
基于通信链路的NoC映射算法*
2016-12-01 03:57金世燕姚远程秦明伟
电子技术应用 2016年8期
金世燕,姚远程,秦明伟
(西南科技大学 信息工程学院 特殊环境机器人技术四川省重点实验室,四川 绵阳621010)
基于通信链路的NoC映射算法*
金世燕,姚远程,秦明伟
(西南科技大学 信息工程学院 特殊环境机器人技术四川省重点实验室,四川 绵阳621010)
片上网络映射算法对系统通信能耗、延时等性能具有重大影响。基于通信链路通信量大小,提出一种改进的多目标遗传映射算法,以降低系统能耗和延时。算法中提出根据通信链路通信量大小决定任务在网络拓扑中映射位置的方式来产生初始染色体,并通过改进的变异操作产生新的子代,有效降低了算法复杂度,加快了算法的收敛速度。实验通过NIRGAM仿真平台进行,结果表明,与传统的多目标遗传算法相比,在实际应用DVOPD中,能耗降低了49.76%,通信延时降低了53.23%;在VOPD实验中,能耗和延时分别降低了 29.54%和32.45%;而MPEG-4的能耗和延时则分别降低了45.72%和49.40%。同样,提出的算法与模拟退火算法相比,能耗和延时性能也有明显提高。
片上网络;映射;多目标遗传算法;通信链路;能耗;延时
0 引言
随着单芯片上集成的IP核数量不断增加,传统总线的通信方式已经不能满足通信的需求,在功耗、可靠性及延迟等方面都面临着非常严峻的挑战[1]。在这种情况下,新型芯片体系架构就成为亟待研究的方向。新型芯片体系架构片上网络(Network on Chip,NoC)[2-3]就在这样的背景下应运而生。通过借鉴计算机网络技术,引入新的体系结构,从根本上克服了片上系统(System on Chip,SoC)总线架构的种种弊端。总体说来,影响NoC性能的因素主要包括网络拓扑结构、路由算法以及应用映射等。本文主要研究NoC的应用映射问题,以减少系统的能量及延时消耗,提高系统性能。
目前,很多文献对NoC映射算法进行了研究,例如,TOSUN S提出了一种映射优化算法[4],该算法将通信频繁的任务映射到物理位置接近的网络节点中,以减少数据包传输的距离,但该算法容易陷入局部最优,而难以得到最优解。陈亦鸥等人针对面向实时复杂系统的片上网络架构及映射技术展开研究[5],提出了面向实时复杂系统的NoC多目标映射模型。文献[6]采用了分支定界法实现NoC的映射。文献[7]提出一个均衡优化时延模型和一种基于Boltzmann-NSGAⅡ的映射算法,时延模型从宏观链路负载和单个节点排队时延进行优化,避免了传统NSGAⅡ算法在解决NoC映射问题时容易出现局部最优和种群多样性的问题。文献[8]采用多目标自适应免疫算法对NoC映射问题进行研究,旨在减少系统延时和能量消耗。文献[9]采用多目标免疫算法作为NoC映射算法,有效降低了系统功耗,提高了可靠性。文献[10]以互连任务之间的通信量作为映射顺序优先级的判定标准,提出一种启发式算法,通信量大的任务先被映射到NoC拓扑中,接着将与已映射任务之间有通信的任务按照通信量大小依次映射至网络拓扑中,直到应用程序中的所有任务都完成映射为止。由于算法每一次迭代都考虑了已映射任务所有邻节点的情况,使得算法复杂度极高,达到了O(n5logn),n为任务数量。
本文在文献[10]的基础上,提出一种基于通信链路的改进映射算法(Improved Mapping Algorithms based on Communication Links,IMACL),IMACL算法通过将通信量较大的任务映射到网络跳数较近的NoC核上,达到减少系统能耗和延时的目的。但与文献[10]中的算法不同,IMACL算法不采用逐个搜索的映射方式,而是通过改进的多目标遗传算法完成映射。实验通过NoC仿真平台NIRGAM进行,结果表明,该算法在能耗和延时方面具有较好的优化效果,并降低了算法复杂度,提高了算法收敛速度。
1 映射问题分析
NoC映射的目的是在满足约束条件(能量、延时最小)的情况下,将给定的任务分配到 NoC处理核上。该过程中使用的一些名词定义如下:
定义1:任务通信图(Task Communication Graph,TCG),图G(T,E)中,ti∈T代表应用中的任务,ei,j∈E代表任务ti与任务 tj之间的通信量。实际应用 VOPD对应的任务图如图1所示。
定义 2:拓扑图(Topology Graph,TG),图 T(P,L)中,pi∈P代表网络拓扑中的处理核,li,j∈L代表核 pi与核pj之间的通信链路。一个 4×4 Mesh结构的拓扑如图2所示。

图1 VOPD任务图
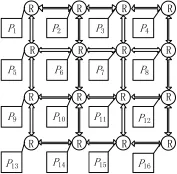
图2 4×4拓扑图
在本文中,优化目标为系统能耗和延时,采用TERRY T Y在文献[11]中提出的能量建模方式:

其中,Ebit表示相邻路由器之间传输 1 bit数据消耗的能量,ESbit、EBbit、EWbit和 ELbit分别代表被处理核消耗的能量、缓存消耗的能量、线路和数据在链路中传输消耗的能量。网络较大时,EBbit和 EWbit可以忽略,因此能耗模型可表示为:


其中,vi,j表示节点 pi与 pj之间的通信量。
延时(D)为系统关键路径(从输入到输出的最长链路)延时,其计算式为:

其中,di,j和 qi,j分别表示从节点 pi到节点 pj的数据传输延时和等待延时。
映射过程中,将能耗和延时作为两个优化目标,即目标函数为:

2 IMACL算法
IMACL算法将TCG中的任务映射到TG处理核上,算法实现过程中,遵循任务与处理核一一对应的原则。IMACL算法的主要思想是将相互之间通信量大的任务映射至路由跳数少的处理核上,以此降低系统的通信能耗和延时。算法以多目标遗传算法为原型,但避免了传统的多目标遗传算法存在的收敛速度慢、易陷入局部最优等缺陷,IMACL算法流程图如图3所示。

图3 IMACL算法流程图
2.1种群初始化
遗传算法的基本单元为染色体,一条染色体代表一种映射方案,传统的遗传算法初始种群都是随机产生一个染色体组,而初始种群的优劣直接影响算法的收敛速度,随机产生的初始种群可能导致算法收敛过慢。因此,IMACL算法初始种群中的染色体按照通信链路的通信量大小来产生,描述如下:
(1)对TCG中的通信链路按照通信量进行排序,找到通信量最大的通信链路 e=(ti,tj),图1中通信量最大的通信链路 e=(t8,t10);
(2)分别计算任务 ti和 tj总的通信量,即与任务节点相邻的通信链路通信量的总和,比较任务 ti和 tj的总通信量,较大的任务即为第一个将被映射的任务,图1中通信总量较大的任务为 t8;
(3)产生一个1~M(处理核对应的编号)之间的随机数p1,将任务ti和tj中总通信量较大的任务(图1中为t8)映射至该处理核;
(4)接下来将最大通信量对应链路(e=(t8,t10))另一端的任务(图1中为 t10)映射至与 p1相邻的处理核 p2上,p2为p1任意一个相邻位置的处理核;
(5)找出剩余任务与已映射任务之间通信量最大的任务,将该任务映射至与已经映射的任务对应的处理核任意一个相邻的处理核上;
(6)如果所有任务都映射完成,则得到了一条可用的染色体,否则返回步骤(5)。设种群大小为N。
2.2遗传操作
传统的多目标遗传算法产生子种群需要进行选择、交叉和变异3个遗传操作,但 IMACL算法仅仅通过选择、变异来获取子种群。其中选择操作目的是保持种群中的优良基因,而变异操作可以增加种群的多样性,但同时也存在使种群产生退化的危险,为了保持种群质量和多样性,IMACL算法让部分个体参与变异,减小种群退化的概率,具体实现步骤如下:
(1)计算初始种群的目标函数,对计算结果进行非支配排序;
(2)将排在后 50%的个体按变异概率 pm(为了避免算法陷入局部最优,变异概率相对传统遗传操作而言取值较大)进行变异操作。随机产生一个变异位置,保持染色体变异位置之前的基因不变,按2.1节中的方式找到下一个待映射的任务 tnext,将任务 tnext映射至新产生的处理核上,直到所有任务映射完成为止;
(3)将父种群与子种群合并,计算新种群的目标函数并进行非支配排序,选择出序值靠前的N条染色体作为新种群,进入下一代进化;
(4)判断是否满足终止条件,若满足,找出最优解,若不满足,返回步骤(2)。
2.3算法复杂度
IMACL算法的主要复杂度体现在初始种群产生、目标函数计算、选择、变异以及非支配排序上。N表示种群大小,M表示染色体长度,产生初始种群的复杂度为O(NM),计算目标函数的复杂度为O(NM2),选择操作的复杂度为 O(N/2),变异的复杂度为O(NM/2),非支配排序的复杂度为O(N2)。所以,IMACL算法的总复杂度为上述各步骤复杂度累积和乘以迭代次数,远远小于O(M5logM),即算法复杂度低于文献[10]中的算法。
3 实验结果及分析
3.1实验结果
针对系统能耗和通信延时两个目标函数,在NIRGAM[12]上进行IMACL算法的仿真实验。NIRGAM是一个离散独立、周期精确的NoC仿真器,它能为 NoC中路由算法的设计和不同拓扑结构下的应用提供大量的技术支持。仿真针对DVOPD、VOPD、MWD和MEPG-4 4种实际应用程序进行,拓扑结构为常见的 2D Mesh结构,采用XY路由算法。实验中,取种群大小N=60,变异概率pm=0.3,最大进化代数max_gen=200,DVOPD的染色体长度(任务数量)M=32,VOPD的染色体长度M=16,MEPG-4和MWD的染色体长度均为M=12。
为了验证IMACL算法的性能,每组实验分别将该算法与传统多目标遗传算法(MOGA)、模拟退火算法(SA)得到的映射方案获得的通信能耗和延时进行对比。4种算法实际应用的通信能耗和延时结果如表1所示,结果比较如图4所示。

图4 实际应用3种算法的实验结果比较

表1 应用实例3种算法的实验结果
由表1和图4可知,IMACL算法与MOGA和SA两种算法相比,通信能耗和延时优化效果均十分明显。相较于MOGA,在DVOPD应用中,系统通信能耗减少了49.76%,通信延时减少了 53.23%;在 VOPD应用中,系统通信能耗减少了29.54%,通信延时减少了 32.45%;对于应用MWD,系统通信能耗和延时分别减少了25.93%和28.38%;在MPEG-4应用中,系统通信能耗减少了45.72%,通信延时减少了 49.40%。而与SA相比,IMACL算法在 DVOPD应用中,系统通信能耗减少了45.93%,通信延时减少了 48.50%;在 VOPD应用中,系统通信能耗减少了 14.40%,通信延时减少了 16.22%;对于应用MWD,系统通信能耗和延时分别减少了4.76%和5.36%;在MPEG-4应用中,系统通信能耗减少了43.43%,通信延时减少了44.36%。
从实验结果可以看出,IMACL算法对于通信链路简单(任务之间通信不频繁)的应用在能耗和延时两方面只有较低的提高,但对于通信链路复杂(任务之间通信频繁)的应用则具有明显的优化效果。
3.2算法收敛性
IMACL算法与其他两种算法相比,在通信能耗和延时上均有很大优化效果,图5为MPEG-4通信能耗的收敛曲线。MPEG-4延时、DVOPD、VOPD以及MWD能耗和延时的收敛曲线与图5相似。

图5 通信能耗收敛曲线
由图5可知,IMACL算法在迭代次数为100时便已进入全局最优,且优化过程中不易陷入局部最优;MOGA算法在迭代次数为50时就进入了局部最优,优化过程中更是多次进入局部最优,而全局最优则是在迭代次数为 350代之后。相比而言,IMACL算法具有极好的收敛性。
4 结论
针对系统通信能耗和延时,本文提出一种基于通信链路的改进映射算法 IMACL解决 NoC映射优化问题。算法遵循通信量大的任务映射至物理位置接近的处理核上的原则,以减少任务相互之间通信消耗的能量和延时,从而有效降低了NoC整个系统的能耗和延时。通过NIRGAM平台的实验结果表明,在实际应用任务DVOPD中,本文提出的算法相较于传统多目标遗传算法的映射优化结果而言,能耗降低了 49.76%,通信延时降低了53.23%。而对于通信链路较为简单的 VOPD应用,能耗仅有29.54%的降低,通信延时降低了32.45%。在MWD应用中,系统通信能耗和延时则分别减少了 25.93%和28.38%。对于应用MPEG-4来说,系统通信能耗和延时分别降低了45.72%和49.40%。与SA相比,IMACL算法在实际应用程序中,能耗与延时性能也具有不同程度的提高。另一方面,IMACL算法降低算法复杂度的同时还具有良好的收敛性。可见本文所提算法对改善NoC映射算法整体性能有着积极意义。
[1]MARCULESCU R,OGRAS U Y,PEH L S,et al.Outstanding research problems in NoC design:system,micro-architecture,and circuit perspectives[J].IEEE Transactions on Computeraided Design of Integrated and Systems,2009,28(1):3-21.
[2]SALEHI M E,MOHAMMADI S,FAKHRAIE S M,et al. Energy/throughput trade-off in a fully asynchronous NoC for GALS-based MPSoC architectures[C].In Proc.5th International Conference on Design and Technology of Integrated Systems in Nanoscale Era(DTIS),Hammamet,Tunisia,2010:1-6.
[3]BOGDAN P,MARCULESCU R.Non-stationary traffic analysis and its implications on multicore platform design[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2011,30(4):508-519.
[4]TOSUN S.New heuristic algorithms for energy aware application mapping and routing on mesh-based NoCs[J]. Journal of Systems Architecture,2011,57(1):69-78.
[5]陈亦鸥.面向实时复杂系统的片上网络架构及映射技术研究[D].成都:电子科技大学,2013.
[6]Zhou Liyang,Jing Ming’e,Zhong Liulin,et al.Taskbinding based branch-and-bound algorithm for NoC mapping[J].Circuits and Systems,2012,3(3):648-651.
[7]易宏波,罗兴国.Boltzmann-NSGAⅡ算法的 NoC映射研究[J].计算机工程,2012,38(22):283-286.
[8]SEPU′LVEDA M J,WANG J C,GOGNIAT G,et al.A multi-objective adaptive immune algorithm for multiapplication NoC mapping[J].Analog Integr.Circ.&Sig. Process,2012,73(3):851-860.
[9]吕兴胜,李光顺,吴俊华.基于多目标免疫算法的 NoC映射优化[J].计算机工程,2015,41(4):316-321.
[10]SAHU P K,MANNA K,SHAN T,et al.A constructive heuristic for application mapping onto mesh based Network-on-Chip[J].Journal of Circuits,Systems,and Computers,2015,24(8):126-155.
[11]TERRY T Y,LUCA B,GIOVANNI D M.Analysis of power consumption on switch fabrics in network routers[C].In Proc.39th annual Design Automation Conference,New Orleans,USA,2002:524-529.
[12]Nirgam(V2.0)[EB/OL].(2013-12-20)[2016-03-08]. http://nirgam.ecs.soton.ac.uk.
An NoC mapping algorithm based on communication links
Jin Shiyan,Yao Yuancheng,Qin Mingwei
(Robot Technology Used for Special Environment Key Laboratory of Sichuan Province,School of Information Engineering,Southwest University of Science and Technology,Mianyang 621010,China)
Network-on-Chip(NoC)mapping algorithm has significant impact on system power consumption,latency and other performances.An improved multi-objective genetic mapping algorithm based on the communication links is proposed to decrease power consumption and latency.The algorithm designs a new chromosome initialization method whose communication links directly decide the positions of tasks in network.And a new mutation operator is used to getting offspring.The new algorithm reduces the complexity effectively and can accelerate the rate of converging.The experiment is implemented on NIRGAM,results show that power consumption and latency on DVOPD decreased 49.76%and 53.23%respectively.Compared with traditional multi-objective genetic algorithm,the result on VOPD can get power consumption 29.54%reduced and latency 32.45%reduced respectively.When come to MPEG-4,power consumption decreased 45.72%and latency decreased 49.40%.Similarly,compared with simulated annealing algorithm,performances of power consumption and latency of the proposed algorithm improved obviously.
Network-on-Chip;mapping;multi-objective genetic algorithm;communication links;power consumption;latency
TN915;TP301
A
10.16157/j.issn.0258-7998.2016.08.030
国防基础科研计划项目(B3120133002);西南科技大学创新团队基金(tdtk02);西南科技大学研究生创新基金(15ycx121)
(2016-03-08)
金世燕(1990-),女,硕士研究生,主要研究方向:片上网络。
姚远程(1962-),男,硕士,教授,主要研究方向:软件无线电。
秦明伟(1979-),男,博士,副教授,主要研究方向:软件无线电、片上网络等。
中文引用格式:金世燕,姚远程,秦明伟.基于通信链路的 NoC映射算法[J].电子技术应用,2016,42(8):121-124.
英文引用格式:Jin Shiyan,Yao Yuancheng,Qin Mingwei.An NoC mapping algorithm based on communication links[J].Application of Electronic Technique,2016,42(8):121-124.
猜你喜欢
移动通信(2021年5期)2021-10-25
自动化仪表(2020年10期)2020-11-13
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
数字通信世界(2017年1期)2017-02-13
火控雷达技术(2016年3期)2016-02-06
船舶力学(2015年6期)2015-12-12
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
中国交通信息化(2014年3期)2014-06-05
汽车维护与修理(2014年10期)2014-02-28
