
一种基于声压级分段的数字助听器响度补偿方法研究*
2016-11-21 01:19唐加能王如刚
电子器件 2016年5期
周 锋,唐加能,王如刚
(1.盐城工学院信息工程学院,江苏盐城,224051;2.华侨大学工学院,福建泉州362021)
一种基于声压级分段的数字助听器响度补偿方法研究*
周锋1*,唐加能2,王如刚1
(1.盐城工学院信息工程学院,江苏盐城,224051;2.华侨大学工学院,福建泉州362021)
响度补偿技术是数字助听器的核心技术之一,目前大多数响度补偿算法均是笼统地通过低、中、高三段输入声压级来进行补偿增益值的计算的,这通常并不符合听力损失患者的实际需要。为此,针对传统三段补偿算法补偿效果的不足,提出了一种基于声压级分段的非等宽多通道响度补偿算法。实验仿真结果显示,该算法比传统的三段补偿算法更好的补偿了患者所需的听力损失,显著提升了患者的言语辨识率,且很好的消除了助听器内部噪声对患者正常使用造成的影响。
声压级;响度补偿;多通道滤波器组;数字助听器
响度补偿技术是数字助听器中最重要的功能之一,其目的在于补偿听力损伤患者缺失的语音信息,以提高患者对于语音内容的理解[1]。目前,对于数字助听器响度补偿方法的研究主要都集中在多通道的划分上。多通道的频带划分虽然能够在一定程度上使得患者可以在不同频段内获得不同的增益补偿,但是其在具体进行响度补偿时,多是笼统地通过低、中、高三段输入声压级来进行补偿增益值的计算的[2],而患者对不同声压级的声音所需要的补偿值并不只是需要三段来补偿。例如:在使用助听器的过程中,麦克风和放大器等助听器的内部组件会产生较大的内部噪声,当在安静环境时,这种噪声有时候可以被患者听见,特别是那些有好的低频听力的患者,这会导致患者对语音的可懂度、辨识率以及舒适度的下降。因此,传统的低、中、高三段补偿是不符合听损患者的实际情况的。
基于上述原因,本文针对传统三段补偿算法的补偿不足,提出了一种基于声压级分段的多通道响度补偿算法,通过将声压级细化为八段,每段根据患者的实际需要进行不一样的补偿,以提高患者的言语辨识率以及舒适度。
1 基于人耳听觉特性的滤波器组设计
由于人耳耳蜗言对声音的感知并不与频率呈线性关系,而是呈一种近似对数的关系,且人耳对声音频率最敏感部分主要集中在低频处,因此在设计滤波器组时需要对低频部分进行细分,而对高频部分进行粗分。根据人耳对不同频段的声音感知能力,我们有:
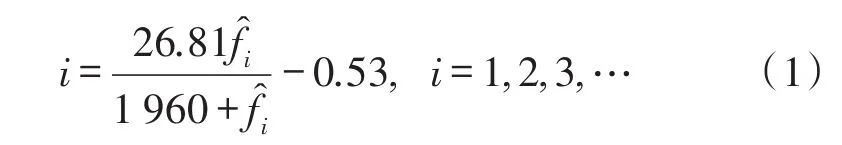
通过式(1)可求得各临界频率,结合常见的11个频率特征点(125 Hz、250 Hz、375 Hz、500 Hz、750 Hz、1 000 Hz、1 500 Hz、2 000 Hz、3 000 Hz、4 000 Hz和6 000 Hz),再根据尽量使划分的通道中心频率值落在频率特征点处和低频划分细、高频划分粗的原则,进一步将100 Hz~8 kHz分为符合人耳听觉特性的16通道[3],如表1所示。

表1 通道划分结果表
根据上述所设计的16通道滤波器组的频带划分,考虑到常用的语音信号的相位对整个语音的可懂度和可听性影响较少[4],且满足条件的IIR滤波器的阶数会比FIR滤波器要少5倍~10倍,所用的存储单元少,运算次数少,这些优点正好是数字助听器所需要的。因此根据实际条件,本文选择使用IIR滤波器来进行16通道滤波器组的设计,滤波器阶数取为6,所得到的滤波器组频响如图1所示。
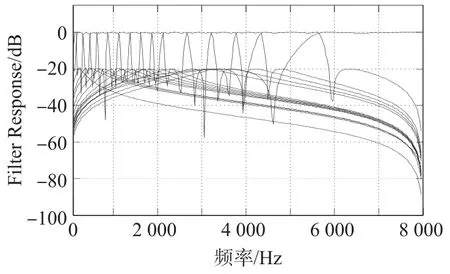
图1 本文设计的16通道滤波器组频响图
2 基于声压级分段的非等宽多通道响度补偿设计
在传统的多通道响度补偿算法设计中,通常是分为低、中、高三段输入声压级来进行增益值的补偿[5,6],而听力损失患者对于不同输入声压级的声音所需要的补偿增益值并不只是需要上述三段来补偿[7-8]。基于此,本文将人耳正常所能接受的0 dB SPL~120 dB SPL的输入声压级进行分段,并且根据“小声多补偿,大声少补偿”以及典型的感音神经性听力损失患者需要的“低频少补偿,高频多补偿”的原则[9-10],同时结合常用的DSL[I/O][11]、FIG6[12]等非线性处方公式,设计得到本文所采用的16通道中任一通道内的处方公式:
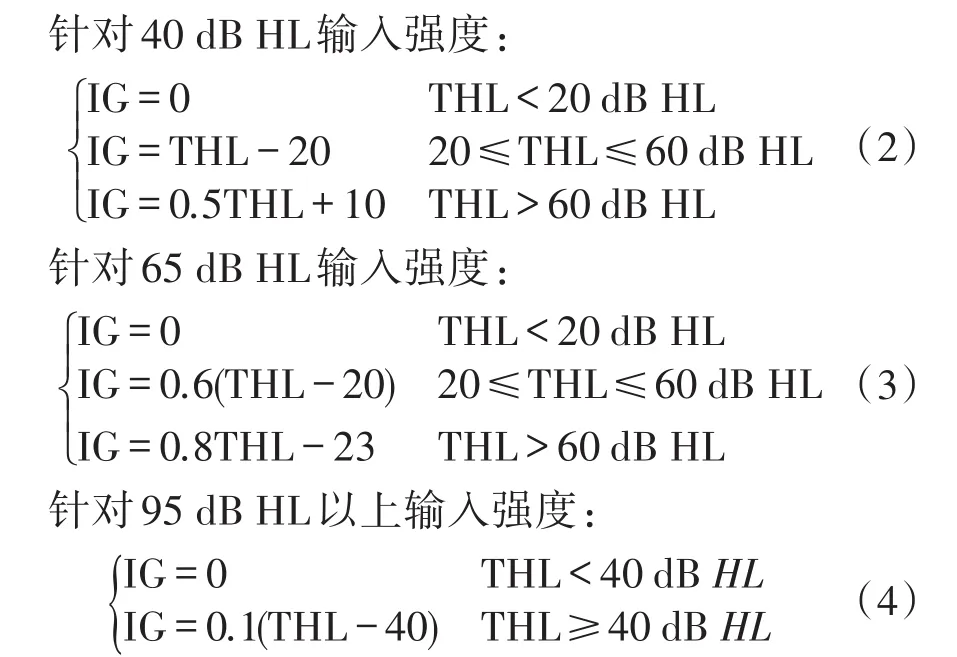
上述各式中,IG表示患者在指定输入声压级下所需的增益值,单位为dB;HL表示当前通道中心频率处患者的听阈值,单位为dB HL,它可以根据患者的听力图通过线性插值得到。
图2为本文所设计的16通道响度补偿算法的整体流程框图。输入语音信号x(n)经过16通道的分解滤波器组分解后,得到了16个子带信号xi(n)(i=1,2,…,16)。在每个通道内,首先进行当前帧信号声压级的计算;与此同时根据患者的听力图,通过线性插值的方法获得患者在当前通道中心频率处的听阈值,再根据式(2)~式(9)所得到当前通道的I/O曲线,即可得到患者在当前帧所需要的非dB域增益值,继而得到当前帧期望的输出信号,最后将此16个通道的输出信号通过综合滤波器组,得到最终补偿后的输出语音信号y(n)。
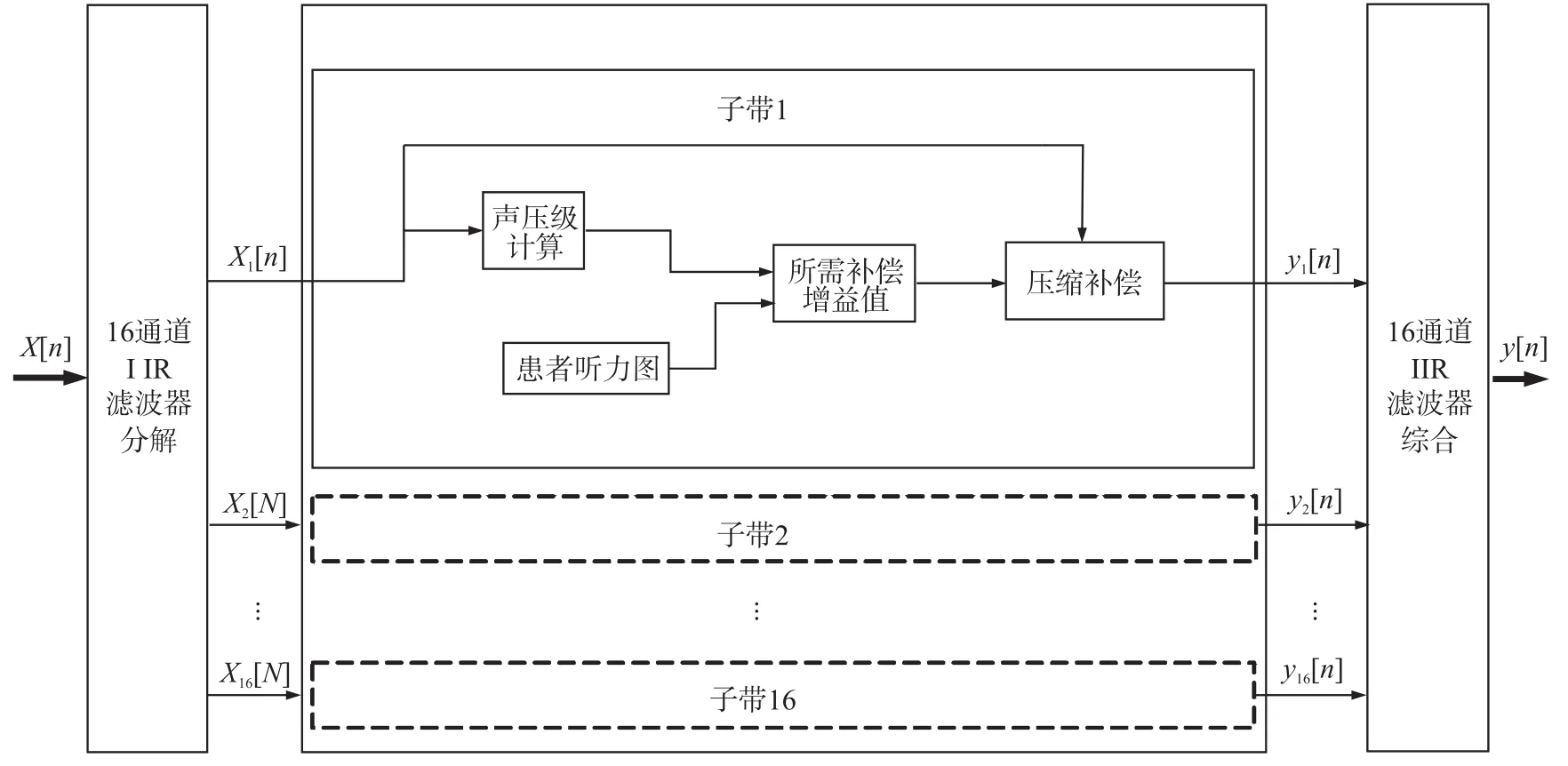
图2 本文设计的16通道响度补偿算法整体流程框图
3 多通道响度补偿实验与仿真
根据图3所示的典型感音神经性听力损失患者的听力图,使用本文所提供的基于声压级分段的算法对该患者进行响度补偿实验与仿真。实验测试语音文件采用TIMIT语音库dr3-madc0类中的sa2.wav文件,采样率为16 kHz,采样精度为16 bit,语音文件内容为“Don't ask me to carry an oily rag like that.”。
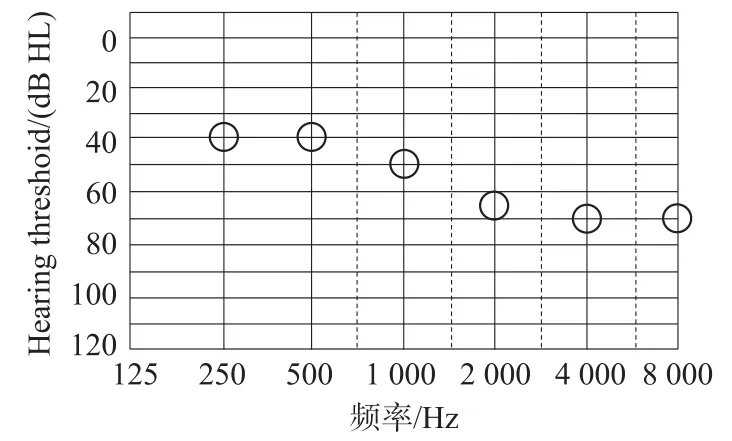
图3 测试用感音神经性听力损失患者听力图
图4即是根据上述算法所获得的该患者所需要的三维输入输出曲线。

图4 本文设计的多通道响度补偿三维I/O曲线
由图4可以看出,曲线在输入声压级值轴上被等分成了8段,且每一段的曲线压缩比(也即该段直线斜率的倒数)均不一样,这样相对于传统的低、中、高三段可以更加有效的根据患者的实际需求对每一个声压级段进行不一样的补偿。
将测试语音文件通过前述所设计的多通道分解与综合滤波器组,各通道内的响度补偿算法分别使用传统的三段补偿算法以及本文所设计的八段补偿算法,得到图5所示的时域波形比较图以及语谱比较图。观察图5(a)可知,传统算法和本文算法的输出语音的振幅相对于原始语音均有了一定的提高,只是幅度略有差别;两种算法补偿前后的语音包络基本相似,且输出语音的毛刺明显增多,表明两种算法都达到了响度补偿的基本要求。继续研究图5(b)的输入输出语谱比较图可知,本文算法在无语音处补偿的较少,而传统算法对无语音处进行较多的补偿,如最明显的开始200 ms左右,此时语音声压级很低,传统算法对此段进行较多的补偿,这就说明传统算法会将助听器的内部噪声进行放大,减小患者佩戴使用时的舒适度,而本文算法由于对此段声压级进行了增益控制,因此补偿后此段依然无语音,很好的消除了上述隐患。
为了更能够体现两种响度补偿算法对语音信号内部的补偿效果,将上述测试语音文件进行分帧,每帧长度取为256个点,并分别选取其中具有正常语音信息的一帧信号以及没有什么语音信息的低声压级信号作为两个演示帧。两种算法对正常演示语音帧提供了相似的补偿,在低频处补偿很少,而对中、高频段进行了较大的补偿,这主要是因为本文测试的患者为感音神经性听力损失患者,其听力损失主要都集中在中、高频段,这样即可使得补偿后的中、高频段语音达到患者的听阈值,使患者听得到声音。从以上分析,同样可以得出本文算法优于传统三段算法的结论。
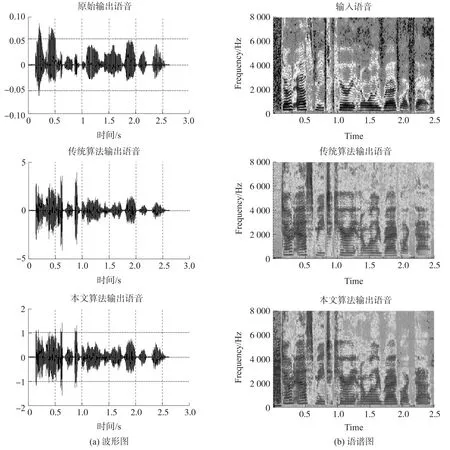
图5 传统算法与本文算法输入输出比较图
在经过多通道响度补偿仿真实验后,为了进一步定量评价本文算法的好坏,继续对一位具有图3所示听力损失情况的老年患者进行言语辨识率测试。实验在安静的房间内进行,房间内的墙壁装有吸音材料,以确保播放出来的单音节词清晰并且没有回声。测试语音来自于解放军总医院所录制的汉语普通话单音节测试词表,将测试语音源文件和按照传统算法以及本文算法做过响度补偿的语音文件分别从计算机扬声器中输出播放。测试的语音采样率为16 kHz,采样精度16 bit,测试50个随机选取的无重复单音节词在不同声压级下患者的识别情况,只有当患者能够正确回答出所播放的单词才算正确,得2%的辨识率分数,其余情况均不能得分。测试结果如图6所示。

图6 两种算法补偿前后言语辨识率
图6的结果显示,声压级在40 dB以下时,无论何种算法,辨识率均极低;而从40 dB开始,随着声压级的升高,患者的言语辨识率也在逐渐地提高。70 dB声压级时,传统算法言语辨识率升至将近50%,而本文算法辨识率则达到70%;而当声压级达到80 dB时,传统算法辨识率开始达到70%以上,本文算法辨识率则进一步增加至86%;最后在90 dB声压级下,传统算法达到90%的辨识率,而本文算法则具有94%的辨识率。
实验结果表明,传统三段算法与本文算法均能有效的提高患者的言语辨识率,且辨识率均比没有进行补偿要高。综合对比响度补偿仿真效果可以发现,本文采用的是基于声压级分段的多通道响度补偿算法,无论是补偿后的语音质量或者可懂度都明显好于传统三段算法,本文所提方法能够更加有效的帮助患者提升听力。
4 结束语
本文针对传统响度补偿算法按照低、中、高三段进行补偿的不足,提出了一种基于声压级分段的数字助听器非等宽多通道响度补偿方法。实验结果表明,该方法相比传统的三段补偿算法,能够更好的补偿患者所需的听力损失,提高患者的言语辨识率,并且在安静情况下能够很好的消除助听器内部噪声对患者正常使用造成的影响。这表明本文所提方法对于数字助听器的设计实现具有一定的应用价值。
[1]Edwards B W.Signal Processing Techniques for a Dsp Hearing Aid[C]//Circuits and Systems,1998.ISCAS'98.Proceedings of the 1998 IEEE International Symposium on.IEEE,1998,6:586-589.
[2]Allen J B.Wide Dynamic Range Compression Hearing Aids[J]. History,Physiology and Signal Processing,2002:1054-1059.
[3]陶智,赵鹤鸣,龚呈卉.基于听觉掩蔽效应和Bark子波变换的语音增强[J].声学学报(中文版),2005(4):367-372.
[4]赵力.语音信号处理[M].第3版.北京:机械工业出版社,2016:67-85.
[5]陈广飞,应俊.数字助听器宽动态压缩算法研究[J].北京生物医学工程,2006,25(5):454-456.
[6]王青云,赵力,赵立业,等.一种数字助听器多通道响度补偿方法[J].电子与信息学报,2009,31(4):832-835.
[7]戴红霞,王剑,赵力.麦克风阵数字助听器实验平台研究与设计[J].电子器件,2011(12):723-726.
[8]包永强.用于语音降噪的级联滤波器的设计与实现[J].电子器件,2013,36(12):810-813.
[9]Cornelisse L E,Seewald R C,Jamieson D G.Fitting Wide-Dynamic-Range Compression Hearing Aids:The DSL[I/O]Approach[J]. Hearing Journal,1994,47:23-23.
[10]Killion M C.Loudness-Data Basis for‘‘FIG6''Hearing-Aid Fitting Targets[J].The Journal of the Acoustical Society of America,1995,98(5):2927-2927.
[11]冯国友,戴扬,沈海斌,等.孤立词语音识别中端点检测加速器的设计与实现[J].电子器件,2007,30(6):1098-1101.
[12]薛凌云,向学勤,范影乐,等.基于神经元阀上非周期随机共振机制的语音复原技术研究[J].传感技术学报,2009,22(2):213-218.

周锋(1981-),江苏盐城人,盐城工学院,信息工程学院,讲师,硕士,2004年本科毕业于东南大学无线电工程系信息工程专业,2012年研究生毕业于东南大学信息科学与工程学院电子与通信工程专业,2004年在盐城工学院从事科研和教学工作,在《光电子·激光》等国内外一流杂志上发表多篇论文,申请国家发明专利多项,主要从事信号与信息处理、图像与语音信号处理方面的工作,zfycit@163.com。
A Research of Loudness Compensation Method for Digital Hearing Aids Based on Segmented Sound Pressure Level*
ZHOU Feng1*,TANG Jianeng2,WANG Rugang1
(1.College of Information Engineering,Yancheng Institute of Technology,Yancheng Jiangsu 224051,China;2.College of Engineering,Huaqiao University,Quanzhou Fujian 362021,China)
Loudness compensation is a key technology for digital hearing aids,most compensation gain values are calculated by three sections of sound pressure level(SPL),which usually does not meet the actual needs of patients with hearing loss.For the lack of compensation effect of traditional algorithm,a loudness compensation method based on segmented SPL is proposed.Simulation results show that to compare to traditional algorithm,the hearing loss can be better compensated,the patient's speech recognition rate can be increased rapid,and the effect caused by noise inside hearing aid in normal use can be well eliminated with the help of the new algorithm.
sound pressure level;loudness compensation;multi-channel filter bank;digital hearing aids
TH785.1
A
1005-9490(2016)05-1180-05
项目来源:江苏省自然基金项目(14KJB510034);泉州市科技计划项目(2014Z103);2014年江苏省“双创计划”项目;2015年江苏省产学研前瞻性项目;盐城工学院人才引进项目(KJC2013014);东南大学水声信号处理教育部重点实验室2015年开放课题项目(UASP1501);中央高校基本科研业务费专项资金项目(2242013K30010)
2015-05-11修改日期:2015-06-18
EEACC:782010.3969/j.issn.1005-9490.2016.05.032
猜你喜欢
现代特殊教育(2022年10期)2022-10-13
中老年保健(2021年7期)2021-08-22
计量学报(2020年2期)2020-04-11
声学技术(2019年6期)2020-01-19
演艺科技(2019年4期)2019-03-30
中国传媒科技(2018年6期)2018-07-25
中华诗词(2018年11期)2018-03-26
计算机辅助工程(2017年4期)2018-02-01
新闻传播(2016年3期)2016-07-12
发明与创新·中学生(2016年7期)2016-05-14
