
G.729.1算法的改进与DSP全汇编优化设计
2017-01-03 01:29:45王春柳陈德宏申星海
重庆邮电大学学报(自然科学版) 2016年6期
王春柳,陈德宏,申星海
(1.河海大学 文天学院 电气信息工程系,安徽 马鞍山 243031;2.安徽工业大学 电气与信息工程学院,安徽 马鞍山 243002)

G.729.1算法的改进与DSP全汇编优化设计
王春柳1,陈德宏2,申星海2
(1.河海大学 文天学院 电气信息工程系,安徽 马鞍山 243031;2.安徽工业大学 电气与信息工程学院,安徽 马鞍山 243002)
在G.729.1宽带语音编码算法中,时域混叠编码器的谱包络编码根据帧内子带的相关性,采用差分霍夫曼编码来减少编码的比特分配。针对相邻帧对应子带的谱包络存在相关性,给出了在原有谱包络编码模式的基础上,增加一种帧间对应子带差分霍夫曼编码的模式来进一步减少谱包络的编码比特数,从而提高合成语音的质量。由于G.729.1可以根据信道的特征随时调整编码速率以取得更好的宽带语音质量,这使得该编码算法具有很高的复杂度。为了能在数字信号处理器 (digital signal processor, DSP)上实时实现G.729.1,结合TMS320VC5505数字信号处理器对G.729.1算法采用全汇编实现,并对汇编后的G.729.1代码做了进一步的汇编优化,优化后的G.729.1算法在保证了高质量语音输出的同时,提高了编码效率,实现了对语音信号的实时处理。
宽带语音;G.729.1; 谱包络编码;差分霍夫曼编码;汇编优化
0 引 言
G.729.1作为ITU-T提出的嵌入式宽带语音编码标准能够根据各个终端设备的能力及传输链路的传输能力,灵活地对编码比特流进行截断,使得编码器具有可分级性。它被广泛应用于分组语音传输、高质量的视频或音频会议、网络拥塞控制及各种多媒体通信系统中[1-3]。它提供了在8~32 kbit/s之间的12种可选速率,并且用户可以根据信道的实际状况对码流速率作相应调整,这种根据网络状况灵活调整比特率的方法使G.729.1具有较好的适应能力,避免了网络拥塞,提高了整体服务质量。

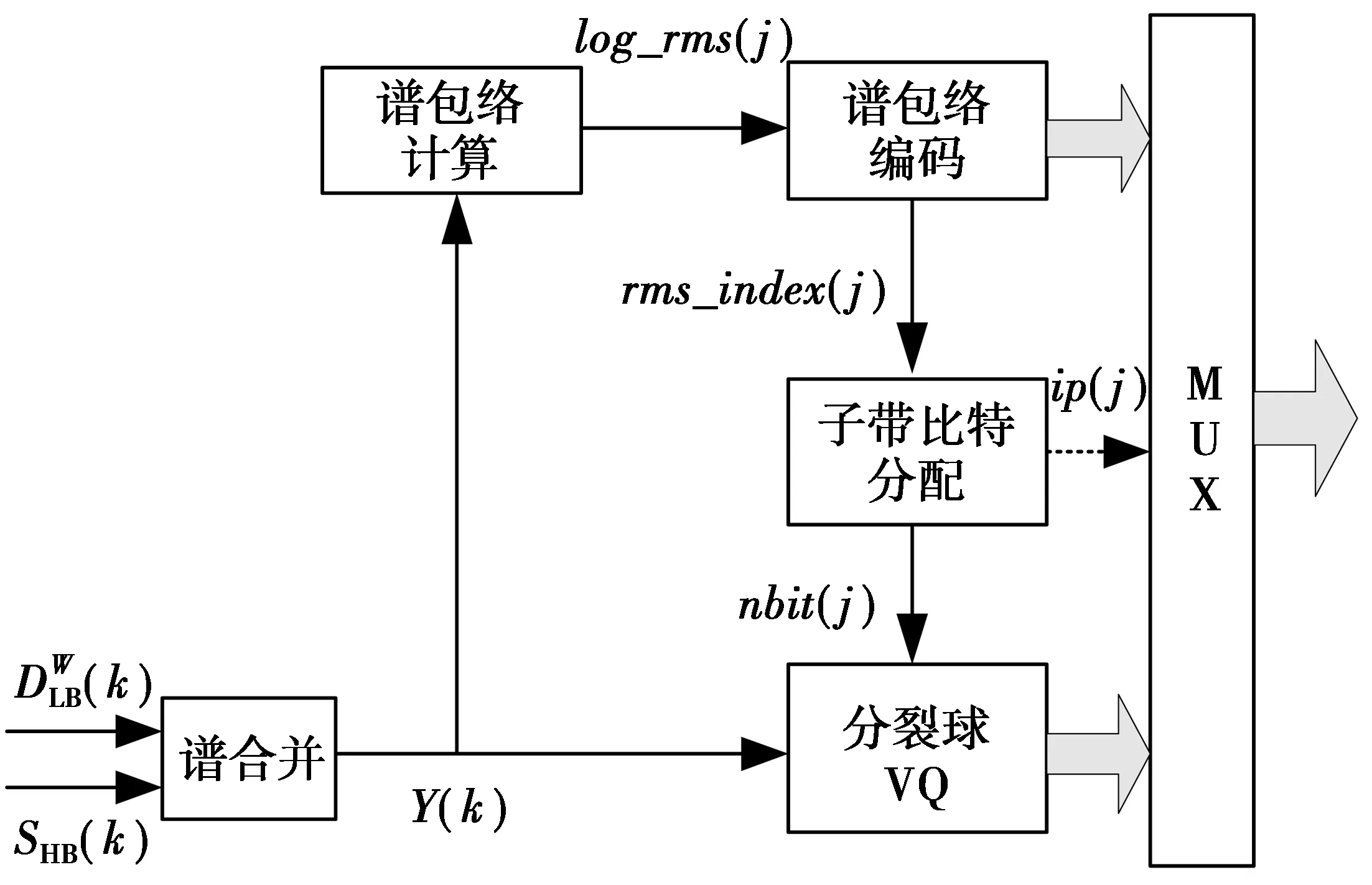
图1 TDAC编码原理框图Fig.1 Block diagram of the TDAC encoder
由图1可以看出,TDAC编码器对低频端重建加权差值谱信号和高频谱信号进行谱合并,组成了全频带的谱信号。对全频带谱信号先进行粗编码,即对变换后的谱系数(320)组成18个子带,每个子带先进行谱包络编码,然后再细量化,即对每个子带的各个谱系数再进行球形矢量量化。由于TDAC编码器分配的总比特数是一定的,因此,子带谱包络编码分配的比特数越少,对子带各个谱系数分配的比特数就越多,细节描述就更准确,得到的语音质量就越高。G.729.1中的谱包络编码利用帧内18个子带的相关性,对一帧内的相邻子带进行差分去相关,而帧内相邻子带差分之后的谱包络能量往往集中在较小的动态范围内,即采用不等长霍夫曼编码,可以进一步降低编码比特数。
本文根据语音帧与帧对应子带之间的谱包络具有很大的相关性,可以利用帧与帧对应子带的相关性,进行差分去相关处理,对帧间对应子带差分后的信号采用霍夫曼编码也可以减少谱包络的比特分配,然而对不同种类的语音信号,对帧内相邻子带采用差分霍夫曼编码模式所分配的比特数和对语音的相邻帧对应子带采用差分霍夫曼编码模式分配的比特数各有优劣,因此,为了使用分配比特数较少的模式,可以同时保留这2种模式,对每一帧的谱包络编码都计算这2种模式的编码比特数,采用1 bit来选择编码比特数较小的那种模式,有利于解码端恢复谱包络的编码模式。
由于G.729.1可以根据信道的特征随时调整编码速率以取得更好的宽带语音质量,这使得该编码算法具有较高的复杂度。在工程应用中,为了达到实时处理的目的,文献[6]采用DM642对G.729.1进行简单的算法优化和C语言级别上的优化,但该优化没有充分利用DSP C6000系列的结构特点,优化效率不高,且C6000系列价格昂贵,因此,采用该系列DSP对G.729.1进行处理,性价比不高。文献[7]采用ARM926EJ为核心的S3C2450处理器对G.729.1进行C语言函数结构和部分汇编优化相结合的优化方式,但这种优化的可移植性较差,不利于工程应用中的直接封装使用。本文利用C55x系列DSP的低功耗,对数字信号处理快的特点,在TMS320VC5505 DSP芯片上给出了一种便于编写、调试的G.729.1全汇编开发方案。通过对G.729.1编解码算法的汇编编写、调试,并进一步对G.729.1汇编代码做汇编优化,如并行指令、循环体优化、流水线优化等。汇编优化后的G.729.1代码可实时处理,并且在工程应用中可直接封装使用并为后续G.729.1算法的优化研究奠定了基础。
1 G.729.1谱包络编码的改进
1.1 G.729.1谱包络编码
(1)

得到18个谱包络后,对每个谱包络参数进行5bit均匀标量量化,其限定量化结果为-11~+20的32个可能的数值,为了防止谱包络log_rms(j)的值过多地超出限定范围,对其进行了溢出处理,进而得到索引rms_index(j)表示为
rms_index(j)=round(1/2log_rms(j)),
j=0,…,17
(2)
(2)式中;log_rms(j)为第j个谱包络;rms_index(j)为第j个量化的谱包络。
量化后的全频带包络分为2个子矢量:第1个子矢量是rms_index(0)~rms_index(9),该10维的子矢量为低频带包络;第2个矢量是rms_index(10)~rms_index(17),该8维的子矢量为高频带包络。这2个子矢量的编码在差分霍夫曼编码(模式0)和直接自然二进制编码(模式1)之间进行自适应转换。这是由于差分霍夫曼编码可使平均编码比特数变小,而直接自然二进制编码用于限制最坏情况的比特数。
该差分霍夫曼编码在帧内的谱包络之间进行编码,一般包括以下4个步骤。
步骤1对取值为[-11,20]的第1个索引rms_index(0)进行5 bit的自然二进制编码。
步骤2计算相邻子带的差分索引和饱和标识satur。
diff_index(j)=rms_index(j)-
rms_index(j-1),j=1,…,9
(3)

(4)
(3)-(4)式中:rms_index(j)为第j个量化的谱包络;diff_index(j)为2个相邻谱包络的差值索引;satur为饱和标志位。
步骤3如果satur=0,对于j=1,...,9的低频差分索引diff_index(j)采用查表法进行差分霍夫曼编码,其霍夫曼表参见文献[1]。
步骤4如果satur=1或者差分霍夫曼编码的比特数大于45,则对rms_index(1),…,rms_index(9)进行步骤1所述的自然二进制编码,并令satur=1。
1.2 谱包络编码的改进
G.729.1中的谱包络编码利用帧内18个子带的相关性,对一帧内的相邻子带进行差分去相关,而帧内相邻子带差分之后的谱包络能量往往集中在较小的动态范围内,从而降低编码比特数。对常出现的小信号用短码表示,不常出现的大信号用长码表示,即采用不等长霍夫曼编码,可以进一步降低编码比特数。
由于谱包络编码分配的比特数与MDCT系数分配比特数的总和是固定的,共351 bit,而MDCT系数精度越高对语音频谱细节的描述就越准确,得到的语音质量就越好。如果希望MDCT系数的比特分配越多,这就意味着谱包络编码分配的比特数越少越好,那么如何进一步减少谱包络编码的比特数呢?一般情况下,语音帧之间的谱包络存在很大的相关性,因此,可采用对帧间对应子带进行差分去相关,之后对去除相关性的对应子带信号采用霍夫曼编码进一步减少谱包络的比特分配。文献[8]表明,对不同种类的语音信号,G.729.1所采用的帧内相邻子带进行差分霍夫曼编码模式所分配的比特数和本文所提的语音的相邻帧对应子带采用差分霍夫曼编码模式分配的比特数各有优劣,因此,为了确定哪种模式分配的比特数较少,本文采用同时保留这2种模式的方法,对每帧的谱包络编码都计算这2种模式的编码比特数,然后进行比较,用1 bit来选择编码比特数较小的那种模式,从而可使谱包络编码保持较少的分配比特数。
谱包络编码的具体步骤如下。
步骤1利用(1)式和(2)式计算连续相邻帧的18个子带的谱包络值,并计算连续帧的对应子带谱包络的差分为
diff(t,j)=rms_index(t,j)-rms_index(t-1,j)
(5)
(5)式中:rms_index(t,j)是第t帧第j个子带的量化谱包络;diff(t,j)为相邻帧对应子带谱包络的差值索引。
步骤2对每帧得到各个谱包络的差值进行霍夫曼编码,并计算分配的比特数。
步骤3比较帧内相邻子带谱包络编码比特分配和相邻帧对应子带谱包络编码比特分配,采用1 bit进行模式选择,哪种比特数少,则采用哪种模式,并输出模式选择标志位。具体谱包络编码流程如图2所示。
本文采用ITU-T提供的测试矢量tstseq1.in作为输入语音,对G.729.1语音压缩编码进行验证,统计了1 000帧的语音信号。结果表明,采用改进的谱包络编码使得该部分的编码比特数减5 bit左右。由于TDAC编码器分配的总比特数是一定的,改进的子带谱包络编码分配的比特数减少了5 bit,则表明对子带各个谱系数分配的比特数就多了5 bit,细节描述就更准确。通过采用ITU-T推出的WB_PESQ软件系统对1 000帧的测试矢量tstseq1.in所合成语音的质量进行评估[9],实验表明,该谱包络方法比原来的谱包络编码方法所得到的感知语音质量评价(perceptual evaluation of speech quality, PESQ)得分由原来的4.05提高到4.11,合成语音质量所提高。

图2 改进的谱包络编码流程图Fig.2 Flow of improved spectral envelope coding
由于该方法在原有编码的基础上增加了对相邻帧对应子带的差分霍夫曼编码模式,因此,TDAC编码器算法的复杂度有所增加,执行一帧的运算量由2 714 111 clock提高到2 759 413 clock,算法复杂度提高了1.67%。由于G.729.1算法本身的运算量较为庞大,而TDAC编码器算法的复杂度只占G.729.1算法中的16.8%,因此,该部分算法复杂度对G.729.1整体算法的复杂度并没有太大影响。但G.729.1的庞大的运算量影响其在工程上的实时实现,本文对G.729.1采用全汇编优化设计,解决了实时处理的问题。
2 G.729.1算法全汇编设计与优化
TMS320VC5505是TI公司生产的16位定点DSP,在数字音频设备、软件无线电、便携式医疗设备等领域得到广泛应用[10]。如果直接将C语言编写的G.729.1编解码算法加载到C55x DSP开发平台进行编译,那么执行一个语音超帧(20 ms)需要47 642 993个时钟周期。对于TMS320VC5505的主频为100 MHz,则执行一个语音超帧需要476.4 ms,无法达到语音实时处理的目的。因此,为了能在C55x上实时实现G.729.1算法,本文对G.729.1进行全汇编编写和优化。而一个合理的开发设计方案对程序的编写和最后的调试有着至关重要的作用。本课题利用CCS3.3软件开发平台,开发一款能够在DSP上实时处理的G.729.1宽带语音编码代码,其总体开发流程如图3所示。

图3 基于DSP的G.729.1汇编开发总方案流程图Fig.3 Flow of G.729.1 assembly development based on DSP
图3描述了G.729.1总体开发方案流程。该方案首先把C代码移植到CCS环境中,并解决移植过程出现的接口不匹配问题;然后对移植成功的C代码进行整体架构的分析,制定整个代码的开发方案,同时对各个模块C代码进行参数精度和算法描述的解读,制定各个模块的汇编方案,汇编编写并调试各模块代码,最后为了进一步提高汇编优化效率,从各方面对汇编代码进行优化。
2.1 代码的移植
由于G.729.1的源C文件是在Visual C++平台上编写的,由于CCS3.3对标准C不是百分之百完全兼容的,因此,需要进行一定的修改才能将G.729.1算法移植到CCS3.3中。通过修改并在CCS3.3上编译通过,移植成功后才可以进行下一步的汇编编写和优化工作。
标准C代码在CCS3.3平台移植过程中存在的3个不足之处。
1)标准C代码的main函数是带参数的,这些参数可自动判断输入文件为什么类型,在CCS3.3中无法执行,因而需要将其改为不带参数的main函数,人工输入文件类型。
2)标准C代码中的数据导入方式是通过fread语句从数据文件中读入数据,在CCS3.3中,fread读一个16位整数时,只能读出16位整数的一个字节,这种方式读入的数据格式不对,解决办法有:①如果数据文件是.data格式,直接装载到数据区;②对于其他格式的数据文件,可以通过tool工具栏中的Memory Save/Load Utility工具将数据读入指定数据区;③可以通过fread将一个16位数据读2次,并需要编程将2个读出的8位合并成一个完整的16位数据。
3)源C程序移植到CCS3.3上,不仅要加入源文件,而且要与C运行库进行连接。由于C5505 有小模式(small memory model)和大模式(large memory model)之分,模式的选择决定C运行库的选择,在大存储器模式下,数据指针是23位,并在存储器中占用2个字,大存储器模式支持数据的不严格存放,代码段和数据段的长度和位置不会受到一定数据页的限制,本文中在编译器中设置-ml,选择大模式。大模式对应的C运行库为rts55x.1ib。
将G.729.1源C文件载入TI 公司提供的集成开发环境C55xx Rev3.0 CPU Cycle Accurate Simulator。输入语音信号,经编解码,将解码得到的信号通过集成开发环境CCS3.3中Tools菜单条中的Memory Save/Load Utility来保存。其中,输入的语音信号为ITU-T提供的测试语音test1_16k.in,将移植后的G.729.1编解码输出的.bit文件和.out 文件与之提供的测试文件逐比特进行对比,完全一致,并通过Cool Edit Pro v2.0 进行试听,直到和原始测试文件听不出任何不同,说明移植成功。
2.2 全汇编的编写设计与调试
由于G.729.1程序规模较大,为了实现其全汇编编写,需要制定一个合理的全汇编实现方案。本文结合C55x汇编语言和算法代码的特点,在保证标准C代码的结构架构不变的情况下,对C代码结构框架下的各个模块逐个进行汇编语言编写,保证每个阶段汇编替代的正确性,完成整个算法的全汇编实现。为了使程序结构清晰,利于修改和调试,这种将复杂的算法分解为各个单独的程序模块分别实现,可使编程变得相对容易,但也要求对C程序代码非常熟悉,并对汇编指令了解透彻。这种思路虽然花费的时间较长,但易于在调试中发现和改正错误。
由于G.729.1包含的模块众多,而各个模块汇编代码编写的顺序并不是随意的,而是根据函数之间的关系以及它们的复杂度大小制定的,编写顺序如下。
1)对于同一分支的函数,因为子函数的编写和调试比较容易,所以,先替换子函数,即内层函数,在保证子函数的正确性后,再替换父函数,即为外层函数,采用由内而外的替换顺序,从而降低代码开发和调试难度。
2)由于执行一次G.729.1源代码编的时间较长,对于同一层次的函数,由它们的复杂度决定替换顺序,采用优先替代复杂函数,这样可以缩短编译和连接的时间,从而确定复杂的函数先替换,简单的函数后替换,从时间上缩短后面函数调试时间。
按照这2个原则逐一替换各个子函数,从而完成父函数的全汇编编写。
为了验证各个模块汇编代码的正确性,本文使用ITU-T 提供的G.729.1相应测试矢量test1_16k.in作为输入信号,由于G.729.1包括12种编码速率,即8~32 kbit/s,为了加快调试的速度,在程序中不能直接设置编码速率为最高速率(32 kbit/s)。如果先编写8 kbit/s所对应的程序模块,可设置编码速率为8 kbit/s,这样12~32 kbit/s所对应的程序将不会执行,增加了编译的速度,且便于调试。当调试某一模块,可在该模块的结尾处设置断点,一帧一帧调试,大概执行10帧,如果该模块的汇编结果与C语言结果相同 ,可认为该模块的汇编程序正确。
2.3 汇编优化
汇编代码执行效率虽然很高,为了进一步提高编写效率,充分利用各种DSP的硬件资源,本文在汇编代码的基础上进一步优化以提高编码效率。
2.3.1 实现高效循环
1)单循环指令RPT(CSR/k8/k16)。如果循环体中只有一条指令或一个并行指令对,则可以使用RPT指令实现。当RPT CSR嵌套循环中使用时,CSR只需要在循环体之外初始化一次,单循环指令的效率很高,是实现循环的首选方式。
2)局部块循环指令RPTBLOCAL{}。当循环体的代码长度不大于56 Byte的时候,可以使用RPTBLOCAL指令对指令缓存队列中的循环体代码块执行循环。局部块循环避免了从内存中重复读取循环体代码,从而减少了程序空间访问的流水线冲突,如果循环代码在外部RAM中,局部块循环不会重复产生额外的等待,从整体上降低了功耗。在实现块循环时,RPTBLOCAL指令是第1选择。
3)块循环指令RPTB{}。由于块循环指令要重复地访问内存代码,执行效率不高,因此,在局部块循环指令不能使用的情况下才会用块循环指令实现循环。
4)跳转指令。以上3种方法在实现循环时无需额外开销,跳转指令则至少需要5个指令的循环开销。这种方法一般在多级(>2)嵌套循环里面使用。
为实现高效的循环,应尽量使用单循环指令和局部块循环指令,避免使用跳转指令来实现循环。如果块循环的代码长度大于56 Byte,可以采用下面2种措施来实现局部块循环:①将循环体拆分为2个长度较小的代码块;②将原循环中长度较大的指令用其他长度较小指令替代,最常见的就是去除立即数指令。碰到2级嵌套循环,应将内层循环的块循环计数器BRC1在外层循环体之前进行初始化,这样可以避免重复初始化带来的额外指令。
2.3.2 宏优化
对于长的或复杂的代码,将重复调用的程序块定义为宏,此外,函数调用会有额外开销,特别是多次调用的函数,将其定义为宏后可以节省调用花费的开销。全汇编代码中定义为宏的函数有G729EV_G729_Copy,Inv_sqrt和Lag_max。下面给出宏Lag_max的部分定义程序,其他函数的宏可以用类似方法定义。
Lag_max .macro scal_sig,L_FRAME,PIT_MAX,
PIT_MIN,max,p_max
.global _tabsqr
……
.endm
2.3.3 DSP汇编指令的巧用
C55x汇编指令有150多种,编写的汇编代码中使用的某些指令并不一定最合适,比如条件跳转指令BCC和指令XCC都可以控制是否执行下条语句,但是BCC需要5到6个执行周期,XCC只需要1个执行周期,因此,在选择指令的时候应尽量选用执行周期较少的。如对某一个数据进行归一化时,并求出归一化的指数,可用并行指令MANT::NEXP,一个执行周期就可完成。如除法运算中的SUBC指令,因为除法运算没有相应的指令,所以可以转换为减法运算,该指令可以求商和余数。
2.3.4 并行指令优化
DSP芯片可以在1个时钟周期下完成多个操作,也就是说可以将多条指令合并为1条,提高程序的运行效率。C55x中的并行分为单指令内建并行和用户自定义并行两类。内建并行就是一些特殊指令,用得最多的就是并行乘累加指令MAC::MAC,它是基于C55x的双乘加(multiply and accumulate,MAC)硬件结构。双MAC并行指令为处理包含大量乘累加操作的G.729.1算法提供了便利。用户自定义并行是指用户通过对指令进行分析,调整编码的顺序,将符合条件的2条相邻指令并行操作[11]。TMS320C5505包含多组总线和功能单元,丰富的硬件资源使其支持高度的并行性,因而并行指令优化是全汇编代码的主要指令优化方法之一。
下面是一些可以采用用户自定义并行指令来优化汇编代码的情况。
1)将所有装载和存储指令并行放置。例如
MOV *AR2,AC1 /*装载AC1*/
‖MOV BRC0,*AR3 /*存储BRC0*/
2)条件执行指令与加载指令并行放置。例如
XCC first,T0==#0
‖MOV #0,AR0
3)可将A单元的ALU与D单元的ALU,MAC和移位操作并行处理。例如
ADD T0,AR1 /*在A单元修改AR1*/
‖MOV uns(rnd(HI(saturate(AC1<<#1)))),*AR2 /*在D单元执行累加器移位饱和和存储操作*/
不同的汇编程序并行优化的效果不同,从全汇编代码的优化结果来看,通常经过自定义并行优化,代码执行时间可以减少20%左右。
2.3.5 流水线延迟的优化
C55x有2条受保护的指令流水线:①取指流水线,用于将指令包放入指令缓存队;②执行流水线,用于完成指令译码、数据访问和运算,共有7个阶段。在流水线中是多条指令同时执行,不同的指令会在流水线的不同阶段修改内存、I/O空间和寄存器的值,为了防止数据访问时会对同一空间进行读/写,C55x的流水线保护单元会插入额外的周期来预防这种错误。如果一条指令要访问前面未执行完的指令所访问的空间,这条指令就会在流水线中中断,直至前面的指令执行完,这条指令再执行。为了使延迟最小,利用分析工具Pipeline Stall Analyzer,通过单步执行程序找出产生流水线延迟的指令并分析在哪个阶段产生流水线延迟并通过调整顺序来解决。例如汇编程序中
MOV #5,AR1
MOV *AR1+,AC0
由于这2条语句有4个周期的延迟,可以把第1条汇编语句改为AMOV #5,AR1,还可以与其他语句进行调整来减小延迟。
2.3.6 多使用双字访问指令
在很多信号处理中,待处理的数据都是连续存放在内存中的,使用双字访问可以一次读取多个数据,减少内存访问指令数。
2.3.7 尽量减少进行函数调用
因为进行函数调用的时候,要将程序计数器(programe counter,PC)指针和一些寄存器压栈,函数调用完后,程序结束还要出栈,这都是一些不必要的操作。所以对于一些小的函数, 就不调用而是直接写入主函数里, 这样就可以减少那些压栈出栈的操作,提高速度。
2.3.8 去除一些冗余的赋值
编译器产生的代码有很多赋值,经常将一个值赋给寄存器,再赋给变量,这样就产生了冗余。
3 结果分析
通过对G.729.1进行汇编编写及优化,并利用CCS3.3提供的性能分析工具(profiler)对优化前后的代码进行分析, 表1是G.729.1编码器源C代码与汇编优化后的指标对比,其中,表1中运算量的单位为CPU的时钟周期,而优化效率则是源C代码的运算量减去汇编优化后的运算量与源C代码的运算量的比值。

表1 G.729.1编码器汇编优化前后的指标对比
由表1可以看出,函数的优化效率至少为90%以上,汇编优化后的函数执行效率得到大大提高。通过测试可知,G.729.1全汇编代码的运算量只有1 683 881 clock,而主频为100 MHz的TMS320VC5505芯片在20 ms内允许执行的代码量为2 000 000 clock,小于G.729.1编解码的代码量,保证了系统的实时性。
为了进一步评价语音编解码系统还原出的语音质量,本文采用ITU-T推出的WB_PESQ软件对系统合成语音的质量进行评估[9]。实验所用语音选自ITU-T提供的4组测试语音矢量,由于测试语音的语种、时长、是否带噪等因素会影响语音质量的测试结果,因此,测试语音应该足够丰富,如表2所示。这些语音的采样频率都为16 kHz,分别对C语言中的32 kbit/s的合成语音和汇编语言中的32 kbit/s的合成语音做对比,如表3所示。
从表3的评测结果可以看出,汇编语音中的合成语音的质量和C语言中的合成语音质量基本相同,且当速率为32 kbit/s时,合成的语音质量较高,因此,全汇编优化后的G.729.1编解码器完全可以满足实际话音通信系统的要求。

表2 测试语音矢量

表3 测试语音WB_PESQ得分
为了进一步验证G.729.1编解码的正确性,本文以测试矢量tst_16k.in作为输入语音,经G.729.1全汇编编码和解码后分别得到8,12和32 kbit/s的合成语音tst_16k_asm.o8,tst_16k_asm.o14和tst_16k_asm.o32。以32 kbit/s的合成语音为例,将原始语音文件与合成语音文件分别导入音频制作软件Cool Edit Pro,并对比它们的波形图,如图4所示。

图4 原始语音和32 kbit/s合成语音的波形图Fig.4 Original speech waveform and synthetic speech waveform of 32 kbit/s
将原始语音和32 kbit/s的合成语音的波形进行对比,由图4可见,32 kbit/s的合成语音波形图与原始输入语音的基本一致,进一步验证了全汇编结果的正确性。
4 结束语
针对G.729.1中的TDAC编码器的谱包络编码方法,本文在原有方法的基础上增加一种对相邻帧对应子带采用差分霍夫曼的编码方法,提高了语音的质量。同时,针对G.729.1编解码算法的高复杂度,通过充分利用C55x DSP结构特点和汇编语言的特点,对其进行全汇编设计及优化,使得G.729.1编解码器在TMS320VC5505得到实时实现,提高系统运行的效率。并且该方法在工程应用中可直接封装使用,为后续G.729.1算法的优化研究奠定了基础。
[1] ITU-T Recommendation. G.729-based Embedded Variable bit-rate coder,An 8-32kbit/s scalable wideband coder bitstream interoperable with G.729 (Amendment 7: New Anne F with voice activity detector using ITU-T G.720.1 Annex A)[S].Geneva,Switzerland:Telecommunication Standardization Sector of ITU, 2012.
[2] RABOT S, KOVESI B, TRILLING R, et al. ITU-T G.729.1: An8-32kbit/s scalable coder interoperable with G.729 for wideband telephony and voice over IP[C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Honolulu, Hawaii, USA: IEEE,2007:529-532.
[3] GEISER B,JAX P, VARY P, et al. Bandwidth Extension for Hierarchical Speech and Audio Coding in ITU-T Rec. G.729.1[J]. IEEE International Conference on Audio, Speech and Signal Processing, 2007,15(8):2496-2509.
[4] 李海婷,范睿,朱恒,等.最新的ITU-T嵌入式变速率语音编码关键技术[J].电声技术,2006, 30(11):50-55. LI Haiting, FAN Rui, ZHU Heng,et al. Key techniques of the latest ITU-T embedded variable bit-rate speech coding[J]. Audio Engineering, 2006,30(11):50-55.
[5] SETO Koji, OGUNFUNMI Tokunbo. Scabable Wideband Speech coding for IP Networks[C]//IEEE Conference on Circuits, Systems & Computers.Penang,Malaysia: IEEE, 2012:77-81.
[6] 刘丽群, 黄冰. 基于DM642的G.729.1的DSP实现[J].桂林电子科技大学学报,2011,31(2):103-105. LIU Liqun , HUANG Bing. Implementation of the G.729.1 based on DM642[J].Journal of Guilin University of Electronic Technology,2011,31(2):103-105.
[7] 董传霄.基于ARM体系结构的上层应用—音频编解码协议G.729.1的优化及应用[D].北京:北京邮电大学,2009. DONG Chuanxiao. An application based on ARM—The optimization and Application of G.729.1 speech coding codec[D].Beijing:Beijing University of Posts and Telecommunications, 2009.
[8] CHO Keunseok,JEONG Sangbae,HAHN Minsoo.Frame Error-Robust MDCT bit Reduce for G.729.1 by Inter-Fame Correlation[C]//IEEE International Conference on Consumer Electronics. Xianning,China:IEEE,2011,819-820.
[9] ITU-T Recommendation. Wideband extension to Recommendation P.862 for the assessment of wideband telephone networks and speech codecs [R].Geneva,Switzerland:Telecommunication Standardization Sector, 2007.
[10] Texas Instruments Inc.TMS320VC5505 DSP System User’s Guide,SPRUFP0C[R].Texas: Texas Instruments Incorporated, 2012.
[11] Texas Instruments Incorporated.TMS320C55X系列DSP指令系统开发工具与编程指南[M].李海森,周天,黎子盛,译. 北京:清华大学出版社,2007. Texas Instruments Incorporated.DSP instructions system development tools and programming guide of TMS320VC55x [M].LI Haisen,ZHOU Tian,LI Zisheng,translation.Beijing: Tsinghua University Press,2007.

王春柳(1989-),女,安徽马鞍山人,硕士研究生,研究方向为数字语音编码、DSP。E-mail:chunliuwang@yeah.net。

陈德宏(1965-),男,安徽马鞍山人,副教授,硕士生导师,研究方向为通信系统总体设计、数字语音编码、DSP、密码分析。E-mail:cdh@ahut.edu.cn。

申星海(1990-),男,山西运城人,硕士研究生,研究方向为数字语音编码、DSP。
(编辑:王敏琦)
G.729.1 algorithm improvement and DSP all assembly optimization design
WANG Chunliu1, CHEN Dehong2, SHEN Xinghai2
(1.Department of Electrical Information Engineering, Wentian College, Hohai University, Ma’anshan 243031, P.R.China;2. Institute of Electrical and Information Engineering, Anhui University of Technology, Ma’anshan 243002, P.R.China)
In the wideband speech coding algorithm of G.729.1 standard, based on sub-band correlation of inter-frames, spectral envelope coding of time-domain aliasing cancellation encoder reduces allocation bits with the difference Huffman coding. Considering the sub-band correlation between adjacent frames, a difference Huffman coding mode in sub-band of adjacent frames is added on the foundation of the original spectral envelope coding mode, which further reduces spectral envelope of coded bits and improves the quality of synthesized speech. G.729.1 can adjust the coding rate according to the characteristics of channel at any time and can get a better wideband speech quality,which makes the encoding algorithm have a high complexity. Therefore, all assemble language based on TMS320VC5505 digital signal processor is adopted to the real-time implement of G.729.1 algorithm. And the further optimization is made for the assembly code of G.729.1. The optimized G.729.1 algorithm can ensure the high-quality synthesis speech, improve the coding efficiency and achieve the real-time processing of the speech signal.
wideband speech coding; G.729.1; spectral envelope coding; difference Huffman coding; assembly optimization
10.3979/j.issn.1673-825X.2016.06.007
2015-05-19
2015-12-21
王春柳 chunliuwang@yeah.net
国家自然科学基金(61304066)
Foundation Item:The National Natural Science Foundation of China (61304066)
TN912.3
A
1673-825X(2016)06-0789-08
猜你喜欢
空间电子技术(2021年4期)2021-11-10 07:06:04
电子制作(2019年22期)2020-01-14 03:16:24
少儿美术(2019年5期)2019-12-14 08:04:52
深圳职业技术学院学报(2018年2期)2018-09-08 05:57:26
海峡姐妹(2017年10期)2017-12-19 12:26:20
三联生活周刊(2017年33期)2017-08-11 04:35:44
银行家(2017年1期)2017-02-15 20:27:20
系统工程与电子技术(2016年2期)2016-04-16 05:16:50
小学教学研究·新小读者(2015年6期)2015-06-16 19:40:54
计算机应用文摘(2014年1期)2014-04-29 00:44:03
