
浅谈声纹识别技术与安全
2017-02-14 09:26阿里巴巴安全部
网络安全技术与应用 2017年1期
阿里巴巴安全部 王 炎
浅谈声纹识别技术与安全
阿里巴巴安全部 王 炎
0 前言
在这个移动互联网大行其道的年代,人们不用互相见面就可以完成很多事情,比如社交、购物、网上开店、金融交易等等,但是如何验证身份变成了人和人在不见面的情况下最难的事情。传统的解决方案就是密码或者秘钥,它需要你记住或者存起来,容易忘又容易丢,还容易被黑客利用各种手段攻击。有多少人使用“123456“这种简单密码在网络上行走,他们就是黑客们最喜欢的目标; 你家的路由器是不是还在用”admin”这种默认密码,这就是物联网领域中安全最薄弱的环节。不过,好在我们每个人身上都长满了“活密码”,指纹、脸、声音、眼睛等等,都是人和人之间相互区分的独一无二的标识,我们称之为“生物特征”。声音就是这种一种可以反映人身份的生物特征,参考“指纹”的命名方式,我们可以叫它“声纹”,见图1。
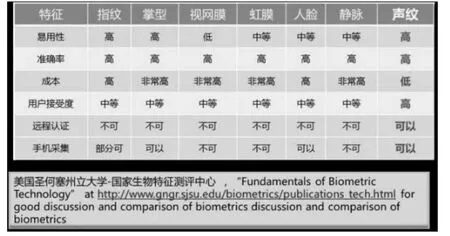
图1 各种生物特征比较
声纹是指人类语音中携带言语信息的声波频谱,它同指纹一样,具备独特的生物学特征,具有身份识别的作用,不仅具有特定性,而且具有相对的稳定性。声音信号是一维连续信号,将它进行离散化后,就可以得到我们现在常见的计算机可以处理的声音信号,见图2。

图2 计算机可以处理的离散声音信号
声纹识别(也称说话人识别)技术也如同现在在智能手机上应用十分广泛的指纹识别技术一样,从说话人发出的语音信号中提取语音特征,并据此对说话人进行身份验证的生物识别技术。每个人都具有独一无二的声纹,这是由我们的发声器官在成长过程中逐渐形成的特征。无论别人对我们的说话模仿的多么相似,声纹其实都是具有显著区别的。
现实生活中的“未见其人,先闻其声”就是人类通过声音去识别另一个人身份的真实描述,你妈甚至通过你电话里的一个“喂”字就知道是你,而不是隔壁老王家的儿子打的电话,这是我们人类经过长期进化所获得到的超常的能力。虽然目前计算机还做不到通过一个字就判断出人的身份,但是利用大量的训练语音数据,可以学出一个“智商”还不错的“声纹”大脑,它在你说出8-10个字的情况下可以判断出是不是你在说话,或者在你说1分钟以上的话后,就可以准确地判断出你是否是给定的1000人中的一员。这里面其实包含了大部分生物识别系统都适用的重要概念:1:1 和1:N,同时也包含了只有在声纹识别技术中存在的独特的概念:内容相关和内容无关。
1 工作原理
对于一个生物识别系统而言,如果它的工作模式是需要你提供自己的身份(账号)以及生物特征,然后跟之前保存好的你本人的生物特征进行比对,确认两者是否一致(即你是不是你),那么它是一个1:1的识别系统(也可以叫说话人确认,Speaker Verification); 如果它只需要你提供生物特征,然后从后台多条生物特征记录中搜寻出哪个是你(即你是谁),或者哪个都不是你,那么它是一个1:N的识别系统(也可以叫辨认,Speaker Identification),见图3。技术上,简单的声纹识别的系统工作流程图来见图4。

图3 说话人确认和说话人辨认

图4 声纹识别工作流程图
对于声纹识别系统而言,如果从用户所说语音内容的角度出发,则可以分为内容相关和内容无关两大类技术。顾名思义,“内容相关”就是指系统假定用户只说系统提示内容或者小范围内允许的内容,而“内容无关”则并不限定用户所说内容。前者只需要识别系统能够在较小的范围内处理不同用户之间的声音特性的差异就可以,由于内容大致类似,只需要考虑声音本身的差异,难度相对较小; 而后者由于不限定内容,识别系统不仅需要考虑用户声音之间的特定差异,还需要处理内容不同而引起的语音差异,难度较大。
目前有一种介于两者之间的技术,可以称之为“有限内容相关”,系统会随机搭配一些数字或符号,用户需正确念出对应的内容才可识别声纹,这种随机性的引入使得文本相关识别中每一次采集到的声纹都有内容时序上的差异,这种特性正好与互联网上广泛存在的短随机数字串(如数字验证码)相契合,可以用来校验身份,或者和其他人脸等生物特征结合起来组成多因子认证手段。
具体到声纹识别算法的技术细节,在特征层面,经典的梅尔倒谱系数MFCC,感知线性预测系数PLP、深度特征Deep Feature、以及能量规整谱系数PNCC 等,都可以作为优秀的声学特征用于模型学习的输入,但使用最多的还是MFCC特征,也可以将多种特征在特征层面或者模型层面进行组合使用。在机器学习模型层面,目前还是N.Dehak在2009年提出的iVector框架一统天下,虽然在深度学习大红大紫的今天,声纹领域也难免被影响,在传统的UBM-iVector框架下衍化出了DNN-iVector,也仅仅是使用DNN(或者BN)提取特征代替MFCC或者作为MFCC的补充,后端学习框架依然是iVector。
图5示出了一个完整的声纹识别系统的训练和测试流程,可以看到在其中iVector模型的训练以及随后的信道补偿模型训练是最重要的环节。在特征阶段,可以使用BottleNeck特征取代或者补充MFCC特征,输入到iVector框架中训练模型,如图6所示。
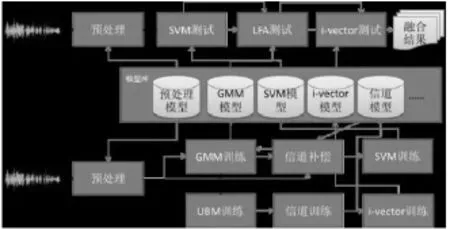
图5 声纹识别算法的完整训练和识别框架

图6 使用BottleNeck特征训练iVector模型
在系统层面,不同的特征及模型,可以从不同的维度刻画说话人的声音特征,加上有效的分数规整,将各子系统融合能有效的提高系统的整体性能。
2 针对声纹识别的攻击
声纹识别作为一种安全身份认证手段,不可避免的要面临非法用户的攻击风险。声纹识别算法目前技术水平有限,很难识别声音十分相似的两人:现在大部分的算法都可以控制在误识率在千分之一,即随机1000个不同人的刻意攻击,有可能会有一个人因声音过于相似而通过。
2.1 熟人模仿攻击
你身边熟悉你的人模仿你的声音,去攻击你的声纹账户,通过的概率比上述随机攻击会更大一些。当然,人与人之间的声音本身有本质的不同,即便人耳不一定能听出来,声纹识别系统对这种差异是非常敏感的,模仿很难成功攻击。
2.2 重放攻击
如果你的声音被某些别有用心的人录下来,然后在声纹登录时播放你的声音。当前,技术上对这种攻击可以有两种防范手段:活体检测和随机内容声纹,活体检测技术可以有效的识别出当前认证的声音来自于真人还是录音设备,而随机内容声纹在每次登录的时候会提示用户必须说随机显示出来的内容,只要说的内容不一致,认证就会失败,这样,让提前录好的声音失效。
2.3 特定人声音合成或声音转换
利用机器学习、深度学习等技术,通过对目标人的一段录音进行建模,学习出目标人的声音特质并将其参数化,然后将非目标人的声音合成并转化为目标人的声音进行攻击; 在深度学习技术流行之前,传统的机器学习技术合成的声音在真实度上比较差,但是近年类似google的WavNet,以及Adobe Project VoCo等技术,极大的提高了声音合成的真实度,对声纹识别算法造成了潜在的威胁。

图7 声纹验证信号处理
声纹识别技术使用便捷,受限制较少。硬件设备简单,只需要有麦克风即可; 不受语种、方言、性别和年龄的影响。并且适合远程使用,可适用于远程控制与识别领域; 在用户正常说话中,即可后台远程进行声纹识别。用户接受程度高:不易遗忘,防伪性能好、不易伪造或被盗。随身“携带”,随时随地使用。
但是它同样也有一些缺点,比如同一个人的声音具有易变性,易受身体状况、年龄、情绪等的影响。不同的麦克风和信道对识别性能有影响,环境噪音和混合说话人对识别有干扰,并且在部分公共场合,用户不方便说话。
目前看来声纹识别技术是未来的发展趋势,随着声音合成技术的发展,对声音活体检测技术也提出了更高的要求。在大数据条件下,利用部分准确或不准确的说话人标注,自动建立说话人模型,具有重要的实际应用意义。
随着数据资源的增多,对声纹识别系统的检索要求的相应时间也越来越短。充分利用移动互联网时代产生的大量语音数据,发挥深度学习的数据驱动威力,可以将声纹识别算法的准确率和鲁棒性大幅提升。
12月份举办的阿里聚安全攻防挑战赛中,声纹身份验证攻防闪亮登场。参赛者可以尝试用声音攻击一套声纹验证系统,通过设计攻击用的音频骗过声纹验证系统,让系统验证成功。这是阿里聚安全在安全挑战赛模式上的一大创新,相信未来会有更多新颖的安全攻防技术出现在各类挑战赛中。
猜你喜欢
天天爱科学(2022年9期)2022-09-15
天天爱科学(2022年4期)2022-05-23
当代水产(2022年3期)2022-04-26
航空世界(2020年10期)2020-01-19
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
通信产业报(2018年32期)2018-11-24
浙江大学学报(工学版)(2015年1期)2015-03-01
