
GPU在活塞销尺寸快速检测中的应用研究
2017-03-01 04:26:15周叶江赵永廷
计算机应用与软件 2017年1期
周叶江 郑 彬 赵永廷
(中国科学院重庆绿色智能技术研究院 重庆 400714)
GPU在活塞销尺寸快速检测中的应用研究
周叶江 郑 彬*赵永廷
(中国科学院重庆绿色智能技术研究院 重庆 400714)
近年来,工业上对工业标准件尺寸检测的研究重点逐渐转移到关注其“高速性”策略的研究,其中边缘信息的检测是最为重要且最耗时的过程。为此,针对活塞销尺寸检测提出一种基于GPU技术的方法。选用提取稳定、精度高的Hough算法作为检测直线的策略,结合现有边缘检测算法,对其主要步骤(高斯滤波、梯度计算、方向角计算及Otsu阈值化)的计算流程进行并行优化。使用相同实验样本,该方法能够在更短的时间内检测出活塞销的尺寸,与传统CPU实现方法对比,其平均效率有近15倍的提升。利用GPU实现活塞销尺寸快速检测的方法,为工业上实现检测的高速性提供一个高效可靠的解决途径,且有效地控制生产成本。
尺寸检测 直线检测 边缘提取 GPU技术 并行计算
0 引 言
活塞销是装在活塞裙部的圆柱形销子,广泛应用于轿车、中型车、工程机械类重型车等。它用来连接活塞和连杆,具有刚度大、强度高和表面质量好的特点[1]。然而在制造过程中销表面会产生各种尺寸缺陷,因此精确地检测出表面尺寸缺陷具有重大意义。由于活塞销具有严格的尺寸参数,传统地用万能工具显微镜、三坐标测量机等进行检测不仅损坏活塞销,而且大大降低了生产效率。现在一般采用机器视觉的方法,该方法通过工业相机采集图像,然后利用图像处理技术识别被测物体,最后设计算法实现检测。
机器视觉具有灵敏度高、设计灵活、非接触性、响应迅速等优点,使得其在工业中得到了广泛的应用,如在空瓶检测机器人、工业零件测量系统、工业机器人分拣系统、色差检测等领域都有应用。近年来,有关工业应用中的机器视觉技术,已经成为解决传统方法速度慢、精度低等不足的有效途径。机器视觉在工业中的应用研究,也引起了国内外学者的关注。
文献[1]针对圆柱形高精密零件曲率表面缺陷检测的问题,设计并实现了基于及其视觉的在线检测系统;文献[3]设计了一种基于三维激光扫描的移动大尺寸圆柱体工件长度快速检测系统;文献[4]基于水平投影法提取铁轨表面缺陷,采用逻辑操作组合检测结果,提出了一种铁轨表面缺陷的视觉检测与识别算法。
近年来GPU技术快速发展,由于GPU相比CPU在处理并行数据上的巨大优势,有关于GPU的应用研究逐渐成为热点。文献[5]使用NVIDIA的并行计算架构将SPH方法的全部处理过程在GPU上实现;文献[6]提出了一种基于GPU的逆时偏移并行加速算法。
本文研究了基于机器视觉的活塞销尺寸检测算法,并设计出机器视觉与尺寸检测系统。针对前期单独使用CPU进行尺寸检测速度慢的不足,有效利用GPU的优势,提出了一种基于GPU的活塞销尺寸检测方法。根据GPU内存的特点,各步骤合理分配GPU资源,同时部分只能串行执行的过程使用CPU进行处理,最终实现CPU-GPU协同工作模式。对比单独使用CPU,在保证精度的前提下检测速度具有极大提高。
1 CUDA与基于CPU的直线求取
1.1 CUDA通用并行计算结构
CUDA(Compute Unified Device Architecture) 是NVIDIA公司推出的一种通用并行计算平台和编程模型,中文名称即统一计算设备架构。在CUDA的架构下,一个程序可以分为两个部分:host端和device端。host端是程序在CPU上的执行部分,而device端是在GPU上的执行部分。GPU执行时的最小单位是thread,多个thread可以组成一个block,执行相同程序的block可以组成一个grid,如图1所示为线程组织结构。
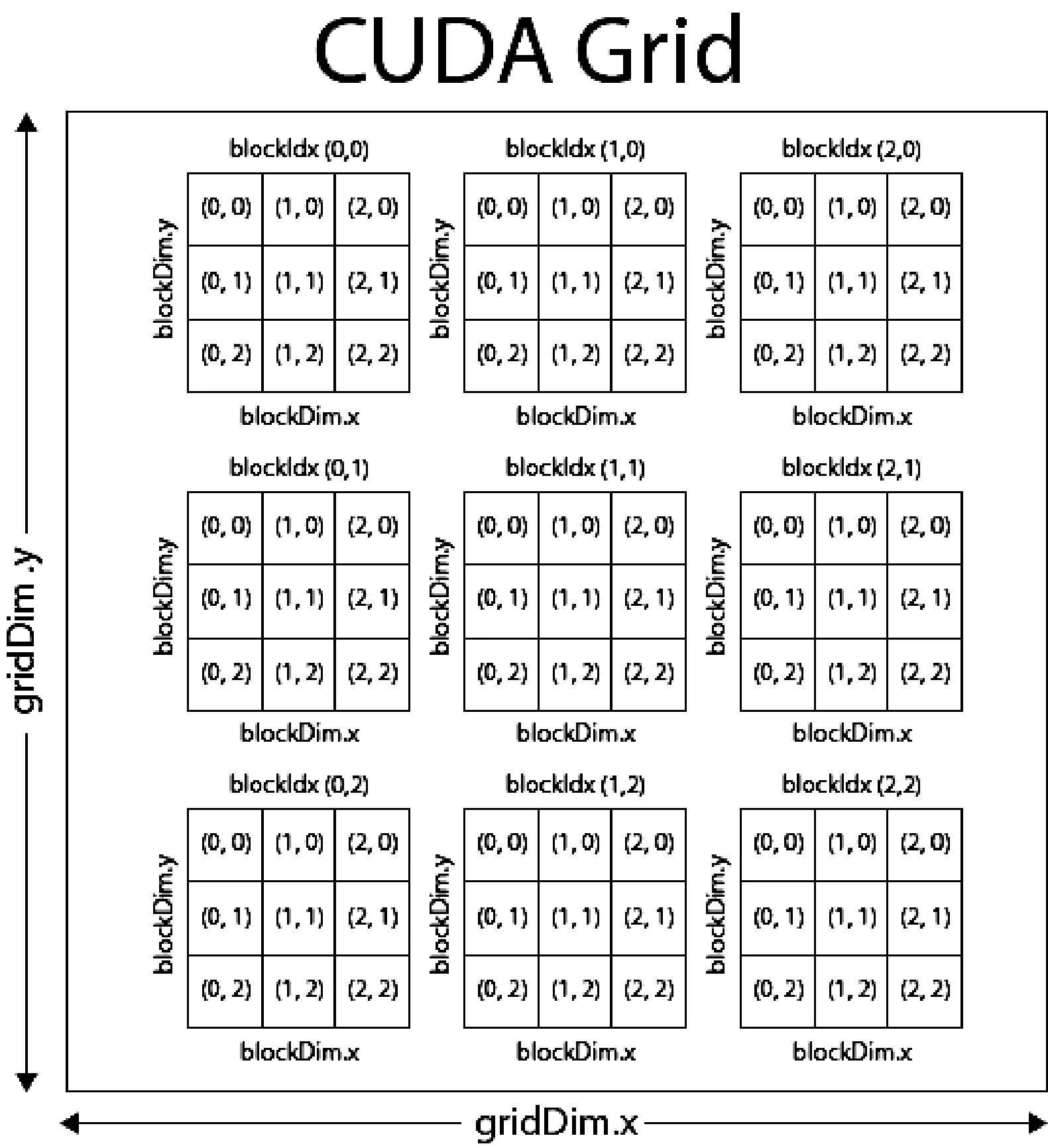
图1 线程结构
CUDA编程模型采用CPU+GPU的异构模式。CPU端代码生成原始数据,通过CUDA运行时函数库将这些原始数据传输到GPU上,然后启动CUDA内核函数进行运算,最后将运算结果从设备端传输到主机端[7]。
1.2 基于CPU的直线求取
工件检测系统中最主要且最耗时的工作为求取直线,主要分高斯滤波、梯度和方向角计算、非极大值抑制、Otsu阈值分割和Hough直线检测五个步骤。
1.2.1 高斯滤波
由于工业摄像头采集的图像受环境等因素的影响,第一步采用高斯滤波进行滤波,其平滑函数为:
(1)
令S[i,j]为平滑后的图像,用G[i,j;σ]对图像I[i,j]进行平滑,则图像与高斯平滑滤波器卷积表示为:
S[i,j]=G[i,j;σ]*I[i,j]
(2)
1.2.2 梯度和方向角的计算
高斯滤波之后进行梯度和方向角的计算,该过程使用一阶有限差分计算偏导数的两个阵列P与Q,已平滑数据阵列S[i,j]的梯度使用2×2的一阶有限差分来近似计算x与y偏导数的两个阵列P[i,j]与Q[i,j][8]:
P[i,j]≈(S[i,j+1]-S[i,j]+S[i+1,j+1]-S[i+1,j]/2)
(3)
Q[i,j]≈(S[i,j]-S[i+1,j]+S[i,j+1]-S[i+1,j+1]/2)
(4)
(5)
θ[i,j]=arctan(Q[i,j]/P[i,j])
(6)
式中,M[i,j]反映了图像的边缘强度,θ[i,j]反映了边缘的方向。使得M[i,j]取得局部最大值的方向角θ[i,j],就是边缘的方向。
1.2.3 非极大值抑制
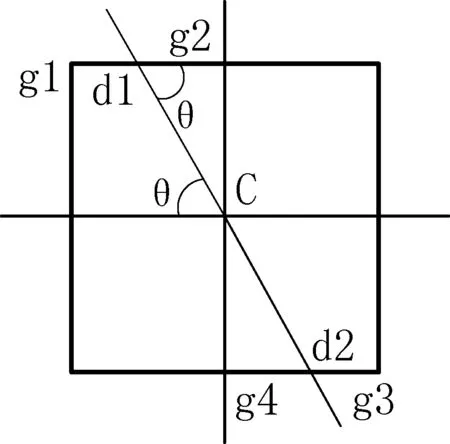
图2 非极大值抑制原理图
仅得到全局的梯度强度并不足以确定边缘。为确定边缘,必须保留局部梯度值最大的点,而抑制非极大值。非极大值抑制过程是利用梯度的方向,将待判断的像素点与邻域像素的梯度幅值进行比较。首先将梯度角的变化范围离散到圆周的四个扇区(0°,45°,90°,135°)之一,对应首3×3邻域内元素的四种可能组合,任何通过邻域中心的点必须通过其中一个扇区。图2为非极大值抑制原理图。
在图2中,黑色斜线方向为C点的梯度方向,局部最大值点位于该直线上,其中C点、d1、d2均可能是局部最大值点,因此需要首先确定像素点C的灰度值在其8邻域内是否为最大[9]。如若C点小于d1、d2两点中的其中任一个,即可说明C点不是局部极大值,则排除C点为边缘。用公式表示为:
N[i,j]=NMS(M[i,j],ζ[i,j])
(7)其中M[i,j]表示点C的位置,ζ[i,j]=Sector(θ[i,j]),即扇区的梯度值(Sector表示一个扇区)θ表示梯度值。
1.2.4Otsu阈值分割
由于每一次处理所使用的阈值不尽相同,所以采用自适应阈值的Otsu算法来确定其大小。对于图像I(x,y),前景和背景的分割阈值记为T,前景点数占图像比例为ω0,平均灰度为μ0;背景点数占图像比例为ω1,平均灰度为μ1;图像总平均灰度记为μ,类间方差为g,则有:
μ=ω0×μ0+ω1×μ1
(8)
g=ω0(μ0-μ)×(μ0-μ)+ω1(μ1-μ)×(μ1-μ)
(9)
将式(8)代入式(9)得到g=ω0ω1(μ0-μ1)×(μ0-μ1),采用遍历的方法得到类间方差最大的阈值T,即为所求[10]。
1.2.5Hough直线检测
通过前几步可以得到图像的细边缘,后面需要检测出直线,以便进行距离求解。检测直线采用Hough变换,其原理为:假设有一条直线到原点距离为s、方向角为θ,直线上的每一点都满足方程s=xcosθ+ysinθ,利用该条件找出图像中的直线[11]。图3为标准Hough变换基本流程图。
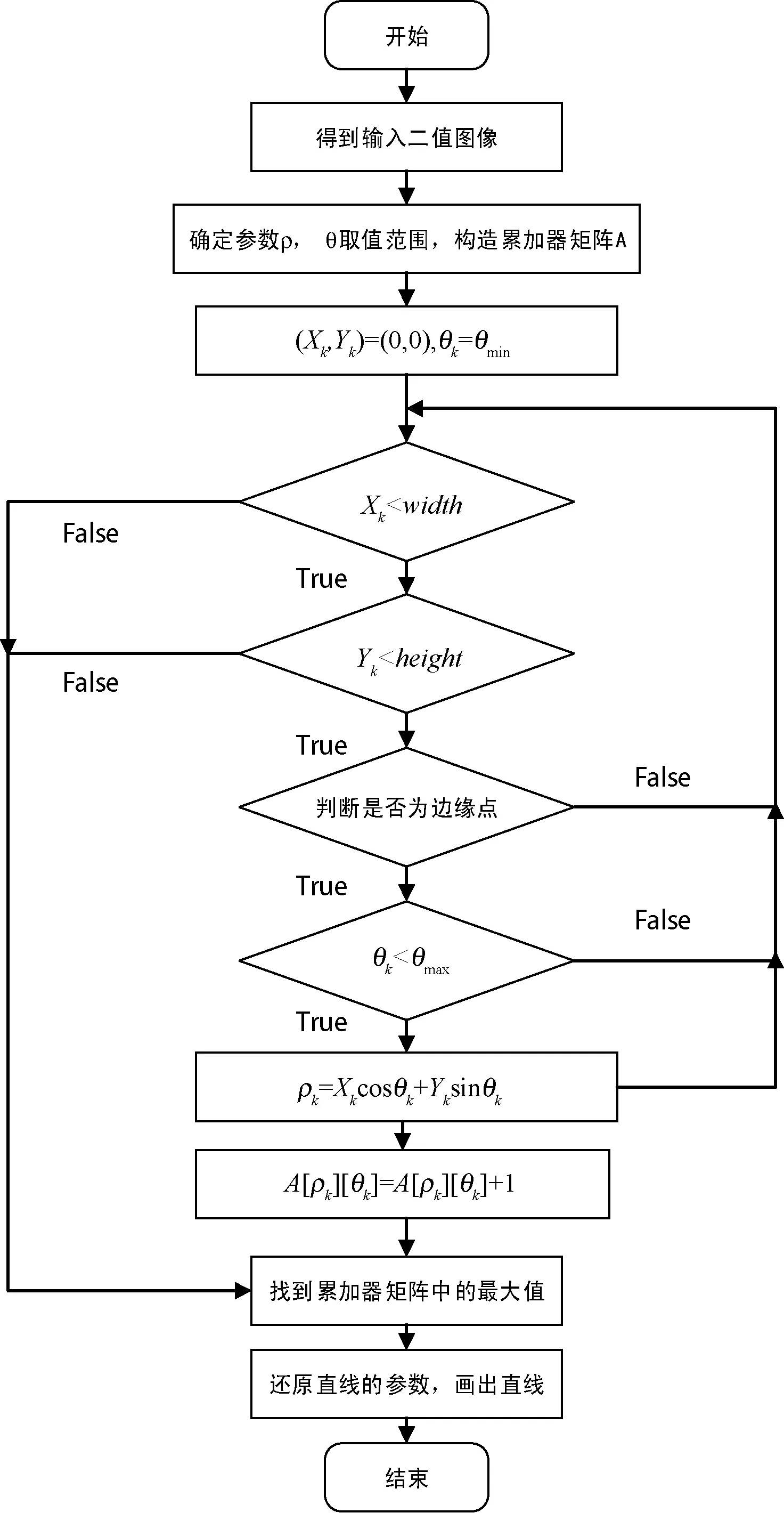
图3 标准Hough变换基本流程图
2 基于GPU的直线求取并行化算法设计
利用GPU实现并行加速,即通过CUDA实现对现有算法过程的并行改进。CUDA是NVIDIA推出的一个并行计算架构,通过该架构可实现利用GPU解决部分复杂计算问题[12]。
2.1 算法思想
针对直线求取过程中的高斯滤波、梯度和方向角计算、非极大值抑制、Otsu阈值分割和Hough直线检测进行并行化处理,使其在CUDA架构上运行,从而达到加速的目的,主要思想和步骤如下:
1) 在进行高斯滤波处理的过程中,常见的有直观实现方法、分离滤波(使用纹理内存)和FFT卷积。假设图像的大小为M×N,滤波核的半径为r,对时间复杂度分析可得:直观实现方法为O(M×N×r2) ,分离滤波器O(M×N×r)。FFT卷积可通过CUDA已经封装好的CUFFT库实现,但由于卷积核相对于图像小得多,故其性能不如分离滤波,最终选择分离滤波[13]。并行化过程中,使用全局内存中的单个线程加载一个像素,然后把数据复制到纹理内存中,之后执行滤波。滤波执行过程中,为了提高计算性能,计算中的循环展开成一阶表达式。
2) 下一步是求出图像X、Y方向的梯度值Gx、Gy及方位角θ。该过程中使用纹理内存,数据传递方式和高斯滤波相同,核函数中单个线程加载一个像素,各像素与卷积因子进行卷积求得Gx、Gy,Sobel卷积因子如图4所示。
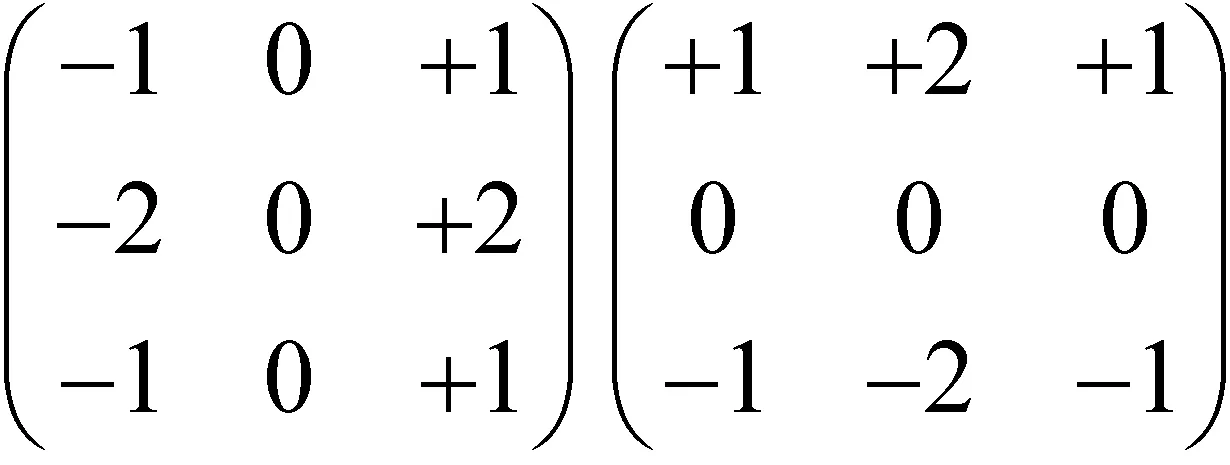
图4 Sobel卷积因子
3) 一旦梯度和边缘方向计算出来之后,需要进行非极大值抑制。它的作用是跟踪图像的边缘方向且抑制非脊像素,只保留脊像素,从而使输出图像边缘细化。
4)Otsu的过程分有计算直方图并归一化、计算图像灰度均值μ、计算直方图的零阶和一阶距、计算并找到最大的类间方差,最后根据找到的阈值进行二值化。Otsu算法并行主要体现在直方图计算、零阶以及一阶距的计算,以及二值化三个部分均在CUDA平台上实现并行化[14]。该过程使用共享内存,因为共享内存中的数据能够被同一线程块中的线程共有,在数据对齐的情况下,具有更快的访问速度。
5) 由图3可以看出,Hough直线检测算法中有明显的不足之处:累加器矩阵A占用了较大的存储空间;每一次都需要对图像的每一个边缘点进行判断,存在大量的循环,会占用大量的时间。在CUDA架构下完成该算法能够大大节约时间,首先采用一个线程对应图像中的一个像素点,判断各个像素点是否是图像的边缘,若是则该点进行Hough变换,若不是则返回[15]。由于单个线程对应一个像素点,所以省掉了单个像素点对θ判断一次所花费的时间。
2.2 基于CUDA的技术分析
CUDA技术的基本框架分为以下5步:1) 分配显存空间;2) 将数据从主机传入GPU;3) 在GPU中进行具体的并行计算;4) 将数据从GPU传回主机;5) 释放显存空间。
结合算法设计思想和步骤,在并行化算法设计时需要考虑以下关键点:
1) 并行化过程中使用了纹理内存,共享内存和全局内存,需要充分考虑数据在传输时的异步问题,避免因为数据的不完全传输造成计算结果的不正确。在分配线程的时候没有必要产生过多超过图像尺寸的线程,造成计算的延时与内存的浪费。在程序运行中由于分配显存和释放显存会占据大量的时间,可以采用把cudaMalloc和cudaFree写到一个主函数当中,程序运行期间只进行单次分配与释放,从而提高计算性能。
2) 纹理内存使用cudaMemcpy2DToArray将数据从主机传到GPU,因为纹理内存针对2D访问有优化,同时需要使用cudaBindTexture2D()将数据绑定到线性存储器中,最后需要使用cudaUnbindTexture()来解绑。
3) 根据共享内存的特点可知,共享内存的访问需要提前进行初始化,不然计算结果不正确。对共享内存中的数据进行原子操作,可以大大提高原子操作的效率,但是由于原子操作是一个串行操作,所以可以采用单GPU线程一次处理同一列上连续32个像素点的优化策略[16]。
4)Hough直线检测过程中,在检测最大值时,最大值容易被周围的值干扰,可以采用将累加器矩阵分块的优化策略[17]。
2.3 部分编码设计
结合2.1节和2.2节所述,利用CUDA技术在VisualStudio2013平台下构建检测系统框架,其软件流程如图5所示。利用CUDA处理并行数据的优势,将处理过程中可以并行执行的数据都放到GPU中进行计算,最后计算结果返回到CPU中。其中CPU部分使用C++编写,GPU部分使用CUDAC编写。
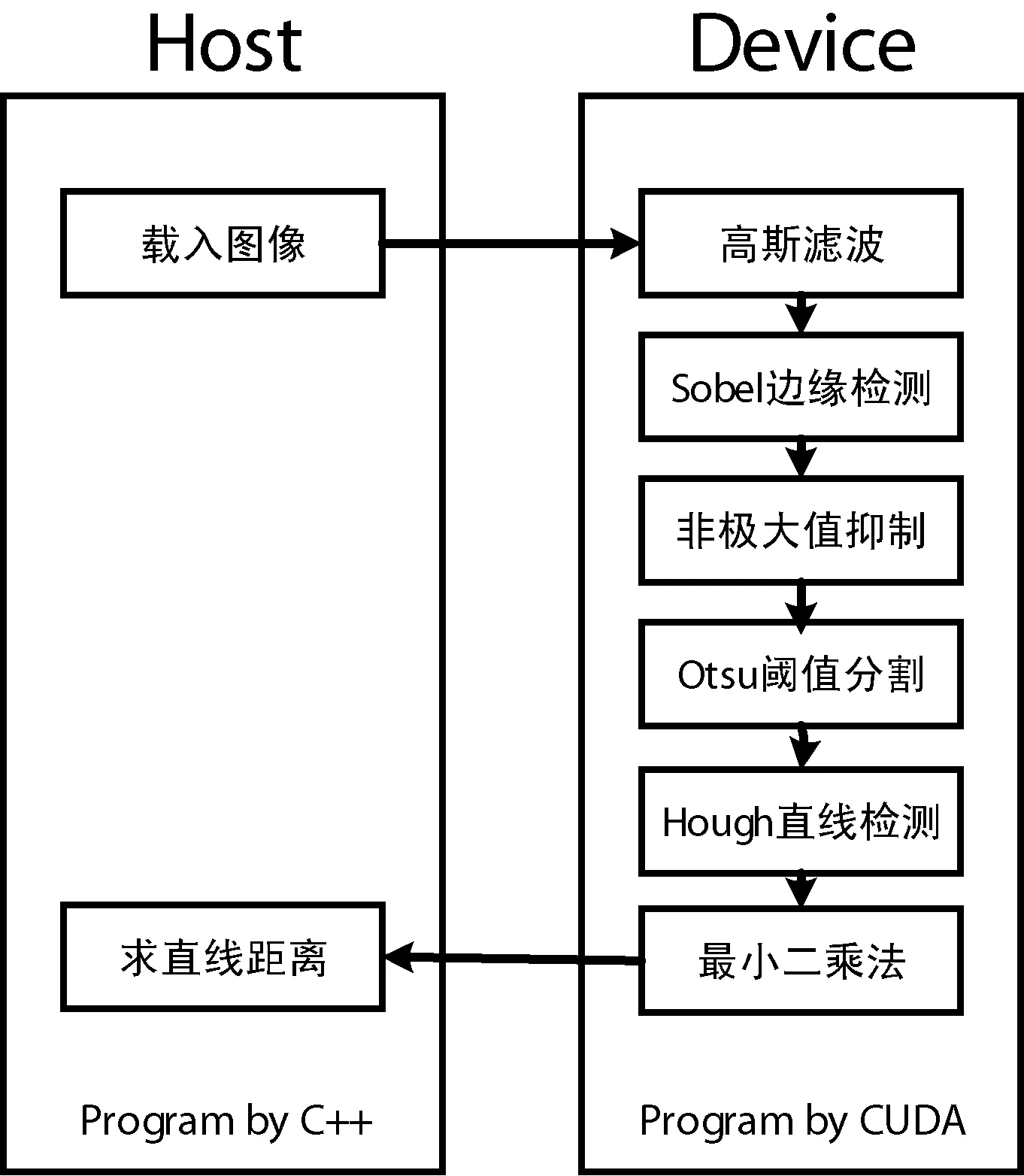
图5 系统流程框图
程序运行时由于分配显存和释放显存会占据大量时间,所以把该过程写在主函数中,部分代码如下:
int main(int argc, char **argv){
…cudaMalloc((void**)&d_in, width*height);
cudaMalloc((void**)&d_out, width*height);
cudaMemcpy(d_in, input, width*height*sizeof(unsigned char),cudaMemcpyHostToDevice);
dim3 blocksize(16, 16);
dim3 gridsize((width + blocksize.x - 1) / blocksize.x, (height + blocksize.y - 1) / blocksize.y);
loadConvertData <<
cudaThreadSynchronize();
cudaMemcpy(output,d_out,width*height*sizeof(unsigned char), cudaMemcpyDeviceToHost);
cudaFree(d_in);
cudaFree(d_out);…}
主函数中首先通过cudaMalloc进行显存的分配,然后cudaMemcpy进行数据在主机和设备之间的传输,在本文中blocksize设置为(16,16),此时效果最好。gridsize的值根据待处理像素的值自动确定,cudaThreadSynchronize()保证每一个像素都处理完毕,最后通过cudaFree释放掉显存空间。
高斯滤波使用的是5×5矩阵,其中需要把像素的循环计算展开成一阶表达式,提高运行速度,部分代码如下:
const float deviceGaussianFilterMask={2, 4, 5, 4, 2,4, 9, 12, 9, 4,5, 12, 15, 12, 5,4, 9, 12, 9, 4,2, 4, 5, 4, 2};
__global__ void GaussianConvolution(float* output, unsigned matrixWidth){
int outputRow = blockIdx.y * blockDim.y + threadIdx.y;
int outputColumn = blockIdx.x * blockDim.x + threadIdx.x;
float accumulator = 0.0;
…accumulator+=deviceGaussianFilterMask[(2+i)*3+(2+j)]* tex2D(deviceMatrixTexture, matrixColumn, outputRow + j);…}
其中outputRow、outputColumn表示分配线程进行行列的滤波,accumulator表示单个像素滤波后的值,通过tex2D(deviceMatrix Texture,matrixColumn,outputRow+j)分配纹理内存中的线程。
再之后是梯度与方向角度的计算,部分代码如下:
__global__ void deviceComputeGradient(float* outputGradient, unsigned* outputEdgeDirectionClassifications, unsigned matrixWidth){
int outputRow = blockIdx.y * blockDim.y + threadIdx.y;
int outputColumn = blockIdx.x * blockDim.x + threadIdx.x;
…xAccumulator += deviceXGradientMask[maskIndex] * tex2D(deviceMatrixTexture, matrixColumn, outputRow + j);
yAccumulator += deviceYGradientMask[maskIndex] * tex2D(deviceMatrixTexture, matrixColumn, outputRow + j);…
int matrixIndex = outputRow * matrixWidth + outputColumn;
outputGradient[matrixIndex] = abs(xAccumulator) + abs(yAccumulator);
float edgeDirection = atan2(yAccumulator, xAccumulator) * (180 / 3.14159265) + 180.0;
if ((edgeDirection >= 22.5 && edgeDirection < 67.5) || (edgeDirection >= 202.5 && edgeDirection < 247.5)){
outputEdgeDirectionClassifications[matrixIndex] = 1;}…
其中xAccumulator、yAccumulator分别表示每个像素在X、Y方向的梯度,outputGradient表示像素梯度强度,即G,edgeDirection表示梯度方向,即方位角θ。
3 实验与结果分析
实验平台的操作系统是Windows7Ultimatex64,CPU为interCorei3-2120 3.30GHz,GPU为NVIDIAGeForceGTX560SE(1536MB),频率736MHz,计算能力2.1,软件环境为VisualStudio2013+CUDA6.5+OpenCV2.4.9。待处理的图像为6张活塞销图像,分辨率2592×1944,大小4.80MB,活塞销标准宽度为1.000cm。如图6所示,活塞销被检测时为任意姿态,边缘信息不尽相同,存在明显差异,因此运行时间有一定差异。

图6 活塞销
如表1所示为6张活塞销图像分别在CPU和CPU+GPU模式下的运行时间对比,可以看出,使用GPU之后的运行时间明显变短,极大地减少直线求取所需时间,平均加速比约为13.42。
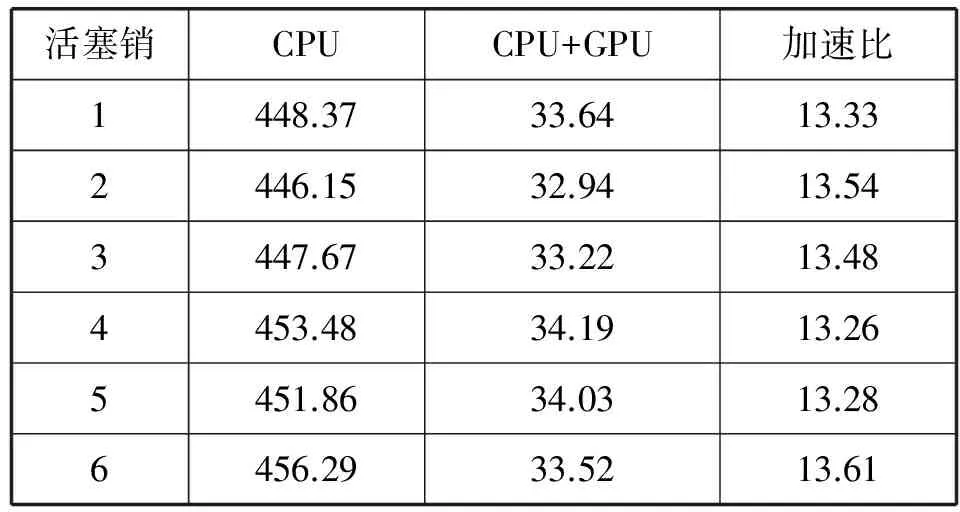
表1 Canny算法运行时间对比
通过对上述单个样本图像进行长时间约上万次的重复检测,可得出如表2所示结果,其表示分别在CPU和CPU+GPU模式下的精度。从表中可以看出,两种模式下准确度均相差不大,能够达到检测系统的生产要求。

表2 精度对比
4 结 语
基于GPU并行的方法实现活塞销尺寸的快速检测,综合利用CUDA架构中的共享内存、纹理内存和全局内存,对比前期单独使用CPU的方法,保证精度的前提下能够明显缩短检测时间。下一步工作将结合现在已有的工作进展,将检测系统和检测算法移植到玻管的缺陷检测上。
[1] 杨文飞,杨文雄.一种活塞销管:中国,CN203009815 U[P].2013.
[2] 苏俊宏,刘胜利.圆柱型高精密零件表面缺陷检测及形貌分析[J].激光与光电子学进展,2014,51(4):150-154.
[3] 周森,郭永彩,高潮,等.基于三维激光扫描的移动大尺寸圆柱体工件长度快速检测系统[J].光学精密工程,2014,22(6):1524-1530.
[4] 唐湘娜,王耀南.铁轨表面缺陷的视觉检测与识别算法[J].计算机工程,2013,39(3):25-30.
[5] 周煜坤,陈清华,余潇.基于CUDA的大规模流体实时模拟[J].计算机应用与软件,2015,32(1):143-147,170.
[6] 张向阳,冯超敏,赵书贵,等.一种基于GPU的逆时偏移并行算法[J].计算机应用与软件,2013,30(10):304-307.
[7] 夏斌.基于CPU+GPU的外辐射源雷达自适应滤波算法实现技术[D].西安:西安电子科技大学,2013.
[8] Gonzalez C I,Melin P,Castro J R,et al.An improved sobel edge detection method based on generalized type-2 fuzzy logic[J].Soft Computing,2014:1-12.
[9] Brown L M,Feris R,Pankanti S.Temporal Non-maximum Suppression for Pedestrian Detection Using Self-Calibration[C]//Pattern Recognition (ICPR),2014 22nd International Conference on. IEEE,2014:2239-2244.
[10] Huang L,Fang Y,Zuo X,et al.Automatic Change Detection Method of Multitemporal Remote Sensing Images Based on 2D-Otsu Algorithm Improved by Firefly Algorithm[J].Journal of Sensors,2015,2015:327123.
[11] Lee J P,Wu Q Q,Park M H,et al.A Study on Modified Hough Algorithm for Image Processing in Weld Seam Tracking System[J].Advanced Materials Research,2015,1088:824-828.
[12] 侯怡婷.基于CUDA的Hough变换并行实现[D].大连:大连理工大学,2013.
[13] 刘进锋.几种CUDA加速高斯滤波算法的比较[J].计算机工程与应用,2013,49(23):14-18,30.
[14] 王媛媛.基于CUDA平台的区域分割并行算法设计与实现[D].大连:大连理工大学,2014.
[15] 徐洋,张清蓉.基于图像处理的汽车指针仪表检测研究[J].计算机应用与软件,2014,31(8):219-221,252.
[16] Rahman M N A,Nasir A F A,Mat N,et al.Image Segmentation Using OpenMP and Its Application in Plant Species Classification[J].International Journal of Software Engineering and Its Applications,2015,9(5):135-144.
[17] Yadav V K,Batham S,Acharya A K,et al.Approach to accurate circle detection:Circular Hough Transform and Local Maxima concept[C]//Electronics and Communication Systems (ICECS),2014 International Conference on.IEEE,2014:1-5.
STUDY OF GPU APPLICATION IN RAPID DETECTION OF PISTON PIN DIMENSION
Zhou Yejiang Zheng Bin*Zhao Yongting
(ChongqingInstituteofGreenandIntelligentTechnology,ChineseAcademyofSciences,Chongqing400714,China)
In recent years, the research is more and more focused on high-speed strategy of industrial standard component dimension detection, and edge detection is the most important and the most time-consuming process of the whole running time. Therefore, a novel method based on GPU technology using CUDA is proposed for piston pin dimension detection. Considering the detection stability and high accuracy, Hough algorithm is selected as the strategy of line detection to parallel optimize several major steps, such as Gaussian filter, gradient computation, calculation of orientation angle and Otsu algorithm, combining with edge detection algorithm in present. Eventually, using the same experimental sample, the proposed method is able to detect the piston pin dimension in shorter time, compared with the original CPU implementation, the average efficiency has been accelerated by nearby 15-fold. The proposed approach outperforms the previous methods on CPUs in implementating same detection. It provides an efficient and feasible method to obtain an accurate and high-speed detection in industrial, and controls the production cost effectively.
Dimension detection Line detection Edge extraction GPU technology Parallel computing
2015-09-28。周叶江,硕士生,主研领域:机器视觉,并行计算。郑彬,副研究员。赵永廷,助理研究员。
TP3
A
10.3969/j.issn.1000-386x.2017.01.036
猜你喜欢
农业工程技术(2022年1期)2022-04-19 13:58:12
数学物理学报(2021年6期)2021-12-21 06:24:38
应用数学(2020年2期)2020-06-24 06:02:50
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
环球市场(2017年36期)2017-03-09 15:48:21
河南科技(2014年3期)2014-02-27 14:05:45
汽车与新动力(2014年5期)2014-02-27 12:10:46
汽车与新动力(2014年4期)2014-02-27 12:10:38
汽车与新动力(2014年3期)2014-02-27 12:10:23
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
