
一种基于极限学习机的在线负增量算法
2016-11-09 01:19谢林森任婷婷卢诚波
计算机应用与软件 2016年9期
谢林森 任婷婷 卢诚波
1(丽水学院工程与设计学院 浙江 丽水 323000)2(浙江师范大学数理与信息工程学院 浙江 金华 321004)
一种基于极限学习机的在线负增量算法
谢林森1任婷婷2卢诚波1
1(丽水学院工程与设计学院浙江 丽水 323000)2(浙江师范大学数理与信息工程学院浙江 金华 321004)
在剔除影响单隐层前馈神经网络性能的“脏数据”后,传统的极限学习机算法需要重新训练整个网络,这会增加很多额外的训练时间。针对这一问题,在传统的极限学习机算法的基础上,提出一种在线负增量学习算法:剔除“脏训练样本”后,不需要再重新训练整个网络,而只需在原有的基础上,通过更新外权矩阵来完成网络更新。算法复杂性分析和仿真实验的结果表明所提出的算法具有更高的执行速度。
极限学习机负增量算法算法复杂性仿真实验
0 引 言
人工神经网络是生物神经网络的数学模型,简称神经网络。而前馈神经网络是神经网络中一种典型的分层结构,其中单隐层前馈神经网络SLFNs(single hidden layer feedforward networks)因其算法简单、容易实现,且具有强大的非线性辨识能力而受到特别的重视[1]。SLFNs最常用的学习方法是BP算法[2]和支持向量机SVM算法[3],BP算法在应用过程中需要对权重、偏差等大量参数进行设置,并且存在训练速度慢、易陷入局部极值、过拟合等问题,支持向量机尽管较BP神经网络运算时间短、精度高,但是其同样需要进行多参数的选择,如核函数、惩罚系数、误差控制等。
近年来,Huang为SLFNs提出了一种称为极限学习机ELM的学习方法[4-8]:设置合适的隐藏层结点数,为输入权值和隐藏层偏差进行随机赋值,然后通过最小二乘法得到输出层权值。整个过程一次完成,无需迭代,极限学习机在保证网络具有良好泛化性能的同时,极大地提高了学习速度,同时避免了由于梯度下降算法产生的问题,如局部极小、过拟合、学习时间长、需要大量的参数设置等[2,9]。
在极限学习机的基础上,Liang等人于2005年提出了一种在线学习的增量算法OS-ELM[10]。该算法可以在新样本到来的时候,通过更新输出权值矩阵来完成网络的更新,而无需重新训练整个网络,具有学习速度快等优点。
在极限学习机的实际应用中,如果在训练网络完成后,发现一些影响网络质量的数据:如“脏数据”、重复数据,需要对其进行剔除,从而优化网络结构。如果直接利用极限学习机重新训练,这会增加很多额外的训练时间。受文献[10]的启发,本文提出了一种在线负增量学习算法,当剔除这些“脏数据”后,不需要再重新训练整个网络,而只需在原有的基础上,通过更新外权矩阵来完成网络的更新,从而减少运算代价,提高执行速度。本文分别从算法复杂性和仿真实验两方面分析验证该负增量算法比传统的极限学习机算法具有更好的执行速度。
1 极限学习机简介
极限学习机是一种基于SLFNs的高效学习算法。对于SLFNs[11],假设有N个样本(xi,ti),
xi=[xi1,xi2,…,xin]T∈Rn,ti=[ti1,ti2,…,tim]T∈Rm
则有L个隐藏结点的SLFNs可以表示为:
其中ai=[ai1,ai2,…,ain]T是连接第i个隐藏层结点的输入权值;bi是第i个隐藏层结点的偏差;βi=[βi1,βi2,…,βim]T是连接第i个隐藏层结点的输出权值;ai·xj表示ai和xj的内积,激励函数g(x)可以是任意有界的非常量连续函数。
如果g(x)无限可导,理论上SLFNs能以一个极小的误差逼近N个训练样本[5],且对于任意给定的ai和bi,有:
(1)
上述N个方程的矩阵形式可写为:Hβ=T,其中,H是该神经网络隐藏层结点的输出矩阵,β为输出权值矩阵,T为期望输出,具体形式如下:
H(a1,…,aL,b1,…,bL,x1,…,xN)
(2)
(3)
在极限学习机算法中,隐藏层的输入权值ai和阈值bi可以随机给定,因此只需求出输出权值矩阵β即可完成网络的训练,输出权值矩阵β可由式(4)得到:
(4)
2 在线负增量算法及其应用
(5)

在训练网络后,如果发现其中有N1个影响网络性能的“脏训练样本”,为了提高网络的质量,则需要剔除这N1个“脏数据”。设N1个“脏数据”的隐层结点输出矩阵是H1,期望输出是T1;剩余的N0个训练样本的隐层结点输出矩阵是H0,期望输出是T0,输出权值矩阵是β(0),则可得:
(6)
则由式(5)可得:
(7)
令:
(8)
(9)
则:
(10)
(11)
可得:
(12)
由式(5)、式(12)可得剔除“脏数据”样本后,由文中提出的在线负增量算法得到的输出权值矩阵β(0)表达式:
(13)
对应地,如果直接用传统的极限学习机算法重新训练剩余的N0个训练样本,则可得极限学习机得到的输出权值矩阵β(0)表达式:
(14)
(15)
(16)
2.1算法时间复杂性分析
下面对本文提出的算法与传统的极限学习机算法进行复杂性比较。
对于在线负增量算法:

则H1的计算量是:LN1n;




L3+2L2m+L2N1+LN1n

即Tnew的最大计算量:
对于极限学习机:
则H0的计算量是:LN0n;

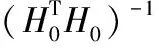


L2m+L3+L2N0+LN0n+LN0m

即Telm的计算量:
则可得:
Q2-Q1=L2(N0-N1-m)+Ln(N0-N1)+LN0m
只要N0>N1+m,则Q2>Q1,即只要剔除“脏训练数据”后的剩余训练数据个数大于剔除样本个数与网络输出维数之和(一般情况下,当训练样本较大时,该条件易满足),就可以得到Tnew计算量小于Telm的计算量,也就是相对于传统的极限学习机算法,本文算法提高了执行速度。
2.2仿真实验
本文通过仿真实验结果验证在线负增量算法的优良性能。实验的运行环境是Matlab 2013a,CPU主频是2.2 GHz,RAM 4.00 GB。神经网络激励函数是“Sigmoid”函数:g(x)=1/(1+exp(-x)),人工数据“SinC”的表达式如下:

在回归的实验中,用的数据集是:人工数据“SinC”,UCI数据库中的abalone数据集[12]和wine quality数据集[13];实验数据的输入归一化到[-1,1],实验数据的输出归一化到[0,1]。在分类的实验中,用的数据集是:handwritten digits 数据集、satellite image数据集[12]和image segmentation数据集[12];实验数据的输入归一化到[-1,1],数据集具体信息见表1所示。

表1 数据集信息
2.2.1回归问题
在回归问题的应用中,测试结果包括本文算法和极限学习机求解测试样本的实际输出与期望输出的均方根误差RMSE(root-mean-square error),以及两种算法求解测试样本实际输出所需的时间。在实验中,采用的数据集是:人工数据“SinC”、abalone数据集[12]和wine quality数据集[13],隐层结点个数均是200,见表1所示,其中人工数据“SinC”是在区间(-10,10)内随机产生5000个训练样本和2000个测试样本。
当剔除训练样本时,输入权值矩阵和阈值随机产生,且随机进行10次实验并将两种算法平均的RMSE进行统计。从表2可以看出,当剔除相同数量的样本时,两种算法的RMSE近似相等,且均比较小,表明当剔除训练样本后,两种算法都具有较好的泛化性能。图1给出了这两种算法的测试时间,可见本文提出的算法比传统的极限学习机算法所需时间少。

表2 两种算法的测试结果的均方差(RMSE)

图1 两种算法的测试结果所需时间
2.2.2分类问题
在分类应用中,测试结果包括两种算法求解测试样本实际输出的分类正确率,以及求解测试样本实际输出所需要的时间。实验选用的数据集是:handwritten digits 数据集、satellite image数据集[12]和image segmentation数据集[12],隐层结点个数分别是250、500、200,见表1所示。
当剔除训练样本时,输入权值矩阵和阈值随机产生,且随机进行10次实验并将两种算法平均的分类正确率进行统计,见表3所示。从表3可以看出,当剔除相同数量的样本时,两种算法的分类正确率相差无几,并且handwritten digits 数据集的分类正确率均在86%以上,satellite image数据集的分类正确率则在88%以上,而image segmentation 数据集的分类正确率高达95%以上。图2给出了这两种算法的测试时间,可见本文的在线负增量算法比传统的极限学习机算法所需时间少,执行速度快。

表3 两种算法的测试样本分类正确率(%)

图2 两种算法的测试结果所需时间
3 结 语
在极限学习机训练单隐层前馈神经网络模型的实际应用中,剔除影响网络性能的“脏数据”后,传统的极限学习机算法需要重新训练整个网络,这会增加很多额外的训练时间。本文提出了一种在线负增量学习算法,在剔除“脏数据”后,不需要再重新训练整个网络,而只需在原有的基础上,通过更新输出矩阵来完成网络的更新。在计算测试结果之后,无需重新计算,剔除后的测试结果只需在原测试结果的基础上进行更新,从而减少运算代价,提高执行速度。通过仿真实验从分类和回归的应用两方面验证了文中算法的速度优势。本文只进行了算法的时间复杂性分析,在以后的工作中进一步研究空间复杂度。除此之外,对于影响网络性能的“脏数据”,文中研究了剔除这些数据后,不需要重新训练整个网络的在线负增量算法。如果用一些优良数据替换这些“脏数据”,并且利用不需要重新训练整个网络的在线学习方法,是否可以得到更好的泛化性能,且具有较好的执行速度,这是未来工作中另一个可以研究的方向。
[1] Sanger T D.Optimal unsupervised learning in a single-layer linear feedforward neural network[J].Neural networks,1989,2(6):459-473.
[2] Chauvin Y,Rumelhart D E.Backpropagation: theory,architectures,and applications[M].Psychology Press,1995.
[3] Cortes C,Vapnik V.Support vector networks[J].Machine Learning,1995,20(3):273-295.
[4] Huang G B,Zhu Q Y,Siew C K.Extreme learning machine:a new learning scheme of feedforward neural networks[J].Neural Networks,2004,2:985-990.
[5] Huang G B,Zhu Q Y,Siew C K.Extreme learning machine:theory and applications[J].Neurocomputing,2006,70(1-3):489-501.
[6] Huang G B,Zhou H,Ding X,et al.Extreme learning machine for regression and multiclass classification[J].Systems,Man,and Cybernetics,Part B:Cybernetics,IEEE Transactions on,2012,42(2):513-529.
[7] Peng D,Zhu Q.Extreme learning machine-based functional link network[C]//Intelligent Control and Automation (WCICA),2014 11th World Congress on.IEEE,2014:5785-5790.
[8] Huang G B.An insight into extreme learning machines:random neurons,random features and kernels[J].Cognitive Computation,2014,6(3):376-390.
[9] Haykin S S.Neural networks and learning machines[M].Upper Saddle River:Pearson Education,2009.
[10] Liang N Y,Huang G B,Saratchandran P,et al.A fast and accurate online sequential learning algorithm for feedforward networks[J].Neural Network,IEEE Transaction on,2006,17(6):1411-1423.
[11] Huang G B.Extreme learning machine:learning without iterative tuning[D/OL].School of Electrical and Electronic Engineering,Nanyang Technological University,Singapore,2010.http://www.extreme-learning-machines.org/.
[12] Lichman M.UCI Machine Learning Repository[D/OL].Irvine,CA:University of California,School of Information and Computer Science,2013.http://archive.ics.uci.edu/ml.
[13] Cortez P,Cerdeira A,Almeida F,et al.Modeling wine preferences by data mining from physicochemical properties[J].Decision Support Systems,2009,47(4):547-553.
AN ONLINE NEGATIVE INCREMENTAL ALGORITHM BASED ON EXTREME LEARNING MACHINE
Xie Linsen1Ren Tingting2Lu Chengbo1
1(School of Engineering and Design,Lishui University,Lishui 323000,Zhejiang,China)2(SchoolofMathematicsPhysicsandInformationEngineering,ZhejiangNormalUniversity,Jinhua321004,Zhejiang,China)
After weeding out the dirty data that affecting the performance of single hidden layer feedforward network, traditional extreme learning machine has the need to train the entire networks. However, this will increase a lot of extra training time. In light of this issue, the paper proposes an online negative incremental algorithm based on traditional extreme learning machine algorithm:after the “dirty training sample” being eliminated, there has no need to train the whole networks once again, but only need to accomplish the network update by updating output weights matrix on the basis of original. The complexity analysis of the algorithm and the result of simulation experiment show that the proposed algorithm has higher execution speed.
Extreme learning machineNegative incremental algorithmAlgorithm’s complexitySimulation experiment
2015-05-07。国家自然科学基金面上项目(11171137);浙江省自然科学基金项目(LY13A010008)。谢林森,教授,主研领域:逼近论,人工神经网络。任婷婷,硕士。卢诚波,副教授。
TP3
A
10.3969/j.issn.1000-386x.2016.09.063
猜你喜欢
电子制作(2021年14期)2021-08-21
科技创新与应用(2020年6期)2020-02-29
测控技术(2018年10期)2018-11-25
自动化学报(2018年2期)2018-04-12
数学物理学报(2018年1期)2018-03-26
制造技术与机床(2017年4期)2017-06-22
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
郑州大学学报(理学版)(2014年2期)2014-03-01
