
基于反射内存的多功能通讯板卡研制
2017-01-12 19:31易宇周学安曲海山王哲
物联网技术 2016年11期
易宇++周学安++曲海山++王哲

摘 要:由于虚拟仿真试验系统对实时性和通用性要求高,并且虚拟仿真试验系统中的虚拟模型与实装模型之间需要通过相应的串行接口卡进行传输,因此设计了基于反射内存的多功能通讯板卡。该通讯板卡中应用了反射内存技术,具有串口与反射内存网络进行交互的功能。实验证明,基于反射内存技术的多功能通讯板卡的带宽最高为30 MB/s,误码率低于10~15,时延为深亚微秒级,支持RS 422接口等。
关键词:反射内存;多功能通讯;RS 422;虚拟仿真
中图分类号:TN913.7 文献标识码:A 文章编号:2095-1302(2016)11-00-03
0 引 言
随着装备性能的提高,装备的控制周期已达到1 ms甚至百微秒量级[1]。因此对虚拟仿真系统中通常采用的反射内存网络进行数据传输。虚拟模型之间通过网络传递数据,虚拟模型与实装模型之间通过相应的串行接口卡进行通讯,例如RS 422、1553B通讯板卡。因此若能直接实现反射内存网中数据与串行接口之间的直接数据传输[2],将极大地提高通讯卡的通用性和仿真系统的实时性[3]。
当今市面上常见的反射内存网络产品无法单独满足虚拟仿真系统对网络功能的需求,所以基于反射内存的多功能通讯模块的研制对于半实物仿真系统有着十分重要的意义。
1 多功能通讯模块原理及工作模式
反射内存网络示意图如图1所示。多功能通讯板卡组建的反射内存网络通过光纤连接而成。网上的每台计算机通过CPCI插槽插入一块多功能通讯板卡形成网络上的一个节点。
网络上每个节点的局部内存都映射到一个虚拟的全局内存,构成分布式共享存储器。用户对本地节点内存的读写相当于对全局内存的读写。对于本地节点内存的读写可以由宿主机或带有RS 422接口的设备完成。多功能通讯板卡上集成了4路RS 422接口,使带有RS 422的设备能直接访问反射内存网。
2 总体方案设计
图2所示为多功能通讯板卡总体框图。该板卡总体上由宿主机交互模块、DDR2模块、RS 422模块、光纤接口模块四部分组成,各个模块均挂载在Avalon总线上,借助该总线进行数据交互。Avalon交换式总线定义的内联线策略使得任何一个Avalon总线上的主外设都可以与任何一个从外设沟通。
2.1 宿主机交互模块设计
宿主机交互模块负责处理板卡和宿主机的信息交互,实现数据解析、数据组帧和打包、与Avalon总线交互等功能。该模块由CPCI总线的接口单元、数据解析单元和数据组帧单元等构成。宿主机交互模块框图如图3所示。
PLX9054的工作模式采用C模式,传输方式选择DMA模式。
数据解析单元通过PCI总线的地址位来区分上位机的数据种类[4]。上位机发送的数据种类有经由RS 422接口的数据、广播到反射内存网络的数据、读写本地内存的数据[5]。为了更好地管理数据,将反射内存网络中的内存划分为两大区域:地址0x00000000~0x000FFFF是RS 422数据,地址0x0010000~0x8000000是通用内存数据。
数据组帧加包是为了解决从单一数据源发送数据到不同出口而产生的数据带宽不同、协议不匹配等问题[6]。为了方便数据交互,统一各路数据结构,根据目前反射内存网络没有形成协议标准的现状,设计其实现机制和数据结构如下所示:
(1)发送到RS 422接口的数据由命令标志位和数据位构成。其中命令标志位用于区分数据帧和命令帧。命令帧包括波特率配置和字长配置。
(2)发送到反射内存网络的数据格式由帧头标志、节点号、中断标志、协议号标志、包长度组成。其中节点号表示该数据包的源节点号,协议号标志表示该数据包的数据源采用的协议。帧头标志位用于区分帧头和地址帧、数据帧、校验帧。
(3)为了提高系统带宽,宿主机交互模块集成了四个Avalon总线主端口,由于每个总线主机均有自己的专用互联,总线主机只需抢占共享从机,而非总线本身,因此不会造成总线拥塞。Avalon接口性能很高,可每个时钟传输1次,所以对上下行数据的传输速率的影响可忽略不计。
2.2 光纤接口模块设计
图4所示为光纤接口模块。该模块由光电收发器、编解码控制、数据仲裁和数据解析等功能单元组成。其中,光传输模块采用集成光电转换方案,其支持的最高串行数据传输率为1.062 5 Gb/s。
各功能单元之间为保持数据的完整性,设计了多个FIFO来缓存接收和发送数据。解决上下接口速率不匹配、跨时钟域的问题。
在高速串行收发器中,内置有8 B/10 B解码器可以检查出单比特错误,同时还内置有CRC校验器,能够有效发现错误并纠正单比特错误。利用这两种方案能够将错误有效反馈给上层进行处理。
2.3 RS 422模块设计
图5所示为RS 422模块。该模块主要由UART模块、控制模块和RS 422接口电路组成。
UART在Avalon总线体系里是一个常用的字符型外围设备[7],为Altera FPGA上的嵌入式系统和外部设备提供了串行字符流通信方式。主控制模块的主要功能单元为UART控制、地址匹配和数据打包等。同时控制模块内嵌3个Avalon主端口和1个Avalon从端口,通过Avalon总线与其他模块进行数据交互。
3 主要功能及性能指标测试
测试时搭建由虚拟机和实物设备构成的半实物仿真系统验证基于反射内存的多功能板卡的各项功能及性能。
3.1 反射内存网络功能测试
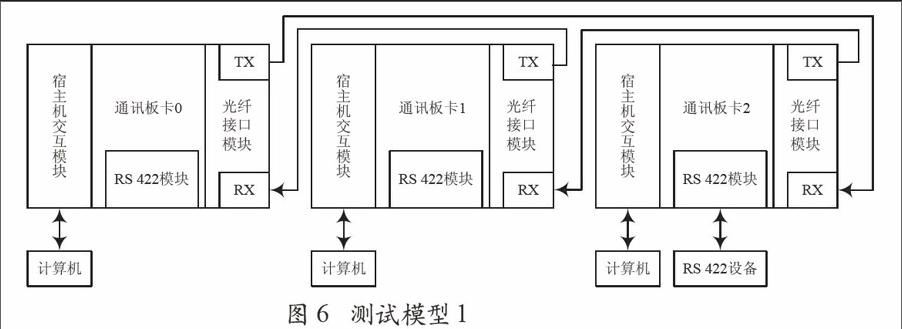
测试网络采用由三个节点、光纤互联组成的环状链路,其中一个网络节点接入RS 422设备,测试是否能构成共享内存网络。测试模型如图6所示。
在广播通讯测试中,节点0计算机作为数据源发送数据包,环路节点1、2收到数据包后执行存储操作,同时按序转发数据包。当数据包回到节点0时,该节点删除数据包,不再转发,最后将3个节点的内存数据读取比较。本次测试用大小为12字节的数据包进行了长时间连续测试。实际测试结果表明传输中的误码率低于10-15。
3.2 RS 422功能测试
测试2模型和测试1一致。节点3上的RS 422设备作为数据源广播大小为12字节的数据包,最后比较各节点内存数据。每个通道按照三种波特率9 600 b/s、115.2 Kb/s、1 Mb/s和字长8位、9位共6种组合方式分别测试,设备收发的数据和各节点内存区数据完全一致。
3.3 网络传输速率测试
测试3沿用测试1的测试模型。宿主机读写采用DMA方式,测试时,节点0宿主机发起数据写传输,发起的同时开启RTX系统提供的0.1 ms时钟,当数据通过环形网络更新完毕时则停止计时,得到数据写速率。每次发送100个数据包,发送500次,有效数据总量为200 000 MB。试验数据如表1所列。通过宿主机读内存数据,每次读100个数据包,读500次,有效数为200 000 MB,得到数据读速率。数据读测试如表2所列。
在数据量较小时,传输速率不高,因为大部分时间开销都在中断的传输和逻辑判断中。当发送数据变大时,传输速率较快,并趋于稳定。
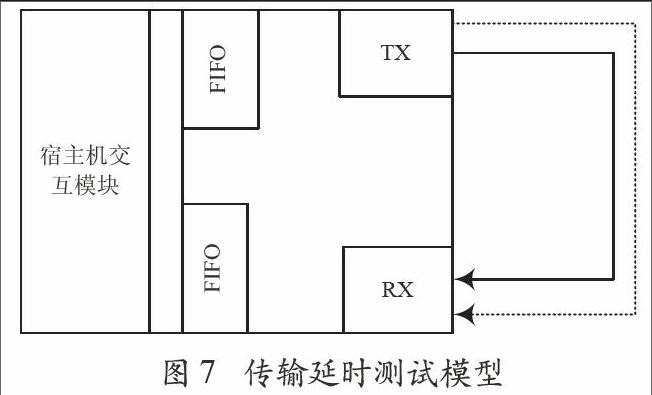
3.4 传输延时测试
传输延时包括节点间延时和节点内延时,测试模型如图7所示。相邻节点之间完成数据发送接收过程的延时测试,需要依次经过发送节点发送单元、光电收发器、光纤、光电收发器、接收节点接收单元,其中光纤长度为10 m。通过100次测试单板自收发,可测得节点与节点间的时延平均为244.4 ns。节点内部处理相邻节点发送的数据并转发时会造成延时。完成以上一次收发需要经过两次节点间时延和一次节点内时延。经过100次测试,得出节点内平均时延为263.2 ns。
4 结 语
通过一系列实验测试证明,基于反射内存的多功能通讯板卡设计合理,满足高速(带宽最高为30 MB/s)、可靠(误码率低于10-15)、可预测(时延是深亚微秒级)、多功能(支持多模式的RS 422)等要求。目前,该板卡已应用在虚拟仿真平台。需要指出的是,该板卡上还集成了RS 232、1533B、CAN等通讯模块,改动FPGA程序即可扩展板卡的通讯能力。
参考文献
[1]刘峰,王鸿翔,张帅.一种基于双中断的反射内存网通信方法研究[J].航空科学技术,2014 (12):54-58.
[2]李锋.基于光纤反射内存网的实时数据传输研究[D].成都:中国科学院研究生院(光电技术研究所),2014.
[3]周强,张秀磊,骆冬,等.基于CPCI总线的反射内存网络接口卡研制[J].计算机测量与控制,2014,22(9):2934-2936.
[4]李明星,魏长安,姜守达.一种基于PCI总线的反射内存卡设计[J].自动化技术与应用,2010,29(10):84-87.
[5]金暑钧,赵占伟.通用试验体系支撑平台下的反射内存网通信组件开发[J].自动化技术与应用,2012,31(5):38-41.
[6]王玉龙,徐志跃,刘亚斌.基于cPCI总线的一种反射内存卡的研究与设计[J].电子设计工程,2015,23(5):164-167.
[7]纪红.基于反射内存网络的实时网络关键技术的研究[D].哈尔滨:哈尔滨工程大学,2013.
猜你喜欢
测控技术(2018年3期)2018-11-25
测控技术(2018年12期)2018-11-25
网络安全和信息化(2018年4期)2018-11-09
火控雷达技术(2016年3期)2016-02-06
铁路通信信号工程技术(2014年5期)2014-02-28
深圳信息职业技术学院学报(2013年3期)2013-08-22
计算机与网络(2013年12期)2013-04-18
电子设计工程(2011年24期)2011-06-09
