点(DataNode)和客户端(Client)。NameNode管理HDFS的文件系统,DataNode存储数据块文件。HDFS将一个文件划分成若干个数据块,这些数据块存储DataNode节点上。
MapReduce是Google公司提出的针对大数据的编程模型。核心思想是将计算过程分解成Map(映射)和Reduce(归约)两个过程,也就是将一个大的计算任务拆分为多个小任务,MapReduce框架化繁为简,轻松地解决了数据分布式存储的计算问题,让不熟悉并行编程的程序员也能轻松写出分布式计算程序。MapReduce最大的不足则在于Map和Reduce都是以进程为单位调度、运行、结束的,磁盘I/O开销大、效率低,无法满足实时计算需求。
Spark是由加州伯克利大学AMP实验室开发的类Hadoop MapReduce的分布式并行计算框架,主要特点是弹性分布式数据集RDD[5],中间输出结果可以保存在内存中,节省了大量的磁盘I/O操作。Spark除拥有Hadoop MapReduce所具有的优点外,还支持多次迭代计算,特别适合流计算和图计算。
基于成本、效率、复杂性等因素,我们选择了HDFS+Spark实现对告警数据的挖掘分析。
4 分析平台设计
4.1 Hadoop集群搭建
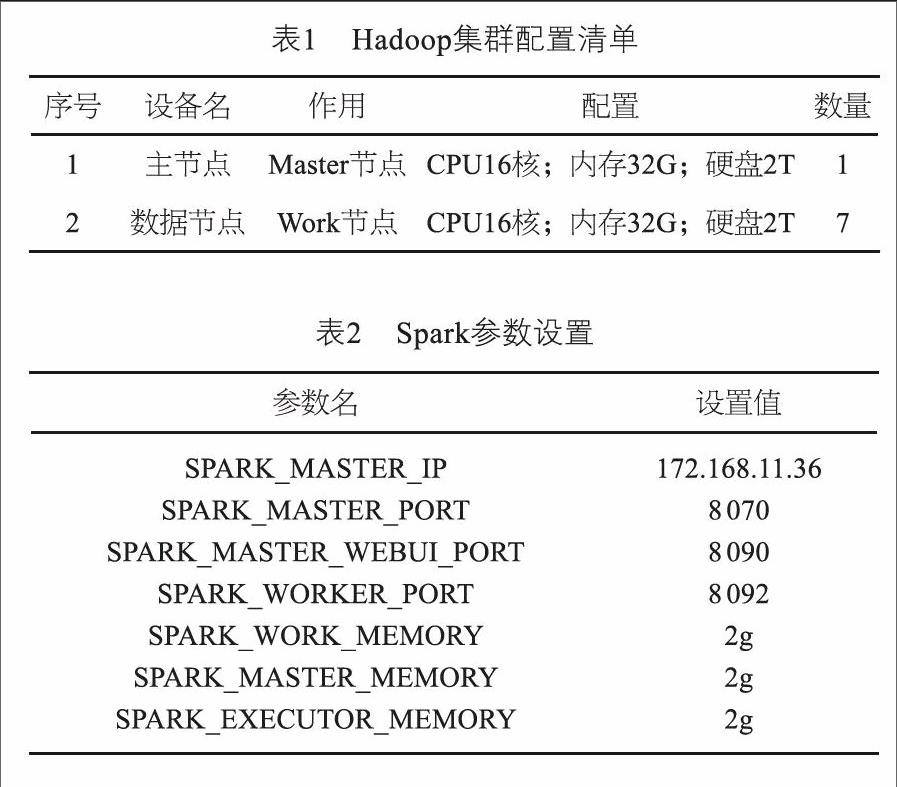
基于CentOS-6.5系统环境搭建Hadoop集群,配置如表1所示。
4.2 Spark参数设置[6]
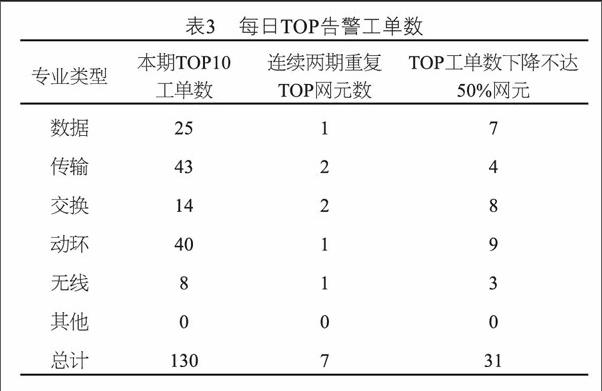
Spark参数设置如表2所示。
4.3 数据采集层
数据采集:由于需采集的告警设备种类繁多,故采取分布式的告警采集,数据网设备、交换网设备、接入网设备分别通过IP综合网管、天元综合网管、PON综合网管进行采集,采集周期5分钟一次。采集机先将采集到的告警日志文件,通过FTP接口上传到智能网管系统文件服务器上,再对文件进行校验,通过Sqoop推送到Hadoop集群上。
4.4 逻辑处理层
(1)建立高频翻转告警监控工作流程
先将海量告警进行初步删选,通过数量、位置和时间三个维度的分析,得出高频翻转类告警清单列表,最后由专业工程师甄别确认,对某类告警进行重点关注和监控。
(2)差异化定制方案
按组网架构细分,针对核心重要节点的所有告警均纳入实时监控方案;
按业务网络细分,针对不同业务网络设计个性化的监控方案;
按客户业务细分,针对客户数字出租电路设计个性化的监控方案。
4.5 数据分析层
Spark读取Hive[7]表的告警数据,然后在Spark引擎中进行SQL统计分析。Spark SQL模塊在进行分析时,将外部告警数据源转化为DataFrame[8],并像操作RDD或者将其注册为临时表的方式处理和分析这些数据。一旦将DataFrame注册成临时表,就可以使用类SQL的方式操作查询分析告警数据。表3是利用Spark SQL对告警工单做的一个简单分析:
5 平台实践应用
探索运维数据分析的新方法,利用大数据分析技术,分析可能影响业务/设备整体性能的设备告警,结合网络性能数据,找到网络隐患,实现主动维护的工作目标。
5.1 高频翻转类告警监控
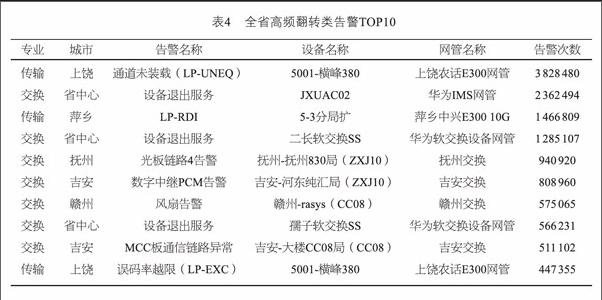
首先制定了高频翻转类告警分析规则,将连续7天每天原始告警发生24次以上定义为高频翻转类告警,并基于大数据平台开发了相应的分析脚本,目前已实现全专业所有告警类型的分析。表4是全省高频翻转类TOP10排名。
5.2 核心设备和重要业务监控
目前以设备厂商或专家经验评定告警监控级别往往会与实际形成偏差,主要表现在以下几个方面:监控级别的差异化设定基于已知的告警类型,一旦网络重大故障上报未知的告警类型就无法在第一时间有效监控到;同一类型的故障告警出现在不同网络层面可能影响业务的程度是完全不同的;不同保障级别的客户对故障告警监控的实时性要求也是不同的。
通过大数据分析平台对差异化监控提供了灵活的定制手段,可根据告警关键字,分专业、地市、网管、机房、告警频次等维度自主定制需要的告警数据,实现日、周、月、某个时间区等统计分析。
应用案例:省NOC通过大数据分析出一条编号为CTVPN80113的中国平安大客户电路在一段时间内频繁产生线路劣化告警,但用户未申告,省NOC随即预警给政企支撑工程师,政支工程师与用户沟通后,派维护人员至现场处理,发现线路接头松动,紧急处理后告警消除、业务恢复。
5.3 被过滤告警分析
全省每天网络告警数据300万条~500万条,其中99%都会根据告警过滤规则进行过滤筛选,把过滤后的告警呈现给网络监控人员。过滤规则的准确性直接影响告警数据的质量。一般来说告警过滤规则可以从具有丰富运维经验的网络维护人员获得,但是这个过程非常繁琐,而且通过人工途径获得的告警过滤规则在不同的应用环境可能存在差异,无法满足网络维护的整体需要。采用大数据技术对被过滤的告警进行分析可以很好地完善过滤规则,让真正急迫需要处理的告警优先呈现给维护人员及时处理,真正做到先于客户发现故障。表5是动环专业被过滤的告警情况分布。
5.4 动环深放电分析
动环网管通过C接口采集蓄电池电压数据,在停电告警产生之后,电压数据首次下降到45 V,表示该局站电池出现深放电现象,通过计算这一放电过程的持续时间,记为深放电时长,该时长可以初步反映电池的放电性能。一个局站每天产生几十万条电压等动环实时数据。
在告警数据分析的基础上,实现对蓄电池电压变化数据的分析,提醒分公司关注那些深放电次数过多和放电时长过短的局站,核查蓄电池、油机配置、发电安排等,并进行整治。利用Spark SQL统计了一个月内抚州、赣州、吉安三分公司几十亿条动环数据,分析了其中深放电的情况如表6所示。
6 结论
本文利用HDFS+Spark技术,实验性地解决告警数据存储和分析等相关问题:一是通过数据分析,从海量告警数据中发现潜在的网络隐患;二是结合资源信息和不同专业的告警,最终为用户提供综合预警;三是转变网络监控思路和方式,通过数据汇聚、数据相关性分析、数据可视化展示,提高了网络监控效率;最后还扩展到对动环实时数据、信令数据进行分析。
从实际运行效果来看,HDFS和Spark完全可以取代传统的数据存储和计算方式,满足电信运营商主动运维的需求。
参考文献:
[1] 中国电信股份有限公司. 中国电信智能网管技术规范-总体分册[Z]. 2015.
[2] Tom white. Hadoop权威指南[M]. 4版. 南京: 东南大学出版社, 2015.
[3] RP Raji. MapReduce: Simplified Data Processing on Large Clusters[Z]. 2004.
[4] Spark. Apache Spark?[EB/OL]. [2016-11-27]. http://spark.apache.org/.
[5] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, et al. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing[J]. Usenix Conference on Networked Systems Design & Implementation, 2012,70(2): 141-146.
[6] 許鹏. Apache Spark源码剖析[M]. 北京: 电子工业出版社, 2015.
[7] Hive. Apache HiveTM[EB/OL]. [2016-11-27]. http://hive.apache.org/.
[8] Holden Karau, Andy Konwinski, Patrick Wendell, et al. Learning Spark: Lightning-Fast Big Data Analysis[M]. Oreilly & Associates Inc, 2015.
[9] 员建厦. 基于动态存储策略的数据管理系统[J]. 无线电工程, 2014,44(11): 52-54.
[10] 杨毅. 一种基于网格优化的空间数据访问与存储
研究[J]. 无线电通信技术, 2014,40(6):43-46. ★
