
海量数据日志系统架构分析与应用
2017-01-18 05:48刘锴
长春工业大学学报 2016年6期
刘 锴
(安徽农业大学 现代教育信息中心, 安徽 合肥 230036)
海量数据日志系统架构分析与应用
刘 锴
(安徽农业大学 现代教育信息中心, 安徽 合肥 230036)
介绍了多种分布式日志系统的架构和数据处理流程,以ELK日志系统(即Elastic search,Logstash和Kibana)为例,介绍ELK在不同场景中的架构特点以及应用案例。
日志; 分布式; ELK; 架构
0 引 言
日志,通常是指以文本模式记录的数据,该数据反映了系统运行过程、状态以及各种关键信息。对每个系统来说,日志都是很重要的记录信息。随着信息化的飞速发展,传统的单一节点的日志系统已经无法记录指数级增长的日志数据,更不用说分析和处理这些数据了。目前,利用分布式平台实现的日志系统逐渐成为日志系统家族中的主力军,他们运行在多个节点组成的集群中,通过算法统一调度,可以实现海量日志的准实时处理。文中将详细介绍分布式日志系统的几种系统架构,并以ELK日志系统(即Elastic search,Logstash和Kibana)为例,介绍其不同场景下的部署架构,最后给出ELK的实际应用案例。
1 日志系统发展现状
所有信息系统平台每天会产生大量的日志,通常以流式数据为主,包括用户访问记录、数据库操作记录等,当数据量达到一定的数量级,传统的单节点系统已经无法完成检索及分析任务,必须使用分布式的日志系统对他们进行处理。一般而言,这些系统需要具有以下特征:
1)构建应用系统和分析系统的桥梁;
2)支持准实时的在线分析系统和类似于Hadoop之类的离线分析系统;
3)具有高可扩展性和可靠性。即:当数据量增加时,可以通过增加节点进行水平性能扩展[1];当某个或某一些节点发生故障时,只影响系统的性能,系统功能性不受影响。
目前在这一领域较为先进的系统包括cloudera的Flume、linkedin的Kafka以及facebook的Scribe等[2]。
1.1 Flume
Flume是cloudera设计开发的开源日志系统,以可靠性、可扩展性、可管理性以及功能可扩展性为设计目标,它内置的各种组件非常齐全,用户几乎不必进行任何额外开发即可使用。Flume采用了分层架构,由三层组成,分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink。source是数据来源,sink是数据去向[3]。
Flume架构如图1所示。
1.2 Kafka
Kafka是采用scala语言编写的开源项目,使用了多种效率优化机制,采用比较新颖的push/pull架构,更适合异构集群[4],底层采用Hadoop作为数据平台。它实际上是一个包含producer,broker和consumer三种角色的系统。其中producer负责向某个topic发布消息,而consumer作为接收方订阅这个topic的消息,一旦出现关于这个topic的新消息,broker负责将新消息传递给订阅它的所有consumer。由此可以看出,在Kafka中,topic是组成消息的关键,而为了便于管理数据和进行负载均衡,每个topic又会分为多个partition。同时,Kafka也使用了zookeeper进行负载均衡[3]。
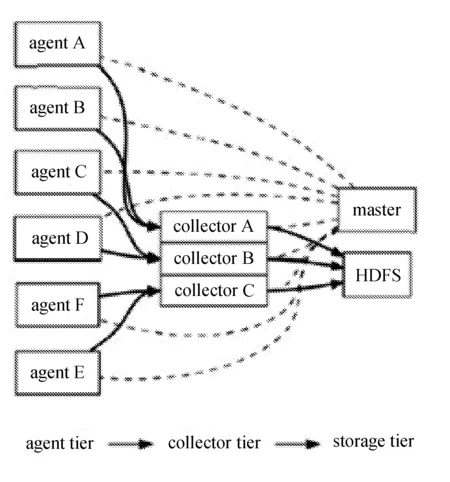
图1 Flume架构图
Kafka架构如图2所示。
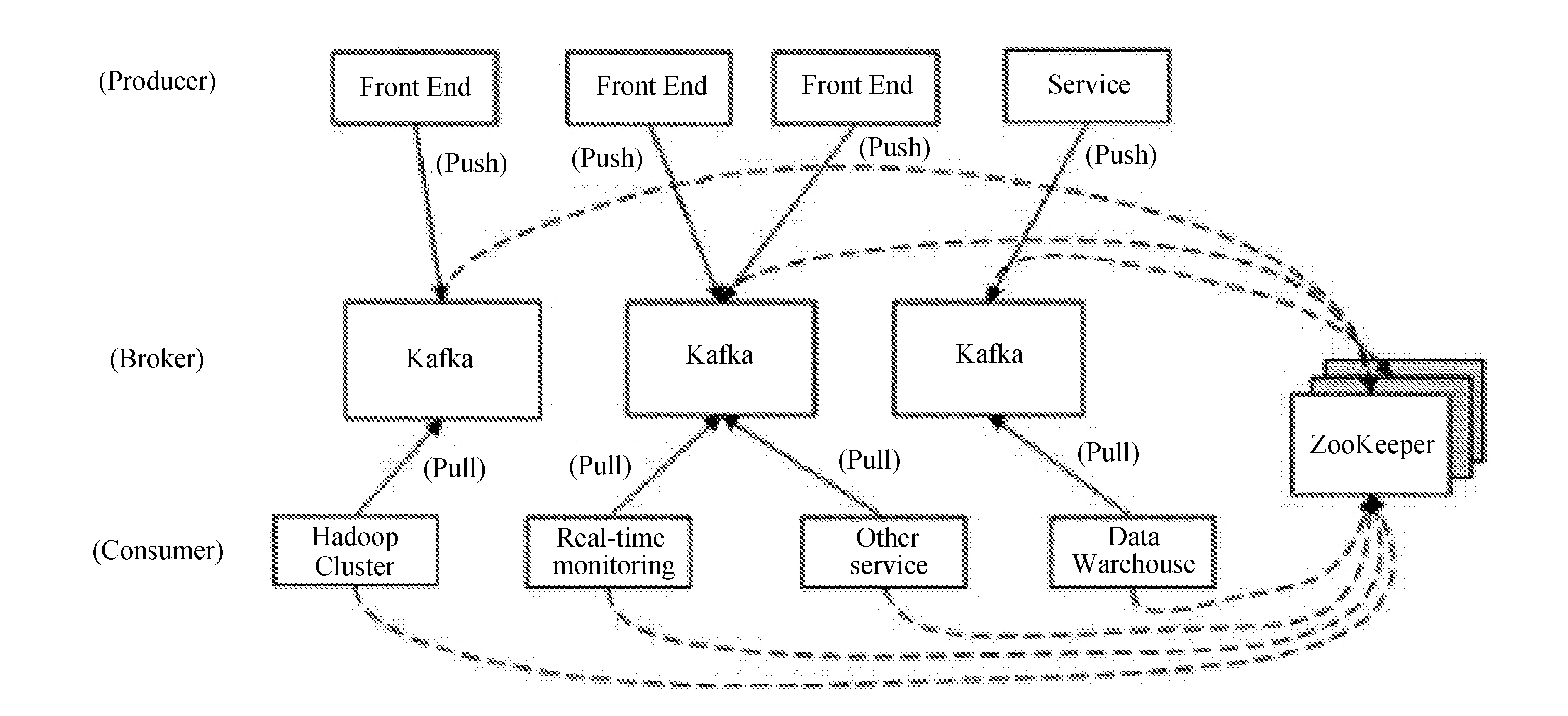
图2 Kafka架构图
1.3 Scribe
Scribe是facebook开源的日志收集系统,facebook公司内部已经大量使用Scribe系统。Screbe系统中存在一个中央存储系统,该系统可由NFS或者分布式文件系统组成,Scribe通过各种日志源收集日志数据,写入中央存储系统,便于集中分析、统计和处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的、高容错的方案[5]。其架构如图3所示。
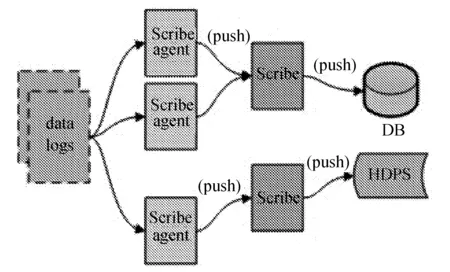
图3 Scribe架构图
Scribe的架构较为简单,主要包括三部分,分别为Scribe Agent、Scribe和存储系统。Scribe架构的最大特点是容错性较好,当存储系统发生故障时,Scribe会将本地磁盘作为存储缓冲区,将数据临时写在本地磁盘上,待存储系统恢复正常后,本地磁盘中的数据会被重新加载到存储系统中[6]。
2 ELK架构介绍
ELK是Elasticsearch、Logstash、Kibana的简称,这是组成ELK的核心套件,但不是全部套件。根据应用场景的不同,搭配不同的套件,ELK可以实现不同的架构。
Elasticsearch提供日志分析中的搜集、分析、存储数据三大功能,是整个架构中的实时全文搜索和分析引擎。它构建于Apache Lucene搜索引擎库之上,是一套可扩展的分布式系统[7]。
Logstash是一个功能强大的工具,用来搜集、分析、过滤日志。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch[8]。
Kibana是用于展示日志信息的图形界面,基于Web搜索、分析和可视化存储在 Elasticsearch指标中的日志数据[9]。
下面将对ELK针对不同应用场景的架构进行分析。
2.1 简单的ELK架构
这是最简单的ELK架构,通常供学习者或者小规模集群使用。它的优点是结构简单、搭建速度快、容易上手,可以快速了解ELK的架构组成,对搭建复杂的ELK集群提供帮助。缺点是处理能力较低,对设备资源占用较大,另外由于结构简单,也存在数据丢失的隐患,通常在业务系统中不推荐此种架构。其架构图如图4所示。

图4 简单的ELK架构
此架构首先由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询、操作。用户亦可以更直观地通过配置Kibana Web Portal方便的对日志查询,并根据数据生成报表。
2.2 带消息队列的ELK架构
此架构在简单ELK架构的基础上引入消息队列机制。其架构如图5所示。
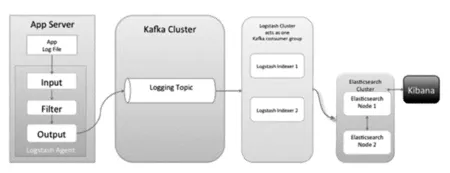
图5 带消息队列的ELK架构
位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。但这种架构也有缺点,位于中心节点的Logstash依旧存在负载过重,占用资源过多的问题。
2.3 带Beats的ELK架构
Beats是一个代理平台,将不同类型的数据发送到elasticsearch。Beats可以直接将数据发送到elasticsearch,也可以通过logstash将数据发送elasticsearch。引入Beats很好地解决了上述两种架构中Logstash占用资源过多的问题。引入Beats平台后的ELK架构如图6所示。
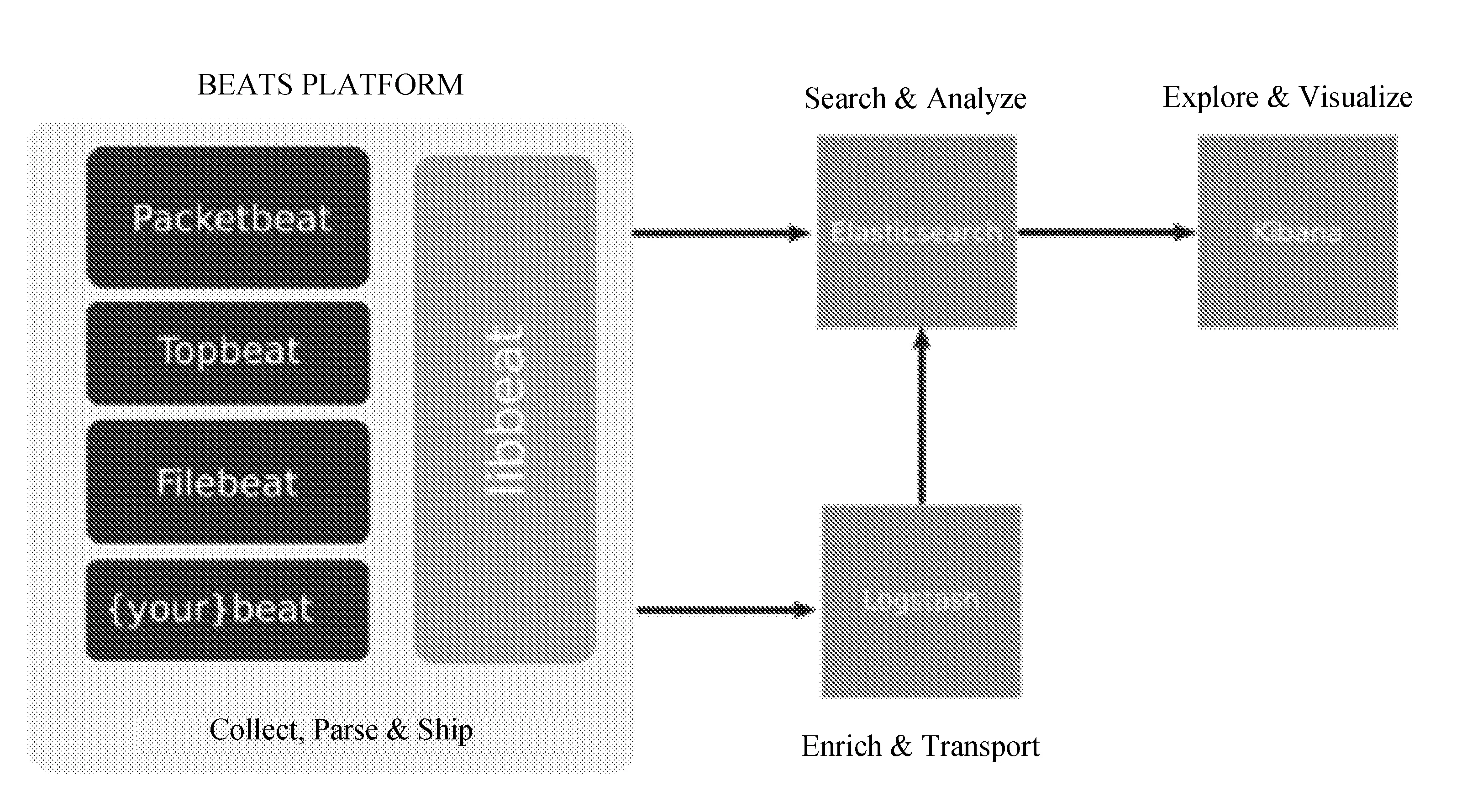
图6 带Beats的ELK架构
Logstash-forwarder可以替代Beats平台,但是Beats拥有更好的扩展性和灵活性。Beats有3个典型的例子:Filebeat、Topbeat、Packetbeat。Filebeat用来收集日志,Topbeat用来收集系统基础设置数据,如CPU、内存、每个进程的统计信息,Packetbeat是一个网络包分析工具,统计收集网络信息。
不管采用上面哪种ELK架构,都包含了其核心组件,即Logstash、Elasticsearch 和Kibana。各系统运维中究竟该采用哪种架构,可根据现实情况和架构优劣而定。
3 ELK大数据运维应用
3.1 ELK模块组件
采用分布式架构的日志系统中,以下几个方面是必不可少的:
1)对各个系统的监控,包括对硬件系统和软件系统的各个组件的监控,如CPU、内存以及系统可用性等;
2)基于分布式平台的日志集中管理和查询;
3)基于日志信息的鼓掌查询;
4)安全及事件日志的记录和管理;
5)提供可视化的报表功能。
ELK组件应用于分布式系统之上,其功能模块如图7所示。
ELK能够提供线上业务的准实时监控,并在业务故障时帮助快速定位原因,跟踪分析Bug,排除故障,通过报表功能可以跟踪业务趋势,实现安全与合规审计,最大深度地挖掘海量日志的数据价值。同时Elasticsearch提供包括rest,java,phthon在内的多种开源API,用户可以根据需求自行扩展开发。

图7 ELK功能模块
3.2 ELK应用举例
在实际应用中,通过ELK组件Hadoop环境下的运行日志,经过筛选、过滤并存储可用信息,从而完成对Hadoop作业运行状态监控。ELK搜集作业运行和完成状态进行监控,实时掌握集群状态,了解作业完成情况,并生成报表,方便监控和查看,ELK应用举例如图8所示。
图8 ELK应用举例
ELK的数据来源可以是多种多样的日志数据,其input plugin组件支持近50种日志类型。
Logstash配置文件有3个主要模块:input()输入或者说收集数据,定义数据来源;filter()对数据进行过滤、分析等操作;output()输出。当数据源搜集到数据后,通过filter()将数据过滤整理成固定的格式,可以是JSON、grep、grok、geoip等类型。然后将整理后的数据输出到数据库或者直接传递给Elasticsearch。当数据存储在Elasticsearch后,用户可以通过它提供的API来进行数据检索,如使用REST API执行curl get命令请求检索指定数据。另外,用户也可以使用Kibana对数据进行可视化浏览。Kibana还提供时间检索功能,即可以对某一时段的数据进行查询和生成报表。
4 结 语
介绍了目前各大分布式环境下的日志系统架构,并对应用广泛、灵活性较强的ELK日志系统架构进行了详细分析,分别阐述了不同应用环境下的ELK架构的优缺点,并给出了ELK日志系统在业务系统中的应用案例。经过实践,ELK日志系统作为一个开源的分布式日志系统,能够为用户提供稳定、可靠的准实时搜索服务,并且能够提供多种报表供用户选择,为用户在故障排查、数据分析时提供帮助。
[1] 丁雪松.共享数据服务统计信息的提取与可视化研究[D].北京:中国地质大学,2012.
[2] 周昕毅.Linux集群运维平台用户权限管理及日志审计系统实现[D].上海:上海交通大学,2012.
[3] 吕佳.基于Elastic Search的分布式日志搜索系统设计[D].上海:复旦大学,2013.
[4] 何海刚.基于Key-Value的海量日志存储系统设计[D].上海:复旦大学,2013.
[5] 叶斌,余阳,王会,等.大数据在MOOC中的应用分析[J].微型机与应用,2015(6):97-98.
[6] Scribe Kafka.开源日志系统比较[EB/OL].(2011-06-10)[2016-05-29].http://dongxicheng.org/search-engine/log-systems/.
[7] Serdar Yegulalp.IBM Bluemix adds graph analytics, DB management[EB/OL].(2016-02-05)[2016-05-29].http://www.tuicool.com/articles/3mEzmeA.
[8] Serdar Yegulalp.6 Splunk alternatives for log analysis[EB/OL].(2016-05-02)[2016-05-29].http://www.tuicool.com/articles/7ZjQRrn.
[9] 周映,韩晓霞.ELK日志分析平台在电子商务系统监控服务中的应用[J].信息技术与标准化,2016(7):67-70.
Architecture analysis and application of massive data log system
LIU Kai
(Modern Educational Information Center, Anhui Agricultural University, Hefei 230036, China)
The architecture and data processing flowchart of some distributed log systems are analyzed first. Taking ELK log system (Elastic search, Logstash and Kibana) as an example, we discuss the features of ELK at different scenes and applications.
log; distribute system; ELK; architecture.
2016-05-29
安徽省教育厅高校自然科学基金项目(KJ2015A326)
刘 锴(1981-),男,汉族,安徽合肥人,安徽农业大学工程师,硕士,主要从事大数据处理研究,E-mail:liukai@ahau.edu.cn.
10.15923/j.cnki.cn22-1382/t.2016.6.13
TP 391
A
1674-1374(2016)06-0581-06
猜你喜欢
华人时刊(2021年13期)2021-11-27
哈尔滨轴承(2020年2期)2020-11-06
心声歌刊(2020年4期)2020-09-07
发明与创新·大科技(2019年12期)2019-03-17
思维与智慧·上半月(2018年9期)2018-09-22
能源(2017年10期)2017-12-20
小学生(看图说画)(2017年6期)2017-11-06
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
中国教育信息化(2015年12期)2015-08-24
