
舰船噪声环境下改进语音信号增强算法
2016-11-23 13:46李大卫杨日杰韩建辉
西安电子科技大学学报 2016年5期
李大卫,杨日杰,韩建辉
(海军航空工程学院电子信息工程系,山东烟台 264001)
舰船噪声环境下改进语音信号增强算法
李大卫,杨日杰,韩建辉
(海军航空工程学院电子信息工程系,山东烟台 264001)
谱减法广泛应用于语音增强,但在舰船噪声环境下,噪声的复杂多样性给谱减法中信号的语音段与噪声段的正确检测带来极大的困难,影响了谱减法的效果,为此,笔者在分析信号频谱特性的基础上,首先通过分帧信号相邻帧间频谱的相似性测度对信号段粗判断,再利用帧间偏移方法进行精确判断,实现语音段与背景噪声段的精确辨别,进而利用谱减法实现舰船噪声环境下语音信号的增强.经过大量实测数据的验证,改进的谱减法能够适应多种类型舰船噪声环境下的语音增强,对语音段的判别准确度达到96%,对背景噪声的判别准确度达98%.与传统谱减法及其他相关改进算法相比,在低信噪比强背景噪声下,文中改进谱减法仍能取得稳定的语音增强效果.
语音增强;谱减法;频谱相似性;语音段检测;帧间偏移
随着海洋经济效益的提高,舰船环境下语音交流和通讯越来越频繁,但舰船自身各种设备工作时的巨大噪声,严重干扰了工作者的正常交流和通讯,很多情况下,强烈的噪声直接将语音掩盖,给本就恶劣的工作环境带来更多不适,为此,需要研究一种合适的方法在复杂多变的舰船强背景噪声下对语音进行增强.
谱减法自Steven Boll提出后,被广泛地应用于语音增强,其核心是利用无声段信号功率谱来近似估计干扰噪声的谱期望值,然后直接从含噪语音段的功率谱中减去噪声功率谱的期望值.因此,正确分离出源信号中的语音段和无语音的噪声段,是谱减法实现语音降噪增强的关键.为此,许多学者提出了各种语音段和噪声段的检测分离方法,包括时域和频域特征处理方法,如基于短时能量[1],线性预测编码(Linear Predictive Coding,LPC)参数分析与谱散度[2],倒谱分析与频带方差[3],多重线性回归分析[4]及修正调制谱估计[5-6]等.
这些方法虽然取得一定的效果,但对舰船噪声这种特殊噪声环境,遇到了以下困难:首先,舰船种类繁多且状态多变,从舰型、工况到航次,覆盖范围极广,噪声各不相同,同一类别舰船噪声特征可千差万别,背景噪声的复杂多变,给语音段的正确检测带来困难;其次,舰船设备工作时噪声巨大,可完全淹没语音信号,同时,语音信号本身随着说话人的年龄和性别等特征而差异很大.
为解决谱减法遇到的困难,笔者将算法改进的重点放在原始含噪信号的语音段与无语音的背景噪声段的检测上,通过提高分离的精度和准确度,解决谱减法在舰船背景噪声下遇到的困难.改进谱减法首先利用分帧信号相邻帧间频谱的相似度(Similarity of the Frequency Spectral Distribution between adjacent frames,SFSD)及其方差(Vsfsd)对信号段进行粗判别,再通过噪声片段向过度片段的帧偏移将检测的精度进一步提高,实现噪声段的精确判别,然后利用改进的谱减法实现舰船环境下语音信号的降噪增强.经大量实测数据的实验验证,改进的谱减法能够适应不同类型舰船不同工况下的噪声环境,能够克服背景噪声和语音的多变复杂性,在强背景噪声信噪比下仍能取得较好的增强效果.
1 信号频谱特征分析
舰船辐射噪声与语音信号本身都为复杂多变的信号,无论从线谱、连续谱特征角度,还是从梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)、LPC特征角度进行两种信号的分离,特征都出现较大的重叠.为此,笔者从信号发声机理角度探索两种信号的特征差异,借助频谱相似性实现信号的分离.
尽管不同类型不同工况的舰船,其噪声之间复杂多变,但不论何种类型的舰船,其噪声主要由机械运动、舰载设备的运行等影响产生,因而,舰船的形状、工况等都会成为其噪声特性的决定性因素[7-8],而根据舰船运行实际情况,这些决定因素在一个较短时间内,比如一秒钟的时间间隔会保持在一个较稳定状态,这使得其噪声特性也会表现出较好的短时稳定性,表现在频谱分布上即为短时频谱变化趋势保持一致,如图1(a)所示情况,两条曲线为相邻两帧噪声数据的频谱曲线,可以看出,曲线变化趋势基本相同.
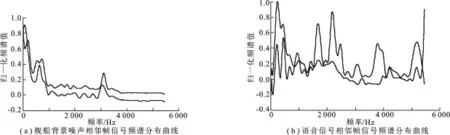
图1 相邻两帧信号的频谱分布曲线
图1(b)为语音信号相邻两帧信号频谱曲线,从图中看出,两条曲线表现出很大的不同.语音中有意义的最小单元是单词,单词由音素组成.所谓音素,是指语言发出各种声音的最小单位,每个音素都有其独立的各不相同的发音方法和发音部位,形成各自的频谱分布特征,从而使不同的单词也有各自的频谱特征.一段语音信号中会选择各种不同单词来表达内容,这样每个单词中包含的不同音素会使语音信号的短时频谱分布出现较大的变化,这形成图1(b)中语音信号短时频谱分布不稳定的特性.
综上所述,在较短时间内语音与背景噪声信号的相邻帧间频谱分布不同,这种差异可用短时频谱分布相似性(SFSD)来衡量,语音信号短时频谱分布变化较大,其帧间相似度较小,而背景噪声相似度较大.为了精确描述频谱分布的差异,文中采用相似度测量值的方差(Vsfsd)作为辨别特征,特征差异明显.
2 基于频谱相似性的改进谱减法
语音段与噪声段的正确检测,是文中算法的核心.首先,对时域信号分帧,并计算每帧信号频谱趋势;然后,以若干帧为一个片段,计算片段内的SFSD值;最后,计算一个片段内的Vsfsd值,作为期间分离特征.
由于Vsfsd的计算是在一个片段内的时间内,故算法的检测分离精度只能精确到一个片段的时间长度.为此,文中在确定过渡片段的基础上,通过帧偏移的方法将最终的期间分离精度提高到信号帧的时间长度.
2.1计算频谱分布趋势
实际信号难免受到各种噪声的污染,直接表现在信号频谱分布中出现较多的瞬时突变,直接使用频谱分布曲线计算相似度,会严重影响辨别结果的鲁棒性.为此,算法中使用频谱分布曲线的趋势来计算相似度.
对于待识别信号的频谱分布曲线趋势,用一组序号分别为w=1,2,…,N的N个邻接的滤波器进行滤波,再作平方积分、归一化为1 Hz分贝值处理,得到每帧信号的频谱估计值f(w).

其中,f(w)′为位置标准化后的频谱值.于是有f(w)′≥0.然后,进一步得到归一化的频谱值为


2.2提取期间分离特征
信号的语音段和无语音段的分离特征基于频谱分布的短时相似性测量,这里使用基于概率密度函数测量的式(3)来计算相似性.
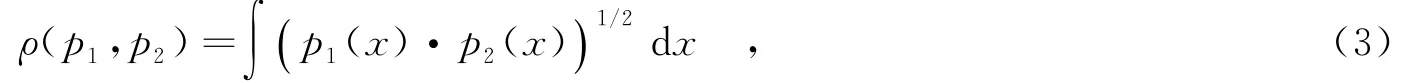
其中,p1(x),p2(x)为两帧信号.

其中,w=1,2,…,N,其定义同式(1)中w的定义.根据方差定义,可计算片段内的SFSD方差.

图2 语音信号与背景噪声信号的Vsfsd值分布图
图2所示为计算得到的语音段与无语音段的Vsfsd值分布,语音数据取720 s,背景噪声数据取255 s,可以看出,Vsfsd值分布有明显的分界,可以作为含噪语音信号语音段与无语音段的检测特征.
2.3过渡片段判别与帧间偏移
过渡片段与帧偏移都是为了提高信号语音段与噪声段的分离精度,可以将检测精度提高到一个信号帧的时间长度.因为当当前片段既含有语音段又含有无语音噪声段时,其Vsfsd值会判断为语音段,所以当t0+1片段与t0-1片段为不同的类型,而当前片段t0为语音片段时,则当前片段t0判定为过渡片段.
帧偏移操作在过渡片段与其最近的无语音噪声片段之间,如图3所示.噪声片段Seg t0+1向过渡片段Seg t0偏移一帧,形成新的片段Seg tk+1,重新计算新片段的Vsfsd值,并进行判断.如果仍为无语音的噪声片段,则继续再偏移一帧,直到当偏移第k+1帧时,新片段Seg tk+1+1被判断为语音片段,则第k帧信号与k+1帧信号为语音与噪声的精确分离帧,这样,通过帧间偏移实现语音段与噪声段的精确判别.

图3 帧偏移方法示意图
3 实验验证及分析
实验中采用不同类别的舰船背景噪声数据100 min,不同的说话人和录制环境的语音数据100 min,实际舰艇背景噪声环境下语音数据100 min,所有数据采样率均为44.1 k Hz,采用海泰HTPXI1008数据采集设备搭配麦克风录制,舰船背景噪声数据及噪声环境下语音数据借助南海试验和演习录制,包括多艘船舶及多位工作人员语音,纯净语音数据为实验室环境下录制,并结合文献[9-11]中的部分数据.
3.1信号帧长确定实验
由于算法以帧间频谱相似性差异为出发点,故频谱分辨率越高越好.频谱分辨率计算公式为

其中,fs为采样率,N为信号帧时长.当fs一定时,N越长Δf越高,算法的分离效果越好,但由于信号的非平稳非高斯性,帧过长将影响到算法的稳定.图4为不同帧长平均Vsfsd的分布,图中采用50帧的时间片段计算Vsfsd,并对结果归一化.可以看出,N在15 ms、20 ms、25 ms和30 ms时,分离效果明显,而自30 ms以后,出现较大的振荡,分离效果不稳定,结合实际应用,文中采用20 ms的信号帧长.
3.2信号段与噪声段检测实验
图5为三次实验结果.图5(a)所示实验采用不同类型及工况下的舰船背景噪声数据,主要验证算法对不同类型不同工况下舰船背景噪声的适用性和判别效果;图5(b)所示实验全部采用语音信号,包括几个年龄段的男声、女声,主要验证算法对语音信号的判别效果;图5 (c)所示试验采用语音信号与噪声信号随机组合后的数据,验证算法的最终检测效果.从图中可以看出,算法取得了较好的检测效果.
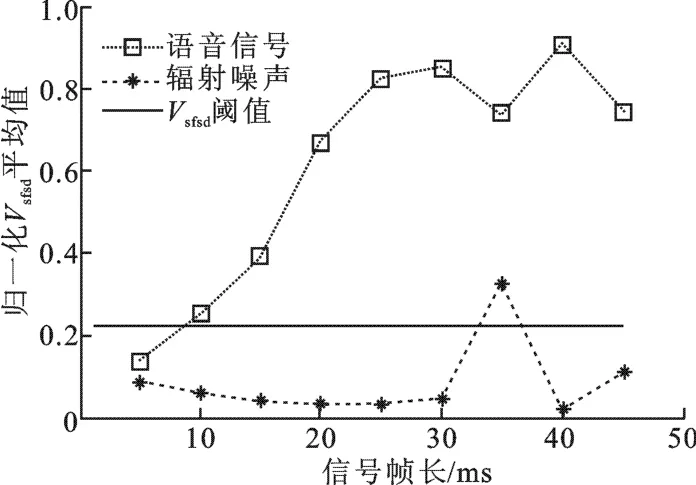
图4 信号不同分帧长度下平均Vsfsd分布情况

图5 语音段与噪声段检测实验结果
文中进一步通过计算正确检测的信号时长与实验使用的总信号时长的比值来衡量算法判别的效果,即

对所有实测信号数据处理后,背景噪声信号判别精度为98%,语音信号为96%.经分析,语音信号精度相对低是因为其中含有静音帧,一些静音帧被判别为背景噪声,但这并不影响实际的语音增强工作.
3.3改进谱减法语音增强试验
为了对比文中算法与传统谱减法及其他改进谱减法[2,5]在强背景噪声下的语音增强效果,实验中按式(7)以不同的分段信噪比将纯净语音信号与背景舰船噪声信号混合.图6为混合过程,将实验室录制的纯净语音按随机间隔与背景舰船辐射噪声混合,混合分段信噪比仅计算有语音段的部分,利用文中改进谱减法及其他改进的谱减法对混合后信号进行语音增强处理.如图6第4幅子图所示,方框内信号视为正确检测的信号,而其他位置的信号则视为非正确语音信号,根据式(6)分别计算正确语音信号和非正确语音信号占原始语音信号时长的百分比.

图6 语音信号与辐射噪声混合示意图

图7 不同分段信噪比下检测正确率
分段信噪比计算方法为
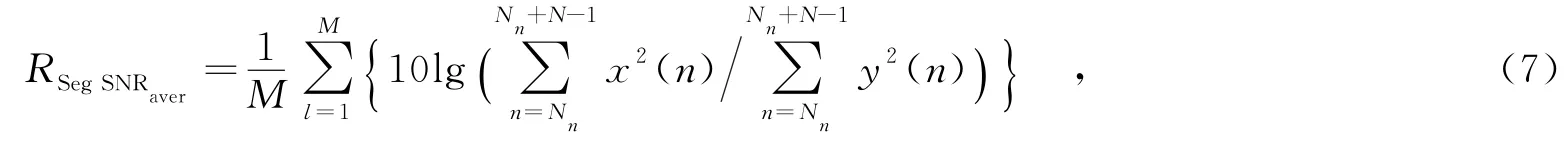
其中,M为语音段数,N为一段语音信号的长度,Nn为一段语音信号的起始点,x(n)为语音信号,y(n)为舰船辐射噪声等背景噪声.将式(7)所计算的分段信噪比约束在[-15 dB,35 dB]的范围内,过高和过低的信噪比对主观的语音质量没有贡献.图7为在不同的分段信噪比下对语音信号检测结果.可以看出,文中方法在小于-5 d B的低信噪比下仍能保持稳定的检测准确性.
为了进一步比较文中提出的改进算法对语音信号的增强效果,采用对数谱失真测度(Log Spectral Distortion,LSD)对增强后的正确语音信号与原始语音信号进行对数谱失真测度,并与其他谱减法进行比较,比较结果如表1所示.谱失真测度与主观语音质量的相关度较高[2-13].测度计算值越小,说明增强后语音信号和原始语音信号越接近,即主观的语音质量越好.其中最常用的方法为LSD,其计算式为


表1 对数谱失真测度LSD结果
表1为以驱逐舰噪声和登陆舰噪声为实验背景噪声,混合分段信噪比为-5 dB、0 dB、5 dB和10 dB时的对数谱失真测度LSD测试结果.分析表1,对于分段噪声比较高的情况下如10 d B以上,文中谱减法与其他[2,5]改进谱减法都得到较好的对数谱失真测度测试结果,但随着分段信噪比的下降,其他改进算法的LSD测试值迅速变化,当为-5 dB及以下时,其LSD测试值已变得很大且不稳定,而文中谱减法仍可以保持较稳定的测试值.分析其主要原因是其他改进谱减法将背景舰船噪声的处理方式与普通噪声处理方式一样,并没有很好地利用舰船噪声本身的频谱特征,故当信噪比较低时,对背景噪声和语音信号的检测出现较多的不准确结果,导致增强效果不理想.通过对比分析可见,文中算法在强背景辐射噪声下仍能取得较好的语音增强效果.
4 总 结
在分析语音信号与舰船背景噪声信号频谱特性的基础上,笔者提出了一种基于频谱分布相似性的改进谱减法语音增强方法,算法以提高信号语音段与背景噪声段的检测精度为核心,解决谱减法用于舰船背景噪声下语音增强遇到的困难,实验结果验证了文中算法对不同舰船背景噪声下的语音信号增强的有效性.尽管语音信号增强后“音乐噪声”不可避免的存在,但语音段和无语音段的正确分割,是强背景噪声下语音信号增强的关键,在此基础上,算法可以进一步结合不同的语音增强算法对当前算法进行完善.
[1]张君昌,刘海鹏,樊养余.一种自适应时移与阈值的DCT语音增强算法[J].西安电子科技大学学报,2014,41(6): 155-159. ZHANG Junchang,LIU Haipeng,FAN Yangyu.Speech Enhancement Method Using Self-adaptive Time-shift and Threshold Discrete Cosine Transform[J].Journal of Xidian University,2014,41(6):155-159.
[2]RAMIREZ J,SEGURA J C,BENITEZ C,et al.Efficient Voice Activity Detection Algorithms Using Long-term Speech Information[J].Speech Communication,2004,42(3/4):271-287.
[3]MCCOWAN I,DEAN D,MCLAREN M,et al.The Delta-phase Spectrum with Application to Voice Activity Detection and Speaker Recognition[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(7): 2026-2038.
[4]PARK J,KIM J W,CHANG J H,et al.Estimation of Speech Absence Uncertainty based on Multiple Linear Regression Analysis for Speech Enhancement[J].Applied Acoustics,2015,87:205-211.
[5]MOMENI H,ABUTALEBI H R,TADAION A.Joint Detection and Estimation of Speech Spectral Amplitude Using Noncontinuous Gain Functions[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2015,23(8):1249-1258.
[6]张君昌,张丹,崔力.一种鲁棒自适应阈值的语音端点检测方法[J].西安电子科技大学学报,2015,42(5):115-119. ZHANG Junchang,ZHANG Dan,CUI Li.Robust Adaptive Threshold Speech Endpoint Detection Method[J].Journal of Xidian University,2015,42(5):115-119.
[7]KALAMANI M,VALARMATHY S,KRISHNAMOORTHI M.Speech Enhancement Using Modified Modulation Magnitude Estimation Based Spectral Subtraction Algorithm[J].Arabian Journal for Science and Engineering,2014,39 (12):8965-8978.
[8]ZHANG Y,ZHAO Y X.Real and Imaginary Modulation Spectral Subtraction for Speech Enhancement[J].Speech Communication,2013,55(4):509-522.
[9]BSS Eval:a Toolbox for Performance Measurement in(Blind)Source Separation[EB/OL].[2015-06-12].http://bassdb.gforge.inria.fr/bss_eval.
[10]Singing Voice Separation:Demo Clips[EB/OL].[2015-06-12].http://sites.google.com/site/unvoicedsoundseparation/ mir-1K.
[11]Music Information Retrieval Evaluation eXchange(MIREX)[EB/OL].[2015-06-12].http://www.music-ir.org/mires/ wiki/MIPEX_HOME.
[12]MAK M W,YU H B.A Study of Voice Activity Detection Techniques for NIST Speaker Recognition Evaluations[J]. Computer Speech and Language,2014,28(1):295-313.
[13]HSU C C,LIN T E,CHEN J H,et al.Voice Activity Detection Based on Frequency Modulation of Harmonics[C]// Proceedings of 2013 38th IEEE International Conference on Acoustics,Speech,and Signal Processing.Piscataway: IEEE,2013:6679-6683.
(编辑:李恩科)
Study of speech enhancement in the background of ship-radiated noise
LI Dawei,YANG Rijie,HAN Jianhui
(Dept.of Electronic and Information Engineering,Naval Aeronautical and Astronautical Univ.,Yantai 264001,China)
Spectral subtraction is wildly used in speech enhancement.But it is not always available in the ship working environment because of the fact that it is hard to discriminate the speech duration with the ship noise.So,in this paper,we propose a new approach,which first computes the frequency spectrum similarity and then discriminates the signal segments into speech or noise roughly.And then by the frame shifting method,we achieve a high discrimination precision.Finally,the improved algorithm is benchmarked on a large measured data and experimental results show that the proposed method can be used in various ship-radiated noise environments.The discrimination accuracy is 98%for ship-radiated noise and 96%for speech.
speech enhancement;spectral subtraction;spectrum similarity;speech detection; frame shifting
TN912.35
A
1001-2400(2016)05-0133-06
10.3969/j.issn.1001-2400.2016.05.024
2015-07-05 网络出版时间:2015-12-10
国家自然科学基金资助项目(61271444);“泰山学者”建设工程专项经费资助项目(2011)
李大卫(1983-),男,工程师,海军航空工程学院博士研究生,E-mail:latt68@sina.com.
网络出版地址:http://www.cnki.net/kcms/detail/61.1076.TN.20151210.1529.048.html
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
噪声与振动控制(2022年3期)2022-07-04
现代仪器与医疗(2022年1期)2022-04-19
舰船科学技术(2021年12期)2021-03-29
数学物理学报(2020年3期)2020-07-27
北京航空航天大学学报(2019年9期)2019-10-26
雷达学报(2017年3期)2018-01-19
地震研究(2017年3期)2017-11-06
舰船科学技术(2016年1期)2016-02-27
应用海洋学学报(2015年1期)2015-11-22
