
三层架构数据库设计
2017-03-06 00:29曹树贵卢志舟刘娟高振华
软件导刊 2017年1期
关键词:数据库
曹树贵+卢志舟+刘娟+高振华

摘要摘要:以河北省教育考试统计分析系统为例,结合系统面向考试种类多、同类考试考次多、单次考试数据量大、各类考试基础字典数据及统计分析需求存在差异等特点,介绍了一种三层架构的数据库设计方案,包括:顶层公共数据库、第二层考试类别公共数据库、第三层考次成绩数据库。对各层数据库的表对象(Table)构成进行分析,并提出了跨库建立视图(View)以及存储过程中使用动态SQL语句的多层数据库跨库访问方法。
关键词关键词:教育考试;考试数据;数据库;三层架构
DOIDOI:10.11907/rjdk.162228
中图分类号:TP392文献标识码:A文章编号文章编号:16727800(2017)001014004
引言
三层架构数据库指将数据分布在不同层次的数据库上,分层依据如按类型、层次、粒度、用途、使用环境等。本文以河北省教育考试统计分析系统为例,介绍了一种三层架构数据库设计方案。该系统旨在对各类终结性教育考试和学生在校的过程性考试成绩进行统计分析,并针对不同的服务对象(学生、教师、学校、教研部门、教育行政部门)提供针对性的统计分析反馈报告[1]。系统具有面向考试种类多、同类考试考次多,单次考试数据量大、各类考试基础字典数据差异化以及统计分析需求存在差异等特点。因此,在数据库设计上需要基于这些特点采用针对性的解决方案。
1三层数据库架构
教育考试数据统计分析系统在数据库设计上具有单一数据库架构和多数据库架构两种解决方案。单一数据库架构指各类考试数据集中在一个数据库中,将同类数据存放在同一张数据表下,例如,各次考试的考生数据与各类考试的考试成绩数据各存放在一张数据库表中。多数据库架构则是将考试数据按一定规则分布在多个数据库中。
单一数据库架构的优点是针对数据库的编程逻辑相对简单,便于多次考试统计分析对比等,但缺点也显而易见。首先,数据库表记录行数庞大造成效率低下问题。由于系统需要管理多种类型的考试,每类考试又存在多次考试,单次考试数据量巨大,所以随着时间推移,数据库将存储累积海量数据。单表行数规模很容易达到千万级或亿级以上规模,使数据统计分析效率受到严重影响。另外,数据集中在单一数据库中也不利于解决不同类型考试在基础数据及统计分析需求方面的差异化问题。
综上,教育考试数据统计分析系统宜于采用多数据库架构。鉴于教育考试数据统计分析系统管理的考试有多种类别,每类考试既有共用数据,又有独有数据。同时每类考试又有多次考试,每次考试同样有该类考试的共用数据及独有数据,因此可采用三层数据库架构,把不同类型的考试数据分布在不同层次的数据库上。三层数据库架构由顶层TOP公共库、第二层类别公共库、第三层考次成绩数据库组成,如图1所示。
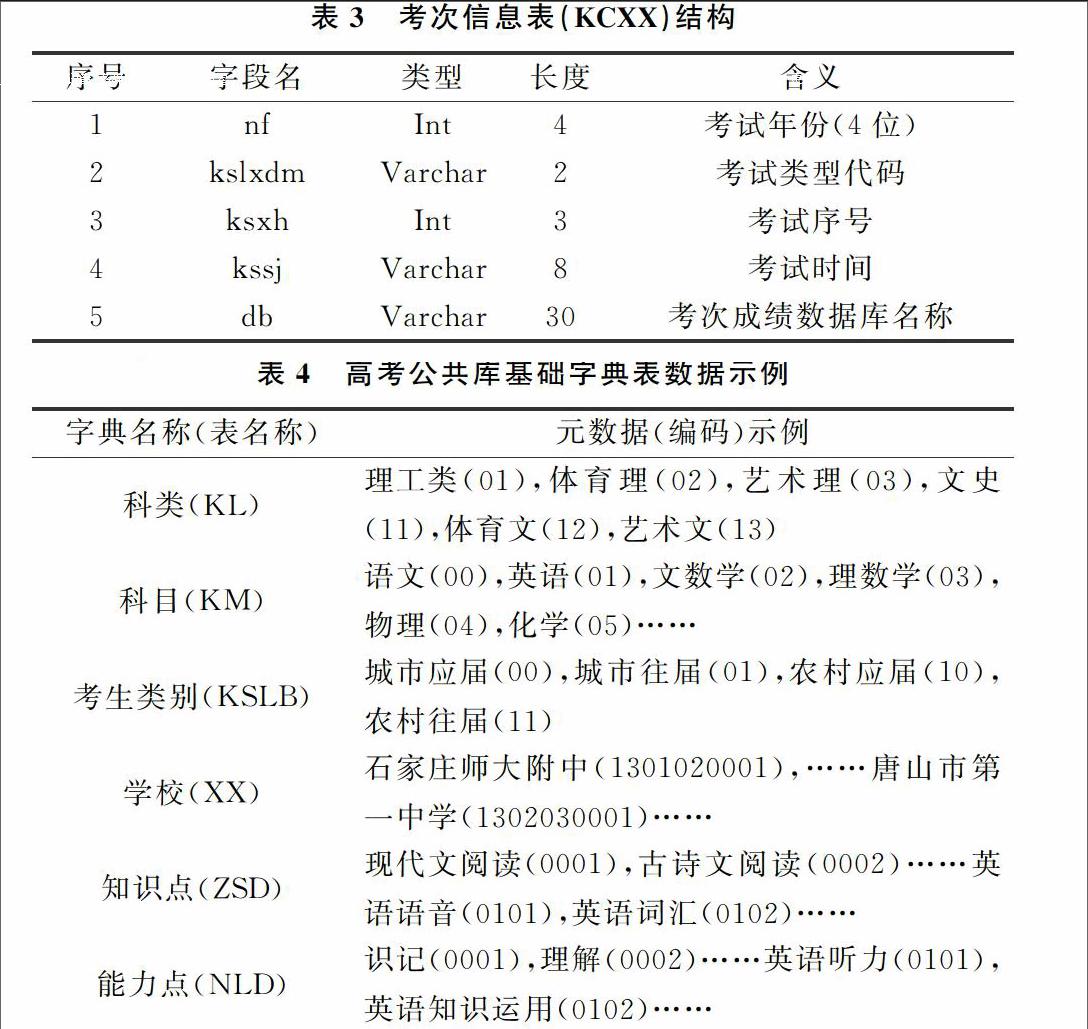
第一层,顶层公共库。用于存放各类型考试的公用数据,包括公用基础字典数据以及考次管理数据。顶层公共库可命名为:COMMOM_TOP。
第二层,类别公共库。例如高考公共库、高中过程性考试公共库、自学考试公共库、全国英语等级考试公共库、全国计算机等级考试公共库等,用于存放同一类型各次考试的公用数据,以及各次考试的统计汇总数据。类别数据库的命名方式为:COMMON_考试类别。例如,高考公共库命名为:COMMON_01,“01”为高考编码。
第三层,考次成绩数据库,用于存放某次考试的考生、试卷、成绩等数据。例如,2015年高考、2016年高考是高考的不同考次,考试成绩数据分别保存在不同的数据库中;石家庄高考模拟考试一、石家庄高考模拟考试二、石家庄高考模拟考试三是高中過程性考试的三次不同的考次,考试数据也分别存放在不同数据库中。考次成绩数据库的命名方式为:KC_考试年度_考试类型_序号。例如,2016年高考的数据库命名为:KC_2016_01_01,名称中第一个“01”代表高考,第二个“01”代表考试序号。
2各层数据库构成设计
2.1顶层公共库
顶层公共数据库存放各类型考试的共用数据,这些数据包括公用基础字典数据以及考次管理数据。
基础字典数据包括:考试类型、学校类别、试卷类型、题型、性别、行政区划等,如表1所示。
考次成绩数据库位于第三层,用于存放某次考试的考生、试卷、成绩等数据[2]。以下仍以高考考次成绩数据库为例,高考考次成绩数据库的表对象主要由考生信息表、考生成绩表、试卷信息表三大类构成,其中考生成绩表又可分为总成绩表以及单科成绩表,试卷信息表可以分为试题信息表、试卷知识结构表、试卷能力结构表(见表7)。图2反映了高考考次成绩数据库中各表之间的关联关系。
表7高考考次库表对象(部分)表名称表内容考生信息(ksxx)存放每个考生的个人信息,字段如:考生号、姓名、性别、身份证号、报名点学校、班级、考生类别、科类等考生成绩(zcj)存放每个考生的总成绩信息,字段如:考生号、总成绩考生单科成绩(dkcj_x)按科目存放每个考生的单科成绩信息,dkcj_x中随着科目不同而不同,如语文对应表名为dkcj_00,英语为dkcj_01……,字段如:考生号、单科总分、试题01得分、试题02得分、试题03得分……试题信息(stxx)存放每个科目的试题信息,字段如:科目、试题编号、试题分值、试题答案、主客观标志、选作标志等试卷知识结构(sjzsjg)存放每个科目各试题对应的知识点,字段如:科目、试题编号、知识点编号试卷能力结构(sjnljg)存放每个科目各试题对应的能力点,字段如:科目、试题编号、能力点编号图2高考考次成绩数据库主要表对象关系
3多层数据库跨库访问
三层数据库架构将数据分布在不同层次的数据库中,可有效解决前文所述的若干问题,但是将有一定关联关系的表分布在不同数据库中,也会带来访问上的不便。例如,考次成绩数据库中相应表的代码字段名称需要在顶层公共库或类别公共库访问到字典表才能获得;用于数据统计分析的存储过程以及数据统计结果分布在第二层类别公共库中,而统计数据来源于考次成绩库,需要有效解决跨库操作问题。针对以上问题,后文提供两种解决方法,分别为建立跨库视图以及在存储过程中使用动态SQL。
需要说明的是,河北省教育考试统计分析系统采用的是Mysql数据库系统,所以后文所述的SQL语句为基于Mysql数据库的语法。
3.1跨库视图建立
数据库视图(View)是基于多个表或远程表的虚拟表,是用户可以看见的虚关系。视图能提高数据库应用的灵活性,减少用户对数据库物理结构的依赖,同时产生比逻辑模型更符合用户需要的关系模型视图[3]。利用视图可以很好地解决数据表与字典表的连接问题,例如,将COMMON_TOP中的考试类型(KSLX)表引入为高考考次库(KC_2016_01_01)的视图V_KSLX,其创建语句为:
同样,可以将顶层公共库以及类型公共库的其它字典表引入到考次库,从而方便数据之间的关联访问。
3.2动态SQL
为了减轻客户端与数据库系统间网络I/O的负载,从而提高数据分析效率,系统采用存储过程来完成数据的查询处理[4]。如果存储过程和所访问的数据表在同一个数据库下,则在存储过程中可以直接书写SQL语句完成计算。例如在考高考次库(KC_2016_01_01)中建立一个存储过程sp_ks_tj,统计考生相关信息,其中包括对考生人数的统计,则存储过程中可直接书写如下SQL语句完成人数统计:
SELECT COUNT(1) FROM ksxx
而如果存储过程建立在高考公共库(COMMON_01)中,此时要访问考次库KC_2016_01_01中的考生人数,则SQL语句中ksxx表需要加上考次成绩数据库名称作为前缀,即:KC_2016_01_01.ksxx,而该存储过程需要适用于各个高考考次库,所以ksxx表的数据库前缀应该为变量(如@db),整个SQL语句应该为字符串变量(如@sql)。因此,在存储过程中需要构造字符串变量@sql,构造方法如下:
set @sql=CONCAT("SELECT COUNT(1) into @result FROM ",ls_db,".ksxx");
此时,虽然SQL语句已经构造出来,但仅仅是存放在字符串变量@sql中,还需要有一种机制来执行变量@sql所存储的语句,这里采用MYSQL数据库的prepare预处理语句组。MySQL prepare预处理语句组由预处理定义语句、预处理执行语句、预处理删除语句构成[5]。3个语句的简化语法格式如下所示:4结语
以河北省教育考试统计分析系统为例,结合系统面向考试种类多、同类考试考次多、单次考试数据量大、各類考试基础字典数据及统计分析需求存在差异等特点,介绍了一种三层架构的数据库设计方案,包括顶层公共数据库、类别公共库、考次成绩数据库。顶层公共库用于存放各类型考试的公用数据;类别公共库存放同一类型各次考试的公用数据,以及各次考试的统计数据;考次成绩数据库用于存放某次考试的考生信息、试卷信息、成绩信息等数据。针对分层架构的跨库访问,可以采用建立跨库视图以及在存储过程中执行动态SQL语句的方法。
三层架构的数据库设计方案已在河北省教育考试分析系统开发中得到实施,数据处理效率得到了有效提高,不同类型考试的差异化更易于处理。河北省教育考试系统数据库目前是基于单台数据库服务器,随着系统管理的考试类型逐步丰富,考次数量增加,以及考生个性化评测报告查询并发数量的增加,可逐步过渡到基于多台数据库服务器的数据库集群模式,而分层数据库架构更易于向集群模式过渡[6]。
参考文献:
[1]刘娟,高振华.化枯燥为神奇——高考数据统计分析报告“把脉”中学教学[J].考试与招生,2010(12):5354.
[2]张向兵.考试相关数据标准和统计分析[D].天津:天津大学,2007.
[3]汤国华,叶丹,徐罡,等.基于设计模式的通用数据库视图生成方法[J].计算机辅助工程,2008(1):7276.
[4]支春明.影响数据库性能的因素分析及改进策略[J].中国高新技术企业,2008(23): 152.
[5]SQL syntax for prepared statements[EB/OL].http://dev.mysql.com/doc/refman/5.7/en/sqlsyntaxpreparedstatements.html.
猜你喜欢
畜牧兽医杂志(2022年6期)2023-01-05
海洋石油(2021年3期)2021-11-05
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
中国学术期刊文摘(2016年4期)2016-03-31
中国期刊年鉴(2015年0期)2015-01-19
