
社会网络数据中一种基于k-degree-l-diversity匿名的个性化隐私保护方法
2016-11-14 03:27:46焦佳
现代计算机 2016年29期
焦佳
(长沙民政职业技术学院,长沙 410004)
社会网络数据中一种基于k-degree-l-diversity匿名的个性化隐私保护方法
焦佳
(长沙民政职业技术学院,长沙410004)
近年来关于社会网络数据的隐私保护方法中,大部分将社会网络中的所有个体考虑为具有相同等级的隐私保护需求,没有考虑其隐私需求是多样化和个性化的,故会对某些个体存在过度保护,造成数据不必要的失真。基于此,在k-degree-l-diversity匿名方法的基础上提出了个性化-(k,l)匿名方法。实验证明,该个性化匿名方法能减少数据的损失,提高数据的可用性。
个性化匿名;隐私保护;社会网络
0 引言
如今,随着网络技术的发展,越来越多的用户加入不同的在线社会网络,如Facebook、QQ空间和新浪微博等。当发布这些极具分析价值的社会网络数据时,却因攻击者具备某些个体的背景知识时,造成这些个体的个人隐私信息泄露。因此,怎样使发布的社会网络数据具有实用性的同时保护个人的隐私信息已成为目前研究热点之一。
已存在的关于社会网络的研究中,研究者一般用一个图来表示社会网络数据。图中的节点代表社会网络中的个体,图中的边代表个体之间的联系[1-2]。目前许多关于社会网络隐私保护的方法已存在。在攻击者具有节点度的背景知识下,为了抵御个体的重识别,Liu等人[3]提出了k-degree匿名方法。为了抵御个体和个体标签的重识别,在k-degree匿名的基础上,Yuan等人[4]引入了k-degree-l-diversity匿名的方法。但是kdegree-l-diversity匿名方法没有考虑个体的隐私需求是多样化和个性化的,基于此我们提出了个性化-(k,l)匿名方法。
1 问题描述
本文,我们研究的是节点带一个敏感标签和一个隐私属性的无权的无向的简单图的隐私保护问题。且攻击者所具有的背景知识是某个节点的度,其想要重识别某个节点或某个节点的敏感属性。
定义1社会网络图:一个社会网络是一个四元组G=(V,E,L,λ),其中V是图G节点的集合,E⊆V×V是图G节点之间边的集合,L是节点标签的集合,λ:V→L是节点和其标签间的映射函数。
对任意在L中的la,la是一个三元组,即la=(id,s,r),其中id是节点的标识符,s是节点id的敏感标签,r是节点id的隐私需求。隐私需求分为三个层次,即r2,r1,r0,且隐私需求从r2到r0是依次从高到低。
定义2度序列X:一个有n个节点的图G的度序列X是一个n元祖,且其中任一元素X[i]=(id[i],d[i],s[i],r[i])(1≤i≤n),其中id[i]是第i个节点的标识符,d[i]是第i个节点的度,s[i]是第i个节点的敏感标签,r[i]是第i个节点的隐私需求。度序列中的元素先按节点度(X[i].d)从大到小排列,其次按节点隐私需求(X[i].r)从高到低排列。
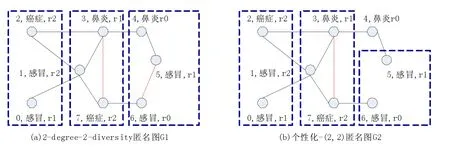
图1 两种匿名方法的发布图
如图1(a),其度序列XG1={(1,4,感冒,r2),(3,4,鼻炎,r1),(7,4,癌症,r2),(0,2,感冒,r1),(2,2,癌症,r2),(4,2,鼻炎,r0),(5,2,感冒,r1),(6,2,感冒,r0)}
定义3 k-degree匿名:对于图中任意一节点v,同一至少存在k-1个其他节点与v有相同的度。如图1(a)所示,图G1是满足2-degree-2-diversity的匿名图,其中节点和节点间红色的线即为满足匿名条件所添加的边(如节点5和节点6间的边)。
定义4 k-degree-l-diversity匿名:对于图中任意一结点v,同一分组中存在至少k-1个顶点和v有相同的度,且具有相同度的这些顶点至少包含l个不同的敏感标签值。如图1(a)所示,图G1也是满足2-degree-2-diversity的匿名图。
定义5个性化-(k,l)匿名:对于图中任意一隐私需求为r2的节点,满足k-degree-l-diversity匿名;对于图中任意一隐私需求为r1的节点,满足k-degree匿名;对于图中隐私需求为r0的节点,可无需匿名。如图1(b)所示,图G2是满足个性化2-degree-2-diversity的匿名图。
经过个性化-(k,l)匿名处理后的发布图,个体重识别的概率不大于1/k,个体敏感标签识别的概率不超过1/l,且满足个体个性化的隐私需求。
2 算法
通过上述定义,实现个性化-(k,l)匿名的算法的伪代码如算法1所示:
算法1个性化-(k,l)匿名的算法
输入:图G的度序列XG,整数k,l(k≥2,l≥2)
输出:满足个性化-(k,l)匿名图G2
1for(v=1;v<=n;v++)
2if(r(v)=r2)
3合并节点v后面的m个节点,使节点v满足k-degree-l-diversity匿名
4将这m+1个节点的追加存入匿名图G2的度序列X_G2;
5v=v+m;
6if(r(v)=r1)
7合并节点v后面的n个节点,使节点v满足k-degree匿名
8将这n+1个节点的追加存入匿名图G2的度序列XG2;
9v=v+n;
10for(任一两节点vi,vj,vi,vj满足(XG2(v).d-XG(v).d≠0))
11在vi,vj间添加边,直至XG2(v).d-XG(v). d=0
3 实验
实验环境采用Windows 8.1中文版操作系统,CPU为2.5Ghz的Intel Core i5,编程语言为C++,运行平台为Microsoft Visual Studio.NET 2010。我们在真实数据集Citation做实验。数据集Citation(http://www.datatang. com/data/17310)包含2555个节点和6101条边,我们用节点的17个出版年份作为节点的敏感属性,且按r2:r1:r0=3:3:4的比例随机分配节点的隐私需求。
图2(a)是数据集Citation在不同的k值(l=5)下两种匿名方法节点度增加代价Costa,因为个性化的匿名方法为了达到匿名要求,不需对所有节点进行度增加,故在相同k和l下Costa更小。图2(b)是数据集Citation在不同k值 (l=5)下按两种匿名方法发布图后的APL与原图的比较,据图可知在相同的k和l下,个性化匿名方法发布后图的APL与原图的APL较非个性化匿名发布后图的APL更接近,即个性化匿名方法发布的图更有实用性。
4 结语
本文基于k-degree-l-diversity匿名方法,提出了满足社会网络个体个性化隐私需求的个性化-(k,l)匿名方法,设计并实现了个性化-(k,l)匿名算法。实验表明,我们的方法能减少代价,提高发布数据的实用性。
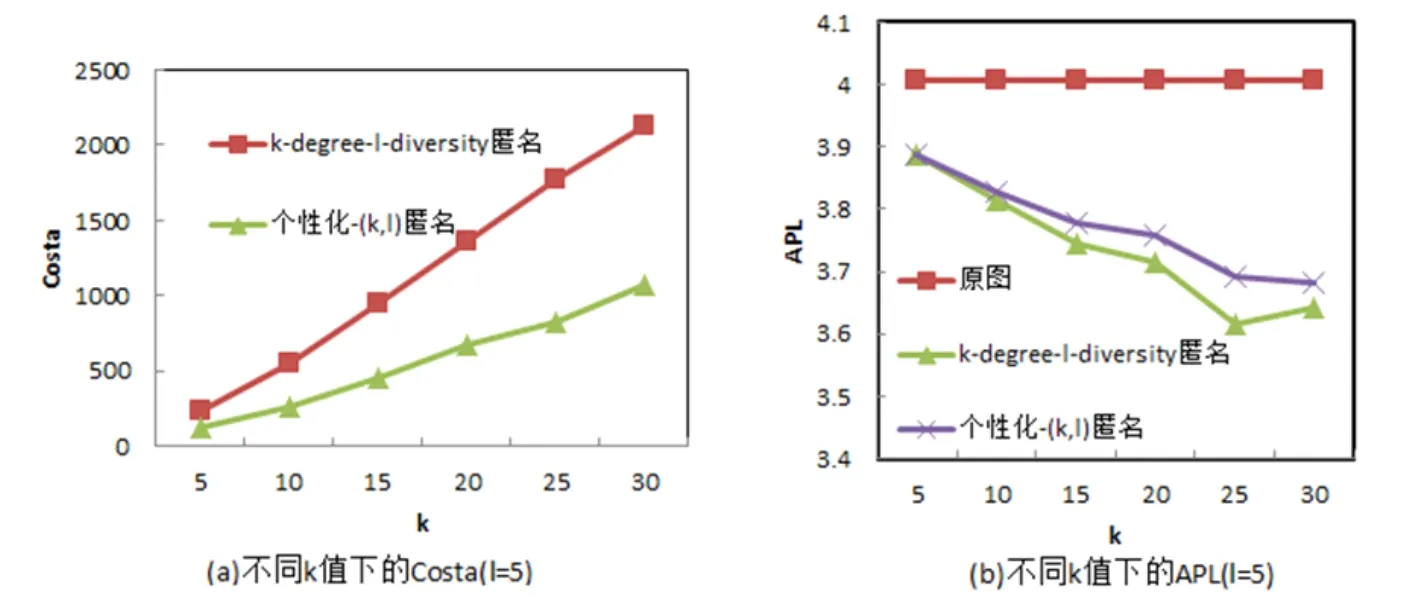
图2 数据集Citation:不同k值下的Costa和APL
[1]Wasserman S.Social Network Analysis:Methods and Applications[M].Cambridge University Press,1994
[2]Liu K,Das K,Grandison T,et al.Privacy-Preserving Data Analysis on Graphs and Social Networks[M].Next Generation of Data Mining.CRC Press,2008:419-437
[3]Liu K,Terzi E.Towards Identity Anonymization on Graphs[C].Proceedings of the 2008 ACM SIGMOD International Conference on Management of data.ACM,2008:93-106
[4]Yuan M,Chen L,Yu P S,Yu T.Protecting Sensitive Labels in Social Network Data Anonymization[J].IEEE Transactions on Knowledge and Data Engineering,vol.25,no.3,pp.633-647,March 2013,doi:10.1109/TKDE.2011.259
Personalized Anonymity;Privacy Preserving;Social Network
A Personalized Privacy Preserving Method Based on k-degree-l-diversity Anonymity for Social Network Data
JIAO Jia
(Changsha Social Work College,Changsha 410004)
In recent research about privacy preserving for social network,most of the methods focus on the same level privacy requirement for all individuals,and do not consider that individuals’privacy requirement is various and personalized.Thus can cause“excessive protection”to some individuals,and then bring unnecessary data distortion.Motivated by this,proposes the personalized-(k,l)anonymity method based on k-degree-l-diversity anonymity method.The experiment shows that the personalized anonymous method can reduce the data distortion and improve the utility of the data.
1007-1423(2016)29-0045-04
10.3969/j.issn.1007-1423.2016.29.010
焦佳(1987-),女,湖南岳阳人,硕士,助教,研究方向为数据安全、隐私保护
2016-08-26
2016-10-10
1007-1423(2016)29-0048-05
10.3969/j.issn.1007-1423.2016.29.011
猜你喜欢
文苑(2020年4期)2020-05-30 12:35:12
劳动保护(2019年7期)2019-08-27 00:41:02
新闻传播(2018年12期)2018-09-19 06:27:10
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
汽车与新动力(2016年6期)2017-01-04 10:50:48
公民与法治(2016年10期)2016-05-17 04:12:58
学习月刊(2015年22期)2015-07-09 03:40:48
计算机工程(2015年8期)2015-07-03 12:20:27
中学科技(2015年1期)2015-04-28 05:06:12
