
基于HTK的连接数字语音识别的研究*
2016-11-30 02:43黄少龙
山西电子技术 2016年5期
黄少龙
(太原理工大学信息工程学院,山西 晋中 030600)
基于HTK的连接数字语音识别的研究*
黄少龙
(太原理工大学信息工程学院,山西 晋中 030600)
HTK是剑桥大学工程系开发的一套基于C语言的语音处理工具包,目前在语音识别、语音合成以及字符序列等领域已得到广泛应用。本文首先简单介绍了语音识别的一些基本原理,接着从HTK的主要原理和软件结构出发,阐述了基于HTK语音识别系统的搭建过程以及每部分用到的工具或函数,最终完成了7字长的连续语音识别系统,并验证了其识别率。
HTK;语音识别;HMM模型;梅尔倒谱系数MFCC
随着科学技术和计算机行业的迅速发展,智能技术也得以快速的发展,语音识别技术作为一种人机交互技术也越来越受到重视。数字语音识别经历了漫长的发展,目前基本趋于成熟,它在电话语音拨号、网站登录以及火车站售票系统等方面都得到了较为广泛的应用。
HTK(Hidden Morkov Model Toolkit)是一种专门用来建立和处理隐马尔可夫模型HMM的工具包,现在主要用于语音识别,最初是由英国剑桥大学工程系的语音视觉和机器人技术工作组开发的,之后经过了剑桥大学、Entropic公司以及Microsoft公司的不断完善和改进,目前已经处于语音识别领域的高端水平。HTK是由一系列库模块构成,工具箱中包含了语音识别阶段所要用到的每个工具,且每个工具都有其对应的输入接口和输出接口,其源代码都是开放的,我们可根据自己的实验需求来进行修改。
本文主要结合隐马尔可夫模型,利用HTK语音识别工具包,实现连接数字语音识别系统的设计。
1 语音识别系统原理
语音识别从本质上来说属于模式识别的一种,是机器通过识别和理解过程把人类的语言信号转换成相应的文本信息或命令的技术,它的目的在于让机器能够听懂人类的语言并执行相应的动作。语音识别根据不同的准则可分为:孤立词识别、连接词识别和连续语音识别;特定人语音识别和非特定人语音识别等。现在被普遍使用的系统有基于DTW和模式匹配技术系统、基于隐马尔可夫模型链HMM 语音识别系统、基于人工神经网络ANN语音识别系统。语音识别系统主要是由特征提取、识别网络、声学模型和识别模块等四部分组成。
特征提取是对语音信号进行预处理,将录制得到的语音波形信号转换为声学特征,如预加重和分帧,然后对每一帧语音数据提取最能够反映语音特征的特征向量,如MFCC系数,LPC系数,LPCC系数等。

图1 语音识别系统的组成
识别网络是在识别过程中用来搜索最佳词序列的一个搜索空间,一般由任务定义、词典和语言模型组成,任务语法主要定义了基本识别单元的网络,我们这里所用的基本识别单元是音素,词典则包含了识别任务中所有用到的单词且定义每一个单词所对应的音节级或音素级的发音。
声学模型是用来描述发音过程的一个数学模块,本次试验中我们使用的是隐马尔可夫模型(HMM)。
识别模块是语音识别系统的核心部分,它是在识别网络中搜索一条最优路径,使得该路径上的模型产生未知声音序列的概率是最大的。
2 基于HTK语音识别系统的搭建
HTK语音识别系统的建立一般分为四个阶段:数据准备阶段、模型训练阶段、识别阶段、结果分析阶段。
2.1 数据准备阶段
数据准备阶段主要完成语料的准备、语音的标注、任务语法和词典的创建、得到真值文件以及语音数据的特征提取等工作。语音识别工作中,所要用到的语料必须具有一定的代表性,尽可能多得覆盖各种语音现象,语料库选择的好坏对最终的识别结果有着很直接的影响。HTK里的HSLab工具可用来进行语音数据的录制和标注,HCopy用于将一个或多个源文件转换成另一个需要的文件输出,在用于参数的提取时,是将每一个语音文件(wav或sig)转换成相应的MFCC文件,这里我们对每帧的语音信号提取39维的梅尔倒谱系数(MFCC)。在HTK中还可以用Per脚本Prompts2mlf来实现将语音文件截成音节级真值文件,用HLEd工具实现将音节级真值文件转换成音素级真值文件,用HParse函数可将创建好的任务语法文件转换成机器能直接使用的词网络。词典可以自己手动创建,也可以通过HDMan函数来创建,HTK里的HList工具可以用来检查语音文件的内容,还可以查看语音文件转换成特征文件的结果,HLEd是一个由脚本驱动的标记编辑器,用于生成系统所需要的录音标记文件*MLF。
2.2 模型训练阶段
模型训练阶段我们主要完成为每个识别单元定义原始的HMM模型以及模型的初始化过程和模型的训练。对语音而言我们一般选取自左向右的无跨越模型。在定义初始模型时,首先需要确定模型的结构,本系统中我们创建5个状态的HMM模型,采用从左向右的拓扑结构(如图2所示),状态2,3,4称为活动状态,状态1和5为开始状态和结束状态,为非发散状态,确定结构之后根据HMM模型的参数定义格式对HMM模型进行原始定义,定义的参数包括特征参数提取的类型、向量的维度、高斯混合密度数、状态数以及每个状态的均值和方差,状态的转移矩阵等。在训练模型之前,为确保训练能够快速且精准收敛,HMM模型的参数必须依照原始的训练数据正确初始化,将所有特征矢量的均值和方差作为原始模型的初始均值和方差,HTK里可通过Hinit或HCompV两个工具来实现模型的初始化。模型的训练就是对模型参数的学习和调整过程,用大量的训练语音调整参数,对参数进行重估,在HTK里使用基于Baum-Welch算法的HERest工具来实现对模型的训练。
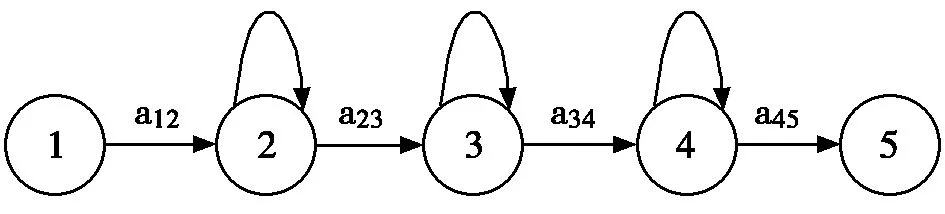
图2 HMM的拓扑结构
2.3 识别阶段
识别阶段为对输入语音进行模式匹配的过程,HTK里提供了语音识别的工具Hvite,其是一种基于Veterbi算法的识别工具,可以用来测试输入观察是否与识别器的马可夫模型相一致。
2.4 结果分析阶段
最后系统的性能分析是由HTK提供的工具HResults来实现,用于分析识别率。最终给出的结果包括词和句子的识别率以及其他信息。该工具通过以下公式来计算识别率:

其中,N为数据集中词的总个数,D为识别结果中删除词的个数,S为识别结果中替换词的个数,I为识别结果中插入词的个数。
3 实验结果及分析
3.1 实验语料库
实验所用的语音库为Tidigits数据库,选取了其中400条7字长的数字串作为训练语句,男女各200条,选取其中100条作为测试语句,男女各50条。所有的数据采样率为20 000Hz,量化精度为16bits。
3.2 实验环境
本文的实验环境如下:Windows7操作系统,CPU为Intel酷睿i5 3230M,主频为2.6GHz,内存为4GB,HTK工具包的版本为3.4.1,visual的版本为2010,Perl脚本编辑器的版本为5.20.2。
3.3 实验结果及分析
图中SENT表示句子,其中有100条测试语料,85条识别正确,识别率为85%;第二行WORD表示单词的识别结果,总共700个单词,D表示删除错误,S表示替换错误,I表示插入错误,词的识别率为99%,识别率比较高。

图3 最终的实验结果
4 结论
本文结合隐马尔可夫模型,利用HTK语音识别工具包,实现了连续数字语音识别系统的搭建。本系统我们采用的是7字长的连续数字识别,识别率比较不错,可用于各种银行卡卡号或各类会员卡号的识别,或者是网站的登录等,未来我们还可以继续研究中英文数字串的识别,同时还可以加入中英文姓名。日后我们将围绕HTK的基本工具,不断改进算法来提高系统的识别率。
[1] 杨嵩.基于HTK的连续汉语数码语音输入系统研究[J].计算机与数字工程,2012,4(40):35-38.
[2] 范会敏,郑峦.基于HTK的语音识别系统设计及实现[J].电脑编程技巧与维护,2015,23(47):95-97.
[3] 涂俊辉,续晋华.基于HTK的连续语音识别系统及其在TIMIT上的实验[J].现代计算机(专业版),2009,319:29-33.
[4] 王鸿儒,杨根科,杨祖华.基于HTK的连续语音识别网站系统的研究与实现[J].微型电脑应用,2010,7(26):19-21.
[5]KuldeepKumar,AnkitaJainandR.K.Aggarwal.AHindispeechrecognitionsystemforconnectedwordsusingHTK[J].ComputationalSystemsEngineering,2012,1:25-32.
[6]SteveYoung,GunnarEvermann,MarkGales,etal.TheHTKBook[J].http//htk.eng.cam.ac.uk
[7] 张雪英.数字语音处理及MATLAB仿真[M].北京:电子工业出版社,2010.
[8] 王炳锡,屈丹,彭煊.实用语音识别基础[M].北京:国防工业出版社,2005.
The Research of Continuous Digital Speech Recognition Based on HTK
Huang Shaolong
(DepartmentofInformationEngineering,TaiyuanUniversityofTechnology,JinzhongShanxi030600,China)
HTK is a set of speech processing tools based on C language developed by the University of Cambridge's engineering department.It has been widely used in the fields of speech recognition,speech synthesis and character sequence at present.This paper first introduces the basic principle of speech recognition,and then expounds the building of speech recognition system based on HTK and the tool or function used in every part from the basic principle and the software structure of HTK.Finally,the recognition system of 7 characters long continuous speech is completed and the recognition rate is verified.
HTK; speech recognition; HMM modeling; Mel-frequency cepstral coefficient
2016-07-06
山西省留学回国择优资助项目(晋人社厅函[2013]68号);山西省自然科学基金(2014021022-6)
黄少龙(1988-),男,山西临汾人,工程硕士,研究方向:信号与信息处理。
1674-4578(2016)05-0086-03
TN912.34
A
猜你喜欢
小太阳画报(2020年11期)2020-12-10
小太阳画报(2020年10期)2020-10-30
计算机工程(2020年3期)2020-03-19
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
中国听力语言康复科学杂志(2019年3期)2019-06-24
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
红领巾·成长(2018年10期)2018-11-19
中国交通信息化(2018年3期)2018-06-13
