
百亿级话单存储查询系统设计与实现
2016-12-06 12:16:48欧阳秀平李婷婷陈荣添朱旭明
电脑与电信 2016年6期
欧阳秀平 李婷婷 陈荣添 朱旭明
(中国联通广东省分公司,广东 广州 510627)
百亿级话单存储查询系统设计与实现
欧阳秀平李婷婷陈荣添朱旭明
(中国联通广东省分公司,广东广州510627)
随着广东联通市场规模的扩大,产品与技术的不断发展,业务数据量呈现指数级增长,客户对话单详单查询的要求越来越高,对海量数据的高效插入和读取变得越来越重要。面对上百亿条话单记录,如何保证查询的高效性、高可靠性、高可用性成为了首要科研课题。本文提出利用HBase技术可在廉价服务器上搭建起大规模结构化存储集群,而且查询速率可以达到秒级。
话单查询;HBase;高效性;高可靠性
1 引言
随着广东联通业务量的不断发展以及运营商间市场竞争日益激烈,客户对话单详单查询要求也越来越高,查询方式也日益丰富。为支持客户通过营业厅、自助终端机、互联网终端及移动智能终端等方式随时随地进行详单查询,迫切需要建立一个支持高并发、查询响应快速、支持长期历史数据查询的详单查询系统,提升详单查询的服务能力,提高客户满意度。本文以短信话单为例子,广东联通全省的短信量一天就达到2~6亿条,尤其是月初,会有大量的SP短信下发,短信存储周期为三个月,如何在将近300亿条短信记录中快速查询并且得到快速响应成了首要问题。原系统采用RMDBS技术,随着广东联通用户量的不断增长,虽然点对点短信有逐年下降的趋势,但是SP短信数据量却是在节节攀升。原系统在此时已经不能满足快速查询响应的需求,导致影响客服人员处理投诉时的效率。在此背景下,广东联通实现了采用HBase分布式列式存储数据库为核心的短信话单存储查询系统,在百亿条话单记录中查询能达到秒级的效应,大大提高了查询效率,为客服人员解决客户投诉问题带来了巨大的便利。
2 研究背景
2.1HBase简介
HBase是分布式、面向列的存储系统,提供实时读写和随机访问海量数据集。最基本的单位是列Column,一列或多列形成一行,并由唯一的行键Rowkey来确定存储。一个表中有若干行,其中每列可能有多个版本,默认版本号是在单元格插入时由HBase自动分配的时间戳Time Stamp。一行由若干列组成,若干列又构成一个列簇ColumnFamily,常见的引用列的格式为family:qualifier,qualifer是任意的字节数组。
2.2系统架构
广东联通短信存储查询系统是采用基于Hadoop的 HBase分布式列式数据库实现的,该系统由Client(客户端)、Zookeeper(协调系统)、Master(管理者)和Region Server(存储数据)四个角色组成,广东联通短信存储查询系统架构图如图1所示。

图1 短信存储查询系统总体架构图
系统共6台x86服务器,由三台Zookeeper服务器组成Zookeeper cluster,四台Region server服务器组成Region server cluster,一台服务器可同时担任Zookeeper角色和Region server角色,一台作为Master,一台作为Client。Client包含访问HBase的接口,维护一些cache比如Region的位置信息等,可以加快对HBase的访问。Zookeeper存储了所有Region的寻址入口,可以实时监控Region Server的状态,将Region Server的实时动态消息通知Master。Master为Region Server分配Region,负责Region Server的负载均衡。Region Server维护Master分配给它的Region,处理Region的I/O请求。
短信话单数据导入到HBase集群后,HBase中所有的数据文件都存储在Hadoop HDFS文件系统上,以HFile的格式进行存储,HFile是HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,StoreFile是对HFile做了轻量级的包装,即StoreFile底层就是HFile。
短信记录查询时,HBase Client端连接Zookeeper Qurom,通过Zookeeper组建Client获得管理-ROOT-Region的Server,Client访问管理-ROOT-的Server,-ROOT-表存储了-META表的Region索引,在-META-中记录了HBase所有表信息,从而获得Region这一行的信息。短信记录定位的算法流程如图2所示。

图2 短信记录查询定位算法流程
3 系统实现
3.1话单数据入库
HBase数据入库有三种方式:(1)生成HFile方式,使用bulkload导入工具生成HFile的过程比较慢,生成HFile后写入HBase非常快,基本上就是HDFS上的mv过程,但是适合初次入库;(2)MapReduce方式,开始会很快,但是由于Mapreduce和HBase竞争资源,到一个特定的时间点会变很慢;(3)JavaAPI方式,多客户端,多线程同时入库,目前看来是最好的方式,Client和RegionServer分开,硬盘读写分开,瓶颈只在网络和内存上,但是只提供API,易用性是短板。
本系统采用Java API的入库方式,Java的API方式是采用Put进行入库,但是该方式每添加一条记录默认就会调用一次RPC,影响入库效率。于是将HTable的setAutoFlush设置成false,使其支持客户端批量更新,用Scanner来控制一次性缓存量,当Put填完客户端再一次性调用RPC发送到服务端,并且修改WAL方式,将wirteToWAL设置成false提高了部分性能。在大量数据入库时往往会因为触发compaction而影响入库效率,我们经过优化将major_compaction修改成闲时触发,而不是在入库时触发compaction,大大提高了入库效率。
此测试是为了研究多线程导入速率与线程数的关系,因此只是将数据导入同一个表,测试程序中每个线程分别读取一个本地文件,同时写入一个表中,结果见表1。
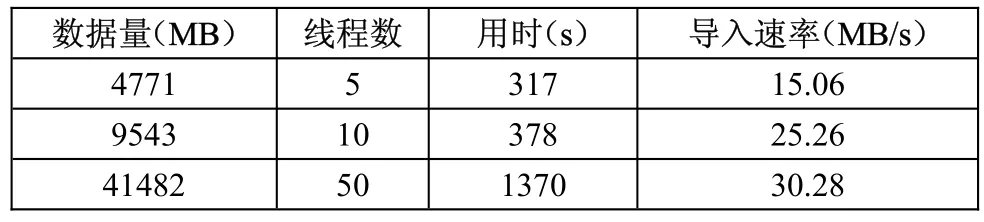
表1 线程数与导入速率的关系
可见,增加线程数可以在一定程度上提高导入速率。本系统最后采用单客户端同时启动10个线程导入方式。
3.2存储表结构设计
HBase是以表的形式存储数据,最基本的单位是列(Column),一列或多列形成一行(Row),若干列又构成一个列簇(ColumnFamily),并且由唯一的行健(RowKey)来确定存储,一个ColumnFamily的所有列存储在同一个HFile里。库表结构设计得好与否直接影响到系统的查询性能,最关键是库表的Rowkey的设计,HBase的Table每一行存在一个唯一的Rowkey,并且是按照字典序列进行排列,Rowkey的设计如下所示:
RowKey=PhoneNumber+Time+Random
PhoneNumber是用户的手机号或者SP端口号,Time是指该条话单记录的时间,Random是五位随机数,由于SP会在同一时间内发送大量记录,为了确保RowKey的唯一性,所以加入了5为Random数。
在逻辑上,HBase的表数据按照Rowkey进行字典排序,RowKey实际上是数据表的一级索引(Primary Index),由于HBase本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠Rowkey,为了支持多条件查询,一般的做法是将所有可能作为查询条件的字段拼接到Rowkey字段中,但是无论怎么设计,单一的Rowkey固有的局限性决定了它不可能有效地支持多条件查询。为了同时满足一条话单记录支持主叫号码查询和被叫号码查询,不局限于单一的Rowkey在复杂查询上的局限性,本系统提出了建立二级索引表很好地解决了该问题。
短信分为两种:SP短信和点对点短信,SP短信是指通过SP端口号批量下发给用户的短信,而点对点短信是指两个用户之间互相发送的短信,两种短信记录需要分开,本系统总共涉及4张表,表结构如下所示:
(1)sp信息表
sp(spRowkey,columns:callingNum,columns:calledNum, columns:scCallType,columns:firstDVTime,columns:register-Time,columns:sendOutTime,columns:languageType,columns: retryCount,columns:messageStatus,columns:messageLength)
其中spRowkey是唯一标示符,是由calledNum+register-Time+random组成,callingNum表示主叫号码,calledNum表示被叫号码,scCallType表示呼叫类别,firstDVTime表示首次下发时间,registerTime表示MO时间,sendOutTime表示MT时间,languageType表示编码方案,retryCount表示重发次数,messageStatus表示发送返回状态码,messageLength表示消息长度。
(2)sp索引表
sp_index(spIndexRowkey,columns:spRowkey)
其中spIndexRowkey是唯一标示符,是由callingNum+ registerTime+random组成,而spRowkey即sp信息表的Rowkey,由calledNum+registerTime+random组成。
点对点信息表
sp(p2pRowkey,columns:callingNum,columns:calledNum, columns:scCallType,columns:firstDVTime,columns:register-Time,columns:sendOutTime,columns:languageType,columns: retryCount,columns:messageStatus,columns:messageLength, columns:messageInfo)
其中p2pRowkey是唯一标示符,是由callingNum+registerTime+random组成,callingNum表示主叫号码,calledNum表示被叫号码,scCallType表示呼叫类别,firstDVTime表示首次下发时间,registerTime表示MO时间,sendOutTime表示MT时间,languageType表示编码方案,retryCount表示重发次数,messageStatus表示发送返回状态码,messageLength表示消息长度,messageInfo表示短信内容(经过加密处理)。
(3)点对点索引表
p2p_index(p2pIndexRowkey,columns:p2pRowkey)
其中p2pIndexRowkey是唯一标示符,是由calledNum+ registerTime+random组成,而p2pRowkey即点对点信息表的Rowkey,由callingNum+registerTime+random组成。
3.3查询性能测试
查询情况分为三种情况:只输入主叫号码、只输入被叫号码、既输入主叫又输入被叫。根据查询的需求,结合HBase的Rowkey唯一性,如果只输入被叫号码,直接查询sp表即可,如果只输入主叫号码,则先查询sp_index表找到sp表的Rowkey,再查询sp表。
点对点表结构设计和SP的表结构类似,只是比SP的少了一列短信信息详情,如果只输入主叫号码,直接查询p2p表即可,如果只输入被叫号码,则先查询p2p_index表找到p2p的Rowkey,再查询p2p表。
使用单线程查询客户端,在指定时间范围内的所有HBase表中查询某个指定手机号的所有记录。HBase会按顺序依次查询所有时间范围内符合条件的记录,测试结果见图3,其中横坐标表示天,纵坐标表示查询耗费时间,单位为秒。

图3 单线程查询客户端结果表
4 结论
本文介绍了基于分布式列式数据库HBase的百亿级话单存储查询系统方案设计与实现,该系统不仅提高了话单存储查询系统的查询效率,对百亿级的话单数能够达到秒级的响应,而且还提高了系统的灵活度,HBase提供了横向扩展的能力,可以随时根据业务量的发展情况添加或减少集群的节点,并且不会影响到集群其他节点的正常工作。此外还提高了系统的健壮性和可靠性,HBase集群内部的Balance机制,可以使数据均匀分布在各个节点上,不会出现旧系统的设备存储不均衡的情况。集群的数据有冗余备份,如果某台设备出现宕机,集群的Master节点会将该台设备的数据拷贝到其他节点上进行存储,这种灵活的机制确保了集群数据不丢失。
[1]Jin Y,Deyu T,Yi Z.A distributed storage model for EHR based on HBase[C]//Information Management,Innovation Management and Industrial Engineering(ICIII),2011 International Conference on.IEEE,2011,2:369-372.
[2]Chen Q K,Zhou L.HBase-based storage system for large-scale data in wireless sensor network[J].Journal of Computer Applications,2012,32(7):1920-1923.
[3]Vora M N.Hadoop-HBase for large-scale data[C]//Computer Science and Network Technology(ICCSNT),2011 International Conference on. IEEE,2011,1:601-605.
[4]Franke C,Morin S,Chebotko A,et al.Distributed semantic web data management in HBase and MySQL cluster[C]//Cloud Computing (CLOUD),2011 IEEE International Conference on.IEEE,2011:105-112.
[5]Huang J,Ouyang X,Jose J,et al.High-performance design of hbase with rdma over infiniband[C]//Parallel&Distributed Processing Symposium(IPDPS),2012 IEEE 26th International.IEEE,2012:774-785.
[6]Konishetty V K,Kumar K A,Voruganti K,et al.Implementation and evaluation of scalable data structure over HBase[C]//Proceedings of the International Conference on Advances in Computing,Communications and Informatics.ACM,2012:1010-1018.
[7]Bai J.Feasibility analysis of big log data real time search based on Hbase and ElasticSearch[C]//Natural Computation(ICNC),2013 Ninth International Conference on.IEEE,2013:1166-1170.
[8]Barton S,Dohnal V,Rigaux P.Similarity search in a very large scale using Hadoop and HBase[R].Technical report,CEDRIC-Cnam,2012.
[9]Liu Jun,Li Tingting.Mining And Modeling the Dynamic Patterns of Service Providers in Cellular Data Network based on Big Data Analysis,China Communication,2013,12:25-36.
[10]Li Tingting,Liu Jun.Characterizing Service Providers Traffic of Mobile Internet Services in Cellular Data Network[C]//Intelligent Human-Machine Systems and Cybernetics,2013 5th International Conference on.IEEE,2013,1:134-139.
Design and Implementation of Call Bill Query and Store System in Ten Billion Level
Ouyang XiupingLi TingtingChen RongtianZhu Xuming
(China Unicom Guangdong Branch,Guangzhou 510627,Guangdong)
With the expansion of market size in Guangdong Unicom and the development of products and technology,the amount of business data is exponentially growing.The request of call bills query is higher and higher.The insertion and reading of massive data becomes more and more important.Facing with tens of billions of call records,it has become a major research topic that how to ensure the query efficiency,reliability and availability.This paper uses HBase technology in cheap server to build up large-scale structured storage clusters.The query rates can be in second level.
query HBase;high efficiency;high reliability
TP311.52
A
1008-6609(2016)06-0084-04
欧阳秀平,男,广东人,硕士,工程师,研究方向:移动互联网、大数据、信息化。
猜你喜欢
今日农业(2021年6期)2021-06-09 08:05:06
邯郸学院学报(2020年2期)2020-08-11 09:12:16
小学生学习指导(低年级)(2020年6期)2020-07-25 02:31:36
故事会(蓝版)(2020年1期)2020-01-19 05:53:40
奥秘(创新大赛)(2019年10期)2019-10-24 11:36:38
电子制作(2018年19期)2018-11-14 02:37:08
电信科学(2017年12期)2018-01-08 05:35:46
中国学术期刊文摘(2016年2期)2016-02-13 16:01:41
电测与仪表(2015年7期)2015-04-09 11:40:24
小说月刊(2014年1期)2014-04-23 08:59:54
