
一种软硬件协同控制的片上缓存功耗优化方法
2016-11-30 07:27:46褚廷斌袁正希
电子技术应用 2016年2期
李 嵩,褚廷斌,袁正希
(电子科技大学 通信与信息工程学院,四川 成都 611731)
一种软硬件协同控制的片上缓存功耗优化方法
李嵩,褚廷斌,袁正希
(电子科技大学 通信与信息工程学院,四川 成都 611731)
导读:随着半导体技术和集成电路技术的发展,计算设备的运算性能相比于诞生之初空前提高,但计算设备的能量效率并未得到同步提高。由此而带来的各种问题使得高能效计算成为当前的一个热点研究问题。本期专栏从大量投稿中为大家精选了多篇高能效计算相关的论文,分别从系统架构设计与优化、算法复杂度改进、硬件结构改进等方面对计算设备的能效进行了优化,具有很好的参考价值和借鉴意义。但在征文的过程中我们发现我国的很多研究者对于高能效计算技术缺乏足够的认识,对能效优化的理解仍然比较肤浅。希望此次专栏的出版能让更多的科研工作者了解到能效优化的含义,为我国高能效计算相关技术的发展尽一点绵薄之力。
——本期专题特约主编:黄乐天
片上多处理器系统的发展导致片上高速缓存的所占面积急剧增加,其对应的泄露功耗也相应增加。将高速缓存行划分成3部分进行控制,其中数据部分的访问分为协议访问和数据访问两部分,每部分支持多种工作模式来进行管控。通过工作模式的切换对高速缓存的三部分进行管控可以使漏过功耗平均减少76.78%,但相应的性能损失最高会达到7.74%。由于性能损失较大,提出了一种改进的高速缓存衰退的方法来优化管控策略。这种策略不仅能够把性能损失控制在3%以下,而且能够保证平均能耗优化达到近75%。
片上多处理器;高速缓存;漏过功耗;性能损失
0 引言
近些年来,片上多核处理器已经作为主流的硬件微型结构被广泛应用在通信领域。随着半导体深微技术的发展,晶体管的集成度越来越高,高速缓存占据片上多核处理器面积增加带来的漏过能量的增加也愈加成为一个不可忽视的难题。
为了减小高速缓存漏过能量的消耗,许多采用控制高速缓存供电电压的技术手段被相继提出。门控电压[1]和高速缓存衰变[2]作为其中极具代表性的技术手段得到了广泛的应用。门控电压技术是采用在静态随机存储器单元与地之间接入一个高阈值的控制晶体管的方式来开关控制高速缓存的供电电压。当静态随机存储器单元不工作时,高速缓存的漏过能量就相应被节省下来了。然而这种方式有一个很大的弊端,切断供电电压的同时容易造成数据的丢失,这和电脑突然断电随机存储的数据容易丢失是一样的原理。而文献[3]提出了一种介于开关之间的一种工作模式(睡眠模式)完美地解决了这个问题,同时节省了50%-75%的能耗。另一种技术手段——高速缓存衰变技术,其核心是在高速缓存的每一行设置一个时间监控器,如果缓存行的访问时间高于所设阈值时间,则认为该行将不会被再次访问,因此可以采用门控电压的方式将其关断。
本文也采用门控电压机制。基于高速缓存的数据部分访问分为协议访问和数据访问的前提下,采用这种门控电压的方式对高速缓存块的供电电源进行控制,不仅可以获得能耗上比较理想的优化,同时采用这种方式也不会破坏高速缓存的一致性通信机制。
1 相关研究动态
高速缓存衰变技术是对高速缓存的每个块使用门控电压的硬件控制能源减少机制。文献[2]中,死区时间被定义为一个块最后访问和驱逐之间的时间。高速缓存衰变决定是否一个块是在死区时间是使用一个对相应的数据块驻留在缓存中的时钟周期进行计数的计数器来进行判断。访问高速缓存的每一个数据块时,计数器会被重置。如果计数器的值超过给出的衰变时间间隔,则缓存数据块是在死区时间。那么就可以利用门控电压的方式来切断高速缓存数据块的供电电源。
软件自失效技术[4]可以有效减少漏过能耗。软件自失效适用于门控电压控制自失效技术[5-6]的概念。自失效技术是为维持在多处理器环境中的缓存一致性而设计的。上面提到的引用基于一个至关重要的事实那就是无效块并没有有效的数据。因此,可以从能耗角度关闭数据块的供电电源。另一方面,基于预测的自失效技术置本地缓存副本于无效可以在无效消息接收到之前就能有效地切断无效数据块的供电电源从而保证高速缓存的一致性。
休眠高速缓存[3]提出了一种新的工作模式。每次访问缓存行时,缓存控制器通过检测缓存休眠位来控制高速缓存的供电电压。如果访问的缓存行是在正常工作模式下,可以读取缓存行的数据内容而不会损失任何性能。其没有性能处罚是因为通过检测休眠位来检查缓存行电源模式和读取、比较标记位的行为是并行发生的行为。然而,如果内存数组是在休眠的模式下,需要防止内存数组的位线放电,因为它可能会读出不正确的数据。为了解决这个问题,缓存行在下一个周期会自动唤醒,即缓存行工作在正常模式下。所以在唤醒期间可以访问缓存行的数据。
前面提出的软件自失效技术虽然可以有效地减少漏过能耗,但采用门控电压的技术来开关数据块的供电电源会导致数据的丢失,从而导致性能上的较大损失。然而采用文献[3]中提出的技术手段可以很好地避免这个问题,同时也可以一定程度上减少漏过能耗。所以本文也采用这种技术手段来节省缓存的能耗。
2 研究动机
为了确定漏过能量的优化空间,分别对协议访问和数据访问的访问量作一个统计,统计结果如图1所示。在统计过程中,通过对 SimpleScalar 3.0[7]仿真器进行修改来获得最后一级高速缓存中协议访问和数据访问的情况。其中具体的参数设置如表1所示。
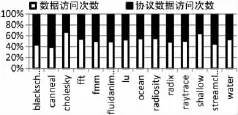
图1 协议访问和数据访问的比例
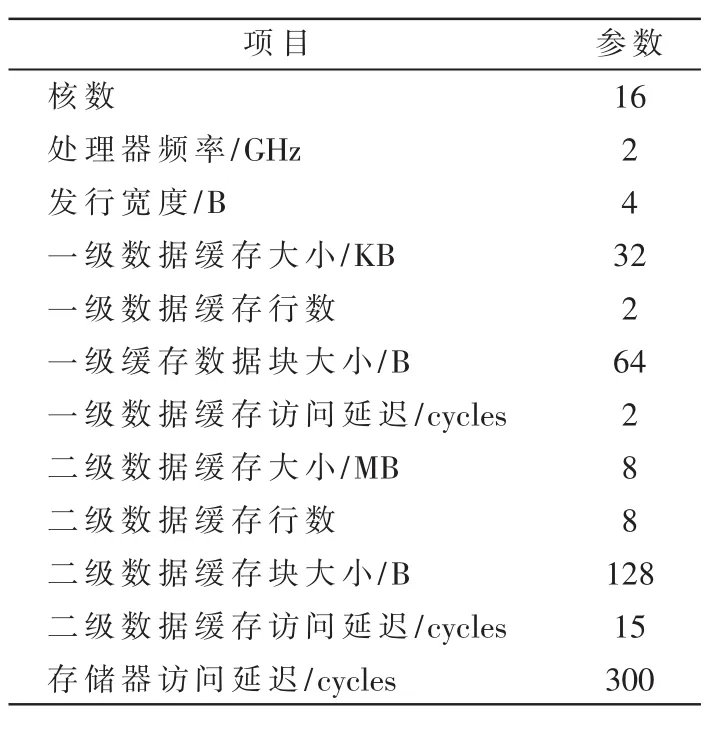
表1 仿真器的配置参数
通过 6个 PARSEC[8]的应用程序和 8个 SPLASH2[9]的应用程序来对仿真器进行测试。本次仿真的时间直到执行完一亿条指令才截止,仿真结果如图1所示。
如图1所示,水平轴是14个不同的测试应用程序,用于测试和验证本文的假设。垂直轴是两个不同的缓存数据块被(协议块和数据块)访问的比例。结果表明,协议访问接近一半的缓存访问。由于协议访问不会进行数据的读写,若是协议访问,那么可以通过切断该数据块供电电源来达到节省能耗的目的。但是会造成当前保存在数据块中的数据大量丢失,从而进一步导致应用程序访问最后一级缓存行时产生丢失。在此情况下,程序会访问主存从而产生非常大的延迟。所以这种方法会对仿真器的性能造成很大的影响。然而,如果采用文献[3]中提出的控制方案就不会出现这个问题。因此,本设计采用休眠的方式对数据块进行控制。另一方面,数据块从睡眠模式唤醒,只需要几个周期的时间消耗[10]。这意味着,这种休眠方式并不会带来性能上的较大损失。另一个原因仅仅睡眠数据块而不是整个缓存行,那是由于程序每次访问缓存行时都要并行比较缓存行的标记数组位,若休眠标志位将会引起频繁的唤醒,从而带来额外的性能损失。除此之外,标记数组位和数据块相比只消耗轻微的能量,因此它可以工作在正常模式下。
3 软硬件协同控制方案
3.1硬件设计方案
为了控制最后一级高速缓存块的供电电压,使用标记数组中的有效位(图2中用V表示)来开关控制相应的数据块供电电源。该有效位能够表示缓存行数据是否可用。如图2所示,有效位直接连接到相应的门控电压。如果有效位是逻辑1,表示该数据快数据可以被访问,因此相应的数据块供电电源被接通为关闭。如果它是逻辑0,表示数据块中的数据不可用,此时数据块被悬空。当有效位为逻辑1时,此时缓存数据块将分为两部分(协议数据快和数据块)来进行控制。两部分数据块将工作在图3所示的两种模式中,模式的切换由A位控制,A位标识数据块访问的类型。
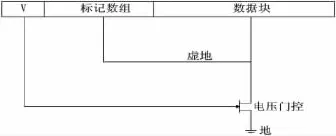
图2 电压门控技术
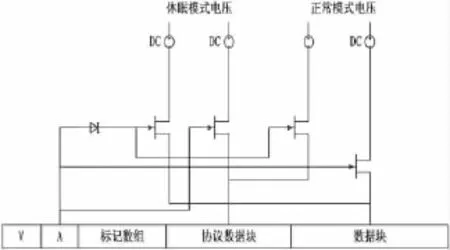
图3 数据块工作模式
如图3所示,电压切换是通过A位来实现的。如果只有协议数据访问,就将A置为逻辑1或者逻辑 0。在本设计中置为逻辑0。
在硬件中执行这种机制时,标记数组的工作电源既没有被切断也没有在低电压休眠模式,有两个方面的考虑。其一是如果标记数组总是工作在正常的电压,可以在多处理器环境中避免缓存相干问题,而且其能耗和数据块相比是非常小的。其二是程序对标记数组的访问更加频繁,频繁的唤醒和开关对系统的性能会有很大的影响。
3.2软件层控制方案
研究发现,性能退化的主要原因是缓存数据块频繁从休眠模式中唤醒。因此提出一种改进的高速缓存衰退的方法在软件控制层面优化本设计从而达到减小性能损失的目的。在软件层方面,测试程序的平均访问时间间隔被设置为睡眠时间间隔。具体算法流程如图4所示。如果前后两次休眠的时间间隔比设置的休眠时间阈值小,认为唤醒代价太大,数据块将工作在正常的电压,反之唤醒的代价较小,此时它将在睡眠模式下工作。
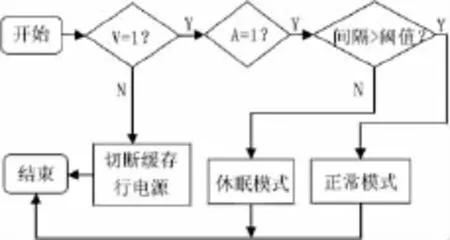
图4 两种工作模式的切换算法流程
4 仿真结果
通过修改Simple Scalar仿真器对提出的硬件设计方案做了性能上的仿真统计,仿真器相关配置参数如前表1所示。此外,使用惠普实验室提出的能耗统计工具Cacti6.0[11]来获得最后一级高速缓存的泄漏能耗。测试程序集为8个SPLASH2的测试程序和6个PARSEC的测试程序。对比对象均为未经修改的仿真器。仿真结果如图5~图8所示,其中未加入软件控制的系统能耗优化和性能损失情况如图5和图6所示,加入软件控制之后的仿真结果如图7和图8所示。
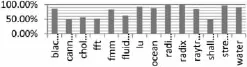
图5 未加入软件控制能效优化统计
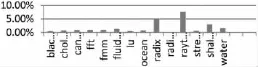
图6 未加入软件控制的系统性能损失

图7 加入了软件控制能效优化统计
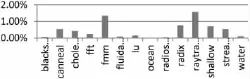
图8 加入了软件控制的系统性能损失
从以上仿真结果不难看出,单一的硬件控制方案可以很大程度上节约系统的能耗,然而性能上的损失是比较严重的,其中raytrace更是达到了5%以上。然而加入了软件控制方案之后,系统的性能损失得到了很明显的改善,均降低到了2%一下,同时系统的能耗优化较之前只减少了2%,这个是可以接受的。
5 小结
在此研究中,目标是减少协议访问情况下的漏过能量消耗。统计发现近一半是协议访问,基于此提出了一种基于门控电压技术的硬件设计。使用了14个测试程序集来对修改后的仿真器进行性能和功耗评估。统计结果表明,能耗比正常情况减少了76.78%,但不可忽略的是系统的性能损失非常严重。继而提出了一种改善的高速缓存衰退策略的软件层次控制算法。仿真结果表明,性能损失得到了很好的改善。未来的工作是要更加细化设定的休眠间隔阈值使性能损失更小,从而完善整个设计。
[1]POWELL M,YANG S H,FALSAFI B,et al.Gated-Vdd:a circuit technique to reduce leakage in deep-submicron cache memories[C].Proc.of ISLPED,2000:90-95.
[2]KAXIRAS S,HU Z,MARTONOSI M.Cache decay:exploiting generational behavior to reduce cache leakage power[C]. Proc.of 28th ISCA,2001:240-251.
[3]FLAUTNER K,KIM N S,MARTIN S,et al.Drowsy caches:simple techniques for reducing leakage power[C].Proc.of Computer Architecture 2002.Proceedings.29thAnnual International Symposium on,2002:148-157.
[4]TANAKA K,FUJITA T.Leakage energy reduction in cache memory by software self-invalidation[C].Proc.of 12th Asia-Pacific Computer Systems Architecture Conference(AC-SAC),Springer,2007:163-174.
[5]LEBECK A R,WOOD D A.Dynamic self-invalidation:reducing coherence overhead in shared-memory multiprocessors[C].Proc.of ISCA,1995:48-59.
[6]LAI A C,FALSAFI B.Selective,accurate and timely selfinvalidation using last-touch prediction[C].Proc.of ISCA,2000:139-l48.
[7]BURGER D,AUSTIN T,BENNETT S.Evaluating future microprocessors:the simplescalar toolset[R].Tech Report CSTR-96-1308,Univ.of Wisconsin,CS Dept.,1996.
[8]PRINCETON P.Princeton application reposity for sharedmemory computers(PARSEC)[EB/OL].http://parsec.cs. princeton.edu/.
[9]WOO S C,OHARA M,TORRIE E,et al.The SPLASH-2 programs:characterization and methodological considerations[C]. In Proceedings of the 22nd International Symposium on Computer Architecture,1995:24-36.
[10]Wang Yue,ROY S,RANGANATHAN N.Run-time powergating in caches of GPUs for leakage energy savings[C]. Proc.of Design,Automation&Test in Europe Conference &Exhibition,2012:300-303.
[11]MURALIMANOHAR N,BALASUBRAMONIAN R,JOUPPIN. CACTI 6.0:an intergrated cache timing power and area model[M].Hewlett Packard Labs,2009.
A power optimization method of cache-on-chip with software-hardware co-control
Li Song,Chu Tingbin,Yuan Zhengxi
(School of Communication and Information Engineering,University of Electronic Science and Technology of China,Chengdu 611731,China)
The development of on-chip multiprocessor systems leads to sharp increase in the area of on-chip cache,and its corresponding leakage power has also increased.Cache line in this article are divided into 3 parts to control while the data access section is divided into metadata access and data access in two parts,each supports a variety of modes to control.The operating mode switching to control the cache into three parts enables us to reduce leakage power consumption on average by 76.78%,but the loss of the performance is up to 7.74%.Due to the large loss of performance,this paper describes an improved method of cache decay to optimize control strategies.This strategy not only losses below 3%performance but also ensures optimization of average energy consumption to nearly 75%.
on-chip multiprocessor;cache;leakage energy;performance degradation
TN431
A
10.16157/j.issn.0258-7998.2016.02.001
2015-12-15)
李嵩(1991-),男,硕士研究生,主要研究方向:片上多处理器高速缓存功耗优化策略。
褚廷斌(1990-),男,工程师,主要研究方向:片上多处理器功耗管控与优化策略,片上多处理器行为级建模与仿真。
袁正希(1962-),男,研究员,主要研究方向:通信集成电路与系统。
中文引用格式:李嵩,褚廷斌,袁正希.一种软硬件协同控制的片上缓存功耗优化方法[J].电子技术应用,2016,42 (2):6-8,13.
英文引用格式:Li Song,Chu Tingbin,Yuan Zhengxi.A power optimization method of cache-on-chip with software-hardware cocontrol[J].Application of Electronic Technique,2016,42(2):6-8,13.
猜你喜欢
昆钢科技(2022年2期)2022-07-08 06:36:14
江西教育·职教版(2022年9期)2022-04-29 00:44:03
当代水产(2021年10期)2022-01-12 06:20:28
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
建材发展导向(2021年23期)2021-03-08 01:05:38
中国电业与能源(2020年7期)2020-08-18 11:08:12
今日农业(2019年15期)2019-01-03 12:11:33
华人时刊(2018年15期)2018-11-10 03:25:26
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
风能(2015年5期)2015-02-27 10:14:47
