
基于阴性选择算法的改进模型
2016-11-12 05:06:30傅龙天陈腾林
黑龙江工程学院学报 2016年5期
傅龙天,陈腾林
(1.福州外语外贸学院,福建 福州 350011;2.闽江学院,福建 福州 350011)
基于阴性选择算法的改进模型
傅龙天1,陈腾林2
(1.福州外语外贸学院,福建 福州 350011;2.闽江学院,福建 福州 350011)
人工免疫学中的阴性选择算法是其核心算法,在各行业应用广泛。但其不足之处也越来越明显,例如在训练样本选择方面、训练学习算法方面,都有可能影响检测精度。训练学习算法中引入半监督学习机制,并在样本选择上扩展训练样本来源,使训练学习更有针对性。仿真实验证明改进后的模型能提高检测率,并具备较强的自适应能力。
阴性选择算法;人工免疫;半监督学习
1974年丹麦学者Jeme提出了第一个人工免疫数学模型[1],后来Forrest等[2-3]提出了阴性选择算法和计算机免疫学概念,Lee等[4-5]人通过从程序入口点开始提取一系列字符串区分自体与非自体,以实现病毒检测,推动了计算机免疫系统的全面发展。虽然到目前为止阴性选择算法在各领域解决了很多问题,但算法本身仍然存在一些不足之处,例如训练成熟检测器时,当训练样本(已知的自我集)比较少,即训练学习不够充分,可直接影响检测精度。只有在理想状态下,随机生成的未成熟检测器,经过自体耐受学习,经历淘汰后存活的成为成熟检测器,并不断迭代该过程,获得足够的成熟检测器才能取得良好的检测效果。但在实际应用中是不现实的,用于训练学习的样本往往很少,并且有标记的更少或较为昂贵,这就导致阴性选择算法的误检、漏检现象。
目前,Watkins和Timmis[6]对人工免疫算法进行了并行性改造,增强了算法的并行能力;舒才良等[7]提出了在数据不完备情况下的改进算法,引入了分类器融合投票决策思想;翟宏群等[8]利用模糊思想,采用最优搜索原理有效地减低了黑洞数量;伍海波[9]通过改进成熟检测器的生成机制及改变匹配阀值,来解决成熟检测器生成效率低和容易产生黑洞问题。上述学者的各种改进措施都起到了一定的效果,但未考虑训练样本较少的情况下如何提高检测率问题,为了解决该问题本文在自体耐受学习过程中引入半监督学习算法,通过少量已标记的样本和若干未标记样本的学习,提高检测精度。
1 阴性选择算法及其分析
自然界大部分生物存在天然的免疫机制,当生物体第一次遭遇抗原时将发生初次应答,生物体通过学习,完成自体耐受过程,产生免疫记忆;当第二次遭遇相同抗原时激发二次应答,识别该抗原[10]。计算机领域借鉴该免疫机制形成了人工免疫识别系统(AIRS),阴性选择算法是其核心算法之一,算法描述如下:
步骤1:初始化训练样本,未成熟检测器由系统随机生成,然后与自体集匹配,如果匹配成功则淘汰,存活则加入成熟检测器。
步骤2:重复迭代步骤1,直到生成足够的成熟检测器。
步骤3:利用成熟检测器集检测待检样本,如果匹配成功,则识别成功。
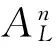
2 改进模型E-AIRS
2.1模型定义
阴性选择算法的训练样本来源于随机生成的数据,大量的非自体集合数据未参与训练。半监督学习是利用未标记数据的一种主流学习技术,它能够在不加外界干预的情况下,自动地利用少量已标记数据和大量未标记数据进行学习[11-12]。本文引入自体集和非自体集作为训练样本,使训练样本来源更具代表性。把少量的自体集定义为已标记(Labeled)集合,若干非自体抗原定义为未标记(Unlabeled)集合。利用这两种集合进行训练学习。其形式化定义如下所示:
定义1:设已标记集合为L、未标记集合为U,描述如下:
其中:对于已标记样本,yi为xi的标记。L为已标记样本数,n为所有样本数。
定义2:相似度(Similarity)矩阵,定义一个n×n的矩阵W,用于计算任意两个样本之间的相似度,描述如下:
(1)

定义3:设概率转移(ProbabilityTransition)矩阵T为n×n的矩阵,用于计算xj到xi的概率,然后归一化(Row-normalized),其中k表示累计求和的下标变量,描述如下:
(2)
(3)

(4)
(5)
定义5:传播公式,通过T和Y相乘,迭代多次后,如果Y矩阵中第i列值接近1,则可把xj划归为ci分类,加入到已标记集合中。描述如式(6)所示,其中t表示迭代指数,Y为第t次迭代结果。
(6)
定义6:检测函数采用阴性选择算法原有的匹配规则,即r连续位(r-contiguousbits)匹配规则。成熟检测器与非自体抗原匹配操作描述如下:
(7)
式中:Ag表示非自体抗原,fmatch(L,Ag,r)表示r连续位匹配函数,r表示匹配阀值。当fdetect(L,Ag)返回1时表示检测器识别了该抗原。
2.2模型算法实现
本模型涉及两个算法:训练学习算法和检测算法。训练学习过程引入半监督学习机制,把训练样本分成已标记(自体集)和未标记样本(非自体抗原),通过学习训练,产生成熟检测器,然后利用r连续位匹配函数实现样本检测。
2.2.1训练学习算法
半监督学习算法包括多种学习算法,本文采用基于图(graph-based)的半监督学习。利用已标记和未标记的样本构造图(graph),边缘(edges)表示结点的相似度,已标记结点根据相似度来传播,并标记所有未标记的结点。为实现该过程,先定义相似度矩阵(见式(1)),经过一序列的变换处理操作(见式(2)~式(5)),最后根据传播公式(见式(6))得到成熟检测器。其算法描述(伪代码描述)如下:
输入:已标记集合和未标记集合
输出:成熟检测器
Procedure TrainOperation ()
Begin
BuildGraph(); //根据已标记集合L和未标记集合U构造图
ComputeSimilarityValue();//根据式(1)计算相似度
ComputeProbability(); //根据式(2)计算概率
RowNormalized(); //根据式(3)归一化
BuildVertices(); //根据式(4)、式(5)构造矩阵Y,用于初始化顶点
Propagate(); //根据式(6)循环迭代,生成成熟检测器
Output(); //返回成熟检测器
End;
2.2.2检测算法
从训练学习算法获得了足够的成熟检测器后,可对外来非自体抗原进行检测。检测算法采用原阴性选择算法的匹配规则,即r连续位(r-contiguousbits)匹配规则。预先设置匹配阀值r,r的值大一些匹配精度较高,但样本检测时容易出现漏检现象,在实际应用中可根据需要设定,其伪代码描述如下:
输入:非自体抗原和成熟检测器集
输出:被识别的抗原
Procedure Detection()
Begin
Flag = 0; //定义是否识别的标记
While 循环变量 do //在成熟检测器中循环匹配
{
If(Detect()) //根据式(7)进行匹配。
Flag = 1; //如果非自体抗原与成熟检测器匹配,则标记变成1
}
If(Flag == 1)
Output(); //返回已识别的抗原
End;
3 仿真实验
为了验证本模型的性能,本文设计了一个模拟仿真实验,以收集的真实实验数据为基础,并与阴性选择算法进行对比,来分析E-AIRS模型的性能。
3.1实验环境
使用IBM服务器X3650M4 7915i31作为实验机,主要配置:CPU为Intel至强E5-2600,内存4 GB,500 GB硬盘,操作系统为Microsoft Windows2003,云平台使用Google Compute Engine,开发工具为Visual Studio2010。为了保证实验机纯净环境,除操作系统自带软件外,不再安装其它软件。
本文选取美国哥伦比亚大学的数据测试集(2D Synthetic Data)[13],从中选取500个病毒样本,其中250个样本包含其特征码作为已标记样本集合,另250个样本不包含特征码作为未标记样本集合;300个正常程序样本作为自体集合;从已标记样本集合随机抽取150个样本,再从未标记样本集合随机抽取150个样本,共同组成300个非自体抗原集合。
3.2实验结果及分析
为了得到真实可靠数据,进行了两组实验,每组实验进行50次,取平均值。第一组实验随机选取已标记样本40个,未标记样本160个,共200个训练样本,即已标记样本占20%,实验得到的检测率和误检率如图1所示;第二组实验随机选取已标记样本160个,未标记样本40个,共200个训练样本,即已标记样本占80%,实验得到的检测率和误检率如图2所示。
从图1(a)和图2(a)可以看出,本文提出的E-AIRS模型在训练样本比较少的情况下(两组实验都只有200个训练样本)比阴性选择算法的检测率更高,特别是在训练学习不够充分时(即成熟检测器较少)检测率明显更高,因为E-AIRS模型引入半监督学习算法,其分类精度更高,并且在选择训练样本时引入了非自体抗原集中的数据(即未标记样本),因此,训练样本更具代表性;从图1(a)和图2(a)可看出两条曲线之间的距离,图1(a)的距离更大,例如:图1(a)有100个成熟检测器时检测率分别是53%和72%,相差19%,而图2(a)分别是72%和81%,相差9%,这说明已标记训练样本较少时,E-AIRS模型相对阴性选择算法的检测效果更好。
从图1(b)和图2(b)可以看出,E-AIRS模型相对阴性选择算法误检率较低一些,而E-AIRS模型只改进了训练学习过程,未修改检测操作的匹配规则,所以E-AIRS模型误检率低说明其训练学习过程更有效;图1(b)和图2(b)的两曲线之间的距离是图1(b)较大,说明在已标记训练样本较少时误检率更低,E-AIRS模型的优势更明显。

图1 已标记样本占20%的检测率比较
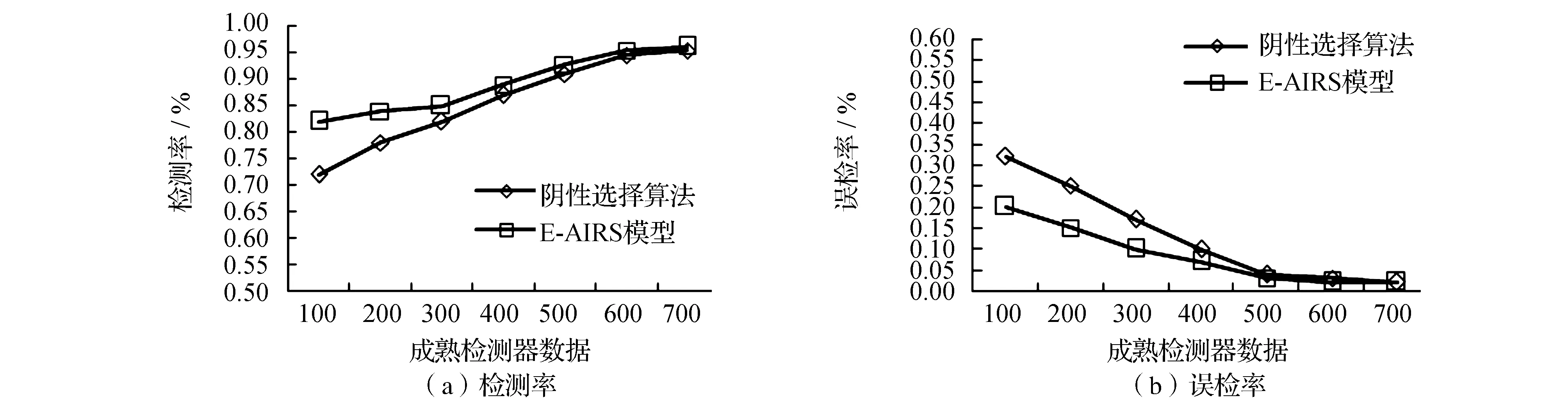
图2 已标记样本占80%的检测率比较
4 结束语
本文针对阴性选择算法的不足提出了一个改进模型E-AIRS,该模型引入半监督学习机制,扩展了训练样本来源,使训练样本更具代表性,改善了训练学习过程。通过仿真实验证明E-AIRS模型相对于阴性选择算法,在已标记样本较少的情况下检测精度较高,并且误检率较低;另外,本模型对训练样本的要求较低(只需要少量的已标记样本),更贴近现实,增加了进一步应用推广的可能性。
[1]AYDIN I,KARAKOSE M,AKIN E.An adaptive artificial immune system for fault classification [J].Journal of Intelligent Manufacturing,2012,23(5): 1489-1499.
[2]CHANG S Y,YEH T Y.An artificial immune classifier for credit scoring analysis [J].Applied Soft Computing,2012,12(2): 611-618.
[3]NICHOLAS W,PRADEEP R,GREG S,et al.Artificial immune systems for the detection of credit card fraud: an architecture,prototype and preliminary results[J].Information Systems Journal,2012,22(1): 53-76.
[4]BINH L N,HUYHN T L,PANG K K.Combating Mobile Spam through Botnet Detection using Artificial Immune Systems[J].Journal ofUniversal Computer Science,2012,18(6): 750-774.
[5]SAMIGULINA G A.Development of decision support systems based on intellectual technology of artificial immune systems[J].Automation and Remote Control,2012,73(2): 397-403.
[6]WATKINS A,TIMMIS J.Exploiting parallelism inherent in AIRS,an artificial immune classifier[EB/0L].(2012)[2012-01].http://www.cs.kent.ac.uk/?abw5/.
[7]舒才良,严宣辉,曾庆盛.不完备数据下的免疫分类算法[J].计算机工程与应用,2012,48(20):172-176.
[8]翟宏群,冯茂岩.一种改进的变阈值阴性选择免疫算法[J].南京师范大学学报(工程技术版),2011,11(3):78-82.
[9]伍海波.一种改进的否定选择算法在入侵检测中的应用[J].计算机应用与软件,2013,30(2): 174-176.
[10]郭蓉,姜童子,黄葵.Aβ3-10s基因疫苗免疫AD小鼠诱导Th2型免疫反应的研究 [J].中风与神经疾病杂志,2013,30(5):112-118.
[11]周志华.基于分歧的半监督学习[J].自动化学报,2013,30(11):123-129.
[12]年素磊,黎铭,杜科,等.基于主动半监督学习的智能电网信调日志分类[J].计算机科学,2012,39(12):167-170.
[13]程春玲,柴倩,徐小龙,熊婧夷.基于免疫协作的P2P网络病毒检测模型[J].计算机科学,2011,38(10):60-63.
[责任编辑:郝丽英]
The improved model based on negative selection algorithmFU Longtian1,CHEN Tenglin2
Artificial immunology loyalty is the core algorithm of negative selection algorithm,which has been widely applied to various industries.But its deficiency is becoming more and more noticeable,such as the training sample selection and learning algorithm are likely to influence the accuracy of detection.Learning algorithm is introduced in this paper as a semi-supervised learning mechanism,of which the training sample source in the sample selection is expanded to make the training more targeted.Simulation experiment proves that the improved model can improve the detection rate,and have strong adaptive capacity.Key words:negative selection algorithm; artificial immune; semi-supervised learning
10.19352/j.cnki.issn1671-4679.2016.05.014
2016-05-16
傅龙天(1976-),男,讲师,研究方向:信息安全.
TP301.6
A
1671-4679(2016)05-0050-04
(1.Fuzhou College of International Studies and Trade,Fuzhou 350011,China;2.Minjiang University,Fuzhou 350011,China)
猜你喜欢
科技创新与应用(2020年6期)2020-02-29 10:39:27
中国交通信息化(2017年9期)2017-06-06 07:14:57
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
工业设计(2016年11期)2016-04-16 02:49:43
感染、炎症、修复(2015年2期)2015-12-10 02:37:59
实用手外科杂志(2015年1期)2015-08-27 01:52:06
中国医疗美容(2015年1期)2015-07-12 10:06:41
河南科技(2014年22期)2014-02-27 14:18:12
