
基于误分类模式的乳腺癌诊断研究
2017-02-15 08:19:40高集荣杨永红刘清华
网络安全与数据管理 2017年2期
高集荣,田 艳,杨永红,刘清华
(1.中山大学 计算机科学系,广东 广州 510006;2.西安财经学院 统计学院,陕西 西安 710061)
基于误分类模式的乳腺癌诊断研究
高集荣1,田 艳2,杨永红1,刘清华1
(1.中山大学 计算机科学系,广东 广州 510006;2.西安财经学院 统计学院,陕西 西安 710061)
乳腺癌已经成为当今世界影响妇女健康的重要疾病。对于乳腺癌诊断来说,当一个恶性病例被误分类为良性病例的时候,其代价远远大于一个良性病例被误分类为恶性病例。它利用数据挖掘领域的代价敏感相关方法,建立一个识别良性乳腺肿瘤和恶性乳腺肿瘤的诊断预测系统。在建模过程中充分考虑到误分类代价的因素,提出了误分类代价策略。通过一系列实验验证了所建立的模型。从实验结果来看,Adaboost与SVM的误分类组合分类算法在正确率和总误分类代价两个评估指标上得到了良好的效果。
数据挖掘;代价敏感;误分类代价;乳腺癌
0 引言
乳腺癌已经成为当今世界影响妇女健康的重要疾病[1],全球乳腺癌发病率从上世纪70年代末起就一直呈上升趋势。据美国的调查,平均每8名美国妇女中,就有一个人在其一生中可能患有乳腺癌疾病。据中国国家癌症中心和卫生部疾病预防控制局2012年公布的2009年乳腺癌发病数据显示:全国肿瘤登记地区的女性恶性肿瘤排行榜上,乳腺癌发病率位居第1位。
乳腺癌的研究和治疗历史悠久,积累了不少的数据,如何从这些数据中发现有用的信息来辅助治疗,成了当下比较热门的一个课题。数据挖掘技术和机器学习的不断进步,将这些技术用于乳腺癌的识别和预测是大势所趋。再结合医生本身的经验来预测乳腺癌,这将是未来癌症疾病的诊断模式。
国内外对乳腺癌诊断预测的研究从未停止过,很多研究算法都得到了95%以上的正确率。但是这些研究所使用的数据集为威斯康星乳腺癌数据集,共收集病例样本699个样本,只有9个特征属性。
本文使用到的良恶性乳腺肿瘤分析的数据为威斯康星乳腺癌诊断数据集,含有569个样本(其中良性样本357个,恶性样本212个),30个特征维度[2];近些年的乳腺癌挖掘研究大都采用此数据集。
在进行乳腺癌诊断预测的过程中,降低误诊断的风险是一个实际的需求。如果是恶性乳腺肿瘤被预测为良性,其带来的后果比原本是良性的被预测为恶性的给病人带来的后果会更严重。因此,本文引入误分类代价,误分类代价是一种代价敏感的策略,它定义了被误分类为不同类型时所产生的成本是不同的。
1 算法描述
基于误分类的乳腺癌诊断预测建模主要分为两个步骤:首先是对数据集中的数据进行降维操作,乳腺癌细胞的特征属性本来就很多,本数据集中含有30个特征属性,如果直接对其进行建模,所花费的成本会很高,而且这么多特征属性之中,可能存在噪声数据,影响建模的效果;其次是使用基于误分类代价的建模方法对其数据进行训练和验证。文中重点考察了决策树和SVM两种分类方法,并且在研究中引入它们的误分类策略。
1.1 乳腺癌特征选择的方法
降维方式基本分为两种,特征选择和特征变换。特征选择方法依据是否独立于后续的学习算法又分为过滤式和封装式两种[3]。过滤式与后续的学习分类算法无关,一般是直接利用所有训练数据的统计信息评估特征,其特点是速度快;封装式利用后续学习算法的训练准确率评估特征子集,其特点是偏差小,计算量大。特征变换不同于特征选择之处在于其输出结果不是原有的属性,而是基于某种变换的原则所产生的新属性。作为医疗诊断来说,不仅需要诊断预测的结果,还重视其推理的过程。由于变换后的属性改变了原有属性的物理特性,不可能看到其推理的结果,因此这里不讨论特征变化方式。
本文研究的模型针对的是拥有30个属性维度的数据集,属于高维数据集。如果直接针对原始数据集采用分类方法,不仅成本较高,而且可能由于噪声属性的影响而降低精确度。
在绝大部分的特征选择方法中,其核心部分在于对属性特征重要性的评估,本文将选用三种特征重要度评估方式,其中一种是上文中提到的F-scores,另一种是在构建决策树过程中用于选择分裂数据集时评估属性的GINI方法,最后一种则是基于分类器的特征评估方式。选择这三种评估方式的先验条件是假定每一个特征是独立的,可以评估出每一个特征的重要程度,并按照重要程度进行降序排序,从而根据需要选择最重要的前N个特征属性。
1.2 乳腺癌误分类代价的组合分类研究
在进行了降维操作之后,需要对其进行分类建模操作。本文除了要基本保持诊断预测的正确率之外,还要降低其误分类诊断的总代价。这里将把误分类代价的概念引入到乳腺癌诊断预测课题中,误分类代价属于代价敏感的一种。
1.2.1 代价敏感
数据挖掘的本质在于利用一个特定的数学模型来给某一个数据进行分类,判定其类别,为了构建出数学模型,需要从大量的数据中获取信息,并发现其中蕴含的规律,最后利用这个规律,也就是数学模型来预测一些数据,得到其可能的一个类别,这个类别是通过预测而来的,可能会和该数据真实的类别(假设只能在未来验证得知)不一致,这时就会出现一个分类正确率的问题,对于一个预测数学模型来说,正确率是一个非常重要的指标。但是在实际应用中,代价因素也是不得不考虑的一个问题。
分类的代价不平等性给基于代价敏感的数据挖掘方法带来了全新的视角和方向。TURNEY P D[4]认为代价具有抽象的意义,可以用不同的单位来进行衡量,并且他归纳总结了分类过程中8种不同的代价类型:误分类代价、测试代价、标注代价、干预代价、计算代价、获取实例代价、人机交互代价、不稳定代价。
代价敏感,尤其是误分类代价在机器学习中重点处理的是数据不平衡的情况,担心大样本类别数据在建模过程中对分类结果产生一定的倾斜。而对于本文所研究的问题而言,这却是一个具有实际意义的问题。对于乳腺肿瘤良恶性诊断来说,当一个恶性病例被误分类为良性病例的时候,其代价远远大于一个良性病例被误分类为恶性病例的代价(主要指对病人的关注)。
对于二元分类问题,一个实例本来是i类别的,但是在分类预测的时候被错误地归为类别j,Ci,j表示将类别为i的事物预测为类别j时所产生的代价。
一个二元分类的代价矩阵定义如表1所示。其中,正确分类的不会产生代价。误分类代价的分类的目的就是要以最小误分类代价建立以下模型:
TotalCost=C0,1*FN+C1,0*FP
(1)
其中FN和FP分别为假负实例数和假正实例数。

表1 代价矩阵
1.2.2 组合分类器误分类策略
将误分类策略分别引入到基础分类器和组合分类器中,但是在大部分的误分类研究中,主要是使用单一的分类器进行误分类建模,在上述给出的单一误分类器中,从某种程度来说也改变了其建模过程中的一些步骤,因此可能与不引入误分类策略后分类正确率有所出入。为此,使用组合分类模式来降低个体分类器在引入误分类策略时所带来的误差,同时使用基于误分类策略的组合分类模式,也能达到基础分类器和组合分类器误分类效果的叠加。
本文使用的基础分类器有C45决策树和SVM,使用的组合分类器有Adaboost与Bagging。其中Adaboost拥有误分类策略,而Bagging尽管自身没有误分类策略,但是可以使用带有误分类策略的基础分类器来达到其误分类的效果。
2 算法验证
本节着重根据上文提到的各种方法对乳腺癌数据进行建模实验,从而构建出基于误分类代价的诊断预测系统。因篇幅所限,本文只列出了一部分。
2.1 N-交叉验证
交叉验证是数据挖掘实验中常用的方法。在N-交叉验证[5-6]中,将数据集随机划分为N份,并进行N次实验。在每一次实验中,选取与之前不同的一份作为验证集,剩余N-1份作为建立模型使用的训练集。
在本文的实验中会频繁用到N-交叉验证,例如在特征选择的时候,需要经过N-交叉验证来确定特征属性的重要程度;在建立预测诊断模型的时候,需要使用N-交叉验证来评估预测的准确性和总误分类代价。
2.2 评估标准
乳腺肿瘤良恶性诊断是一个分类问题,目前成熟的分类模型评估方式有:正确率、召回率、精确度、AUC、ROC曲线、混淆矩阵等。在混淆矩阵的基础上,可以得到以上多个评估度量值。其中正确率(Acc)和错误率(Err)是使用最广泛的两个基础度量标准,其公式如下:
(2)
(3)
除了基本的正确率和错误率之外,由于本文重点考察的是基于代价敏感的乳腺肿瘤良恶性诊断。在前文的描述中也提到,一个恶性乳腺癌患者被诊断为良性所付出的代价远比一个良性乳腺肿瘤患者被诊断为恶性所付出的代价要高得多。所以本文所做研究是,除预测结果基本保持在一个比较高的水准之外,还需要预测的代价尽可能地小。下面给出基本准则去判断实验评估指标,即预测产生的错误总代价(TotalCost)。
表2给出了乳腺癌预测的代价矩阵,其中如果本身为良性乳腺肿瘤而预测为良性,由于预测是正确的,因此不会产生代价,恶性乳腺肿瘤预测为恶性也是同样的道理。而如果本身是良性乳腺肿瘤被诊断为恶性的话,其花费的代价是C0,1,如果本身是恶性乳腺肿瘤而被诊断为良性的话,其花费的代价为C1,0,其中C1,0>C0,1。由此可以得到式(4):
TotalCost=FN*C0,1+FP*C1,0
(4)

表2 代价矩阵
本文希望达到的目标是:在保持正确率不会有太大下降的情况下,降低总的误分类代价。
2.3 误分类组合建模实验
在组合不同误分类代价策略时,基本分类器均具有其误分类代价策略,可以进行对比试验,而组合分类器只有Adaboost具有误分类策略,可考虑将基础误分类与Bagging组合分类器,而Adaboost可对比采用误分类策略与不采用误分类策略的效果,并同时与基础分类器的误分类策略进行整合。
为了看出误分类策略的效果,需要设计对比试验,下面针对每一个基础分类器设计了几组对比试验。表3给出了需要对比的实验,以证实在建模过程中确实有误分类策略的效果。

表3 对比实验设计
本文所采用的数据挖掘的基础程序来自Weka-3.6。怀卡托智能分析环境(Waikato Environment for Knowledge Analysis,Weka)是一款免费的、非商业化的挖掘工具,基于Java环境的开源的机器学习以及数据挖掘软件。源代码可在其官方网站下载,其中的C45基础算法也来自该官网。
SVM则采用LIBSVM的Java版本,LIBSVM是台湾大学林智仁等人开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归软件包,不但提供了编译好的可在Windows操作系统上执行的文件,还提供了源代码,方便改进、修改以及在其他操作系统上应用。
(1) C45算法结果分析
首先展示Adaboost+C45算法的结果,以便与后期结果进行对照。
(2) SVM算法结果分析
SVM在此问题上有很好的处理效果。这里可以对其进行分析比较,研究其在误分类代价的情况下的处理效果。本文采用的是LIBSVM的Java版本,其中一些参数均为默认值,其中核函数采用的是RBF核函数。
图1、图2分别给出了正确率、总代价曲线,表4给出了不采取误分类策略的Adaboost+SVM的最高评估值。
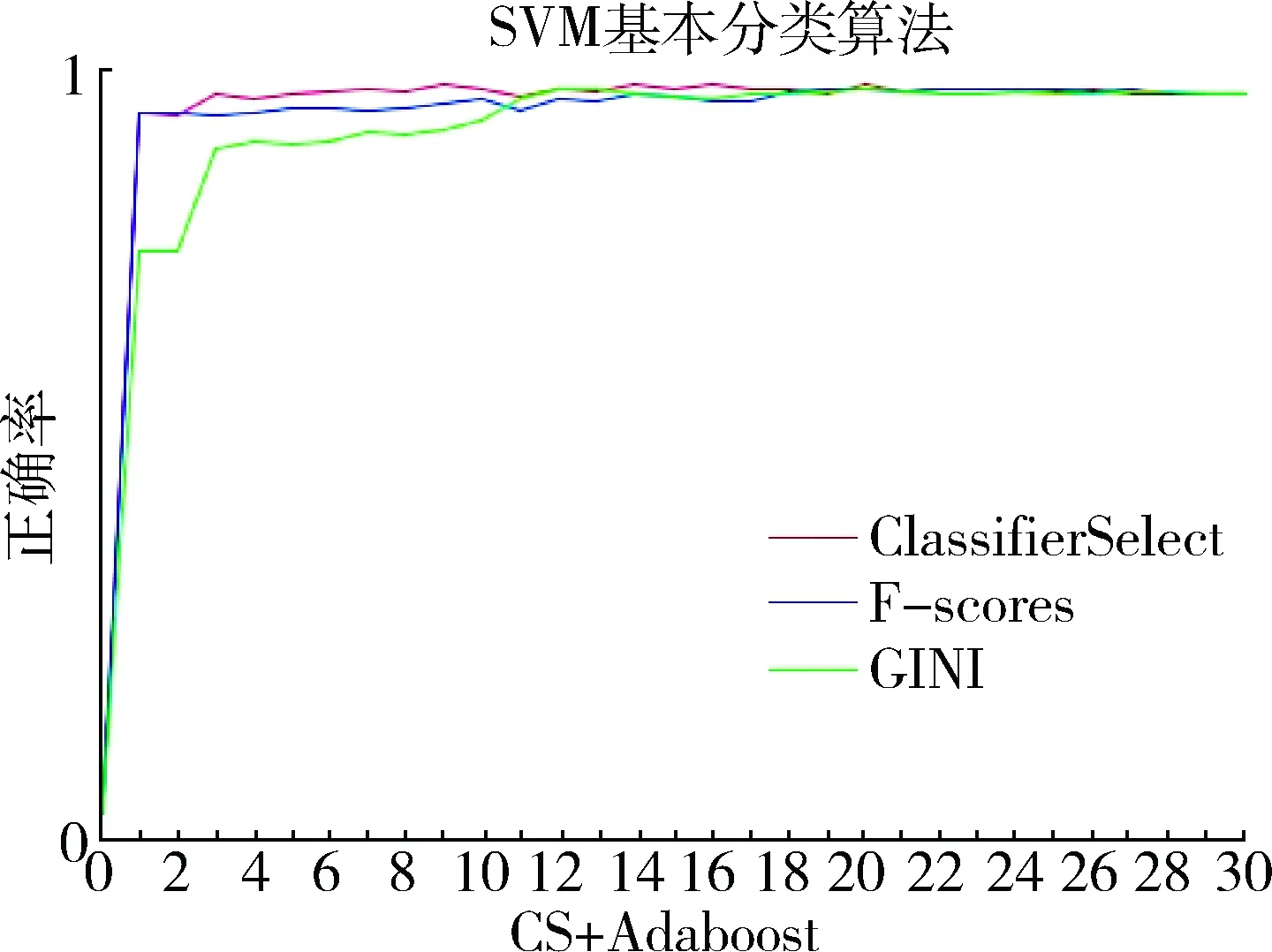
图1 选择不同数目特征Adaboost+SVM的正确率
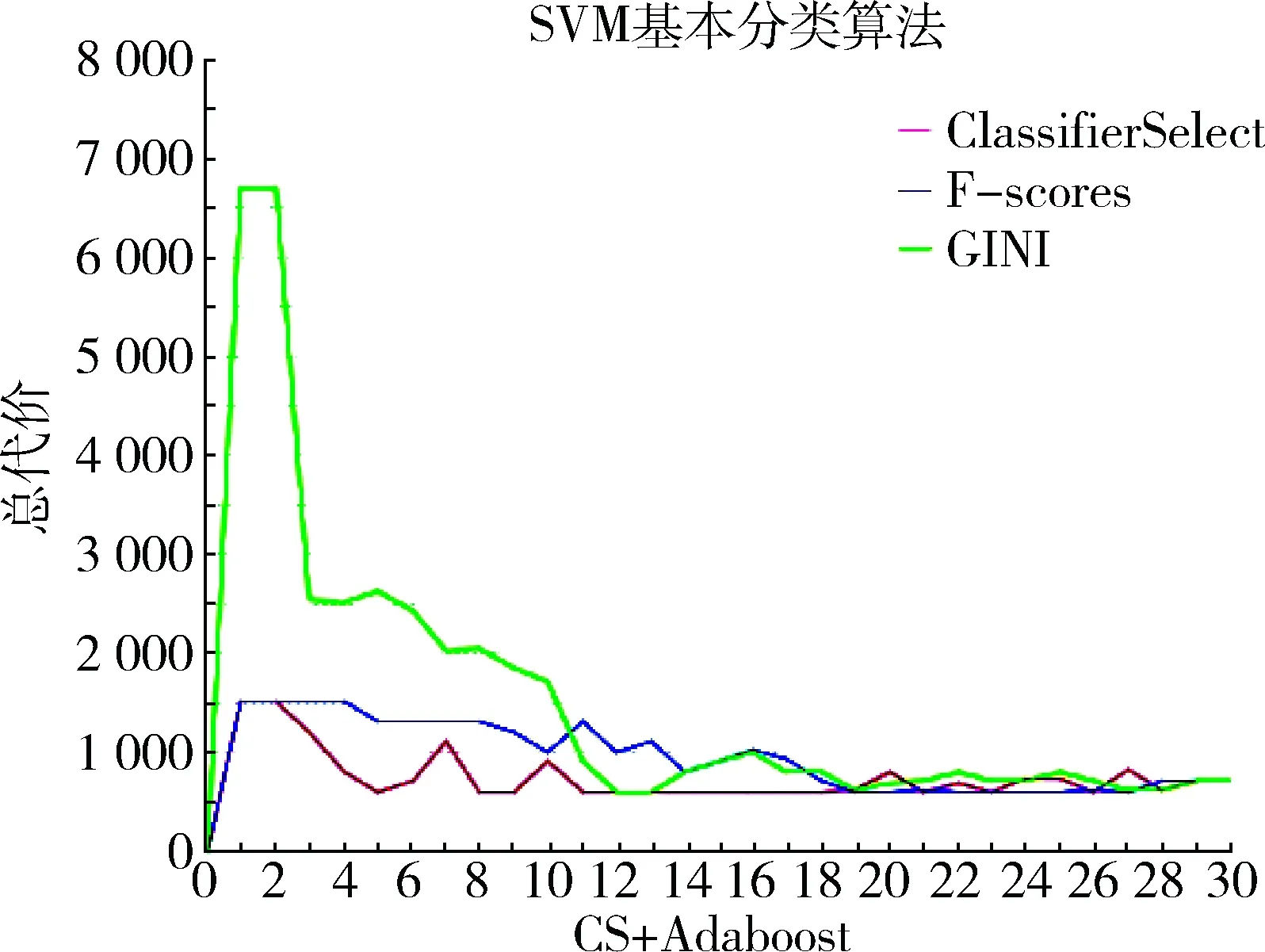
图2 选择不同数目特征Adaboost+SVM的总误分类代价
从实验结果可以看出,尽管Adaboost+SVM组合模式的正确率非常高,但是其代价也不低,主要原因在于其高误分类代价的个数比较多。而采用SVM的误分类策略组合模式可能可以做到既拥有比较高的分类正确率,又能减少其高代价误分类的个数,从而降低总的误分类代价。
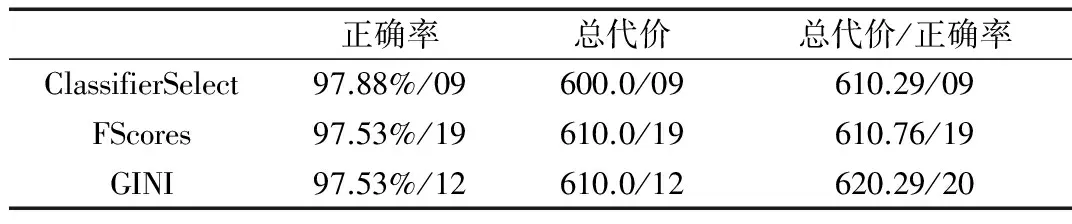
表4 Adaboost+SVM不同特征选择策略的最高评估值
从对比实验可以看出,SVM在误分类代价策略效果下表现得比决策树都要好一些。其相对较高的正确率是一个重要原因,从SVM和决策树两者的表现来看,SVM构建模型的分类正确率远高于决策树,因而被误分类的个数要小于决策树;另一原因是在采用了误分类代价策略之后,恶性乳腺肿瘤被诊断为良性的个数比不采用误分类策略时减少了,所以总的误分类的代价才会减少。
实验结果表明,大部分实验都达到了其降低总误分类代价的目的,而且能保持比较高的正确率:Adaboost与SVM的误分类组合分类算法不仅正确率达到了98.23%,而且将总误分类代价从600左右降到了330。
3 结论
本文结合传统的基础分类算法,运用组合分类模式进行诊断预测,并针对乳腺癌样例的特征属性采取了降维的处理,旨在降低建模过程的成本和对样例进行预测时的成本,并希望清除噪声属性。同时,也将代价敏感的概念引入到乳腺癌诊断过程中。在建模过程中,将误分类代价策略和基础分类模式、组合分类模式Bagging和Adaboost进行整合修改,以便能在保持较高正确率的情况下,降低总的误分类代价。设计了对比试验,以便能得出最优的组合分类模式;在此基础上采用粒子群算法,以最低误分类代价为评估标准,采用上述组合实验中的最佳组合分类方法,选择出最稳定的低误分类代价的特征属性和相关参数值。
[1] The Women’s Health Resource .What is breast cancer[EB/OL].(2013-06-10)[2016-07-28].http://www.imaginis.com/general info-rmation-on-breast-cancer/what-is-breast-cancer-2.
[2] UCI Machine Learning Repository. Wisconsin breast cancer dataset[EB/OL]. (2012-06-30)[2016-07-28]http://archive.ics.uci.edu/ml/datasets.html?format=&task=cla&att=&area=&numAtt=&numIns=&type=&sort=.
[3] 姚旭.特征选择方法综述[J].控制与决策.2012,127(2):35-40.
[4] TURNEY P D. Types of cost in inductive concept learning[C]. Workship on Cost-Sensitive Learning at ICML, 2000:15-21.
[5] DUPRET, G. KODA, M. Theory and methodology: boostrap resampling for unbalanced data in supervised learning[J]. Eropean Journal of Operational Research,2001,134(1), 141-156.
[6] GOOD,P.I. Resampling methods: a practical guide to data analysis (3rd Edition)[M]. Birkhauser, 2006.
Research on breast cancer diagnosis based on the pattern of misclassification
Gao Jirong1, Tian Yan, Yang Yonghong1, Liu Qinghua1
(1.Department of Computer Science , SUN YAT-SEN University,Guangzhou 510006,China; 2.Institute of Statistics, Xi’an University of Finance and Economics, Xi’an 710061,china)
Breast cancer has become an important disease affecting women’s health in today’s world. The cost of a malignant case mistakenly being classified as a benign one is far greater than the cost of a benign case being wrongly classified as a malignant one. Through cost-sensitive method in the field of data mining, a diagnosis predictive system which can distinguish the benign breast tumor from the malignant tumor will be built. During the process of pattern building, the misclassification cost factors are taken into consideration and the corresponding strategies are put forward. This pattern will be validated through a series of experiments whose findings show that Adaboost combined with classification algorithm of SVM based on error classification can obtain good results in the two evaluation indexes, accuracy and total misclassification cost.
data mining; cost sensitive; misclassification cost; breast cancer
TP393.092
A
10.19358/j.issn.1674- 7720.2017.02.004
高集荣,田艳,杨永红,等.基于误分类模式的乳腺癌诊断研究[J].微型机与应用,2017,36(2):10-13,16.
2016-07-28)
高集荣(1960-),男,硕士,副教授,主要研究方向:数据库技术、网络技术及其应用。
田艳(1962-),女,学士,教授,主要研究方向:信息管理技术、网络技术及其应用。
杨永红(1967-),女,硕士,讲师,主要研究方向:计算机理论、算法。
猜你喜欢
中华养生保健(2020年7期)2020-11-16 01:14:26
电子测试(2018年1期)2018-04-18 11:52:35
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
故事会(2016年15期)2016-08-23 13:48:41
中学生(2015年12期)2015-03-01 03:43:53
