
基于时空模型视频监控的行人活动预测算法
2017-03-01 04:26:13江志浩李旻先赵春霞邵晴薇
计算机应用与软件 2017年1期
江志浩 李旻先 赵春霞 邵晴薇
(南京理工大学计算机科学与工程学院 江苏 南京 210094)
基于时空模型视频监控的行人活动预测算法
江志浩 李旻先 赵春霞 邵晴薇
(南京理工大学计算机科学与工程学院 江苏 南京 210094)
在现代监控和视频检索系统中,跨摄像头行人跟踪问题仍然是个挑战,其原因是行人再识别时庞大的搜索空间,特别是当有大量的摄像头和行人的时候。针对跨摄像头行人再匹配计算量大,耗时久等问题,提出一种融合样本数理统计和混合高斯分布的时空关系模型。该模型可以有效地预测行人活动,即当一个行人从一个摄像头可视区域离开时,我们能够预测该行人下一次直接进入摄像头可视区域的时间和所在的出入点位置。根据预测的结果,极大地减少了行人再识别的匹配范围,从而提高匹配识别的准确率,再依赖行人的表现模型和轨迹进行行人再识别,最终实现跨摄像头行人持续跟踪的目的。实验结果表明了模型的表现与实际情况比较接近。
行人再识别 时空关系模型 活动预测
0 引 言

图1 基于表现模型的行人再识别示意图
然而,多摄像头无重叠视域的行人跟踪不同于传统的行人再识别问题。由于在颜色、照明、观测距离和角度等方面的差异[2,6,8],我们仅仅依靠表现模型不足以准确地匹配行人。即使在多摄像头中同一行人的特征很相似,由于庞大的搜索空间,对应的问题仍然很难解决,特别是在大量的行人和摄像头的情况下[11,15]。在视频监控的实际环境中,目标的运动和转移的规律可以反映多摄像头网络的时空关系,一旦摄像头之间的时空关系模型建立,多摄像头无重叠视域的行人持续跟踪算法可以得到时空关系上的约束,这对算法的效率有着明显的提高。所以,我们需要解决目标关联问题。
为了解决这个问题,研究人员近年来已经提出了许多方法,例如将实际场景中的摄像头视域和路径转换为图结构,通过拓扑图来刻画它们之间的关系。目前,对摄像头网络时空关系的建立主要基于监督和无监督学习方法[9]。监督学习,即早期的人工干预的方法,主要适用于小的无重叠视域的摄像头网络,并不能很好地适应系统的变化。无监督学习,比如在线学习方法,具有一定的自适应学习能力,但学习速度慢、学习适应性不强。吉尔伯特等人[7]采用一种无监督在线累积学习方法估计摄像头间的拓扑关系。贾韦德等[8]采用基于高斯核和时间窗口的概率密度估计器估计拓扑关系。
基于以上考虑,本文提出了一种基于样本数理统计和混合高斯分布SGMM(Spatiotemporal Gaussian Mixture Model)的时空关系模型反映摄像头网络的时空关系[10,13]。该模型旨在描述多摄像头中目标运动和转移关系的规律:当行人出现在一个摄像头视域中时,我们可以预测该目标即将进入摄像头的序号。该模型可以极大地减少搜索空间。此外,它更适合处理在视觉监控应用中经常需要使用的庞大的数据集。实验结果证明了该模型的有效性。
1 时空关系模型
摄像头网络拓扑结构代表了运动目标在多摄像头中的时间和空间转移关系。本文中,多摄像头的拓扑关系,也就是时空关系,主要包含每个摄像头视域中出入点的位置以及移动目标在这些出入点之间的转移时间[10]。在图2中,通过对两组行人的活动分析我们可以看出目标运动和转移的规律性。为了更好地在非重叠视域的多摄像头中对目标进行持续跟踪,本节中,我们通过样本统计和混合高斯分布建立一个时空关系模型预测目标活动,以达到约束行人再识别搜索范围的目的。建立时空关系模型的流程如图3所示,输入行人活动样本,输出训练好的时空关系模型。如果一个目标从一个摄像机视域离开穿越一段不可见的区域直接达到另一个摄像机视域,经过的时间和这两个视域之间的平均时间相差不大时,我们可以基于目标的表现模型(AM)进行匹配[12]。当差别较大时,我们就不再进行匹配,并判定该目标不是缓冲区的待匹配目标。如图4所示,我们描述一个简单的摄像头网络的拓扑结构,使用节点图进行表示,并将结点图进一步细化为有向图。图中将摄像头视域O中的出入点定义为节点集合P,E为节点之间的边集合。特别指出的是,这些边指的是两点之间存在可直接达到的路径。因此,图模型可以定义为:
G=〈P,E〉pi∈P,e(i,j)∈E,1≤i,j≤N
(1)
其中pi表示图中节点,e(i,j)表示直接从节点pi到pj的有向边,N表示节点的数量。

图2 行人活动分析示意图

图3 建立时空关系模型的流程图

图4 摄像机网络拓扑关系和图模型建立示意图
1.1 空间关系模型
女人穿着一条改良后的火红色旗袍,旗袍很短,齐膝盖上几寸的地方,旗袍的口子开得特别高,她侧坐在那个六十来岁已经秃了顶的台湾画商腿上,白花花的大腿就暴露了出来。画商色眯眯地盯女人的大腿,手很不老实地在上面揉来捏去。
空间关系确立节点之间是否需要建立边以及边的方向。一般而言,只要摄像机位置固定,摄像机视域中出入点的位置也就相应的确定了。如果两个出入点之间可以一步到达,即中间不经过其他点,我们将会在它们之间建立一条边。而边的方向由目标的移动方向决定。由于位置信息不好度量,我们用样本统计建立出入点之间的边。在这里,我们根据出入点的数量建立一个n×n的空矩阵,其中vij为目标样本从节点pi到pj的数量,如果样本目标直接从pi到pj,那么vij=vij+1。若vij>0,则表示pi到pj有直接可行路径,令ρij为vij的频率并定义为:
(2)
1.2 时间关系模型
图模型的边权重是由目标在不同出入点转移的频率决定的。我们用样本学习的方法建立对运动目标的时间约束,并以此定义边权值w(pi,pj),pi,pj∈P。通过统计目标在相邻结点之间的转移时间,我们得到了一个时间集合T=(t1,t2,…,tl)。图5中,我们可以看到两个摄像头之间样本转移时间的分布图,由于时间样本集在实际场景中是以多峰形式存在的,我们采用高斯混合模型来刻画样本。

图5 两个摄像头之间样本转移时间的分布图
幸运的是,通过上述对样本活动的统计,我们可知每个矩阵元素下的所有样本的转移时间。根据这些已有的转移时间,我们利用C均值算法聚类,聚类数目控制在4个以内,如果任意两个聚类接近,则将它们合成一个新的聚类,从而形成m(m=1,2,3,4)个波峰,其中聚类m的个数为wij_m。记ρij_m为目标从pi到pj的时间区域在第m个峰值的频率并定义为:
(3)
(4)
(5)

最后,由空间关系模型和时间关系模型我们可以建立摄像机网络的时空关系模型,并利用该模型对目标活动进行预测。
2 活动预测
针对上一节中训练好的时空关系模型,我们利用一组行人活动的测试集来进行目标活动的预测。令测试集为Total,预测正确的数量为Acc,那么totalAn(j,i,tb,te)表示活动A的第n条轨迹从pj进入,从pi离开以及它的进出时间tb和te。预测步骤如下:
1) 当测试集中的目标A从出入点pi离开时,我们根据式(3)得到pi到其他出入点的频率ρij_m,由高到低,返回前k个,即这k个就是对目标到达下个出入点和其转移时间域的预测:
(6)
2) 根据测试集中的活动totalA(n+1)(j′,i′,tb′,te′),进行验证,即totalA(n+1)中的j′与Prk中的pj一致且(tb′-te)∈E时,认为此次行人活动预测成功,否则为失败;
3) 对测试集中所有目标进行测试,统计准确的个数Acc,这样我们可以得到一个准确率Pre:
(7)
经过实验验证,该模型在测试集上的预测准确率已经达到了83%,满足在实际场景中应用的需求,即认为建立的时空模型在现实场景中是有效的。
3 行人轨迹匹配
由于时空模型的预测,当一个目标离开一个摄像头视域时,可以极大地缩小行人再识别的范围。而对于行人再识别,我们打算采取轨迹间的匹配代替之前的行人图片间的匹配。将预测范围内的所有轨迹作为待匹配的轨迹,鉴于每条轨迹的长度不等,我们对轨迹长度进行归一化:选取l作为轨迹长度,若一个轨迹长度为L(L≫l) ,择取d=L/l,在轨迹中按等差数列差值为d抽取行人图片,组成长度为l的轨迹。记目标在原摄像头视域下的轨迹为tra0,待匹配的轨迹为traij_m_seq,表示为该目标有可能从i到j第m个时间区域下第seq个轨迹。将tra0和traij_m_seq进行匹配,选取RGB颜色距作为鉴别性特征,通过PCA降维处理,接着采用欧式距离进行计算,于是得到:
(8)
其中Dx,y为tra0中第x张图和traij_m_seq中第y张图的欧式距离,Sim0,ij_m_seq表示tra0和traij_m_seq的相似度。结合上述的ρij_m,最终得到:
traij_m_seq=arg max(Sim0,ijmseq·ρijm)
(9)
其中,traij_m_seq即为和tra0同一个目标的轨迹。依次类推,找到该目标的所有的轨迹,组成该目标的活动。
4 实验结果与分析
在本节中,我们活动预测的实验数据来源于PKU-SVD-B数据集,这其中的摄像头网络包含14个摄像机,每个摄像机有若干个出入点。摄像头网络间的时空关系模型即根据第2节中的方法训练而得。
实验方法如下:在建立摄像头网络时空关系模型阶段,我们基于一组较大的行人活动的样本集作为训练集。训练集包含目标活动经过的摄像头序号以及对应的进入时间和结束时间。如表1所示,通过式(3),计算求得从p10到其他出入点p4和p7的频率ρij_m。

表1 从p10到其他出入点的频率
在表1中,可以发现∑ρij_m≈1。这涵盖了一个运动目标离开出入点p10后到达其他出入点的所有的可能性。进一步,在表2中,通过式(4)和式(5),计算求得从p10到p4和p7转移时间的混合高斯分布(μ,σ2)。

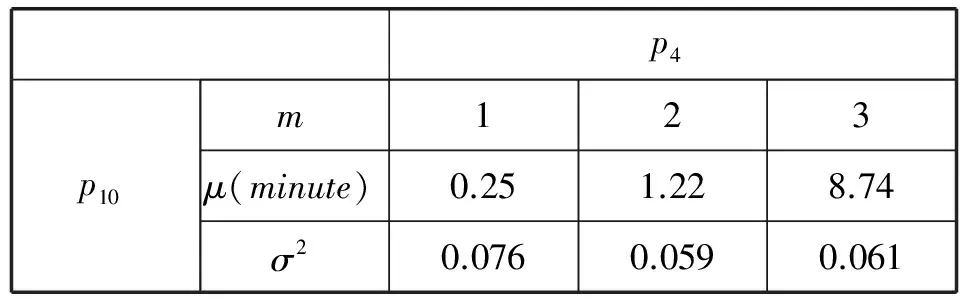
表2 从p10到p4的混合高斯分布
图6反映了预测活动的准确率与训练规模集的关系,可以发现训练集规模从9到11时测试集的准确性的曲线上升较快,这是由训练集的规模比较小所导致的。而在训练集规模达到18以上,曲线变化比较平滑,这说明当训练集的规模足够大时,它将几乎覆盖实际场景中的绝大多数情况,已达到一个较为稳定的水平,故而测试集的准确率的变化也就相对平缓。

图6 训练集规模从1到25变化时的预测活动准确率
表3列出了三组目标集的准确率,召回率和F值。本文结合目标的表现模型与时空关系模型预测的方法相比于传统的只基于表现模型的方法在精度上有了较大的提高(约11%的提升)。实验证明,本文所提出的方法在实际应用中有较好的实用性。

表3 行人再识别精度对比
5 结 语
本文提出一种融合样本数理统计和混合高斯分布的时空关系模型的跨摄像头行人跟踪方法。这个模型虽然简单但在实际的摄像头网络中却十分有效。在实验中,该模型较为准确地预测了目标离开一个摄像头视域后的去向。因此该模型能够在实际应用中帮助减少行人再识别问题的搜索空间,从而提高匹配识别的准确率,依赖行人的表现模型和轨迹进行行人再识别,最终实现跨摄像头行人持续跟踪的目的。然而,由于多摄像机网络场景的复杂性行人目标移动过程中的移动速度等因素,如何将算法进一步扩大到更大范围的应用场景以及多样化目标将是下一步的研究工作。
[1] Layne R,Hospedales T M,Gong S.Person Re-identification by Attributes[C]//British Machine Vision Conference (BMVC),2012.
[2] Snavely N,Hauagge D C.Image matching using local symmetry features[J].Computer Vision and Pattern Recognition (CVPR),2012 IEEE Conference onIEEE,2012,157(10):206-213.
[3] Bryan Prosser,Weishi Zheng,Shaogang Gong,et al.Person Re-Identification by Support Vector Ranking[J].British Machine Vision Conference (BMVC),2010,42(7):1-11.
[4] 刘少华,赖世铭,张茂军.基于最小费用流模型的无重叠视域多摄像机目标关联算法[J].自动化学报,2010,36(10):1484-1489.
[5] Liu C,Gong S,Loy C C,et al.Person Re-identification:What Features are Important[M].Springer Berlin Heidelberg,2012,7583:391-401.
[6] Wang X,Tieu K,Grimson W E L.Correspondence-free activity analysis and scene modeling in multiple camera views[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(1):56-71.
[7] Andrew Gilbert,Richard Bowden.Tracking Objects Across Cameras by Incrementally Learning Inter-camera Colour Calibration and Patterns of Activity[J].Lecture Notes in Computer Science,2006,3952:125-136.
[8] Wang X,Tieu K,Grimson E L.Correspondence-Free Activity Analysis and Scene Modeling in Multiple Camera Views[J].Pattern Analysis & Machine Intelligence IEEE Transactions on,2010,32(1):56-71.
[9] 吕真,张浩,连卫民.多特征协同的双层组合结构行人监控识别方法[J].计算机应用与软件,2015,32(9):170-174.
[10] 郭烈,张广西,葛平淑,等.基于特征组合粒子滤波的行人跟踪方法[J].计算机应用与软件,2013,30(11):4-7.
[11] 董永坤,王春香,薛林继,等.基于TLD框架的行人检测和跟踪[J].华中科技大学学报:自然科学版,2013(s1):1284-1289.
[12] 李琦,邵春福,岳昊.视频序列中面向行人的多目标跟踪算法[J].北京理工大学学报,2013(2):178-184.
[13] 马元元,李成龙,汤进,等.视频监控场景下行人衣着颜色识别[J].安徽大学学报:自然科学版,2015(5):23-30.
[14] Li W,Zhao R,Wang X.Human Re-identification with Transferred Metric Learning[M].Computer Vision-ACCV 2012 Springer Berlin Heidelberg,2013:31-44.
PEDESTRIAN ACTIVITY PREDICTION ALGORITHM IN SURVEILLANCE VIDEOS BASED ON SPATIOTEMPORAL MODEL
Jiang Zhihao Li Minxian Zhao Chunxia Shao Qingwei
(SchoolofComputerScienceandEngineering,NanjingUniversityofScienceandTechnology,Nanjing210094,Jiangsu,China)
In the modern monitoring and video retrieval systems, it is still a challenge to track pedestrian from multiple camera. The reason is that there is large search space in the process of the pedestrian re-identification, especially when there are a large number of cameras and pedestrians. In view of this, a spatiotemporal relationship model based on the sample statistics and mixture Gaussian distribution for multiple cameras pedestrian tracking is proposed. The model is able to predict the pedestrian activities effectively, which means, when the pedestrian disappears from one camera view, the model is able to predictthe time and place that the pedestrians will appear in another camera view. According to the results of prediction, the matching range of pedestrian re-identification is greatly reduced and the accuracy rate of matching is improved.The purpose of multiple cameras pedestrian tracking is finally realized by re-identifying the pedestrians' expression model and track. The experiment result demonstrates that the performance of the model is consistent with the observations in the extensive experiments.
Pedestrian re-identification Spatiotemporal model Activity prediction
2015-10-28。国家自然科学基金项目(61401212,61272220)。江志浩,硕士生,主研领域:图形图像技术与应用。李旻先,讲师。赵春霞,教授。邵晴薇,硕士生。
TP391.9
A
10.3969/j.issn.1000-386x.2017.01.027
猜你喜欢
中国交通信息化(2022年9期)2022-10-28 06:14:40
社会科学战线(2022年8期)2022-10-25 03:16:02
汽车工程师(2021年12期)2022-01-18 06:02:43
意林(2021年5期)2021-04-18 12:21:17
冰雪运动(2020年1期)2020-08-24 08:10:58
武术研究(2020年2期)2020-04-21 10:32:56
扬子江(2019年1期)2019-03-08 02:52:34
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
汽车维修与保养(2015年8期)2015-04-17 03:32:59
声屏世界(2014年8期)2014-02-28 15:18:11
