
基于K-means聚类分析算法的2型糖尿病动态血糖监测数据分析
2016-12-09 12:26:04吕克难王能才
中国医学装备 2016年11期
韦 哲 吕克难 王能才
基于K-means聚类分析算法的2型糖尿病动态血糖监测数据分析
韦 哲①②吕克难①②王能才①
目的:探讨分析基于K-means聚类分析算法的2型糖尿病动态血糖监测数据,以解决动态血糖测量仪所测数据中的噪声和干扰信号问题,得到适用于灰色关联度分析法的实验数据。方法:引入K-means聚类分析算法处理和分析由动态血糖仪测得的糖尿病患者60 min血糖值的数据,去除误差较大的数据点,使平均数值更加可靠。结果:K-means聚类分析算法对生成所需的、无干扰地对患者60 min内间隔5 min的血糖值实验数据进行处理,并与采用K-means分析算法处理之前的数据进行对比。结论:K-means聚类分析法能够有效去除干扰和噪声信号,获得高质量的实验数据,有利于对动态血糖监测数据进行处理和分析。
血糖监测;数据处理;K-means聚类分析;灰色关联度分析法
[First-author’s address] 1.Department of Information, Lanzhou General Hospital, Lanzhou Military Area Command, Lanzhou 730050, China. 2.School of Electrical Engineering and Information Engineering, Lanzhou University of Technology, Lanzhou 730050, China.
糖尿病是由胰岛素分泌缺陷和(或)胰岛素作用缺陷所引起的,并以慢性高血糖伴碳水化合物、脂肪和蛋白质的代谢障碍为特征的慢性疾病[1-2]。2型糖尿病(Type 2 diabetes mellitus,T2DM)又称为非胰岛素依赖型糖尿病,而非胰岛素依赖型糖尿病的发病机制主要是由于人体的胰岛素抵抗及胰岛素分泌不足所导致,且T2DM患者自身的β细胞并无自身免疫性缺陷,其发病特点是成年发病,起病比较缓慢,病情也较轻,比例占到全部糖尿病人数的多数[3]。目前,控制糖尿病病情最为有效和常见的治疗方案之一是注射胰岛素,但不论是健康人还是糖尿病患者血糖数据均具有不稳定性和波动性,如果患者对注射胰岛素的时间和注射量把握不准确,则会导致低血糖或高血糖,并可对糖尿病患者的身体造成极大的伤害,因此对糖尿病患者血糖的准确预测具有重要的研究意义[4]。
目前,测量血糖的方法多数采用化学方法,而该测量方法易受温度的影响,且测量者的运动会对测量结果产生影响,但目前还尚无一种能够对血糖测量数据进行准确聚类分析的方法。基于此,本研究提出基于K-means平均聚类分析方法,可以对血糖测量数据进行聚类,从而剔除掉有明显误差的数据点,使得计算的数据结果更加准确,为后续的灰色关联度分析算法打下良好的基础[5]。
1 K-means聚类算法原理
1.1K-means算法概述
K-means算法是采用距离作为相似性评介指标的聚类算法,如果两个对象的距离越近,其相似度就越大[6-7]。K-means聚类算法认为簇是由距离靠近的对象所构成,因此将得到紧凑且独立的簇作为最终目标[8]。K-means聚类算法具有计算快速、简单且其时间复杂度近于线性等诸多优点,适合大规模数据集的挖掘[9]。
1.2K-means聚类算法
(1)随机选取k个聚类质心点为μ1,μ2,…,μκ,E Rn。
(2)重复下述过程直到收敛,对于每个样例,计算其应该属于的类为公式1:
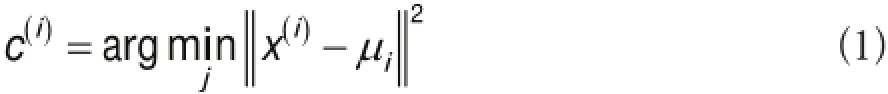
对于每一类j,重新计算该类的质心为公式2:

式中k为事先给定的聚类数;C(i)为样例i与k个类中距离最近的一类;C(i)为该值1到k中的一个;μj为质心,代表对属于同一类其他样本中心点的估测[10-15]。
2 动态血糖仪数据聚类分析
动态血糖仪Minimed皮下埋入式动态血糖检测系统是一种基于化学试剂葡萄糖分子化学反应的有创型人体血糖动态检测系统,该系统价格昂贵,通常为大型医院所配备。而对于患有T2DM的患者,注射胰岛素降低血糖是最有效的治疗糖尿病的方法,但这种方法必须在医生的指导下,先对血糖进行检测才能进行,否则会引发严重的不良反应[16-19]。因此,本研究采用SPSS Clemenine专业数据挖掘应用工具(美国,SPSS公司)对动态血糖仪数据聚类分析。
2.1聚类分析数据资料
本研究选用原兰州军区兰州总医院T2DM患者的皮下组织葡萄糖检测数据资料。数据以每日96个检测点,其中包括早餐前(A)、早餐后(B)、中餐前(C)、中餐后(D)、晚餐前(E)、晚餐后(F)、睡前(G)及夜间(H)60 min内每间隔5 min所检测得到的血糖值,见表1。
表1显示,患者早餐前(A行)有3个明显的测量错误数据点,如数据7.8、3.7和8.4,而采用聚类的方法可以将正确数据分为聚类1,并且将错误的数据点分别归为聚类2和聚类3。
2.2K簇平均算法建模
Clemenine能够直接进行K平均簇算法进行建模,并通过数据流导入进行数据分析。
(1)设置数据库来源。在工作区中加入“数据源”选项中的“表格”类型的节点,在节点中导入输入数据,即动态血糖仪采集到的原始数据表格,并对数据类型进行设置,选择“范围”,读取数值并确定,如图1所示。
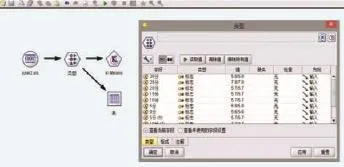
图1 K平均算法数据流和设置类型节点界面图
(2)设置建模节点。在“建模”选项栏中选择K-mean节点,添加到工作区中,并将“类型”节点和“K-means”节点连接,再对“K-means”节点进行参数设置。预设置“聚类数”为3,并选择是否输出其他结果,如图2所示。
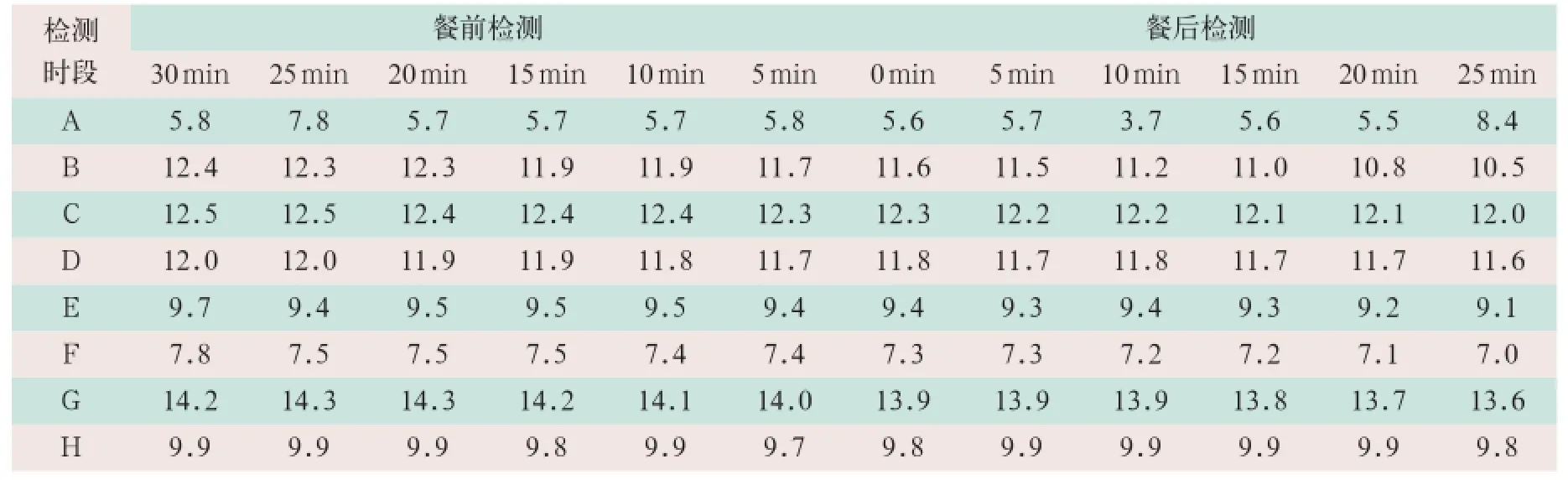
表1 患者96个血糖值数据点(mmol/L)
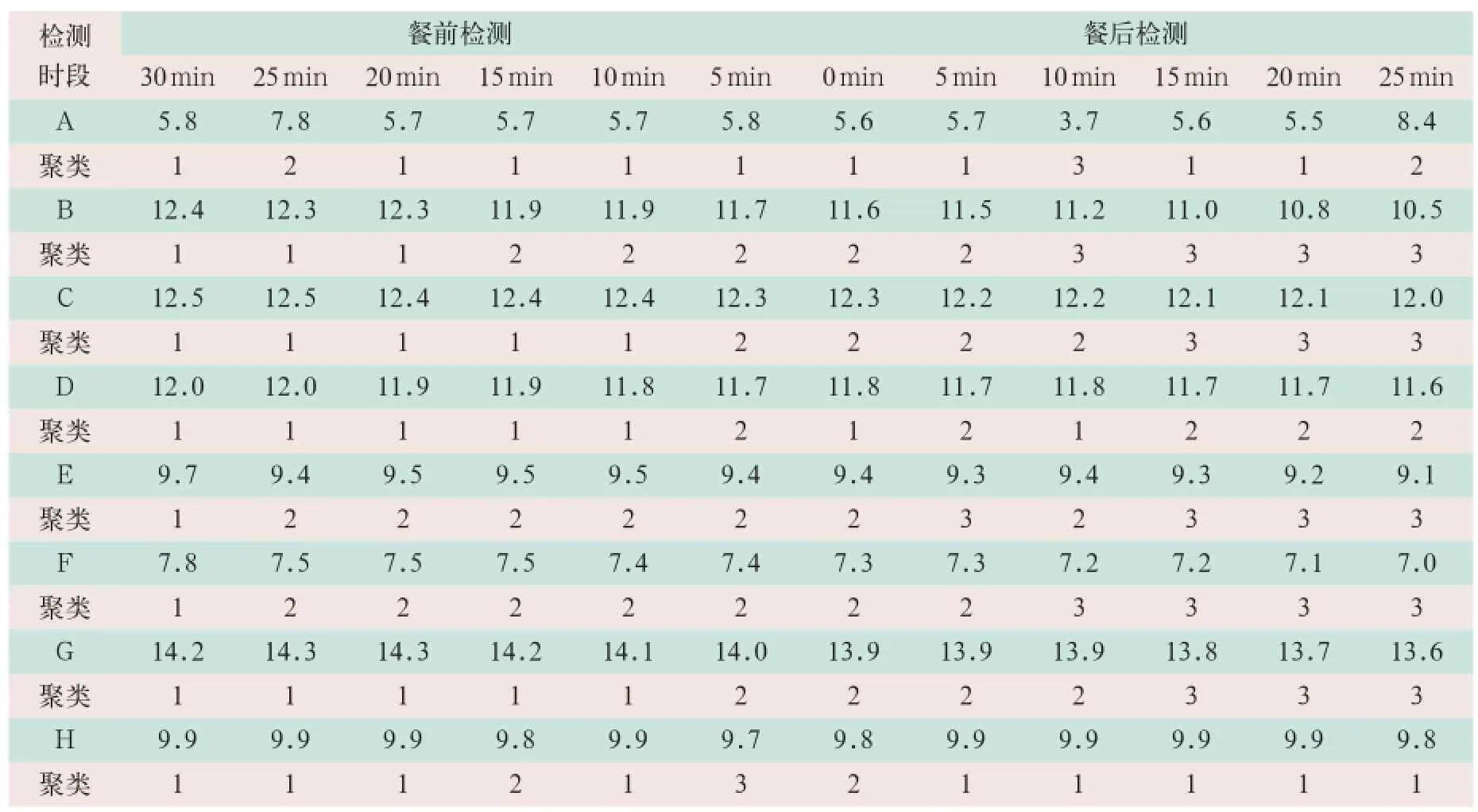
表2 K平均算法处理后患者某日血糖值的部分数据(mmol/L)
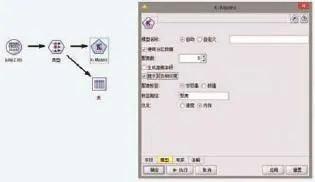
图2 数据流和设置建模节点界面图
在输出结果中显示出Clementine工具对动态血糖仪原始数据进行了有效聚类分析,按照3个聚类数的要求进行分类处理,见表2。
表2显示,利用K-means算法对表1的数据进行聚类处理后,将每个时间段的数据分成3类,有助于去除误差较大的数据点,得到更加精确的均值结果。
3 结论
血糖测量数据会由于客观或主观的原因产生误差,如果不对这些误差进行处理,会增大均值的误差,采用瞬时值则不准确,导致对患者的健康及治疗产生很大的影响。而本研究使用K-means算法对糖尿病患者一日的测量节点数据进行了聚类处理,将每个时间段的数据分成三类,并且去除了误差较大的数据点,使平均值数据更加准确可靠。同时,为提高灰色关联度分析算法的精度打下坚实的基础。
[1]李武成,王官权,金科.2型糖尿病并发高血压的危险因素分析[J].实用医学杂志,2010,26(17):3180-3181.
[2]Güler I,Übeyli ED.Diabetes diagnosis by multilayer perceptron neural networks[J].Journal of the Faculty of Engineering and Architecture of Gazi University,2006,21(2):319-326.
[3]嵇加佳,刘林,楼青青,等.2型糖尿病患者自我管理行为及血糖控制现状的研究[J].中华护理杂志,2014,49(5):617-620.
[4]Garcia-Compean D,Jaquez-Quintana JO,Gonzalez-Gonzalez JA,et al.Liver cirrhosis and diabetes:risk factors,pathophysiology,clinical implications and management[J].World Gastroen terol,2009,15(3):280-288.
[5]Jothi R,Mohanty SK,Ojha A.On Careful Selection of Initial Centers for K-means Algorithm[M]. Proceedings of 3rd International Conference on Advanced Computing,Networking and Informatics,2011.
[6]Wild S,Roglic G,Green A,et al.Global prevalence of diabetes-Estimates for the year 2000 and projections for 2030[J].Diabetes Care,2004,27(5):1047-1053.
[7]Qin J,Fu W,Gao H,et al.Distributed k-Means Algorithm and Fuzzy c-Means Algorithm for Sensor Networks Based on Multiagent Consensus Theory[C].IEEE International Conference on Industrial Technology,2016,5(3):1-12.
[8]Zhao D,Liu X.A Genetic K-means Membrane Algorithm for Multi-relational Data Clustering[M].Human Centered Computing Springer International Publishing,2013.
[9]García MLL,García-Ródenas R,Gómez AG.K -means algorithms for functional data[J].Neuro computing,2015,15(1):231-245.
[10]Capó,Marco.An efficient approximation to the K-means clustering for massive data[J]. Knowledge-Based Systems,2016,5(3):122-123.
[11]Bandyapadhyay S,Varadarajan K.On Variantsof k-means Clustering[J].Computer Science,2015,9(1):1-14.
[12]Abdallah L,Shimshoni I.K-Means over Incomplete Datasets Using Mean Euclidean Distance[J].Machine Learning and Data Mining in Pattern Recognition.Springer International Publishing,2016,3(11):113-127.
[13]Li JT,Liu YH,Hao Y.The improvement and application of a K-means clustering algorithm[C].IEEE International Conference on Cloud Computing and Big Data Analysis.IEEE,2016,3(10):93-96.
[14]Peura RA.Blood glucose sensors:an overview[J]. IEEE,2014,5(2):63-68.
[15]Qi L,Yuan J.Development of the Portable Blood Glucose Meter for Self-monitoring of Blood Glucose[C].Engineering in Medicine and Biology Society,2005.Ieee-Embs 2005.International Conference of the.IEEE,2006,3(5):45-47.
[16]张建辉.K-means聚类算法研究及应用[J].武汉理工大学学报,2014,3(4):17-22.
[17]周世兵,徐振源.K-means算法最佳聚类数确定方法[J].计算机应用,2010,7(8):10-11.
[18]吴夙慧,成颖.K-means算法研究综述[J].现代图书情报技术,2011,6(5):23-25.
[19]王千,王成.K-means聚类算法研究综述[J].电子设计工程,2012,4(7):19-22.
Analysis for monitoring data of type 2 diabetes mellitus based on K-means algorithm
WEI Zhe, LV Ke-nan, WANG Neng-cai// China Medical Equipment,2016,13(11):13-16.
Objective: To analyze the monitoring data of type 2 diabetes mellitus based on K-means algorithm to avoid noise and interference signals in glycemic measurement and get experimental data applicable to Gray Relational Method. Methods: We use the data of a patient who named Mr. Li from the information department of one tertiary referral hospital in Lanzhou which includes course note of disease and his health record. And we use K-means algorithm to process and analyze his glycemic data in 60 minutes to remove error data point. Results: We can get Mr. Li’s necessary and undisturbed experimental data in 60 minutes. Conclusion: K-means algorithm holds a higher efficiency in removing noise and interference signals to obtain highquality experimental data, in order to process and analyze.
Blood glucose monitoring; Data processing; K-means analysis; Gray relational method
韦哲,男,(1963- ),博士,高级工程师。兰州军区兰州总医院信息科,从事医疗仪器及医疗信息系统的研究及教学工作。
1672-8270(2016)11-0013-04
R587.1
A
10.3969/J.ISSN.1672-8270.2016.11.005
①兰州军区兰州总医院信息科 甘肃 兰州 730050
②兰州理工大学电信学院 甘肃 兰州 730050
2016-05-18
猜你喜欢
卫星应用(2022年7期)2022-09-05 02:36:02
卫星应用(2022年3期)2022-05-23 13:44:30
卫星应用(2022年1期)2022-03-09 06:22:20
环球慈善(2019年6期)2019-09-25 09:06:24
保健医苑(2018年9期)2019-01-10 02:23:24
爱你(2018年20期)2018-07-12 07:07:42
爱你·健康读本(2018年7期)2018-05-14 08:53:25
电子测试(2017年15期)2017-12-18 07:19:27
特别健康(2017年4期)2017-03-12 01:33:13
智能系统学报(2015年4期)2015-12-27 09:38:39
