
基于深度学习的视频敏感信息检索的研究
2017-02-03 05:04:52李想
电子设计工程 2017年21期
李想
(武汉邮电科学研究院湖北武汉430000)
随着互联网技术的快速发展,数据量呈指数式的增长,伴随着移动互联网的浪潮,我们真正进入了大数据时代。于此同时,视频作为网络数据的重要组成部分,其数目也在飞速增长,如何管理这些视频信息,已成为很棘手的问题。视频检索技术的出现使得我们能提取视频关键信息,而深度学习的出现使得我们能对视频中敏感信息进行高效准确的分类,从而能得到敏感信息。
第二部分是基于深度学习的分类模型,该模型用于将得到的关键帧进行分类,检索我们需要的信息。本文设计了一种基于深度学习的网络模型VGG16,它是一种卷积神经网络。由一系列的偏置项和权重项的神经元组成,每个神经元都接受若干输入,并进行点积计算。将结果进行非线性处理,最后通过分数函数进行预测。整体设计流程图如图1所示。
1 总体设计

图1 总体设计流程图
本文设计分为两部分,第一部分为视频关键帧提取部分,设计一种算法从一段视频中提取一段关键帧序列,用来代表整段视频的主要内容。该算法对整段视频进行镜头边界检测,对于任何一个镜头,我们将第n/2作为其关键帧,然后生成一个视频关键帧候选的序列,对该段序列进行K-Means聚类,通过聚类的有效性分析方法选取最佳的聚类数量。最后对于每一类选取聚类中心的帧作为视频的关键帧[1-4]。
2 视频关键帧提取部分的实现
本文设计的关键帧提取算法分为3部分:视频特征的提取、视频边界检测、关键帧序列的聚类。
2.1 视频特征提取
特征,即对应某一对象某些可量化的属性。对于视频来说,主要分为通用性特征和针对特定领域的特征[5-6]。针对视频的多样性,本文考虑的是通用性特征。总结考虑到关键帧提取速度、图像特征提取的高效性,图像特征选为颜色直方图和颜色分部描述子。
一般来说图像颜色的表示都是基于颜色空间的,例如 RGB、HSV、YCbCr等[7-8]。本文设计的算法是在HSV颜色空间中生成的颜色直方图,其中H分为16份,S和V分为4份,所以生成了256个直方图索引。首先对直方图索引进行初始化即:Hist(h,s,v)=0,直方图的两帧fi和fj的相似度可以定义为:

其中0表示两图的颜色直方图差距最大,1表示相同。对于颜色分部描述子,它是用来描述图像中颜色的空间分部该特征提取过程分为:图像分块,即属于图像分为64个等大的区域;主导颜色选择,即每一块选取一个主导颜色并生成一个8*8的微缩图;对64个像素的Y、Cb、Cr分量进行离散余弦变换,得到3组系数;最后对得到的离散余弦洗漱进行Zigzag扫描,从中选取少量的低频系数构成改头像的分部描述子。分别记为Dy、DCb、DCr.此时定义帧fi和帧fj之间的距离为
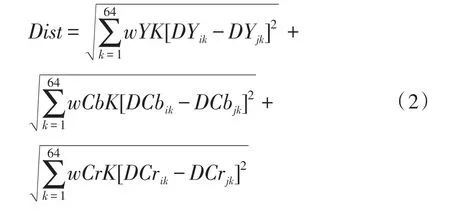
其中DYik表示帧fi的Y分量的离散余弦系数的第k项,wYK对应其权重;越接近0表示两帧图像越相似,图像描述子方便在不进行视频切割的情况下,对图像进行快速检索。
2.2 视频边界检测
本文的边界检测基于突变型的镜头切换,根据视频领域变换的特点,给出了镜头边界系数的定义,该系数抗噪能力强。设邻域窗的宽度为2N+1,所以第i帧的邻域窗帧差为:
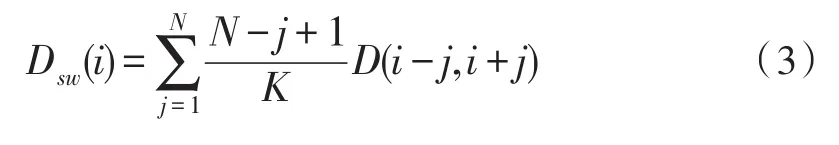
其中K=N(N+1)/2。相对而言,镜头内的变化比镜头间的变化小的多;若镜头内任意两帧距离为Ds,镜头间为Db,显然Ds<<Db,若此时N取3,切第K帧和第K+1帧发生镜头突变,则可得去常数序列Osw(j)为(1,3,6,6,3,1),定义第i帧镜头边界相似系数:

根据前面所得,当相邻帧之间切换时,镜头边界相似系数接近1,其余情况下为0与1之间一个较小的值。图2为某段视频的视频边界系数。

图2 视频边界系数图
图中的峰值点对应于镜头切换,非边界处镜头边界系数较小,这使我们更好的选取阈值,本文中取0.85,当且仅当镜头边界系数大于该值时,我们认为检测到了镜头边界。
2.3 关键帧序列的聚类
由于同一镜头可能重复出现,这将导致我们得到的关键帧序列出现重复,为了降低最终得到的关键帧序列的重复性,我们对关键帧序列进行了聚类操作:即K均值聚类,最后通过聚类的有效性方法确定K值[9-10]。
本文的评价方案是M.Halkidi提出的,定义了聚类性能指标SD(c)=aScat(c)+dis(c),其中Scat(c)为单一类的类内距离,a为Dis(c)表示类之间的距离,由于此两项的取值范围相差较大,故设置一个权重因数a,也就是Dis(cmax),其中cmax为最大预设聚类数量。当且仅当该值最小时取得的c,为最优聚类数量。
3 基于深度学习的网络架构的实现
文中用到的神经网络是基于卷积神经网络,它是由一系列的偏置项和权重向的神经元组成[11-15]。具体结构如图3所示。
VGG16模型是一种卷积神经网络模型,数据通过带有偏置项和权重项的神经元输入,然后进行点积,对结果进行非线性处理和分数函数预测。本文应用的VGG16模型采用BP算法来求解目标函数,采用将输出的算是函数误差反向传播到各层的输出单元上,求解权重梯度,之后更新权重参数。利用BP算法反复迭代减少误差,以此来完成整个模型的训练。

图3 VGG16模型结构图
训练过程中学习率为0.01,动量为0.9,权值衰减为0.000 5,每迭代10个epoch学习率衰减10倍,每迭代100次显示一次,最大迭代次数为30个epoch。
4 实验
本部分主要对上文中设计的网络模型进行测试和并通过对比选出最优结果。选取如表1所示的样本集。
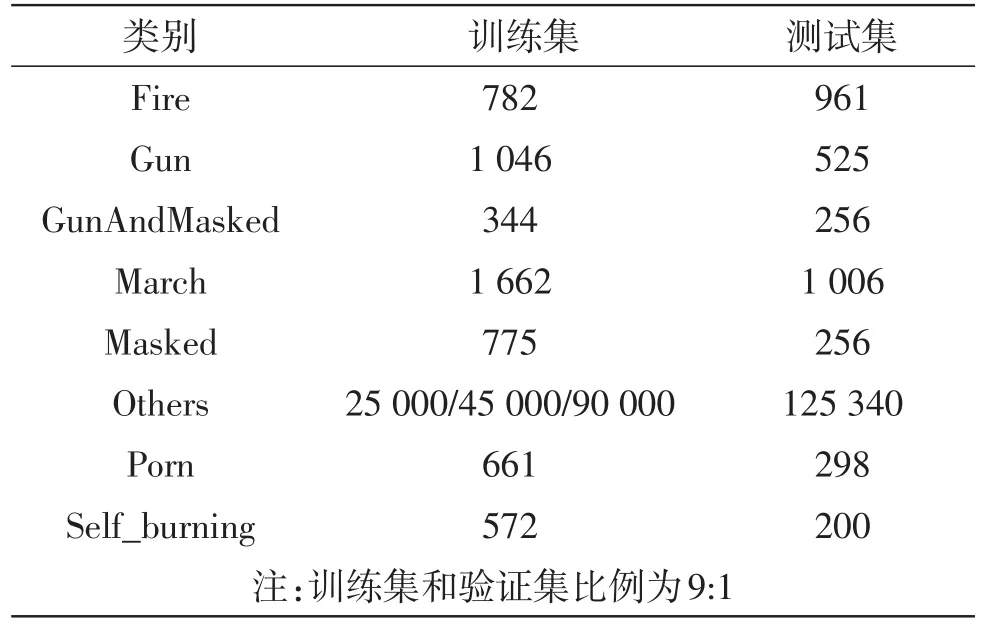
表1 各类训练集和测试集样本数一览表
针对Others类(安全类,负样本)非常多,其它不安全类所占比例非常小(250:1)的问题,提出在训练分类模型时,增大Others类训练样本在整个训练集中所占的比例。这里我们实验了3个模型,其它不安全类训练样本数不变,Others类样本数分别为25 000、50 000、100 000。并通过我们设计的模型进行训练,结果如表2~4所示。
其中,TP为系统检索到的相关文件数,TP+FN为系统所有相关的文件总数,TP+FP为系统所有检索到的文件总数,Recall为系统召回率,Precision为系统准确率。
把表格结果各个类的召回率和准确率用折线图表示出来如图4所示,横坐标表示Others类样本数增加:

表2 训练集Others类样本数为25 000

表3 训练集Others类样本数为50 000

表4 训练集Others类样本数为10 0000
由图表实验结果可以看出,随着Others类训练集样本数增加,系统平均Recall(召回率)下降,Precision(准确率)上升。当Others类训练集样本数为50 000时,系统平均召回率为0.793 158,准确率为0.719 958。当Others类训练集样本数为100 000时,系统平均召回率为0.755 652,准确率为0.723 318。两个模型都满足要求。从折线图可以看出,随Others类训练集样本数增加,系统召回率下降较快,并且有一半以上的类在Others类训练集样本数为50 000时,准确率最高。所以我们认为当Others类训练样本数为50 000时,模型分类效果最好。

图4 Others类增加时类召回率(图a)与类准确率(图b)曲线图
5 结束语
本文针对视频中如何快速检索敏感信息的问题,首先通过基于边界相似系数的关键帧提取算法提取能表示视频主要内容的关键帧,然后可以通过应用的VGG16模型进行敏感信息快速检索。为了验证该模型的有效性及最优性,文章最后对该模型进行测试验证,并通过改变Others类的数目对比试验,确定了最优模型。
[1]曹长青.基于内容的视频检索中关键帧提取算法研究[D].太原:太原理工大学,2013.
[2]汪翔.基于内容的视频检索关键技术研究[D].合肥:安徽大学,2012.
[3]惠雯,赵海英,林闯,等.基于内容的视频取证研究[J].计算机科学,2012,39(1):27-31.
[4]夏洁,吴健,陈建明,等.基于虚拟检测线的交通视频关键帧提取[J].苏州大学学报:工科版.2010,30(2):1-5.
[5]Jia Y,Shelhamer E,Donahue J,et al.Caffe:Convolutional architecture for fast feature embedding[C].ACM Multimedia,2014.
[6]Ross Girshick,Jeff Donahue,Trevor Darrell,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[J].Computer Science,2013:580-587.
[7]Pass G,Zabih R.Histogram refinement for content-based image retrieval[C]//IEEE Workshop on Applications ofComputer Vision.IEEE Computer Society,2012:96-102.
[8]He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[J]. Computer Science,2015.
[9]Angadi S,Naik V.Entropy based fuzzy c means clustering and key frame extraction for sports video summarization[C]//Signal and Image Processing(ICSIP),2014 Fifth International Conference on.IEEE,2014:271-279.
[10]Charikar M S.Similarity estimation techniques from rounding algorithms[C]//Thiry-Fourth ACM Symposium on Theory of Computing.ACM,2010:380-388.
[11]Yoo D,Park S,Lee J Y,et al.Multi-scale pyramid pooling for deep convolutional representation[C]//Computer Vision and Pattern Recognition Workshops.IEEE,2015:71-80.
[12]Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[J].Advances in Neural Information Processing Systems,2012,25(2):2012.
[13]Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J].Eprint Arxiv,2014.
[14]Yoo D,Park S,Lee J Y,et al.Multi-scale pyramid pooling for deep convolutional representation[C]//Computer Vision and Pattern Recognition Workshops.IEEE,2015:71-80.
[15]Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[C].ComputerVision and Pattern Recognition,2015.
猜你喜欢
高中数理化(2024年1期)2024-03-02 17:52:40
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:40
湖南林业科技(2021年3期)2021-12-02 21:15:32
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:02
大连理工大学学报(2017年4期)2017-08-07 07:03:20
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
西北工业大学学报(2015年3期)2015-12-14 13:08:46
计算机工程(2015年8期)2015-07-03 12:20:21
计算机工程与应用(2015年19期)2015-04-16 08:51:36
文艺生活·中旬刊(2014年12期)2015-01-06 03:03:56
