
双重聚类的协同过滤算法在智能家居中的应用
2017-02-22 08:01蔡红霞
计算机技术与发展 2017年2期
胡 磊,蔡红霞,俞 涛
(上海大学 机电工程与自动化学院,上海 200072)
双重聚类的协同过滤算法在智能家居中的应用
胡 磊,蔡红霞,俞 涛
(上海大学 机电工程与自动化学院,上海 200072)
针对智能家居系统中用户获取有效信息困难的问题,提出基于用户和环境双重聚类的协同过滤推荐算法。利用K-means算法分别对智能家居系统中的用户和环境进行聚类,找出目标用户和所处家居环境的最近邻居。使用欧氏距离为度量计算目标用户和系统其他用户之间、目标用户所处家居环境和系统其他家居环境之间的综合相似度。从最近邻居之间选出与目标用户最相似的前K个推荐给目标用户,实现对推荐算法的优化。实验结果表明,与传统的协同过滤算法,以及基于用户或环境单一变量的协同过滤算法相比,文中采用的算法推荐精度更高,实时性和可扩展性更好。
智能家居;K-means;聚类;最近邻居;协同过滤
0 引 言
智能家居,就是使用当前先进的并且处于持续发展阶段的计算机技术,以及网络通讯等技术,以家庭住宅作为平台,将各种与家居生活相关的功能性子系统,结合成一套高效的家居系统。在这套系统中,运用控制平台进行统筹管理,使得家居生活更加安全、高效、舒适。智能家居系统中最重要的组成成分就是用户和家居环境。通过智能家居系统,用户不但可以控制各种家居环境,如远程控制家用电器开关,设置家居温度、湿度等,而且管理员可以管理所有用户的家居信息,如各种家居设备状态信息详情,各个季节时间段不同用户的家居环境偏好信息等,因此智能家居系统中的数据具有数据量庞大、数据异构等特点。随着系统中用户的不断增长,用户和家居环境等信息数据也在成倍增长,同时,信息质量良莠不齐,导致许多有效信息被埋藏在茫茫的信息海洋中,也给用户获取到想要的信息造成了巨大的困难[1]。智能推荐服务技术能为用户提供便利,通过分析用户的某些相关信息,主动地向用户反馈满足其需求的内容。这种方式可以更加高效地为用户提供其所需信息,使用户设置自己喜欢的家居环境,从而有效解决用户信息获取困难的问题。
1 推荐算法及其相关技术
国内外针对智能推荐服务展开了广泛的研究与应用,目前最常见的推荐算法是协同过滤推荐:协同过滤算法[2-4]。根据用户的历史操作,首先分析用户间存在的相似性,再根据这种相似性寻找目标用户的相邻集合,之后根据相邻集合测算出这些目标群体会为他们没有评分过的项目使用怎样的评分,以此得到推荐结果。协同过滤正迅速成为一项受欢迎的技术,具有不需要领域知识、推荐准确度随时间推移性能提高、推荐个性化高等优点。算法描述的应用情景也最适合智能家居系统推荐功能。
“协同过滤”这一术语是由GlodBerg等在开发推荐系统Tapestry[5]时提出的,该技术以其广阔的应用价值受到越来越多的关注。
传统的协同过滤算法可分为基于全局的过滤算法(Memory-basedalgorithm)和基于模型的过滤算法(Model-basedalgorithm)。其中,基于全局的过滤算法又可分为基于用户(User-Based)的全局算法和基于项目(Item-Based)的全局算法。基于用户的全局算法是最原始的,更好的解决办法是构建以项目为基础的推荐模型[5],也就是一种基于项目的协同过滤算法。使用这种算法时,速度要比基于用户的全局算法快很多,能够很快地得到推荐结果[6]。但是基于用户的全局算法适用于用户数目变化不大而项目数量远远超过用户的情况,而基于项目的全局算法却适合用户数量多但项目数并不多的情况[7],同时相比基于用户的方法,该算法拥有更好的可扩展性,但是还不能有效解决实时性和可扩展性问题。基于模型的过滤算法在一定程度上可以解决可扩展性问题,如SarwarB等[8]提出一种增量式的基于矩阵奇异值分解法(SingularValueDecomposition,SVD)的协同过滤算法,从而降低了重复进行矩阵分解的代价,提高了推荐系统的可扩展性。此外,也可以使用主成分分析(PrincipalComponentAnalysis)[9]和(LatentSemanticIndexing,LSI)[10]对用户协同过滤进行降维。若使用基于SVD的降维法,虽然能够解决可扩展性问题,但要进行矩阵分解。为了提高可扩展性,Miyahara等[11]采用基于贝叶斯方法的协同过滤算法,但是贝叶斯网络模型需要定期维护,加上模型训练时间成本较高,所以只适用于数据变化不频发的场景。
文中在智能家居系统中运用协同过滤算法实现智能推荐之前,采用基于用户和环境的双重聚类算法对用户和环境进行聚类。聚类算法采用K-means,因为K-means算法非常适合对大型数据集进行分类[12]。考虑到智能家居用户对不同家居环境偏好信息,使用K-means算法把自身属性和偏好相似的用户划分到相同的用户簇中,另外,再把用户所处的相似家居环境划分到相同的环境簇中,这样可以缩小活动用户的最近邻居查询范围。并且这些聚类操作可以在离线的环境下进行,不仅实现了对推荐系统实时性、可扩展性问题的缓解,同时保证了推荐的有效性。
2 基于用户和环境双重聚类的协同过滤算法流程
文中提出的协同过滤算法,在对智能家居系统进行用户和环境双聚类的同时,分别基于这两方面的协同过滤方法,实现优质推荐,并且克服了原有协同过滤算法中关于可扩展性的缺陷。算法流程如图1所示。
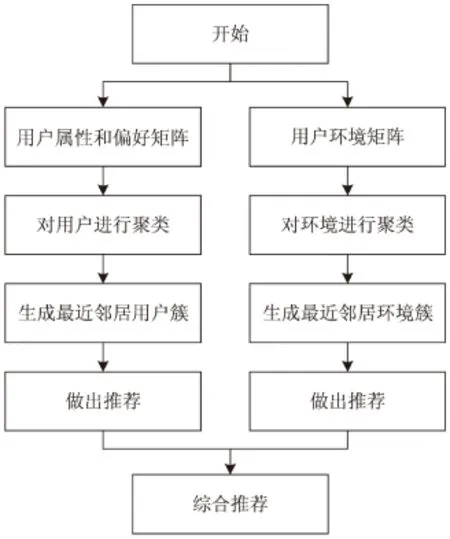
图1 基于用户和环境双重聚类的协同过滤算法流程图
算法具体描述如下:
(1)构建用户属性和偏好矩阵和用户环境矩阵。
(2)用户聚类和环境聚类:对所有系统用户及家居环境,按照预先制定好的聚类准则,分别进行聚类。
(3)确定最近邻居的用户集合和环境集合:首先找到目标用户及其所处环境,并找到这个环境所在的一个或几个簇,然后再在簇中找到其最近邻居集合。
(4)预测推荐:计算出目标用户和目标用户所处的环境的前N个相似度高的推荐方案。
(5)综合推荐:获取用户聚类和环境聚类的推荐结果,将二者进行综合计算,运用加权平均的方式获取前K个方案推荐给目标用户。
3 基于用户和环境双重聚类的综合过滤算法的实现
3.1 用户和环境的基础数据库构建
通过对用户的自身属性和智能家居系统中用户的环境偏好分析,构建的用户数据库表的字段有性别、年龄、体重、温度偏好、湿度偏好、水温偏好等m个属性。假设有n个用户,则表示为用户属性和偏好矩阵就是Xi(n1,n2,…,nm),每一个用户都可以用一个一行m列的数组表示,用户信息表的设计如表1所示。
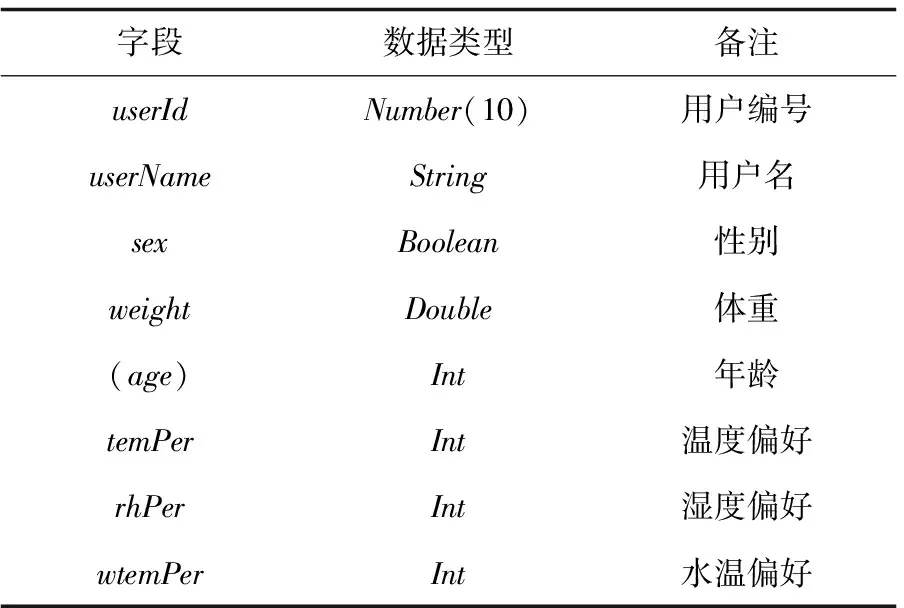
表1 用户属性和偏好表(Users)
通过分析用户所处的智能家居环境,构建环境数据表。表中字段主要有当前温度、温度变化、当前湿度、湿度变化、空气质量、空气质量指数、用户居家模式等k个属性,同样具有n个用户。环境信息表的设计如表2所示。
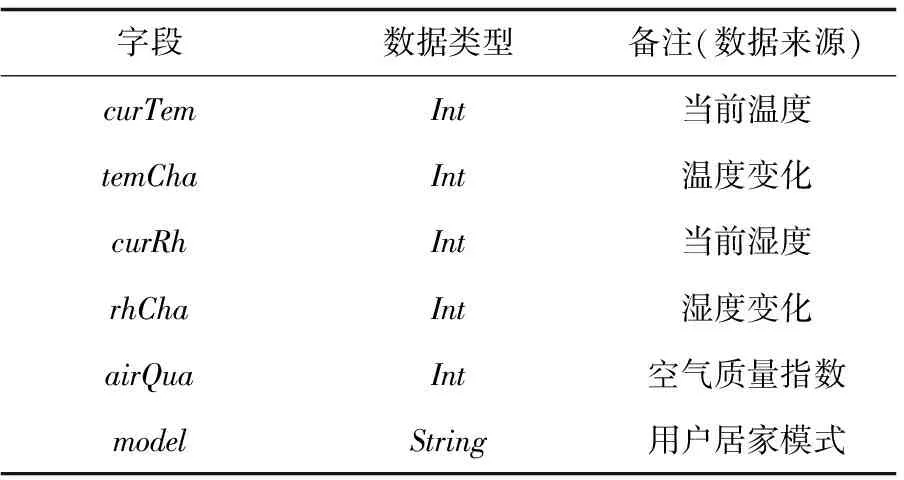
表2 用户家居环境表(Environment)
前面提到,用户和用户所有的属性可以表示为一个1行m列矩阵,那么用户可以用一个n行m列矩阵表示,Xn表示第n个用户。同理,n个用户和环境所有属性也可表示为一个n行m列矩阵。
数据库各个字段,若是数值类型,可直接计算;若是文字描述,则要将其先化为数值的形式。举个例子,用户性别是Boolean类型,女为true,男为false,可以用数字[1,0]表示。若无法枚举,则要转换成数值类型,通过去模糊化的方式。
3.2 用户、环境聚类
由于用户和环境聚类原理是一样的,只是m个属性值不一样,所以只对用户聚类进行描述。
对用户进行聚类,运用的是K-means算法。如果用户属性与偏好值相似,就将他们放到同一用户簇。例如,用户i和用户j的聚类相似度量采用欧氏距离相似度求得。聚类的用户数为n,用户属性和偏好是m,则对用户聚类的步骤如下:
(1)从用户中随机选取K个(u1,u2,…,uk)作为初始聚类簇,将K个用户的m个属性和偏好L(ui,j),i={1,2,…,k},j={1,2,…,m}作为初始聚类中心。
(2)以聚类中心为中心,算出其与剩余的每个用户i属性的欧氏距离,并算出偏好值与其的欧氏距离,比较二者相似度,根据相似度,将其放置到最相似的簇Cm中。
(3)重调各个簇的聚类中心。这种做法是基于分组后各簇中的用户集。再选择新的聚类中心,如何选择则是根据各簇中存在的所有用户属性与偏好值的均值。
(4)经过上一步的调整,进行判断,若新的聚类中心与上一次的一致,或者在一定的误差范围内,就结束聚类;否则重新回到步骤(2)。
另外,设置一个参数—最大迭代次数,以避免因不满足第四步条件而进入无限循环的情形。算法伪代码如下:
(1)从所有用户集N中选择K个用户,用户的属性值和偏好值作为初始的聚类中心,记为集合CC={cc1,cc2,…,cck};K个聚类簇初始化为空,记为集合c={c1,c2,…,ck}。
(2)repeat
Foreachuserui∈U
Foreachclustercenterccj∈cc
计算其他用户i属性和偏好与聚类中心ccj的欧氏距离相似度d(i,ccj);
Endfor
d(i,ccj)=max{d(ui,cc1),d(ui,ccj),…,d(ui,cck)};
聚类cm=cm∪ui;
Endfor
Foreachclusterci∈c//对聚类中心进行调整
计算聚类ci中所有用户属性和偏好平均值,生成新的聚类中心cci
Endfor
Until所有聚类中心与上次循环的聚类中心相同(或者误差Jc的值小于一定的阈值)
Return
3.3 最近邻居查找和推荐生成
对用户和环境进行聚类分簇以后,确定与目标用户相似度最高的簇,获取最近邻居集合(在簇中与目标用户拥有最高相似度的前K个用户组成)。在最近邻居查询过程中,获取用户间的相似度需要通过如下步骤:
(1)用户基于属性和偏好的相似度。
相比距离度量,相似度计算更加注重两个向量在方向上的差异。由于用户属性值和偏好值可以因用户个人变化幅度很大,所以用户属性和偏好组成的向量在方向上的差异很大,故选用皮尔森相关性系数,求出用户基于属性和偏好的相似度simu(u,v):
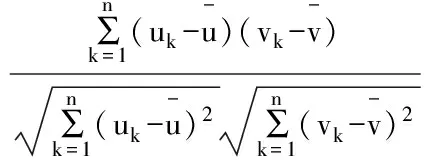
(1)
(2)用户基于环境的相似度。
由于用户在同一季节所处的环境属性变化不会特别大,所以数据差异不会很大,则环境属性组成的向量不会很大。如果用皮尔森相关性系数,那么计算出的环境之间的相似度差异会很小。假如任意两个用户所处的环境的相似度值都达到0.9以上,那么会影响推荐的准确性,所以选用基于欧氏距离相似度计算公式求出用户基于环境的相似度sime(u,v),计算公式为:
(2)
(3)
(3)综合相似度。
通过对前两步加权,计算综合相似度:
sim(u,v)=αsimu(u,v)+(1-α)sime(u,v)(4)
为提高推荐算法质量,可以选择适当的α值,结合两种方式进行相似度计算。
(4)选取目标用户的最近邻居数为N的集合。
(5)在目标用户的最近邻居集合中选取综合相似度最大的K个推荐给目标用户。
3.4 计算实例
在用K-means算法对用户和环境进行聚类,选取目标用户的最近邻居数为K个前提下,以某智能家居公司的数据样本作为实验对象进行分析。用户属性包括性别、年龄、体重、温度偏好、湿度偏好、水温偏好等,使用m1,m2,…,m6描述用户的属性和偏好,性别上取0为男,1为女;环境属性包括当前温度、当前湿度等属性,用n1,n2,…,n6描述,用户居家模式、运动模式和休息模式等分别用[1,2,3]等数字表示。具体用户信息为:[性别:男,年龄:26,体重:65kg,温度偏好:26 ℃,湿度偏好:48RH,水温偏好:60 ℃],具体环境信息为[当前温度:31 ℃,温度变化:14 ℃,当前湿度:55RH,湿度变化:11RH,空气质量:78,居家模式:居家模式],对用户详细信息和环境详细信息进行数学建模后得到用户信息:[m1:0,m2:26,m3:65,m4:26,m5:48,m6:60],环境信息:[n1:31,n2:14,n3:55,n4:11,n5:78,n6:1](文中涉及到的计算用表均为建模处理后的数据)。
3.4.1 用户相似度计算
由于用户属性和偏好采用的单位是不同的,数值的差异也很大,所以计算前要对用户信息数字进行归一化处理,则对用户数据处理后的信息用矩阵表示(由于数据量大,所以只列出一部分)。
令X1为目标用户,归一化处理后的用户信息如表3所示。
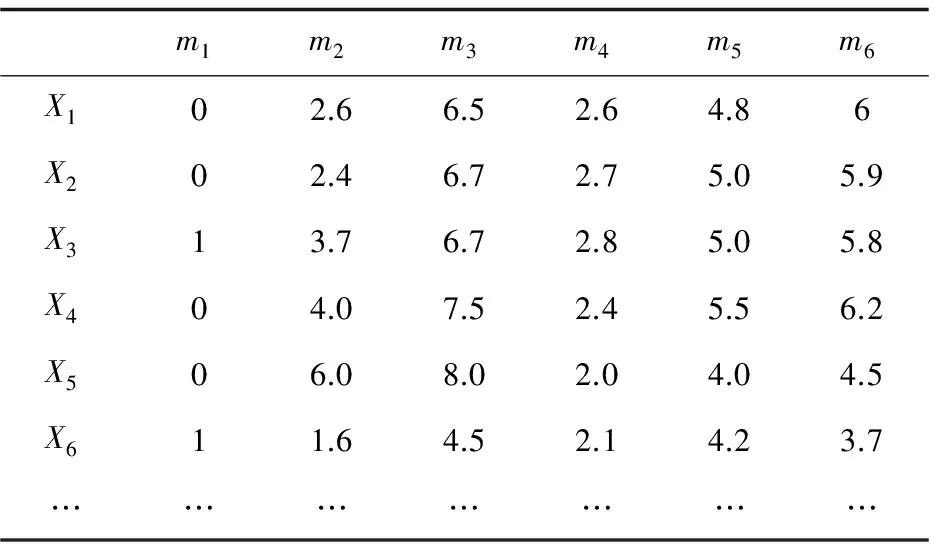
表3 用户信息矩阵
针对上述矩阵,利用皮尔森相关系数公式计算的X1与任意数据库中的用户数组[X2,X3,X4,X5,X6,…]之间的相似度数组分别为[0.975,0.934,0.801,0.733,0.660,…]。
从该数组可以看出,目标用户X1与用户X4的相似度最大,但是仅仅计算用户之间的相似度是不够的。
3.4.2 环境相似度计算
下面来计算环境相似度。具体归一化处理后的环境信息如表4所示。

表4 环境信息矩阵
针对上述矩阵,利用皮尔森相关系数公式计算目标用户所处的当前环境Y1与数据库中任意用户之间的所处环境数组[Y2,Y3,Y4,Y5,Y6,…]的相似度数组为[0.916,0.521,0.497,0.441,0.534,…]。
3.4.3 综合相似度计算
计算出用户相似度和环境相似度后,再根据式(4)计算出基于用户和环境的综合相似度sim(u,v)。当α取0.6时,推荐精度最高的目标用户和所处环境Z1的最近邻居用户簇和环境簇数组[Z2,Z3,Z4,Z5,Z6,…]的综合相似度数组为[0.951,0.769,0.689,0.616,0.610,…]。
3.4.4 产生推荐
最后选取目标用户最近的邻居集合,例如选取综合相似度最大的前10个用户集合作为最近邻居集合,然后在最近邻居集合中选取综合相似度最大的前3个用户偏好和所处家居环境设置方案推荐给目标用户。
4 实验设计和结果分析
4.1 推荐质量的度量标准
为了验证文中描述算法的可行性和准确性,使用了一个度量标准,那就是平均绝对误差,即(Mean Absolute Error,MAE)[13]。由于这种标准的计算方式,是获取预测值与实际值二者间的差值,并以此度量准确性,故这个偏差值越小,就意味着预测精度越高。设预测结果用矩阵[p1,p2,…,pn]表示,对应的实际结果用矩阵[q1,q2,…,qn]表示,则
(5)
这里的预测值可以表示系统通过计算得到的推荐给用户的家居环境方案,而准确值可以表示用户在这种环境下自己手动设置的家居环境方案。例如,用户X1处在Y1的家居环境中,由于目前的环境参数与他的偏好不相符,所以系统通过计算给他提供推荐方案,但是他可以选择不使用系统的推荐方案而自己设置,这样就形成了两个方案的对比,通过计算这两种方案的MAE值,再和传统的协同过滤推荐方案的MAE值进行比较,来判断算法的有效性。
4.2 聚类算法的有效性验证
为了验证智能家居中基于用户和环境K-means聚类算法的有效性,从某智能家居公司中随机抽取1 500位用户和3 000个用户所处的历史环境并通过Matlab对其进行分析。在用户和环境集合中分别随机选取7个中心,以×表示,通过计算点与点之间的欧氏距离,得到的聚类结果如图2和图3所示。由图可知,在智能家居系统中,对用户和环境进行聚类时,采取K-means算法是有效的。
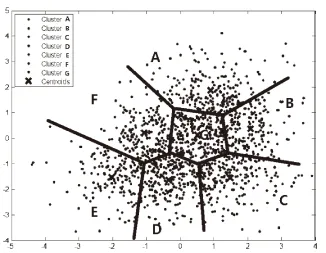
图2 1 500用户聚类结果
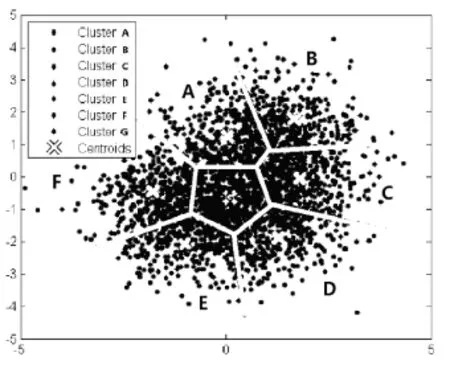
图3 3 000个环境数据聚类结果
4.3 权重系数α取值
式(4)中,权重系数α对推荐精度有很大影响,所以必须确定α的最佳取值来尽可能减小它对推荐精度的影响。α和1-α分别表示基于用户聚类的相似度和基于环境聚类的相似度系数。将α从0.1变动到1,变动幅度为0.1每次,在不同α取值的情况下,观察其对基于用户和环境双重聚类的协同过滤算法的推荐性能影响,从而确定最佳的权重值。α与MAE的曲线图如图4所示。
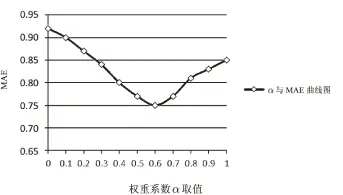
图4 α与MAE曲线图
由图可知,α=0.6为最佳权重值,推荐误差最小。
5 结束语
智能家居正不断发展[14-17],智能推荐已成为智能家居功能扩展中一个重要的趋势,利用智能推荐功能为用户提供定制信息服务将成为智能家居未来的主流。提出了一种基于用户和环境双重聚类的协同过滤算法并运用到智能家居系统中,该方法采用数据库设计思想构建用户库和环境库,从数据库发现目标用户最近邻居集合,从中选取综合相似度最大的前N个最佳方案推荐给用户。理论分析和实践结果均表明,相比现有的传统个性化推荐技术,该技术的性能更加优越。
[1] 李 宁.2012年,哪些技术最火?[N].光明日报,2012-04-10(12).
[2]ResnickP,IacovouN,SuchakM,etal.GroupLens:anopenarchitectureforcollaborativefilteringofnetnews[C]//ACMconferenceoncomputersupportedcooperativework.[s.l.]:ACM,1994:172-190.
[3]SchaferJ.Collaborativefilteringrecommendersystems[M].Germany:[s.n.],2007.
[4]HuangZ,ZengD,ChenHC.Acomparisonofcollaborative-filteringrecommendationalgorithmsfore-commerce[J].IEEEIntelligentSystems,2007,22(5):68-78.
[5]GoldbergD,NicholsD,OkiBM,etal.Usingcollaborativefilteringtoweaveaninformationtapestry[J].CommunicationsoftheACM,1992,35(12):61-70.
[6] 郭艳红.推荐系统的协同过滤算法与应用研究[D].大连:大连理工大学,2008.
[7] 张雪文.智能推荐系统中协同过滤算法的研究[D].上海:上海交通大学,2008.
[8]SarwarB,KarypisG,KonstanJ,etal.Incrementalsingularvaluedecompositionalgorithmsforhighlyscalablerecommendersystems[C]//Proceedingsoffifthinternationalconferenceoncomputerandinformationscience.[s.l.]:[s.n.],2002:27-28.
[9]GoldbergK,RoederT,GuptaD,etal.Eigentaste:aconstanttimecollaborativefilteringalgorithm[J].InformationRetrieval,2001,4(2):133-151.
[10]SoboroffI,NicholasC.Combiningcontentandcollaborationintextfiltering[C]//Proceedingsoftheinternationaljointconferencesonartificialintelligenceworkshop:machinelearningforinformationfiltering.Stockholm:[s.n.],1999:86-91.
[11]MiyaharaK,PazzaniMJ.ImprovementofcollaborativefilteringwiththesimpleBayesianclassifier[J].IPSJJournal,2002,43:3429-3437.
[12]HuangZ.Afastclusteringalgorithmtoclusterverylargecategoricaldatasetsindatamining[C]//ProceedingsoftheSIGMODworkshoponresearchissuesondataminingandknowledgediscovery.Tucson:[s.n.],1997:146-151.
[13]HerlockerJL,KonstanJA,TerveenLG,etal.Evaluatingcollaborativefilteringrecommendersystem[J].ACMTransactionsonInformationSystems,2004,22(1):5-53.
[14] 邓中祚.智能家居控制系统设计与实现[D].哈尔滨:哈尔滨工业大学,2015.
[15] 彭洪明.智能家居的体系结构及关键技术研究[D].北京:北京交通大学,2012.
[16] 吕 莉,罗 杰.智能家居及其发展趋势[J].计算机与现代化,2007(11):18-20.
[17] 高小平.中国智能家居的现状及发展趋势[J].低压电器,2005(4):18-21.
Application of Collaborative Filtering Recommendation Based on Double Clustering in Smart Home System
HU Lei,CAI Hong-xia,YU Tao
(School of Mechatronics Engineering and Automation,Shanghai University, Shanghai 200072,China)
To deal with the difficulty of acquiring effective information in smart home system for users,a collaborative filtering recommendation based on users and environment double clustering is proposed.It appliesK-meansmethodtoclustertheusersandenvironmentandfindoutthenearestneighborsoftargetuserandhomeenvironment.Thencomputesthecomprehensivesimilaritybetweentargetuserandotherusers,homeenvironmentoftargetuserandotherhomeenvironmentinsystem.ChoosesthefirstKrecommendationinthenearestneighborstotargetusers,realizingtheoptimizationofrecommendation.Experimentalresultsdemonstratethatthealgorithmcanimprovetheaccuracyofrecommendationcomparedwiththetraditionaloneandtheonebasedonuserorenvironment,withbetterreal-timeandscalability.
smart home;K-means;clustering;thenearestneighbors;collaborativefiltering
2016-01-11
2016-06-02
时间:2017-01-10
上海市科技重点攻关项目(15111102202)
胡 磊(1991-),男,硕士研究生,研究方向为智能家居系统;蔡红霞,硕士研究生导师,副教授,研究方向为工业信息化、计算机集成制造等;俞 涛,博士研究生导师,教授,研究方向为工业信息化等。
http://www.cnki.net/kcms/detail/61.1450.TP.20170110.0941.014.html
TP
A
1673-629X(2017)02-0100-06
10.3969/j.issn.1673-629X.2017.02.23
猜你喜欢
电子制作(2019年20期)2019-12-04
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
电子制作(2018年1期)2018-04-04
舰船电子对抗(2017年6期)2018-01-11
读与写·教育教学版(2017年10期)2017-11-10
Coco薇(2016年7期)2016-06-28
互联网天地(2016年1期)2016-05-04
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
