
基于XML数据挖掘的Apriori算法的研究与改进
2016-11-17 10:41:00张继荣王向阳
计算机测量与控制 2016年6期
张继荣,王向阳
(西安邮电大学 通信与信息工程学院,西安 710061)
基于XML数据挖掘的Apriori算法的研究与改进
张继荣,王向阳
(西安邮电大学 通信与信息工程学院,西安 710061)
XML以其诸多优点,迅速成为不同领域间信息表示与交换的标准;大量XML数据的出现给数据挖掘带来了新的挑战;挖掘XML数据关联规则的大部分工作都是基于Apriori算法的研究;对Apriori算法的基本方法与效率进行了分析,指出其不足,并提出了改进的XApriori算法,该算法基于新的数据结构,利用Hash表的存储技术以及对Apriori算法的优化来提高查找频繁项集的效率;对Apriori算法和XApriori算法进行了比较,实验结果表明改进的XApriori算法优于Apriori算法。
XML;数据挖掘;关联规则;频繁项集;Apriori
0 引言
XML(eXtensible Markup Language,可扩展标记语言)[1]是一种描述数据内容和结构的语言,其具有标准的文本格式,可以在不同平台间,进行数据的表示、存储和交换,XML的飞速发展产生了大量的XML数据,所以,对其进行挖掘[2]已经变得非常重要。对XML数据关联规则[3-4]的挖掘概括有以下3种不同的方法:1)Wan 等人提出的XML 挖掘算法是直接使用 XQuery 语言来实现Apriori 算法的,无需预先处理 XML 文档[5]。2)Daniele Braga 等人提出的方法是通过预处理数据、抽取关联规则和后期处理关联规则3个主要步骤来实现 Apriori 算法[6]。3)Ling Feng 等人提出一种不基于 Apriori 算法并且将不同的事务和项的概念映射到 XML 文档树型结构的方法[7]。本文基于XML 文档并通过改进的Apriori 算法[4]来进行关联规则的挖掘。XML挖掘包括对其结构和内容的挖掘,本文是基于XML文档的内容来进行关联规则的挖掘,通过DOM技术解析、提取出XML文档的内容[8],由于XML文档的内容等价于元素的值,而被解析提取之后的XML元素值的集合与文本基本等价。所以,对XML文档内容的挖掘就转变成对一般文本文档的挖掘。
1 关联规则的基本概念
设所有的项目集合记为I={i1,i2,…,im},数据集记为D(事物数据库),D={T1,T2,…,Tn},其中Ti(i=1,2,…,n)称为事务且Ti⊆I,包含k个项的项集称为k-项集[9]。在XML数据中,将提取出的每一个元素记为一个事务,每个事务都有自己的ID,元素的值记为项,各个项都有自己的编号Ik(k=1,2,…,n),把XML数据提取出的事务集合记为D,项的集合记为I。以某食品店部分交易记录信息的XML文档的数据表示为例来说明。记录信息的部分XML文档如下:
……
该文档内容经过解析、提取之后,可以表示成表1和表2的形式。
关联规则[10]是形如R:X→Y的逻辑蕴含式,其中X⊆I ,Y⊆I且X∩Y=Φ。在数据库D中,存在关联规则X→Y的支持度记为Support(X→Y)或Support(X∪Y),表示同时出现项集X和Y的比例。若有Support(X),则存在关联规则X→Y的置信度,记为Confidence(X→Y)= Support(X∪Y)/Support(X),表示包含X的事务下同时也包含Y的事务的比例。

表1 事务数据
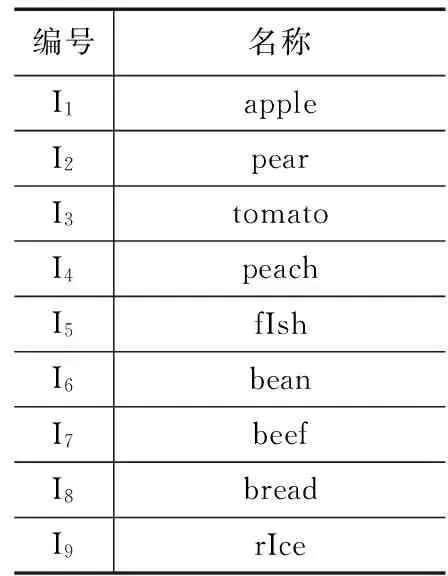
表2 项目数据
关联规则的产生,给定最小支持度minsup,首先找出所有的其支持度不小于minsup的频繁项集,再由频繁项集计算出关联规则。如何高效地查找频繁项集是整个算法的重点,也是本文后续工作研究的重点。
在大量的关联规则算法中,基于 Apriori算法[11]挖掘效率的研究成为了重点。在1993年,Agrawal等人提出了Apriori算法。该算法的基本思想:按包含项目数自小至大的、逐层搜索迭代的方法来寻找频繁项集。即用频繁k-项集产生(k+1)-项集。具体过程是:第一次对数据库进行扫描,找出所有的频繁1-项集,记为L1;对L1自连接产生C2,对C2修剪后,第二次扫描数据库,找出所有的频繁2-项集,记为L2,如此循环,直到没有频繁项集为止。从过程中可看到Apriori算法的不足:在面对较大数据时,需要花费较大的开销产生数目巨大的候选项集,Ck中的项集的数目将会呈现出指数般的增长;另外需要k次扫描数据库,k为最大频繁项集中子项集的项目数。从而带来了很大的I/O交互负载并且非常耗费时间。
2 Apriori改进算法的设计
2.1 数据结构的设计及事务数据的Hash表表示
分析Apriori算法的不足可知, Apriori算法效率的提高关键在于:1)减少扫描事务数据库的次数;2)减少候选项集的数目。对此,本文设计了新的数据结构,并利用Hash表来表示和存储数据。该方法的基本思想是:对于Apriori算法来说,其依赖的数据结构是水平的,本文对其转变成项目事务垂直对应的关系数据结构。对XML解析提取出的数据事务和项用Hash表来记录[12],每个项构建一个Hash表,Hash表中的元素为各个事务在对应的项中出现的事务编码,为了方便后续计算项集出现的次数,本文以二进制编码形式来表示事务元素[13],各事务在对应的项中出现,则相应的表示为1,否则为0。将表1和表2可以表示成Hash表的形式,如表3所示。
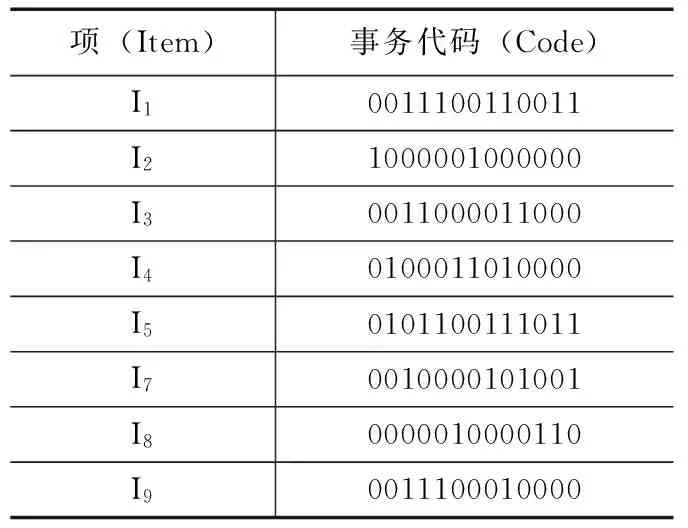
表3 事务数据Hash表
表3产生频繁项集的方法:给定最小支持度计数(minsup),如果项目的二进制代码中1的个数不小于minsup,其相应的项集即为频繁1-项集。有2-项集{Ii,Ij},只需在Hash表中提取第i项和第j项的二进制代码,对其作按位逻辑与运算,得到的二进制代码中1的个数不少于minsup的2-项集{Ii,Ij}即为频繁2-项集。频繁k-项集以相同的方法得到。该方法不会产生大量的候选项集,不但节省了内存空间,而且在计算支持度时,只需提取出部分的二进制代码,不需对Hash表进行整体扫描,从而降低了I/O交互负载并且节省了时间,最终使得Apriori算法的效率得到了大幅度的提高。
2.2 连接步的改进方法
分析Apriori算法的计算过程中发现Apriori算法需要重复多次的对两个k-项集进行判断:1)判断其前k-1项是否相同;2)判断最后一项是否不同。对k-项集的判断运算将影响着Apriori算法效率的高低。于是本文对其进行了必要的改进。该方法的基本思想:Lk-1自连接生成Ck前,判断任意的两个项集的前k-2项是否相同,如果不同,则不进行两个项集的连接运算,因为产生的项集是重复的、非频繁的[14]。设项集按升序排列的Lk-1中,任意项集X和Y作连接时,若Xk-2≠Yk-2,则放弃对X和Y的进行连接运算,从而减少了运算量。
例如在数据库中D中,按升序排列的项集L2={{I5、I1},{I5、I8},{I4、I3},{I4、I1},{I3、I8},{I1、I6}}。按改进的连接方法生成C3,C3=L2×L2={{I5、I1、I8},{I4、I3、I6}},如果按Apriori算法的连接方法生成C3=L2×L2={{I5、I1、I8},{I5、I1、I4},{I5、I8、I3},{I5、I1、I6},{I4、I3、I1},{I4、I1、I6},{I4、I3、I8}},相比可知减少了冗余项集的产生,两者对数据库的扫描分别需要2次和27次。可见,连接步的改进可以减少运算量和扫描次数。
2.3 剪枝步的改进方法
判断Ck中的项集是否属于Lk中的频繁项集前,Apriori算法对Ck进行修剪,以除去Ck中那些不可能产生频繁项集的候选项集。将Ck中各个项集的k-1项子项集与Lk-1中的项集进行匹对,若不出现相同的项集,则删除Ck中产生该子项集的项集。该方法对数据库进行了大量的扫描,中间产生了大量的子项集,从而造成了内存空间的浪费和很大的时间开销,导致了剪枝步的运算效率比级低。为了解决这些问题,本文结合了Apriori的一些性质,提出了剪枝步的改进方法。Apriori的一些基本性质[14]:
性质1:设一项集为Xk,Xk中存在的任意子集记为Yk,如果Xk是频繁项集,那么Yk也是频繁项集。
性质2:设一事务为Tk,Ck-1中的任何项集记为Ik-1,如果Ik-1⊄Tk,则删除事务Tk,不会影响Lk的产生。
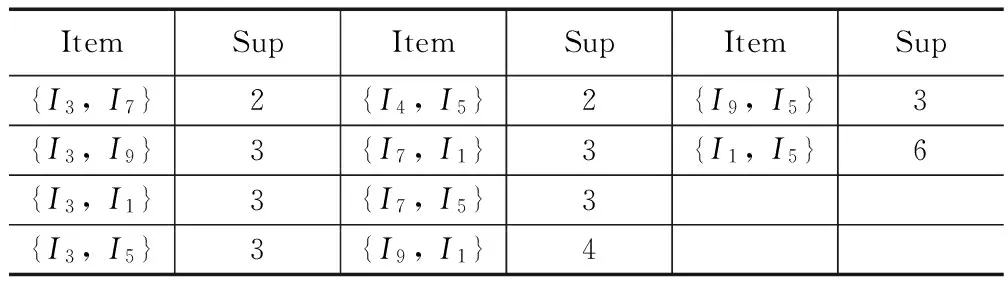
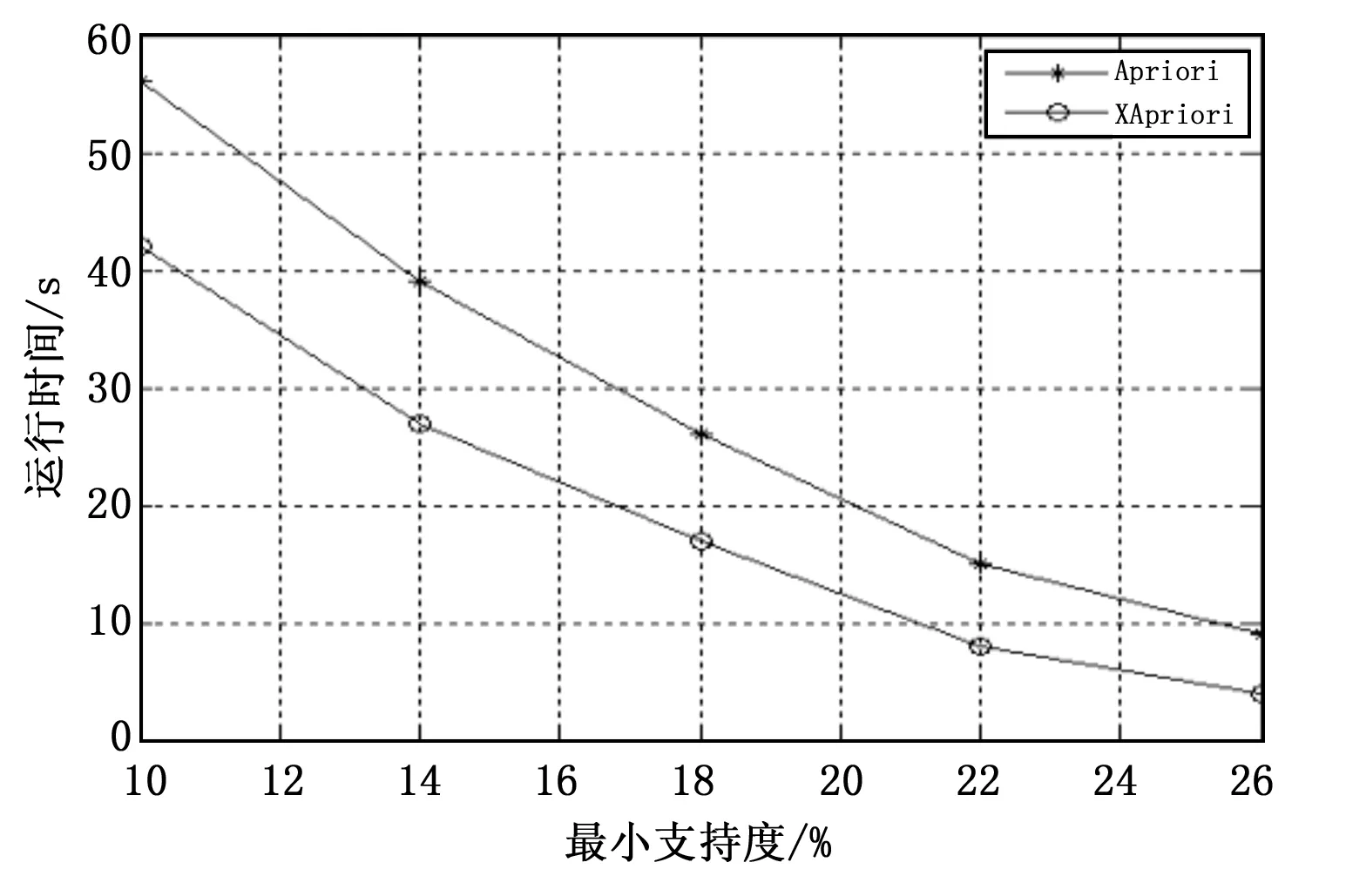
从性质可得:如果在I={i1,i2,…,ik}中,存在j∈I且|Lk-1(j)| 反证法证明:假设有频繁项集Ik,由性质1知Ik中的k个非空子项集Xk-1也是频繁项集,所以所有的子项集Xk-1都存在于Lk-1中。又由性质1知任意项集Xk-1的每一个项目i∈I在Lk-1共出现了至少k-1次,所以,对任何j∈I有|Lk-1(j)|≥k-1,结果明显矛盾,故I不是频繁项集。 由上述性质对剪枝步进行改进,方法的基本思想是:删除集合Lk-1中所有满足|Lk-1(j)| 举例说明:设L3={{I1、I2、I3},{I1、I2、I5},{I1、I2、I4},{I1、I2、I6},{I1、I2、I7},{I2、I3、I4},{I2、I3、I5},{I2、I3、I6},{I2、I3、I7}},由上述修剪方法可得|L3(1)|=5,|L3(2)|=9,|L3(3)|=5,|L3(4)|=|L3(5)|=|L3(6)|=|L3(7)|=2,故删掉L3中包含项目I4,I5,I6,I7的频繁项集得到l3={{I1、I2、I3}},得新的c4为空集,显然L4也为空集。显然改进的Apriori算法只需扫描一次数据库,可以提前删除不可能包含于频繁项集的项,从而大幅度的减少匹配候选频繁项集的时间开销。可见较之Apriori算法的效率有了很大的提升。 2.4 算法描述 第一步:对XML文档进行解析、提取出事务和相应的项,并且以新的数据结构存储在Hash表中,构成事务集合数据库D; 第二步:输入预定的最小支持度,并扫描数据库,在扫描过程中计算各个1-项集的支持度,通过对各个1-项集相对应的二进制代码中1的个数的统计计算,删除小于最小支持度的项集,得到集合L1; 第三步:连接步,为了产生k-项集Lk,运用改进的连接步的设计思想产生k-1项的项集Lk-1(项集中的项按在D中出现频率的大小进行生序排列); 第四步:剪枝步,计算Lk-1中所有项目的频度,通过改进的剪枝步的设计思想来产生一个新的更小的k-1项频繁项集的集合lk-1,再通过自连接生成Ck; 第五步:将Ck中不满足给定最小支持度的项集删除掉,形成Lk; 通过循环迭代计算,重复第三步到第五步,直到不产生新的频繁项集为止,其中各个项集的支持度为生成各个项集的连接项集的二进制代码按位与运算后代码中1的个数。 2.5 对算法进行实例数据的演示 这里以图表3的XML文档解析提取出的数据为例,每一个项目都以二进制代码的形式表示是否出现在13个事务中,给定最小支持度计数为2。XApriori算法的实例计算过程如表4所示。 表4 XApriori算法实例运算过程 L1 ItemSupItemSupItemSup{I1}7{I4}4{I8}3{I2}2{I5}8{I9}4{I3}4{I7}4 C2↓ ItemSupItemSupItemSup{I2,I8}0{I8,I9}0{I4,I1}1{I2,I3}0{I8,I1}1{I4,I5}2{I2,I4}1{I8,I5}1{I7,I9}1{I2,I7}0{I3,I4}1{I7,I1}3{I2,I9}0{I3,I7}2{I7,I5}3{I2,I1}0{I3,I9}3{I9,I1}4{I2,I5}0{I3,I1}3{I9,I5}3{I8,I3}0{I3,I5}3{I1,I5}6{I8,I4}1{I4,I7}0{I8,I7}0{I4,I9}1 L2↓ ItemSupItemSupItemSup{I3,I7}2{I4,I5}2{I9,I5}3{I3,I9}3{I7,I1}3{I1,I5}6{I3,I1}3{I7,I5}3{I3,I5}3{I9,I1}4 C3↓ ItemSupItemSup{I3,I7,I9}1{I3,I9,I5}2{I3,I7,I1}1{I3,I1,I5}2{I3,I7,I5}1{I7,I1,I5}2{I3,I9,I1}3{I9,I1,I5}3 L3↓ ItemSupItemSup{I3,I9,I1}3{I9,I1,I5}3 C4 ↓ItemSup{I3,I9,I1,I5}3→L4 ↓ItemSup{I3,I9,I1,I5}3 对比Apriori算法,XAprior算法有以下优点:1)XApriori算法只对XML文档数据库扫描一次,在后续计算只需要索引出相应项集的二进制代码,随着算法的运行,需要处理的事务和项集在不断地减小,从而节省了大量的时间,也大大的降低了I/O交互负载。 2)XApriori算法的数据结构比较简单,设计了项目事务垂直对应的关系数据结构,对每一个项目进行了二进制编码,存储在Hash表中。在后续计算中使用了集合,使得计算比较节省时间。 3)XApriori算法只在开始扫描数据库时对每个事务和项目进行了处理,在后续计算只需要索引出相应项集的二进制代码,不需对所有项集进行处理。例如支持项目A的事务的集合为TA,支持项目B的事务的集合为TB,则同时支持项目A、B的事务为两个集合交集(交集是两个集合的二进制代码进行按位逻辑与运算后的二进制代码所代表的事务集合,不再对事务中的项目进行匹配),这就使得寻找两个集合的交集时无需进行循环扫描。XApriori算法避免了对所有项集进行大量的模式匹配计算和循环扫描,提高了时间效率。 4)XApriori算法的连接步和剪枝步可以提前删除不可能包含频繁项集的候选项集,减少了冗余,使得算法的效率得到了较大的提高。 为了测试XApriori算法,用Eclipse分别实现了Apriori和XApriori算法,使用了XML文档解析提取出的关系型数据,该数据的事务数中为1 000,平均每个事务拥的项集数为10。该实验在内存为2 GB,CPU主频为2 200 MHz,操作系统为Windows7的计算机上进行。实验结果如图1所示,可以看出,XApriori算法有了较大的提高。 图1 时间和支持度关系图 本文基于XML文档内容关联规则的挖掘,针对Apriori算法的缺陷,本文设计了一种高效的基于项目事务垂直对应关系的数据结构并且利用Hash表来存储、表示提取出的数据,并通过对Apriori算法的连接步和剪枝步进行了优化改进,提出了一种改进的XApriori算法,该算法应用于XML文档元素值之间关联规则的产生。Apriori算法在运算中需要反复的扫描数据库,造成了非常大的I/O交互负载;在产生新的候选项集时需要反复的对上一级频繁项集进行对比与匹配,造成了运算效率的低下。而XApriori算法在整个过程中只需要扫描一次数据库,有效地降低了I/O交互负载;在生成候选项集的过程中,利用了逻辑运算,使得连接剪枝步运算大大的简化,逻辑运算对于计算机来说,使运算效率更高;在生成候选项集前,可以提前删除不可能包含频繁项集的候选项集,从而规避了冗余运算,使得算法的效率得到了较大的提高。 经过实验证明,XApriori算法有效地提高了Apriori算法的运行效率。 [1]源艳芬,梁慎青.简单介绍可扩展标记语言XML[A]. 电脑知识与技术,2010,20(6):5523-5526. [2] 李 巍. 半结构化数据挖掘若干问题研究[D]. 吉林:吉林大学,2013. [3] 李 露,郑 琪.数据挖掘原理与实践[M]. 北京:电子工业出版社,2011. [4] 熊 平. 数据挖掘算法与Clementine实践 [M]. 北京:清华大学出版社,2011. [5] 苏 勇,王 燕. 基于XQuery的XML文档的关联规则挖掘[J]. 计算机工程与科学,2011,5(10):91-95. [6] Braga D, Campi A, Ceri S. Discovering interesting Information in XML Data with association rules[A]. Proceeding of the 14th International Conference[C].2003,(2454):21-30. [7] Feng L, Dillon T.An XML-enabled association rule framework[A]. Proceeding of the 14th International Conference[C].2003,(2736):88-97. [8] 蔚晓娟. 基于DOM的XML解析与应用[J]. 计算机技术与发展,2007,17(4):86-89. [9] J.Han,M.Kamber .数据挖掘概念与技术[M]. 范 明,孟小峰,译. 北京:机械工业出版社,2007. [10]周艳山.数据挖掘中关联规则的研究与应用[D]. 哈尔滨:哈尔滨工业大学,2005. [11] 胡吉明,鲜学丰.挖掘关联规则中Apriori算法的研究与改进[J].计算机技术与发展,2006,16(4):99-101. [12] 张 婕,张 燕,李广水. 基于Hash表的多谓词约束下频繁项集挖掘[J].微电子学与计算机,2011,28(10):56-59. [13] 黄根平,陈海勇,等. 数据集成中XML模式和关系模式映射模型研究[J]. 信息工程大学学报,2009,10(4):529-531. [14] 崔贯勋,李 梁,王柯柯,等.关联规则中Apriori算法的研究与改进[J].计算机应用,2010,30(11):2952-2955. Research and Improvement of Apriori Algorithm for XML Data Mining Zhang Jirong,Wang Xiangyang (School of Communication, Xi′an University of Posts and Telecommunications, Xi′an 710061,China) Due to its many advantages, XML has rapidly become as a standard for representing and exchanging information in different fields. A large number of XML data has brought new challenges to data mining. Most of the work for mining XML data association rules is based on Apriori algorithm.The basic methods and efficiency of Apriori are analyzed, pointing out its shortcomings and propose the improved XApriori algorithm. The algorithm is based on the new data structure, the use of Hash table and the optimization of Apriori to improve the efficiency of finding frequent item sets. The experimental results show that XApriori is superior to Apriori. XML; data mining; association rules; frequent item sets; Apriori 2015-12-03; 2016-01-05。 张继荣(1963-),女,辽宁沈阳人,博士,教授,硕士生导师,主要从事现代通信网方向的研究。 1671-4598(2016)06-0178-03 10.16526/j.cnki.11-4762/tp.2016.06.049 TP311.13 A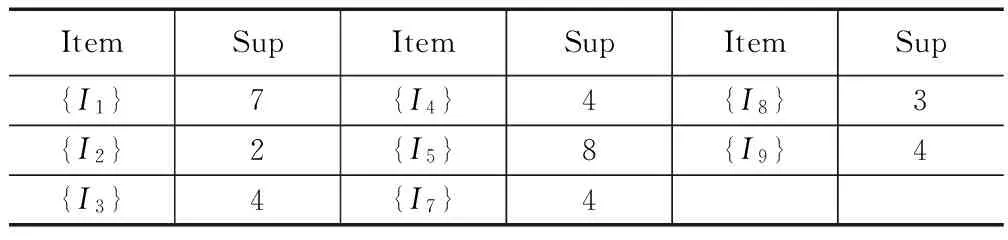




3 算法分析与测试
4 结束语
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15中国交通信息化(2022年10期)2022-11-17 08:19:42中等数学(2021年8期)2021-11-22 07:53:38河南水利年鉴(2020年0期)2020-06-09 05:43:44数学大王·低年级(2019年10期)2019-11-25 08:23:26中等数学(2019年4期)2019-08-30 03:51:44卷宗(2014年5期)2014-07-15 07:47:08计算机工程(2014年6期)2014-02-28 01:26:12长春大学学报(2013年8期)2013-06-21 09:04:04合肥工业大学学报(自然科学版)(2011年2期)2011-03-15 14:30:26
