
众包在国内古籍数据库建设中的应用研究
2016-11-18 03:44颜运梅
图书馆研究 2016年5期
颜运梅
(广州图书馆,广东广州510623)
众包在国内古籍数据库建设中的应用研究
颜运梅
(广州图书馆,广东广州510623)
元数据众包和文本建设众包是国外图书馆界众包项目的主要模式。以国内CADAL数据库和《广州大典》数据库为例,阐述了元数据众包和文本建设两种众包模式在国内古籍数据库中的应用,提出这两种模式存在的问题,并结合《广州大典》数据库的文本建设的众包功能,提出优化改进措施。
众包;CADAL;广州大典;文本建设
1 资源的使用者与创造者
在知识创新时代,图书馆的用户,既是资源的使用者,也是资源的创造者。图书馆的未来定位,不仅仅是存储知识的机构,还应当成为促进知识创新、帮助创造知识的主体,积极鼓励用户参与知识的生产与创新。
澳大利亚国家图书馆在《2015-2019年规划》中明确提出将“促使和参与知识的创造”,在规划期内将通过第三方服务如Flickr平台增加数字内容,继续丰富Trove的资源[1]。
众包这一概念由杰夫·豪(Jeff Howe)于2006年6月《连线杂志》首次提出后[2],国外图书馆界已将众包模式大量地引入图书馆建设中,并通过实践发现,众包可以提升资源的使用率、丰富资源,减轻图书馆的人力负担,扩大共建共享的边际,同时提高资源的可发现性。众包因此成为国外图书馆鼓励用户参与知识共建共享的主要模式。国内图书馆界对众包的研究颇多,但实际应用并不多,尤其是在古籍数据库的建设方面。
2 众包在国内古籍数据库中的应用情况
自上个世纪80年代以来,古籍数据库建设经历了30年的发展,成绩斐然,据2010年统计,古籍数据库数量就达到580余种[3]。国内大型的古籍数据库大部分由于建设较早,用户参与程度低。古籍数字化产品提供商和用户、用户与用户之间交流的渠道少。
数字技术、社交媒体的快速发展使得古籍数据库的一些功能得到拓展,古籍阅读作为古籍全文数据库的核心功能不再那么重要,用户更注重与其他用户就古籍相关内容进行交流和学习等功能,古籍研究者更注重在线古籍研究的功能。交互设计,成为古籍服务平台新的重要建设理念。近几年建成使用的国内古籍数据库也相应地增加了用户互动和参与的功能,增设了交互模块、共建模块,提高了用户参与的积极性,提升了资源的使用率。这些模块包含纠错、论坛、书评和社交。如国内大型的CADAL平台有专门的网络用户社区,用户可以根据喜好建立群组,在群组里讨论、写书评、聊天等[4]。
国内的古籍数据库中除了这些交互和开放功能,采用众包模式建设的古籍数据库还比较少。据笔者调研,CADAL古籍数据库的元数据众包模式较为成熟,2015年底上线的《广州大典》影像全文数据库平台也开发了文本建设的众包,这两者的模式较有代表性,本文以这两个数据库为例,讨论国内古籍数据库的众包模式。
3 CADAL古籍数据库图书元数据的众包
大学数字图书馆国际合作计划(China Academic Digital Associative Library,简称为CADAL)数据库中的古籍和民国期刊的元数据建设采取了众包的模式。用户在平台注册、登录之后,即可参与元数据的众包,CADAL众包功能包括三个方面。
3.1 确定电子书元数据的质量
在古籍电子书的元数据页面有个评价功能,用户可以对这些图书的元数据质量进行评价,评价共分为四个等级,包括:很好,较好,较差、很差。用户对同一本电子书只能提交一次选项,不能重复提交。
3.2 修改图书元数据信息
用户可以在古籍电子图书的详情页面对图书的信息作修改。对图书的元数据,如出版社、出版日期、关键字等信息进行编辑,在此页面上还可以查看某个字段的编辑历史。
3.3 补充电子期刊的元数据
某些民国电子期刊的元数据,可能缺乏期刊名称、出版社、关键词等信息,用户可以在这些期刊的详细页面新增、修改这些元数据。同时某种期刊可能包含多种刊物内容,用户也可以协助找出每一种刊物所对应的起始页。
3.4 CADAL的奖惩制度
为了吸引用户积极参与众包功能,CADAL数据库采用了一些奖惩制度,包括积分、阅读扣分规则,详见表1。平台根据用户贡献的程度,奖励读者获得限量图书的全球访问,无需受到所在学校IP的限制。这种利用特色资源吸引用户参与众包的方式具有一定的吸引力。同时扣分规则可以有效地遏制一些用户的恶意编辑数据,降低网站管理者在后台的审核成本。
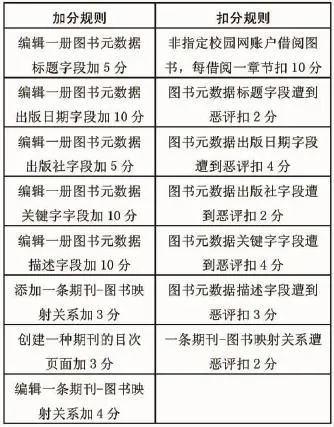
表1 CADAL的奖惩规则
4 《广州大典》影像数据库文本的众包
4.1 数据库介绍
《广州大典》影像数据库是广州市重要的历史文献全文数据库,是由中共广州市委宣传部、广东省文化厅策划并组织研究编纂的大型地方文献丛书,大体依经、史、子、集、丛五部分类,收录广州人士(含寓贤)著述、有关广州历史文化的著述及广州版丛书。所收文献下限为1911年,个别门类延至民国。《广州大典》收录4 064种文献,编成520册。珍本、善本等稀见文献众多,收有稿抄本462种,清乾隆以前刻本357种[5]。《广州大典》根据古籍原文影印出版。数据库是根据原版影像建成、基于PDF格式的影像全文数据库。这种古籍影像数据库,用户无法进行全文搜索,目前仅仅能通过古籍的题名、著者、版本项进行搜索,使用不便,资源无法被深入挖掘与发现,无法满足学术研究群体的高层次需求,仅能满足一般程度的阅读与使用推广。提供《广州大典》全文文本数据和实现全文搜索是数据库建设的二期任务。目前数据库平台开发试用的文本众包功能,为二期文本建设提供了基础。
《广州大典》文本建设的众包模式,包括对文本进行录入和纠错两个重要的功能模块。录入指网络志愿者利用人工手段,录入《广州大典》影像的文本,文本纠错指志愿者可以对其他用户录入的文本或通过OCR识别的文本进行审校和纠误(纠错功能暂未开通)。
4.2 众包的流程
4.2.1 注册登录
用户要参与《广州大典》的文本众包,必须先注册成为广州数字图书馆的用户或者访客。《广州大典》数据库由广州图书馆建设,主要面向广州市的用户开放。非广州市的用户,只需要在广州数字图书馆平台上注册成为访客身份即可参与众包。
4.2.2 领取任务
《广州大典》全文页面的右上角有“未加工页”下拉菜单,注册用户在此选取未被录入或者未被领取录入的任务页码。用户选择页码后,页面直接跳转链接到相对应页面,在“文本建设”框即可录入文字。
4.2.3 加工提交
在文本加工页面有说明文字提醒用户:在录入文本时必须忠实于原文,不必纠正原文错误;对于无法输入的文字或符号,使用X代替;以原文语种(汉语繁体)加工文本。录入完毕可点击提交按钮,数据提交到后台,如果未录入完毕,则可先保存留待继续录入。
4.2.4 后台审核
用户加工文字、录入完毕提交数据到后台,由管理员进行审核,审核反馈意见为通过、不通过。通过审核后文本内容则可由管理员保存,同时前台的任务页面则不能再领取任务。如果审核不通过,则由管理员释放任务,在前台可以重新被领取加工。
4.3 众包的后台管理
《广州大典》文本众包的后台管理模块包括表2中的功能:
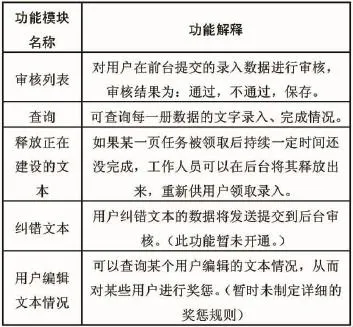
表2 众包的后台管理功能模块
5 两种不同的众包模式
5.1 元数据的众包与文本的众包
国外特色数据库建设的众包模式较多,其中,资源的标引以及文字录入、纠错是其主要的两种方式。资源标引又主要包括给资源设TAG标签和元数据标引。
CADAL古籍数据库和《广州大典》数据库的众包模式是两种不同的模式。CADAL古籍数据库的众包功能主要在于图书的元数据标引、补充和纠错。CADAL项目二期提出了“多维度标签分类实践”,标签的生成包括其中一项是“让用户为文献添加标签”[6]。相对于《广州大典》的全文文本录入来说,CADAL古籍库的众包项目的难度和工作量都较小。《广州大典》数据库的元数据由《广州大典》编辑部提供,是完整和准确无误的,没有必要对这方面的数据进行众包。《广州大典》的二期建设任务是要提供《广州大典》的全文文本数据,其前提条件是必须有古籍数据的文本内容。如果对影像版的古籍进行OCR识别,底本、手抄本、手稿等字体较难识别,识别率较低。如果图书馆负责全部文本录入,又将花费大量的人力。《广州大典》建设方原计划招聘志愿者协助完成文本录入的工作,并给予一定的报酬。但经过大量的调研之后,决定将数据开放在网站上进行文本众包,这是国内大型古籍数据库对文本众包建设模式的大胆尝试。
5.2 众包的效果
CADAL数据库于2011年上线至今,以《民国汇报》为例,其目次页面的贡献人(次数)有5人8次,说明还是有用户关注、尝试众包功能。《广州大典》数据库的众包参与度、效益和影响都不甚理想。2015年12月平台正式上线,推出众包功能至今半年多,暂未收到用户有用的参与数据。
相较而言,CADAL众包项目的管理体制比《广州大典》数据库成熟,平台设计也更便于用户操作,单个任务不用耗费用户大量的时间,用户可以随时退出任务而不至于对任务和对其他用户造成影响。同时制定了严格的奖惩制度,有效地遏制了用户的恶意数据。而《广州大典》数据库的用户在前台领取了文本录入任务,如果用户在规定时间内没有完成任务,系统必须将这些任务重新释放出来供其他用户重新领取录入。另外,也没有制定严格的奖惩制度。
5.3 众包存在的问题
5.3.1 项目工作量大,过于专业
《广州大典》影像数据库的用户只需要简单注册后即可参与众包。与商业性质的众包不同,公共图书馆由于其公益性而更易于获得志愿者支持[7]。但是众包的实际效果,与众包任务本身的特性有密切关系。如Holley提出的图书馆实施众包的六项原则,其中一项是:“众包项目的活动应简单有趣”[8];李书宁与曾姗在对国外图书馆众包项目调查后也认为:“具有无版权、工作任务简单、单个任务耗时短、内容有趣、数据量极大等特点的资源更适合应用众包理念”[9]。美国国会图书馆、大英图书馆和丹麦国家图书馆都以馆藏照片作为众包内容,因为对普通大众来说,图片比文字更具吸引力。另外,澳大利亚国家图书馆和芬兰国家图书馆报纸数字化项目,也是由于报纸内容通俗易懂,具有吸引力。此外,国外图书馆在开展众包项目时还注重对任务进行分解,把庞大的工作分解成细小的任务,将数据库建设分解成收集、整理、组织、描述、审校、纠错等小任务,参与者只需完成自己的一部分即可,互不干涉,随时参与,随时退出[10]。
国内外图书馆众包项目效果差异的原因在于众包任务本身的差异性,同时也与中英文字体的差异性和文字本身的构成有关。英文单词,无论古今,都是由26个字母的组合,在校对录入过程中,字体辨认的难度不大,即使有误差,也不会错得太离谱。手稿录入、校对的难度也较汉字繁体字的录入、审校容易。
汉字的古籍数字化是个慢工出细活的工作,按照程序,一般先要根据扫描书页影像交由电脑OCR系统自动识别为文字,其中不少集外字、模糊字、通假字、异体字极易产生识别错误,这些问题只能靠人工进行校对更正,许多都要根据上下文意进行判断,由录入校对者在空缺的位置补录上正确的文字。所以录校人员不仅需要古汉语知识,同时也要具备一定历史常识的储备,而不仅仅是单纯的录入工作。
《广州大典》一共520册,国际大16开本,每册约850页,共有约44 200张书页。众包项目将所有书页都放出来供用户录入校对,工作量过于庞大。Martin Moyle在总结伦敦大学学院J.Bentham手稿录入项目时认为,文本加工是一项非常复杂的工作,难度不亚于、甚至超过其它众包项目[11]。《广州大典》数据库文本建设如此庞大的工作量由众包来完成,难度可想而知。
5.3.2 用户体验不佳
CADAL的古籍页面因为可以针对元数据进行纠错和补充,导致页面不整洁和紊乱。在使用数据信息时,用户体验不佳,同时也给人不够专业的印象。《广州大典》数据库典籍版面是竖排,而文本录入页面是横排,在“保真”还原效果上差一些。
5.3.3 数据质量差
CADAL的元数据众包,有可能导致本来是应该比较权威的元数据被用户改得不够专业,增加了后台审核的难度和人力。《广州大典》的后台收到一些用户众包的数据,质量低下,完全无法使用。
5.3.4 人力成本高
用户录入文本、提交到后台的数据,需要专业馆员负责审核,如果数据质量不佳,人力成本就会随之增加。
6 《广州大典》众包的改进措施
在国内图书馆界,众包还是“摸着石头过河”,在实践中不断地修正和改进。较之CADAL数据库的众包,《广州大典》网络服务平台的众包项目,对用户而言更为专业和艰深,不是公共图书馆的一般用户可以胜任的。为了避免产生大量无用数据,平台可以对众包的流程做一些改动,优化项目难度较大的工作流程,达到更加理想的状态。
6.1 资源筛选
首先,对《广州大典》的数据进行筛选。对一些经典传世之作,特别是已出版印刷、有文字版的资源进行筛选,这一部分数据不再释放出来录入。而目前《广州大典》众包的做法是将所有古籍的影像版全部释放出来供用户选择进行文本录入、内容建设,这必将造成重复建设。
6.2 优化程序
资源去重之后,对剩下的资源,特别是识别度较高的文本先进行OCR识别,然后组织人力对其进行校对录入。对一些难度较高、识别率低的古籍专门组织人力进行校对录入,而不是对所有的资源率先进行文本的众包录入校对。
6.3 寻找合适的志愿者
古籍数字化的真实再现,是建立在正确理解原文基础上的文字转化,这对从业人员提出了较高的要求。从业者必须是文理兼备的人才,既要掌握计算机技术,又必须有深厚的国学功底。其中涉及的国学知识,包括古籍中异体字关联、简繁体关系,正体异体关系,正字讹(伪)字关系,通假被通假关系,古今字关系,新旧字形关系,形近异义字,避讳字等。如果对参与众包的用户资格进行审核,会提高数据的质量,减少审核的人力成本和难度。
平台可以对申请参与众包的用户进行筛选、审核。对具备一定专业水准的用户开放权限。同时采用适当的激励机制,对积极参与或者数据质量较高的用户给予一定的奖励。《广州大典》数据库众包功能目前还没有出台相对应的奖惩措施。制定奖惩制度,或者是适量的现金奖励模式可以吸引更多用户参与。没有奖励,难以吸引稳定、有粘性的用户参与这项专业工作。同时设置用户黑名单功能,如果发现有用户大量提交恶意无效数据,管理员可以将其加入黑名单,限制其参与众包的功能,有效地减少无效、低质量数据。
6.4 开发易用的平台
建设方应该完善众包功能,优化平台的用户体验,促使资源的发现、使用、交流。平台的操作程序要简洁易用,不要过于复杂。在此基础上,征集专家与用户的意见,持续完善与改进众包的功能模块,使之更具操作性。
6.5 众包的宣传推广
对众包模式进行宣传推广,使图书馆界与用户知道、了解、接受、参与这一模式。在2015年全国图书馆年会会议上,广州图书馆对《广州大典》影像数据库做了专场报告,尤其对数据库的众包功能做了重点介绍,古籍数据库的众包模式已经引起国内图书馆的关注。
7 结束语
众包在国内特色数据库中的应用虽然已经引起了关注,但还不普遍,也不成熟。对于项目的难度把握还不是很好。国内图书馆可以考虑将一些非专业化且工作量不是特别大的项目众包,让用户参与,吸引用户参与建设、丰富资源。期望图书馆界的专家学者共同探讨众包在中国古籍数据库中应用的理论与实践。
[1]National Library of Australia.Corporate Plan 2015-2019 [EB/OL].[2016-05-20].http://www.nla.gov.au/corporatedocuments/corporate-plan-2015-2019.
[2]SAXTON G D,OH O,KISHORE R.Rules of crowdsourcing:Models,issues and systems of control[J].Information Systems Management,2013(1):2-20.
[3]李明杰.中文古籍数字化实践及研究[M].武汉:武汉大学出版社,2010.
[4]CADAL数据库[EB/OL].[2016-05-20].http://www.cadal. zju.edu.cn/index.
[5]广州大典网络服务平台[EB/OL].[2016-05-20].http:// gzdd.gzlib.gov.cn/HRCanton/.
[6]刘翔,黄晨.共享的边界:CADLIS创新模式再析[J].大学图书馆学报,2014(1):41-43,40.
[7]HOLLEY R.Crowdsourcing:How and Why Should Libraries Do It[J/OL].D-Lib Magazine,2010(3/4)(16):[2016-05-07]. http://www.dlib.org/dlib/march10/holley/03holley.html.
[8]HOLLEY R.Tagging full text searchable articles:An overview of social tagging activity in historic Australian newspapers,August 2008-August 2009[J/OL].D-Lib Magazine,2010(1/2)(16):[2016-05-07].http://www.dlib.org/ dlib/january10/holley/01holley.html.
[9]李书宁,曾姗.国外图书馆数字馆藏众包建设实践调查与分析[J].图书情报工作,2014(12):83-90.
[10]关富英,李书宁.众包——图书馆特色资源建设路径新选择[J].图书馆杂志,2015(2):58-62,93.
[11]MOYLE M.Manuscript transcription by crowdsourcing: Transcribe Bentham[J].Liber Quarterly,2011(3/4):347-356.
(编发:王域铖)
Application Research on Crowdsourcing in the Construction of Ancient Books Database in China
YAN Yun-mei
(Guangzhou Library,Guangzhou 510623,China)
Crowdsourcing metadata and text construction are two main models crowdsourcing projects in the libraries.Taking CADAL database and Guangzhou Encyclopedia Database for example,this article describes the application of the two models in domestic ancient database,puts forward existing problems and the optimization measures.
crowdsourcing;CADAL;Guangzhou Encyclopedia;text construction
G250
G250
A
2095-5197(2016)05-0030-05
颜运梅(1979-),女,副研究馆员,硕士,研究方向:图书馆数字资源建设、网站建设。
2016-05-24
猜你喜欢
房地产导刊(2021年12期)2021-12-31
汉字汉语研究(2021年3期)2021-11-24
房地产导刊(2020年11期)2020-12-28
天一阁文丛(2020年0期)2020-11-05
房地产导刊(2020年7期)2020-08-24
小读者(2020年4期)2020-06-16
天一阁文丛(2018年0期)2018-11-29
金桥(2017年5期)2017-07-05
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
