
判别分析在上市公司信用风险中的实证研究
2016-12-15 06:05:45徐慎晖
河南工程学院学报(社会科学版) 2016年4期
杨 莹,徐慎晖
(1.安徽大学 经济学院,安徽 合肥 230601;2.河海大学 商学院,江苏 南京 211100)
判别分析在上市公司信用风险中的实证研究
杨 莹1,徐慎晖2
(1.安徽大学 经济学院,安徽 合肥 230601;2.河海大学 商学院,江苏 南京 211100)
随着我国证券业体系的不断健全、世界金融一体化趋势和金融市场波动性的加剧,上市公司信用的风险评估已经成了金融机构和企业关注的重大问题。因此,通过企业历史数据对其未来发展及其预期风险做出较为准确的判断,对其信用风险进行有效监控就显得愈发重要。以上海证券交易所上市的部分企业的相关数据作为样本,通过选取较为合理的指标体系,对样本进行多元统计判别分析,以提高管理效率,降低风险。判别分析结果显示,所得到的判别模型能够较好解释我国证券市场所出现的部分信用情况。
上市公司;判别分析;信用风险
金融监管对于一国的经济发展有着重要作用。一方面,它可以降低金融风险,维持金融业的稳定;另一方面,过多的监管势必会花费较高的监管成本;同时,还可能会导致被监管对象道德风险的增加,从而降低金融效率。如何判别一个产业是否具有市场竞争力和发展持续性,是值得深思和研究的。目前,美国纳斯达克市场的规范化已经相对较为成熟,而我国沪深两市的建设则较为落后。
美国在风险控制方面以银行业为主,于1991年颁布了《联邦存款保险公司改进法》,形成了快速预警纠偏模型,同时还设立了CAMEL(Captal Adequacy,Asset Quality,Management,Earnings,Liquidity)评级体系。本文对比借鉴CAMEL中的五方面评级标准。CAMEL从以下五方面分析银行的经营情况:资本充足率、资产质量、管理水平、收益状况、波动性。美国一些学者采用诸如回归分析、多元判别分析、Logit和Probit分析对风险进行有效性分析。
随着市场化的加剧及金融市场化和金融全球化的波动性日趋增加,各国银行和投资者都受到前所未有的信用风险的挑战。世界银行对全球银行危机的研究表明,导致银行破产的最主要原因就是信用风险。《巴塞尔协议》旨在加强信用风险的管理。西方国家对于风险控制相对较为成熟,而在我国,证券市场起步晚,发展速度快,相关风险控制的政策还未落实,导致有关信用风险评估研究的成果较少。因此,本文采取判别分析法,对2014年上市公司中已经披露的若干信息对企业信用风险进行判别分析,来研究我国上市公司信用风险的评估。
一、理论假设
判别分析是一种统计判别和分组技术,其原理是就一定数量样本的一个分组变量和相应的其他多元变量的已知信息,对新样品进行判别分组。其中,Fisher判别亦称典则判别,是根据线性Fisher函数值进行判别,使用此准则要求各组变量的均值有显著性差异。该方法的基本思想是投影,即将原来在R维空间的自变量组合投影到维度较低的D维空间,然后在D维空间中再进行分类。投影的原则是使每一类的差异尽可能小,而投影的离差尽可能大。Fisher判别的优势在于对分布、方差等都没有任何限制,应用范围比较广。另外,用该判别方法建立的判别方差可以直接用手工计算的方法进行新样品的判别,这在许多时候是非常方便的。除Fisher外,还有贝叶斯(Bayes)判别法。
本文采用SPSS软件对2014年上市公司信用风险进行判别分析。首先,本文数据来自于A股市场的相关企业年报和证监会披露的信息。其次,本文将2014年上市公司中已知的公司按信用风险程度分成不同的组,之后利用Fisher判别方法,将财务向量进行投影,使之成为单向量,对已经整理过而形成的单个向量进行统计分析,从而建立起信用风险的距离差别准则。对2014年的数据进行判别分析所得到的结果,对比2015年上市公司的相关数据,发现预测正确率较高,误差较低。
判别函数的一般形式为:
Z=a1x1+a2x2+a3x3+…+anxn
其中Z是判别值,x1,x2,x3,…,xn为研究对象的特征变量,a1,a2,a3,…,an为各变量的判别系数。将已知样本分为Group 1和Group 2,根据得到的判别函数,将新得到的样品Y中的各个指标值带入判别函数,便可得到相应的判别值,再找出判别函数的临界值。两者进行比较,就可以对新样本的类别做出判断。当Z>临界值,则Y属于Group 1;当Z<临界值,则Y属于Group 2;当Z处于临界值,则Y待判断。
假设有n个上市公司来自A组,则将n个上市公司作为研究样本,每一个样本点由P个财务指标组成。来自A组的观测值将其投影到某一个共同方向,得到的投影点是线性组合P维常数向量,表示投影方向。SST、SS(TR)和SS分别表示总方差、组间方差、组内方差。所含有的自由度分别为n-1、k-1和n-k。假设各组的真实方差相等,则可对k个组的真实组均值之间是否有显著性差异进行检验。假设k个真实组均值相等是原假设,那么我们可以得到检验统计量:
当统计值F≥F(k-1,n-k)时,则拒绝原假设,F值越大,拒绝原假设的理由越充分,各组真实组均值之间的差异越显著,投影数据越能反映原始数据的真实情况,则判别分析尤其是典型判别分析效果更加理想。
二、模型设计
(一)研究样本
本文选择样本全部出自于在沪深两市上市的公司及其相关财务报告。一方面,截自2015年4月公布2014年财务审计报告以来,本文从沪深两市2015年评选出来的百强上市公司中挑选了包括伊利集团、海螺集团等共30家企业作为判别分析中的信用非违约组。另一方面,本文从相关程序所产生的ST公司中挑选了具有代表性的30家企业,视为判别分析中的信用违约组。综上所述,样本总量共计60家上市公司。
(二)变量选择
财务比率在一定程度上可以客观反映企业运营情况。本文在选择财务指标时,将反映企业的相关财务指标进行考虑,剔除了财务比率之间相关程度较高的指标,最后以净资产收益率(ROE)、资产负债率、流动比率、资产收益率(ROA)、现金比率作为判别分析的变量,分别计为x1、x2、x3、x4、x5,基于此得到典型判别函数模型:
Z(x)=c0+c1x1+c2x2+c3x3+c4x4+c5x5
其中ci为模型的参数。
基于流动性、安全性、盈利性、充足性等对五个因素进行分析。流动比率和现金比率作为流动性参数进行分析,净资产收益率(ROE)和资产收益率(ROA)作为盈利性参数进行分析,资产负债率作为安全性参数进行分析。其中,流动性指标是反映企业偿还短期债务、维持正常经营的重要指标,流动性差会影响企业的经营,但是流动性过高又反过来会影响企业资产的运营效率。
(三)参数估计
根据前面分析讨论,得出以下结果:
n1=30 代表信用非违约组的样本容量,财务状况良好的上市公司属于这个组。
n2=30 代表信用违约组的样本容量,主要以ST企业为主。
n=60 代表总体样本容量。
本文将总样本分为两类,样本数据是由现有沪深两市所有公开披露的企业资料整理而来,在进行下一步的判别分析时,总分类是g=2,n=60。
三、实证结果
按照前面设立的数据模型,以2014年60家上市公司年报所提供的数据作为样本观测值,通过SPSS运行计算结果。

表1 判别函数模型估计
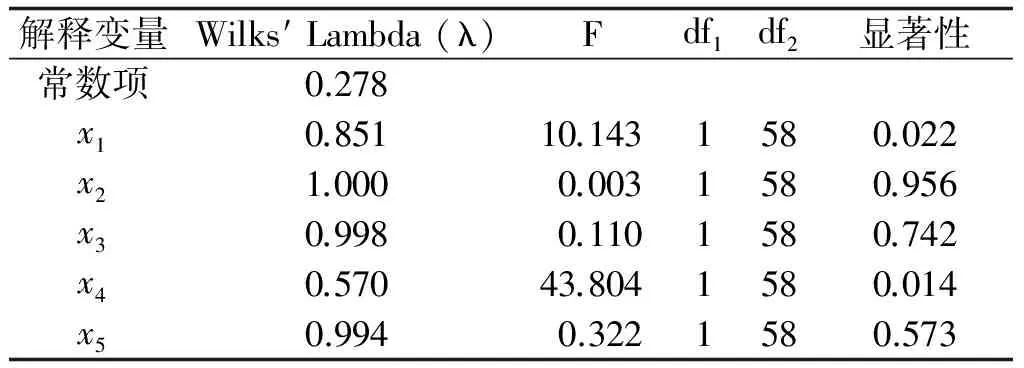
表2 判别函数解释变量显著性检验群组平均值的等式检定

表3 群组统计资料
由表1可以看出,卡方似然估计的统计量为44.736,大于自由度为5的卡方表中的临界值15.09,所以可以得出Z(x)=0.278+0.851x1+x2+0.998x3+0.57x4+0.994x5,且该判别函数是显著的。可以看出,函数总体在1%解释水平下是显著的,表明模型对上市公司信用的风险判断有一定的解释能力。表2 说明显著的解释变量有5个,按照逐步判别过程解释变量进行模型的顺序是x2、x1、x3、x4、x5。因为资产负债率在企业中反映了上市公司的财务风险,后者在一定程度上体现了资产的运行效率,流动比率衡量了企业短期变现资产偿还债务的能力。实质上这5个财务比率指标与上市公司信用风险息息相关。由此可见,模型中所包含的解释变量能够较好地反映上市公司的实际信用风险程度。

表4 共变异矩阵与相关矩阵
通过以上SPSS软件统计,对数据进行分析并进行了预测。标准化的判别函数为:Z(x)=0.278+0.851x1+x2+0.998x3+0.57x4+0.994x5,且观测总量为60。截止到2016年2月,从2015年沪深两市所公布的企业年报中选择业绩较为优良、财务指标规范的企业(银行业除外),以及ST企业一共20家作为检验样本进行后续检验,最后得出检验样本总的正确率达到了90%以上。*表3和表4的意义不在于统计结果的展示,而是展示了模型有效的预测能力,表3的结果是为表4做准备的,其意义在于显示统计量在判别分析的分类中表达出的正确率,从表4可以看出达到了90%以上。因此,样本检验结果表明,模型具有较为有效的预测能力。
四、结论和局限性
通过上面的分析可以得到如下结论:第一,利用历史性数据可以对未来数据进行预测性估计,并对未知样品做出快速的判断。本文中所判断的企业的净资产收益率、资产负债率、流动比率、现金比率和资产收益率只要达到平均水平以上,就能在很大程度上规避和防范风险。第二,企业的年报可以披露绝大多数企业运营情况,所以可以基于数据实际做出相应的监管判断,为投资者进行科学的决策、理智地回避风险提供依据。第三,我国的金融监管在业务运营监管上相对较为成熟,然而需要将企业运营和现场检查两者相结合,通过对数据的整理,对风险进行监测,有利于判断企业的信用风险,也有利于监管机构实施分类监管政策。
采用判别分析也存在一定的局限性。首先,上市公司信用违约组不能仅仅局限在ST企业。本文为了统计的便利性,采用ST企业作为第二组样本进行统计,实际上,一些并非ST的企业也存在信用违约问题。这类企业存在隐藏的信用风险,但并未表现出财务困难,所以可能存在财务虚假报告的可能。因此,在实际操作中,有必要对所有企业做进一步的划分,而不能仅仅局限于ST企业。其次,模型仍然存在犯错的可能,即第一类错误的比率还是较高的,在进一步的分析中应该将定性和定量相结合,将误差降到最低。再次,由于数据误差的存在,同时对银行(包括中国银行、工商银行等样品的舍弃)缺少ROA和现金比率的公报的问题在接下来的研究中将继续选择合适的参数估计量,或者采用一些补救办法对这类问题进行合理性补救。
[1]龙小宁,朱艳丽,蔡伟贤,李少民.基于空间计量模型的中国县级政府间税收竞争的实证分析[J].经济研究,2010(8):41-53.
[2]李林,丁艺,刘志华.金融集聚对区域经济增长溢出作用的空间计量分析[J].金融研究,2011(5):113-123.
[3]施锡全,邹新月.典型判别分析在企业信用风险评估中的应用[J].财经研究,2001(10):53-57.
[4]吴海华,王志红.商业银行监控指标的判别分析[J].统计与信息论坛,2005(7):90-93.
[5]韩丽.聚类分析和判别分析在证券投资中的应用[J].金融观察,2007(7):61-62.
[6]楚尔鸣, 喻多娇.中国货币中性与非中性的实证检验[J].金融发展研究, 2009 (3): 26-30.
[7]苟小菊,许锐,扶元广.安徽省城镇化发展影响因素的空间计量研究[J].中国科学技术大学学报,2015(5):416-421.
An Empirical Study on the Discriminant Analysis About Credit Risk of the Listed Companies
YANG Ying1,XU Shenhui1,2
(1.SchoolofEconomics,AnhuiUniversity,Hefei230601,China; 2.SchoolofBusiness,HohaiUniversity,Nanjing211100,China)
With the constantly improvement of China′s securities system, and with the trend of global financial integration and the aggravated volatility in financial market, the assessment about listed companies′ credit risk has become a major issue of concern for financial institutions and enterprises. It is more important to make a more accurate judgment on the future development and expected risk through an enterprise′s historical data, and thus to monitor the credit risk effectively. In order to manage efficiently and reduce risks, this essay selects reasonable index system and make a multivariate statistical discriminant analysis on the sample, which was taken from related data of part of listed enterprises in the Shanghai Stock Exchange. Discriminant analysis results show that the model can better explain the credit situation in part of China′s securities market.
listed companies; discriminant analysis; credit risk
2016-05-05
杨 莹(1993-),女,安徽六安人,安徽大学经济学院硕士研究生,研究方向为信用风险。
F832.49
A
1674-3318(2016)04-0017-03
猜你喜欢
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
中国特种设备安全(2019年5期)2019-07-16 08:51:42
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
中国科技纵横(2018年3期)2018-03-15 00:27:35
辽宁经济(2017年6期)2017-07-12 09:27:35
当代经济(2016年26期)2016-06-15 20:27:18
新疆财经大学学报(2015年3期)2015-12-10 03:49:13
海南热带海洋学院学报(2014年2期)2014-08-08 12:49:48
