
有限理性条件下决策品质的提升策略研究
2016-11-28 02:07魏静
统计与决策 2016年20期
魏静
(天津科技大学应用文理学院,天津300457)
有限理性条件下决策品质的提升策略研究
魏静
(天津科技大学应用文理学院,天津300457)
文章针对有限理性决策问题,以一套仿真数据实验流程测试三种决策方法的有效性,给予偏好效用函数不同的参数设定模拟有限理性决策者排序的差异。结果显示:PLP法与AHP法通过互动的方式能较v IKOR法的排序更为准确地提供符合有限理性决策者偏好的方案。互动方法中的PLP法又较AHP法更好,原因在于其互动次数远较AHP法要少。v IKOR法因难以提供符合有限理性决策者的理想排序,不适合排序方案。
有限理性决策、PLP法、AHP法、v IKOR法
0 引言
有限理性决策者在进行多准则决策(MCDM)时,可能会受到各种不同的效应影响。再加上目前帕雷多可视化技术所受到的限制,MCDM有限理性决策者无法快速且有效地表达偏好。因此有限理性决策者往往需要与分析者或使用决策软件进行多次互动,通过不断的互动以找出有限理性决策者的真正偏好。但高级管理者受时间与成本的限制,需要在资源有限的情况下进行决策,多数决策属于有限理性决策。决策者在进行决策时,多半不喜欢重复互动式的启发偏好决策。多次互动行为或许可以用来确保周延性、完整的诱导决策者表达其偏好,但也可能引起有限理性决策者的负面情绪,这可能会使有限理性决策者无法专注于当下的问题,影响偏好的呈现。且互动式方法是否真的较其他MCDM方法更符合有限理性决策者偏好,仍有待商榷。再加上有限理性决策者在过量的信息与有限时间的压力下进行决策,会产生认知偏误。因此目前发展处多种准则方法,希望能减低管理者的决策时间并增加决策的品质,但又无法确定这些MCDM方法同互动方法的结果是否一致,其信度及效度难以验证。评选MCDM时面对众多方案,该使用哪种方法较为可信且有效,目前尚无定论。因此本文通过不同的样本组合进行重复试验,比较PLP法、VIKOR法及AHP法间的决策差异。
1 多准则决策实验方法设计
本文以三种MCDM方法:PLP法、VIKOR法及AHP法进行模拟实验,并搭配三种有限理性决策者偏好效用函数,计算MCDM方法评的最佳方案,作为有限理性条件下的决策评估的依据。本文以R X64 3.1.0为主要工具。MCDM方法中的PLP法、VIKOR法及AHP法分别适用于R X64 3.1.0中的pcr套件、ahp程序及MCDM套件中的vik程序,采用上述套件进行运算。
1.1 VIKOR法
VIKOR法步骤如下:
②计算Si和Ri

③计算Qi
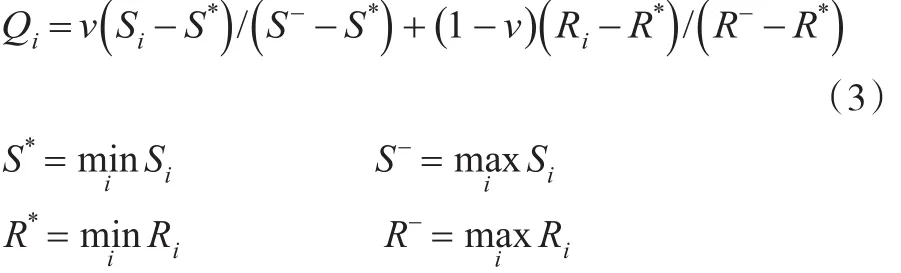
v为决策机制系数在VIKOR中将v设定为0.5,以同时追求群体效用最大化和个别遗憾最小化。
④根据Qi、Si和Ri的大小进行排序
⑤若同时符合下列两个条件,则Qi值最小的方案(A(1))为最佳解。
条件一:可接受的优势

A(2)为Qi第二小的方案,A(1)与A(2)间的差大于门槛值,表示A(1)显著地优于A(2)。
条件二:可接受的稳定性,A(1)的Si或(和)Ri必须优于其他方案。
⑥若无法同时达成两个条件,则形成一组可行方案,依下述判断法则:
条件二未达成时,A(1)与A(2)都为最佳方案。
条件一未达成时,以式(3)为判断标准检验所有方案,通过者都为最佳方案。
VIKOR在参数设定部分,将决策机制系数设定为0.5,以同时追求群体效用最大化和个别遗憾最小化。而由于在本文的实验中,有限理性决策者的偏好是固定的,即权重固定,因此假定偏好一致且已知。故本实验将原本步骤5与步骤6的优势与稳定条件省略,改以直接使用Qi值得大小进行排序,Qi值越小越好,最小者为最佳解。
1.2 PLP法
PLP方法的步骤如下:
①建立集合X与集合Q,集合X包含潜在最佳解,集合Q最初为空集合,用来收集所有被排除方案y。
Q={y|决策者偏好Xr胜于y}
②选择或确定一个参考点,最初参考点的选择为所有方案的线性最大值者。将现在参考方案从集合X中移除。
③每次迭代开始前,必须先对集合X内的所有方案解下列线性规划问题,找到使各方案拥有与参考方案最大差异值得权重组合,且该组权重组合使集合Q内所有方案的线性规划解都为非正值。
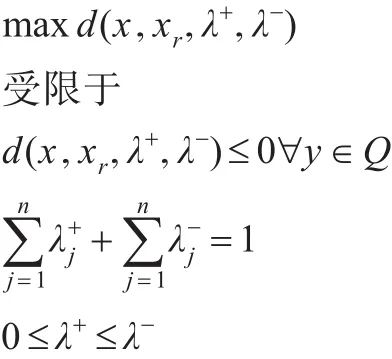
④所有集合X内线性规划解为负值将被从集合内移除,若集合X为空集,则参考方案为最佳解,否则参考方案Xr需与邻近解进行两两比较。邻近解的选择为线性规划值最大者。若决策者较偏好邻近解超过参考方案,则使其为新的参考方案,并更新集合X与集合Q。
⑤重复步骤1到步骤4,直至集合X为空集合。
PLP法中所需两两比较的部分,由相对应的决策者偏好效用函数取代。PLP方法的虚拟程序码如下:
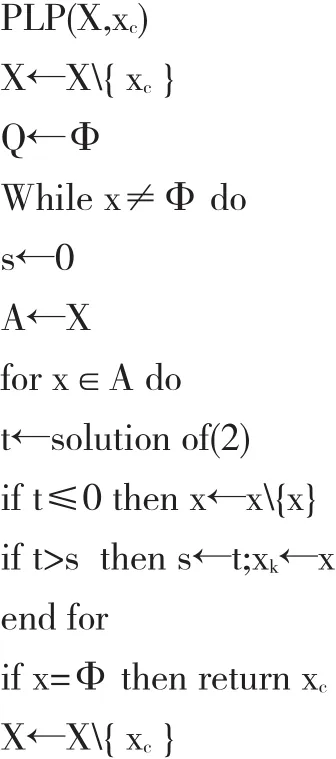

为求得PLP方法对方案的所有排序,本文在逐次进行实验时,将最佳方案选出后从备选方案集合中移除,并对剩余的方案再次进行求解过程,直至备选集合为空集合为止。也就是说在首次PLP方法中选出并排除的方案为最佳,第二次选出方案次佳,并以此类推。
1.3 AHP法
AHP方法的步骤如下:
①建立评估属性和各属性下不同方案的成对比较矩阵
由于本研究为模拟实验,因此省略将决策问题的评估结构化与建立层级结构的过程,直接以生成的数据建立成对比较矩阵。a12为方案1和方案2的比较,本文以相对应的有限理性决策者偏好效用函数值带入计算,求得成对比较矩阵。因此需要进行的成对比较。

a12为方案1与方案2的比较,本文以相对应的有限理性决策者偏好效用函数值带入计算,求得成对比较矩阵。当被评估的指标有m个时,需要进行次的成对比较。就研究而言,方案数为10,因此每次的AHP方法都需要45次的成对比较。
②计算各属性的相对权重和各方案的相对评估值
本文采用行向量平均值标准化法求取向量值:

③根据特征值大小进行排序
由特征值大小进行排序,特征值最大者为最佳方案,依次排序。
在实验方法与效用函数间,差异最小者为PLP法,次小者为AHP法,最大者为VIKOR法。在三种方法中,PLP法与AHP法都为互动式方法,导入有限理性决策者偏好效用函数,因此较能准确掌握有限理性决策者的偏好,使其排序与最优决策较为相符。
2 有限理性决策者偏好效用函数设计
在本文中,PLP方法需要有限理性决策者的偏好作为两两比较的选择依据。以及本文为目的为找出在不同有限理性决策者偏好效用函数下,MCDM方法是否都能准确找到有限理性决策者所希望的答案,因此为能模拟有限理性决策者的偏好,Chebycheff效用函数(CHEBYCHEFF)表示非补偿性的有限理性决策者行为,即由加权后表现最差的属性决定该方案的优劣。观点理论的效用函数(PROSPECT)认为,当有限理性决策者为风险规避者时,会对已拥有的事物持较高的评价,因此往往不愿将其出售或舍弃。反之,风险追求者则较愿意追求更好的事物。

表1列出实验方法在两个有限理性决策者偏好效用函数下不同情境的表现,四个效用函数分别为CHEBUYCHEFF和PROSPECT,在PROSPECT下设立不同的P值借以表示不同的风险偏好。P值为1表示风险中立,无特殊偏好,无论获益或损失都不影响其对方案的看法;P值为0.5代表风险爱好者,较重视获益胜于损失,因此降低对损失的权重;P值为2则为风险规避者,当遇到既有方案与参考方案比较时,会叫重视既有方案的损失而非参考方案的获益。

表1 实验方法在各有限理性决策者偏好效用函数的比较表
更进一步在PROSPECT下设立不同参考点的情境,分别为maX、min和medium,maX表示在效用函数计算时,取各准则的最大值作为参考方案,以获得对方案损失或获益的评价。反之,min则取各准则的最小值作为参考方案。由于在最初生成方案时,准则都是介于0到1间的随机数,因此取其中间数0.5作为参考方案及参考方案的个准则值都为0.5,是为medium。在P=1的情况下,不会因参考方案对权重产生影响,因此予以省略。
3 实验数据选择与结果分析
本文设计以Lahdelma(2003)为基础,实验数据生成的部分包含的变量包含方案数、准则数及分配方式,在加上权重分配以及是否为有限理性决策集合,共五个变量。实验方法考虑有限理性决策者偏好效用函数和多准则决策方法,总共四个因变量在R X64 3.1.0上进行25次的模拟实验。表2列出本实验的所有操作性变量和控制性变量。
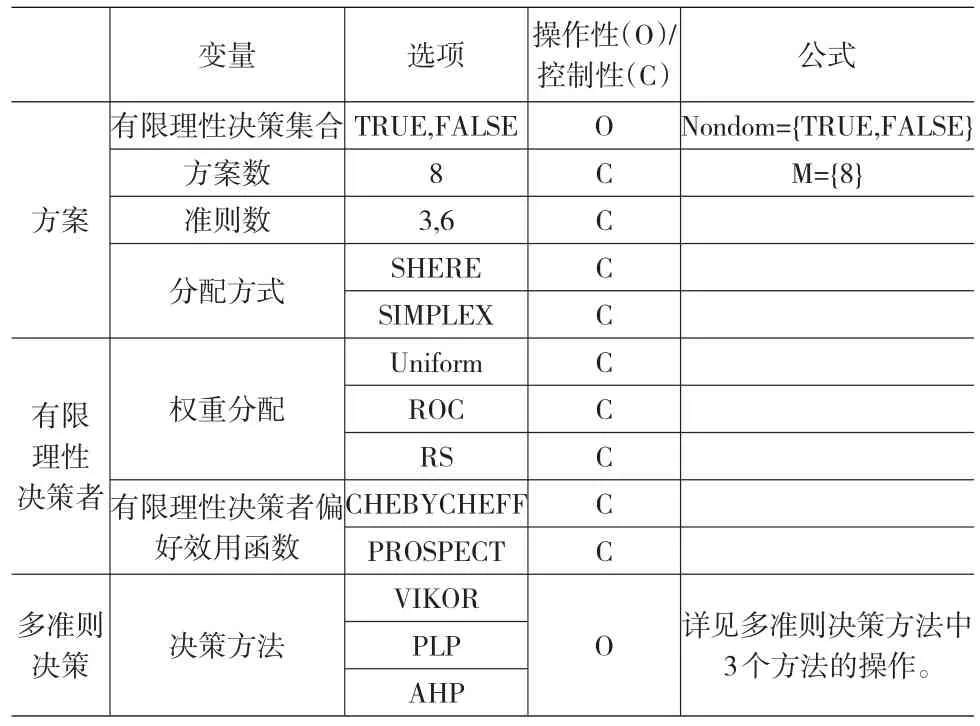
表2 操作性变量与控制性变量列表
本文设计的实验数据包含准则数和分配方式两个控制变量。并针对每种样本进行25次重复实验,生成的资料范围为两个准则数和两种分配方式。方案数(m)固定为8组方案集合,准则数(n)分成3个准则和6个准则,分配方式(d)可分为SPHERE球面分配和SIMPLEX简单分配。
Sphere_X(n)为SPHERE球面分配的生成方式,其虚拟程序代码如下:

SIMPLEX简单分配在生成资料的部分与SPHERE球面分配大致相同,虽然SIMPLEX法也可使用拒绝法,但在高维度下效率不明显,随机生成一组符合限制式的N为资料并将其降幂排列,任意两个连续数值间差异具有密度函数f(xj)=n(1-xj)n-1将其两两间的差视为一笔资料,并进行有效性的判定。Simple_X(n)为SIMPLEX简单分配的方式,以虚拟程序码的方式呈现如下:

在效用函数部分,除了VIKOR外,CHEBYCHEEF在各实验方法中都为最小值,可以推测当有限理性决策者的偏好诶线性时,PLP法与AHP最能反映有限理性决策者的决策。本文以表3来解释。为去掉实验方法与有限理性决策者偏好效用函数间的关联程度与差异是否显着,本文以Kendall's检定作为验证。
表3中的tau值表示相关程度,p则是双尾时的p值表示其差异的显著程度。从实验方法来看,AHP对CHEBYCHEEF的tau值为-1,表示当有限理性决策者偏好为CHEBYCHEEF时,使用AHP法会得到完全相反的结果。本文推估是因为CHEBYCHEEF的公式带有负号以及AHP法的两两比较所导致,造成其方法排序会完全与效用函数的排序相反。以p值来看,两者其实是完全负相关的,因此有限理性决策者偏好为CHEBYCHEEF时使用AHP法需特别注意。PLP法虽然在PROSPECT与CHEBYCHEFF尚不完全相等,但其p值小于0.05,表示具显著的一致性。由于PROSPECT仍是以线性为基础,仅多了对权重的调整,因此其差距为次小者。PROSPECT和CHEBYCHEEF两种效用函数的差值较大,代表当有限理性决策者的偏好为这两个函数时,不适合使用VIKOR法作为工具。
表3为25次重复实验的平均值,并非代表所有样本都未通过Kendall's检定。在本文获得的80530笔资料中,共有20520笔数据的p值大于0.05,表示其与有限理性决策者偏好效用函数具有显著差异。表4为p值大于0.05的20520笔资料在各个变量表现的情形:

表3 Kendall’s检定结果表

表4 显著差异样本在各变量的比例表(单位:%)
从表4中可看出,在生成方案与权重的部分其比重差异不大,主要差异来自偏好效用函数中的PROSPECT函数,以及实验方法中的VIKOR法上。表示这两者可能在排序上的特性容易导致显著差异。因此当有限理性决策者的偏好为PROSPECT时应特别注意选用的方法,而VIKOR法可能不适用于排序方案。PLP法与AHP法虽然都为互动法,但在互动次数与反映有限理性决策者偏好的准确度上仍有差异。由于PLP法的过程中内含CHEBYCHEEF函数,因此其在CHEBYCHEEF时可以完全反映有限理性决策者的偏好,但在采用其他偏好效用函数时则会产生偏差,虽然以整体而言仍具有显著的一致性,但却不保证PLP法排序出的最佳方案即是有限理性决策者的理想方案。反之,AHP则无内含的函数,不同偏好的效用函数都可完整的带入其中,因此在PROSPECT、CHEBYCHEFF时都具有显著一致性。不过AHP法虽可一次将所有方法进行排序,但无论样本型态,因此本文的方案数为8,每次的AHP方法都需要25次的成对比较。反之,PLP法在样本不为有限理性决策集合时,仅需一次互动就可获得最佳解,若为有限理性决策集合,则平均为4.43次的两两比较。
4 结论
本文通过30次的重复实验,比较有限理性决策者偏好效用函数与MCDM方法间排序的差异,以及不同样本模型对实验结果的影响,提出以下结论:
(1)有限理性决策问题有效解集合时较结构化问题有效解集合时的平均绝对差值来得大,是因为有限理性决策问题内的方案较无明显优劣差异,因此造成实验方法的排序较为困难,易与有限理性决策偏好函数产生差异。
(2)PLP法与AHP法通过互动的方式能较VIKOR法的排序更为准确地提供符合有限理性决策者偏好的方案。因此本文认为交互式方法的确能提供有限理性决策者较好的排序。互动方法中的PLP法又较AHP法更好,原因在于其互动次数远较AHP法来得少。虽然因其方法的关系,内含CHEBYCHEFF函数的基础,但在各偏好效用函数上仍具有显著一致性,可以充分表达各种偏好的排序。
(3)除交互式方法外,当有限理性决策者偏好为PROSPECT时须特别注意选用方法,本文的三种方法在PROSPECT函数时,产生的平均绝对差值较大,表示这些方法都较无法充分表达有限理性决策者的偏好并加以排序。
(4)以本文而言VIKOR法较不适用于排序方案、筛选最佳方案,因为与三种有限理性决策者偏好效用函数的平均绝对差值都最大,且不具有显著的一致性。
[1]Anderson R M,Clemen R Toward an Improved Methodology to Construct and Reconcile Decision Analytic Preference Judgments[J].Decision Analysis,2013(10).
[2]董坚,陈春芳.温磊基于等级偏好占优关联系数的群决策模型[J].统计与决策,2015,(05).
[3]卢剑峰.混合多属性群决策理想点方法[J].统计与决策,2014,(19). [4]李春好,苏航,佟轶杰.孙永河基于理想决策单元参照求解策略的DEA交叉效率评价模型[J].中国管理科学,2015,(02).
[5]李光旭,彭怡.寇纲不确定幂加权几何平均算子的动态多目标决策[J].系统工程理论与实践,2015,(07).
(责任编辑/易永生)
C931
A
1002-6487(2016)20-0057-04
天津市教委高等学校人文社会科学研究项目(20132421)
魏静(1983—),女,天津人,硕士,讲师,研究方向:企业管理、财务管理。
猜你喜欢
英语文摘(2021年12期)2021-12-31
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
当代陕西(2018年9期)2018-08-29
铜仁学院学报(2018年6期)2018-07-05
决策与信息(2017年6期)2017-06-10
经济研究导刊(2016年30期)2016-12-24
软科学(2014年8期)2015-01-20
