
C语言编程实现ISODATA算法
2016-12-21 01:04:33刘明晓王旭光
电气传动自动化 2016年5期
刘明晓,王旭光
(1.西安铁路职业技术学院,陕西西安710014;2.西安航天自动化股份有限公司,陕西西安710014)
C语言编程实现ISODATA算法
刘明晓1,王旭光2
(1.西安铁路职业技术学院,陕西西安710014;2.西安航天自动化股份有限公司,陕西西安710014)
ISODATA算法是聚类分析算法中较常使用的算法,是非监督状态下基于统计模式识别的一种动态的聚类算法,在模式识别算法中具有较强的实用性。介绍了ISODATA算法的计算过程和具体实现方法,结合C语言编程工具对具体的样本进行了聚类分析,得到了较为理想的聚类分析结果,研究了参数的选取对分类结果所产生的影响。
ISODATA算法;聚类;C语言编程;模式识别
1 引言
ISODATA算法又称为动态聚类算法或迭代自组织数据分析算法,是一种对样本进行聚类划分的算法[1]。ISODATA算法是以均值迭代来确定聚类中心,其与K均值算法的不同是加入了人机对话环节,这使得参数可以随时进行调整,该算法同时还引入了分裂与合并的功能[2]。分裂是指当某样本的标准差大于设定的阈值或该样本的数目超过某一特定的阈值时将该样本分为两个样本,或在该样本数目少于某一阈值时对样本进行分裂;合并是指当某两个样本的样本中心间距小于某一阈值时将两个样本合并为一个样本,同时当某一样本的样本数目少于设定的阈值时即将该样本取消,归入其他样本中去[3、4]。因此,ISODATA 算法较其他算法相比更加灵活,实用性更强。
ISODATA算法是一种无监督的分类方法,首先选择若干个样本点作为聚类中心,再按照最小距离的原则使其余样本向各个聚类中心聚集,这样便得到了初始的分类样本,然后再判断形成的初始聚类结果是否满足要求,若不满足则可将各个聚类进行合并或分裂处理进而形成新的聚类中心,再次判断新形成的聚类结果是否满足要求。如此经过多次迭代直到新形成的聚类满足要求即可停止聚类划分。
2 ISODATA基本流程和算法步骤
2.1 ISODATA 基本流程
ISODATA 基本流程[5、6]图如图 1 所示。
2.2 ISODATA 算法步骤
ISODATA算法步骤如下:
(1)设置聚类分析控制参数。主要包括:所要求的聚类中心数K;一个待分类的样本应包括的样本数目θN;一个类别样本标准差阈值θS;各聚类中心之间的阈值θC;任何一次迭代过程中允许合并或分裂的样本对数L;允许迭代的最多对数I。

图1 ISODATA算法流程图
(2)将准备分类的样本值读入。
(3)以距离聚类中心距离最近为原则对读入的样本值进行初始化聚类[7]。
(4)聚类分裂[8]。分裂是指在同一聚类中如果样本数目太过密集或聚类中样本的数目太稀疏,那么在该空间中还存在其他聚类中心,这时就需要对该聚类进行分裂。分裂是通过对各样本分布的标准差的上限值进行设定,如果样本距离聚类中心的距离大于标准差的上限值则被划分到另一聚类中,否则该样本仍保留在该聚类中,然后再次转到步骤(2)。
(5)聚类合并[8]。合并是指两聚类的聚类中心相聚较近,该两聚类的样本没有进行分裂的必要性,则可将这两聚类进行合并。具体方法是设置聚类中心之间的距离下限值,如果两聚类中心的距离小于该下限值或是某一聚类中样本的数目过少不足以成为一类时,那么将该聚类中的样本合并到其他聚类中去。然后再次转到步骤(2)。
(6)按照设定的程序对步骤(2)中输入的样本反复进行分类、判别、合并或者分裂操作,如果形成的聚类满足要求或是进行合并和分裂的次数达到了规定的次数则聚类分类结束。
3 具体算例与分析
在C语言编程环境下,利用ISODATA算法将输入的 10 个样本组成样本集{x0,x1,x2,x3,x4,x5,x6,x7,x8,x9},并对其进行分类。这 10 个样本值分别如 下:x0{0,0,0,0},x1{3,0,8,0},x2{2,0,2,0},x3{1,0,1,0},x4{5,0,3,0},x5{4,0,8,0},x6{6,0,3,0},x7{5,0,4,0},x8{6,0,4,0},x9{7,0,5,0},对其进行聚类分析后的样本分布情况如图2所示。
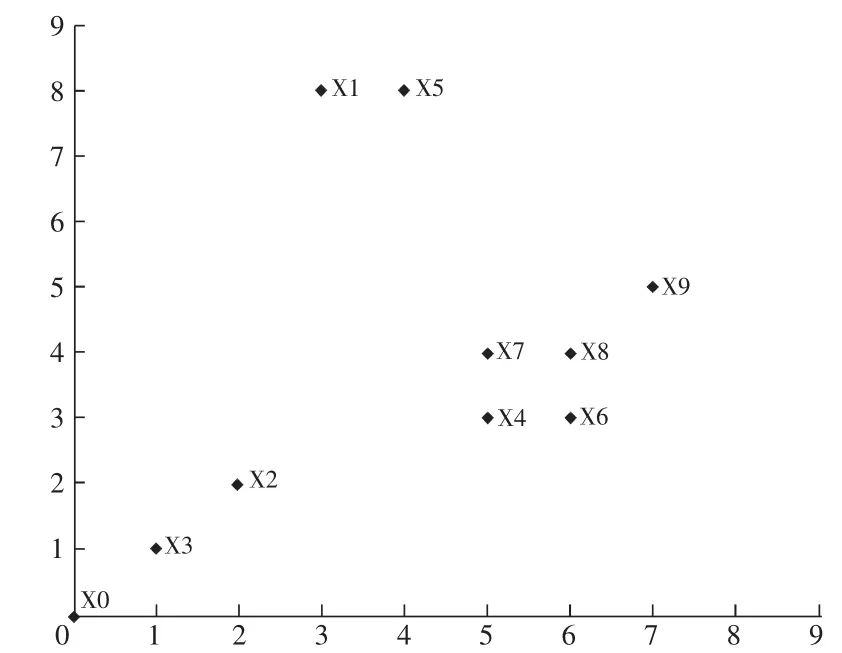
图2 样本坐标图
从图2中可以直观地看出,样本集分为3类是合理的,其中{x0,x2,x3}为第 1 聚类,{x4,x6,x7,x8,x9}为第2 聚类,{x1,x5}为第3 聚类。分别取 K=2、3、4,运用ISODATA算法进行迭代计算,并将K取不同值时的控制参数和分类结果分别以表格的形式列出来。各个控制参数的设定值如表1所示,经过ISODATA算法进行分类之后输出的分类结果如表2所示。
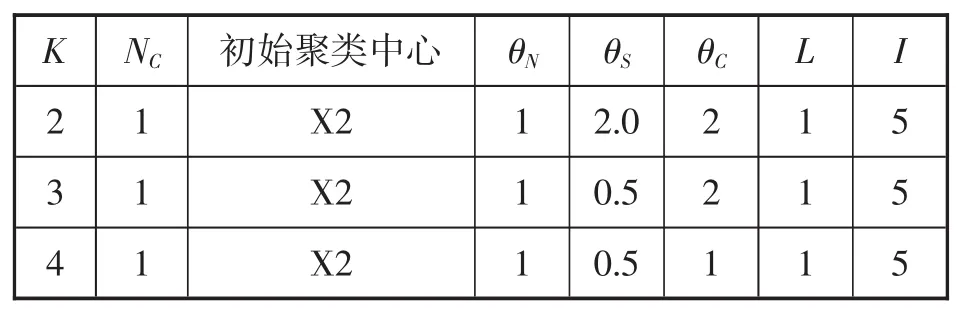
表1 控制参数设定值表
通过分析表2的聚类分析结果,可以看出,将聚类数目K设定为3时,经过ISODATA算法进行合并与分裂之后所输出的聚类结果与预期的结果是一致的,从而验证了ISODATA算法的正确性。另外,由于在ISODATA算法中加入了人机对话环节,故可通过参数调整来改变聚类的结果。从表2也可以看出,当聚类中样本的标准差阈值θS、聚类中心之间距离的阈值θC和允许迭代的最多次数I选取不同的值时,也会对聚类结果产生不同的影响。通过参数控制来研究参数选取对分类结果产生的影响,下面就聚类数K=3时,通过改变其他参数的设定,来验证这三个参数是如何影响聚类结果的。
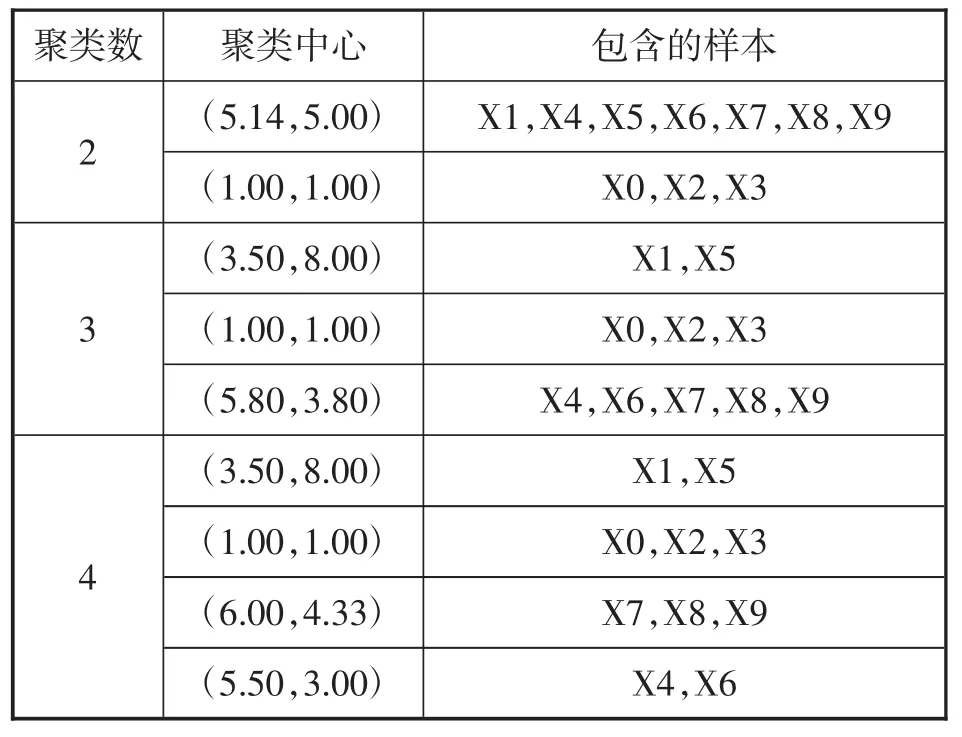
表2 输出的分类结果表
首先控制 K,θN,θC,L,I参数的值不变,当聚类样本的标准差阈值分别取 θS=2.5,1.0,0.5 时,控制参数如表3所示,输出的聚类结果如表4所示。
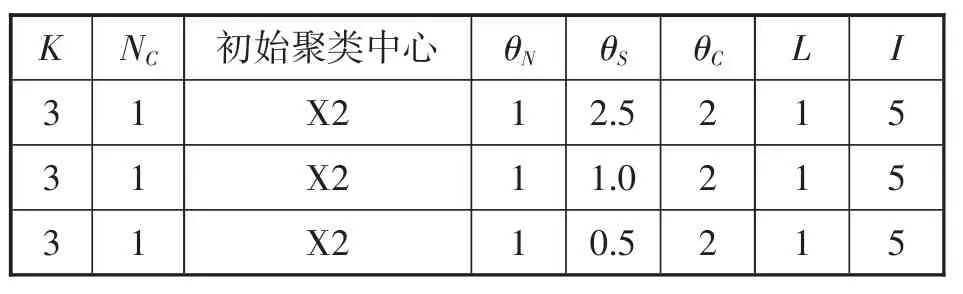
表3 控制参数表

表4 输出的聚类结果表
从表3、表4中可以看出,标准差参数θS设定值越大,分裂的可能性就越小,分类数目也越少,因此,要想得到理想的聚类结果还要通过试验选择合适的标准差阈值。
控制 K,θN,θS,L,I的设定值不变,分别取 θC=5,2,1时,其控制参数如表5所示,输出的聚类结果如表6所示。
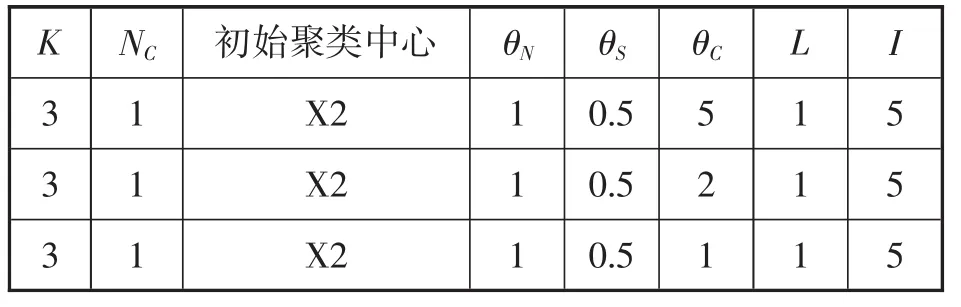
表5 控制参数表
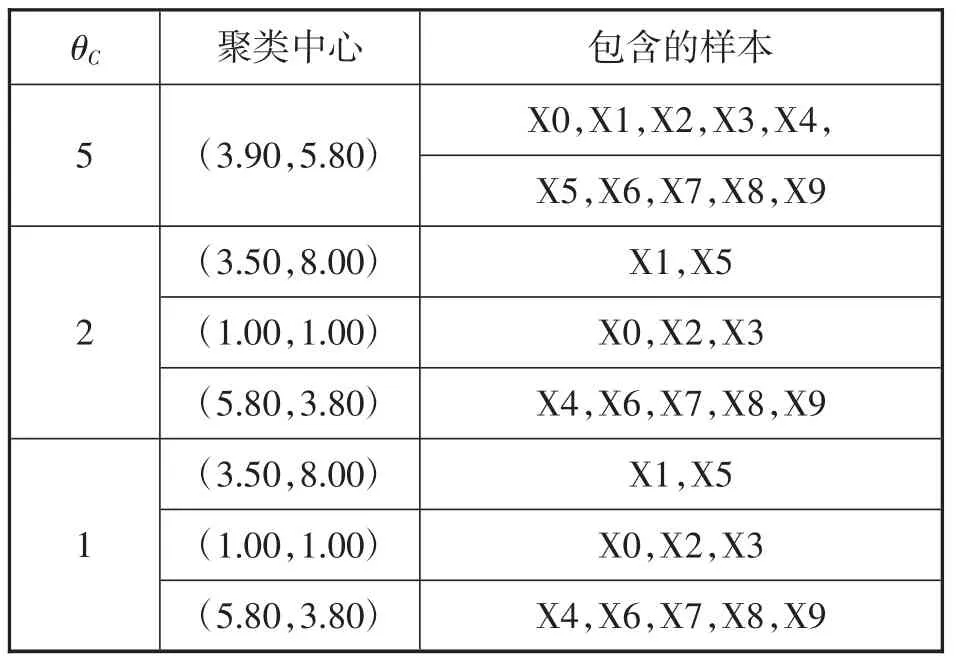
表6 输出的分类结果表
从表5、表6得出的分类结果可以看出,合并参数越小,ISODATA算法迭代过程中合并的可能性也越小,因此,这在较大程度上保留了上一迭代过程的分类结果。
但是当合并参数过大时,会导致分类不到位。控制 K,θN,θS,θC,L 设定值不变,允许迭代的次数分别取 I=20,5,2 时,其控制参数如表 7 所示,输出的聚类分析结果如表8所示。
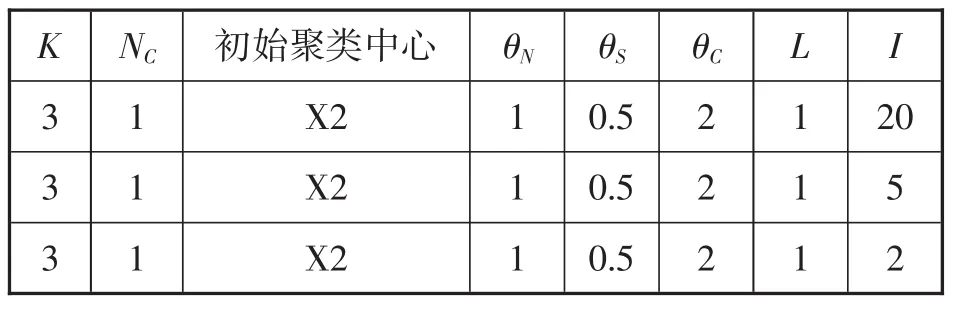
表7 控制参数表
由表7、表8得出的结果可知,迭代次数设置过大会导致过度分类;迭代次数设置过小,又会导致分类不充分,因此选择合适的迭代次数很重要,其对聚类分析结果影响较大。同时,标准差以及合并参数改变后,聚类结果将受到迭代次数设定的影响,当迭代进行到第10次时,如果保持标准差及合并参数不变,那么聚类结果也将保持不变。

表8 输出的分类结果表
4 结束语
本文介绍了基于C语言编程的ISODATA算法原理及具体操作步骤,并结合具体算例进行了聚类分析,得到了较为理想的聚类分析结果,同时,通过改变可影响聚类分析结果的各参数的设定值来研究了各参数对聚类结果的影响程度。ISODATA算法与其他算法的不同是在进行聚类分析之前需要人为设置一些参数,充分体现了人机交互的特点。人机交互过程是将很多人为经验应用到聚类分析之中,这在很大程度上减少了聚类的盲目性,有利于样本朝着较好的聚类方向发展。
[1]胡飞翔.基于云计算的聚类算法的MapReduce化研究[D].沈阳:东北大学,2012.
[2]杨淑莹.图像模式识别-VC++技术实现[M].北京:清华大学出版社,2005.205-212.
[3]王 萍.基于核心集粗化的多层次聚类算法[D].南京:航空航天大学,2014.
[4]李宗杰.基于聚类分析的风电场输出功率模型的研究[D].北京:华北电力大学,2012.
[5]舒 宁.模式识别的理论与方法[M].武昌:武汉大学出版社,2004.69-73.
[6]李元萍,李元良.MATLAB编程实现ISODATA算法[J].矿业研究与开发,2005,25(3):79-80.
[7]曾江源.ISODATA算法的原理与实现[J].科技广场,2009.
[8]杨小明,罗 云.ISODATA算法的实现与分析[J].采矿技术,2006,6(2):67-68.
Realization of ISODATA algorithm by C language programming
LIU Ming-xiao1,WANG Xu-guang2
(1.Xi’an Railway Vocational and Technical College,Xi’an 710014,China;2.Xi’an Aerospace Automation Co.,Ltd.,Xi’an 710014,China)
The ISODATA algorithm is a commonly used algorithm in clustering analysis,which is a dynamic clustering algorithm under unsupervised state based on statistical pattern recognition,and has strong practicability in pattern recognition algorithm.Firstly,the ISODATA algorithm and the implementation methods are introduced,and then the specific samples are clustered and analyzed combined with the C language programming tools,and thus the ideal clusteringresultsareobtained.Theinfluenceoftheparameterselectionontheclassificationresultsisalsoanalyzed.
ISODATA algorithm;clustering;C language programming;pattern recognition
TP311
A
1005—7277(2016)05—0047—04
刘明晓(1987-),女,河南焦作人,助教,硕士,主要研究方向为电力系统及其自动化。
2016-07-11
猜你喜欢
飞控与探测(2022年6期)2022-03-20 02:16:14
湖北农机化(2021年7期)2021-12-07 17:18:46
当代医药论丛(2021年3期)2021-03-17 07:03:12
力学学报(2020年4期)2020-08-11 02:32:12
黑龙江电力(2017年1期)2017-05-17 04:25:08
自动化仪表(2015年5期)2015-06-15 19:01:34
汽车维修与保养(2015年6期)2015-04-17 03:31:40
质量技术监督研究(2015年1期)2015-04-09 06:42:12
赤峰学院学报·自然科学版(2015年15期)2015-03-21 00:30:56
城市道桥与防洪(2013年8期)2013-03-11 15:18:35
