
内核多线程直接存储PCIE驱动设计
2016-11-09 01:11王仕明严发宝徐智勇付承毓
计算机应用与软件 2016年9期
王仕明 严发宝 徐智勇 付承毓
1(中国科学院光电技术研究所光束控制重点实验室 四川 成都 610209)2(中国科学院大学 北京 100039)3(中南大学地球科学与信息物理学院 湖南 长沙 410083)
内核多线程直接存储PCIE驱动设计
王仕明1,2严发宝3徐智勇1付承毓1
1(中国科学院光电技术研究所光束控制重点实验室四川 成都 610209)2(中国科学院大学北京 100039)3(中南大学地球科学与信息物理学院湖南 长沙 410083)
在Linux系统中,高速存储驱动会将大量数据从内核空间复制到用户空间进行存储,这将导致存储速度下降和剧烈波动。针对该问题,结合自行设计开发的PCIE接口高速图像存储系统,分析Linux下PCIE驱动的一般组成及实现,提出一种在驱动中实现多线程多缓存直接存储的方法。首先图像数据乒乓DMA传输到双DMA缓存中,然后将数据乒乓转存到内核空间双大缓存中,最后由内核线程直接写入SSD。经该方法优化后的SSD存储速度达到100 MB/s以上,比常规方法提升了65%以上。在实际工程中,输入512×512@200 Hz的14位灰度图像能够实现稳定存储,避免了原来的丢帧现象,且性能稳定,取得了良好的优化效果。
图像存储PCIEDMALinux驱动多线程
0 引 言
在光电检测和跟踪中,高帧频、高分辨率相机得到了广泛的应用,在提高检测和跟踪精度的同时也对图像存储系统速度及稳定性提出了更高的要求[1]。某些系统要求存储系统放置在设备内部,这对系统的体积提出了更高要求。自行研制的PCIE接口高速图像存储系统满足了体积小、速度快而稳的要求。PCIE采用了点对点串行连接, 比起 PCI 以及更早期的计算机并行总线的共享架构,每个设备都有自己的专用连接, 不需要向整个总线申请带宽, 而且由于差分信号抗干扰性强,可以把数据传输率提高到极高的频率[2]。PCIE用途广泛、标准化程度高、通用性强。
Linux操作系统代码开源,能轻松移植到多种平台上,占用资源较少,是嵌入式设备的一个好选择[3]。另外,Linux在硬盘读写和网络通信方面,可靠性和性能均十分优越,所以本存储系统选用Linux作为操作系统。而驱动是连接硬件与操作系统的纽带,是图像存储系统的核心和灵魂,是可靠性和性能的关键。因此本文结合实例详细介绍PCIE接口的Linux驱动各组成部分与实现,重点阐明内核多线程直接存储的实现方法。
1 硬件系统
本高速存储系统以PowerPC为控制核心,由图像采集单元Frame Grabber、FPGA实现的PCIE接口DMA控制器、mSATA接口固态硬盘(SSD)及千兆网接口几个部分组成。如图1所示,图像采集单元将高速图像数据传给FPGA的FIFO中。FPGA还实现了PCIE接口的DMA控制器,PCIE为2.5 GB/s的X4链路,理论总带宽10 GB/s。当运行在PowerPC上的Linux驱动发送DMA开始信号后,将图像数据传入PowerPC的内存中,再由应用程序存入到挂载在PowerPC处理器SATA接口上的SSD中。千兆网用来实现与远程计算机之间的通信控制和远程显示。
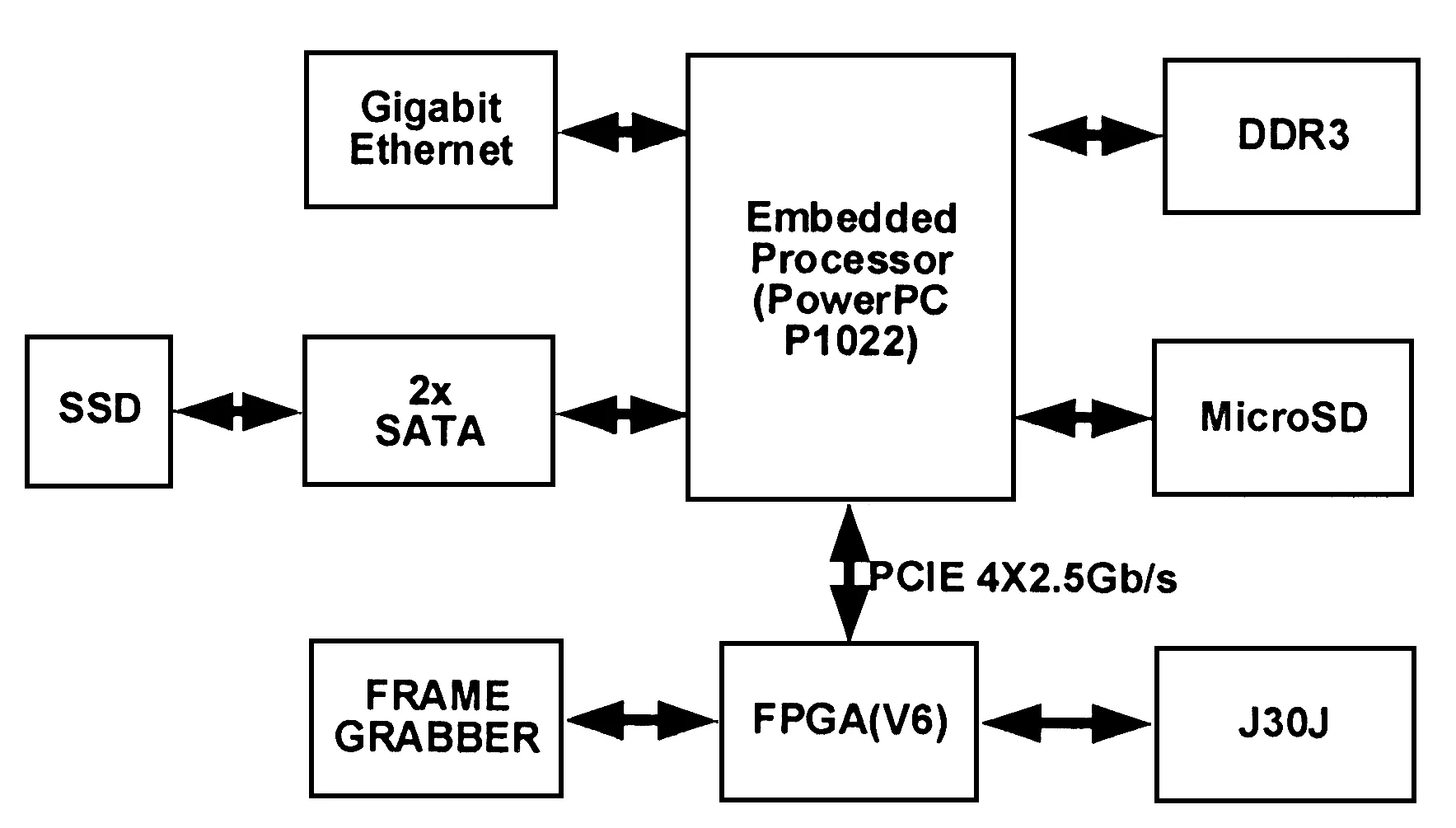
图1 高速存储系统结构框图
2 PCIE驱动
2.1PCIE驱动实现
PCIE接口DMA控制器是字符型设备,PCIE总线作为设备与主控制器之间的高速通道,在驱动中需实现PCIE设备和字符设备驱动双重功能[4]。在PCIE接口DMA控制器驱动中,不仅要实现PCIE的驱动,还需重点实现文件操作字符设备驱动,即 file_operations成员的实现并注册 chr_dev。
DMA采用的是主总线 DMA传输方式,读写都是相对控制器来说的,即写操作是由PCIE设备到内核内存,读是由内核内存到PCIE设备。PCIE接口DMA控制器的驱动组成如图2所示。驱动主要由驱动加载和卸载、中断处理及字符设备文件操作函数组成。

图2 PCIE驱动主要流程
驱动加载的主要步骤如图2(a)所示,关键实现代码及解析如下,每步均需检测是否完成,如出错则需返回出错信息并退出;成功则置申请的资源位,方便模块卸载时判断并释放相应资源。
如申请中断:
stat_flags = stat_flags | HAVE_IRQ;(HAVE_IRQ=4)
注册pci_dev结构体:
gDev = pci_get_device (PCI_VENDOR_ID_XILINX, PCI_DEVICE_ID_XILINX_PCIE, gDev); //根据厂商ID和设备ID找到PCI设备,自动
//扫描配置空间,填入pci_device结构体
使能MSI中断:
pci_enable_msi(gDev);
//MSI中断号会自动填入,pci_dev的irp
//中,即gDev->irq
获取中断号并绑定中断处理程序:
gIrq = gDev->irq;
request_irq(gIrq, (irq_handler_t)(& PCIe_DMA_IRQHandler), IRQF_SHARED | IRQF_SAMPLE_RANDOM, gDrvrName, gDev);
申请DMA缓存:
gReadBuffer = pci_alloc_consistent(gDev, DMA_SIZE, &gReadHWAddr);
gWriteBuffer = pci_alloc_consistent(gDev, DMA_SIZE, &gWriteHWAddr);
字符设备初始化:
register_chrdev(gDrvrMajor, gDrvrName, &PCIe_DMA_file);
PCIe_DMA_file为文件操作结构体,如图2(c)所示,包括读、写、设备控制、打开和释放函数,每个函数需独立实现,如ioctl(设备控制)函数如下:
int PCIe_Ioctl(struct inode *inode, struct file *filp, unsigned int cmd, unsigned long arg)
{
u32 regx;
int ret = SUCCESS;
switch (cmd) {
case RDDCSR:
//读设备状态控制器
regx = XPCIe_ReadReg(0);
*((u32 *)arg) = regx;
break;
⋮
}
DMA初始化
PCIe_WriteReg(2, gWriteHWAddr0);
//写TLP起始地址寄存器
PCIe_WriteReg(3, TLPSIZE);
//写TLP大小寄存器
PCIe_WriteReg(4, TLPCOUNT);
DMA完成后会自动中断,中断处理函数流程如图2(b)所示,通过DDMACR等寄存器即可完成,释放信号量即可唤醒等待读取数据的应用进程。应用进程读数时会调用copy_to_user函数,将数据由内核空间拷贝到应用空间。
2.2速度测试及分析
将FPGA产生的模拟图像数据写入SSD,在速率为60 MB/s时即频繁丢帧。这是由于大量数据需从内核空间拷贝到应用空间,频繁在内核模式和用户模式之间切换,占用了太多的资源及时间,加上应用程序常常不能被及时调度更加剧了速度的不稳定性。因此提出了内核多线程多级缓冲直接存储到SSD的方法。
3 内核多线程多级缓冲直接存储的实现
3.1内核直接存储的优势
常规的驱动在DMA完成时,仅将数据传入驱动的DMA缓冲区中,由于DMA缓冲区需要内存在物理上连续, 由于内核的限制,Linux最大只能分配4 MB[5]。因此当DMA完成后,驱动就需要通知应用程序及时将数据取走,以便进行下一次DMA。当传输速率较高时,就需要把大量数据通过copy_to_user函数从内核空间拷贝到用户空间,导致频繁地在内核模式和用户模式之间进行切换。这将占用大量资源和CPU时间从而导致系统性能的大幅下降和DMA速度的降低[6],长时间运行还会因不确定的延迟导致数据丢失。驱动运行在内核空间中,在驱动中直接将数据存入硬盘则避免了这些问题。另外由于内核线程优先级高,实时性更好,速度更稳定可靠。
3.2内核多线程实现流程
实现原理流程如图3所示。应用程序首先在文件存储路径文件中写入默认路径,然后置DDMACR(设备DMA状态控制器)D1位为1,准备开始存储数据。FPGA检测到此位后开始准备数据,当数据达到一次DMA数据量时,置DDMACR D2数据准备好位,应用程序调用ioctl函数查询此位,数据准备好后开始DMA,应用程序进入睡眠状态。在驱动初始化时申请两个DMA缓存区并设置好DMA写操作初始值,同时初始化两个内核线程,一个写硬盘线程,一个开始下次DMA线程。
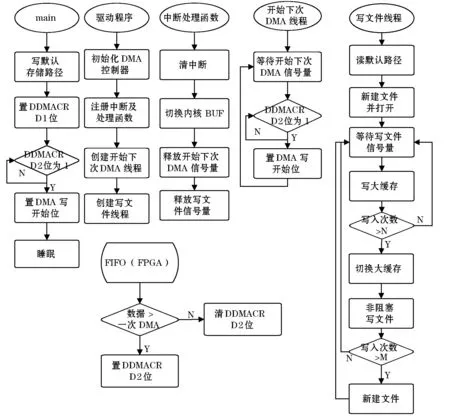
图3 内核多线程直接存储流程图
当DMA完成时,进入中断处理程序,清中断后,切换DMA内核缓冲区,最后释放开始下次DMA信号量和写文件信号量。开始下次DMA线程收到开始下次DMA信号量后,检测数据准备好位,为真时启动下次DMA。写文件线程也申请两个大缓存,收到写文件信号量时,将已完成DMA缓冲区的数据缓存到一个大的内核缓存中,大缓存大小是DMA缓存的N倍。大缓存满时,切换到另一个大缓存,已满大缓存写入到默认路径下依自定义格式所建文件中,当存储达到指定次数后,关闭文件并新建另一个文件。如此循环,实现了连续的高速DMA存储。关键细节主要有两级双缓冲的实现和内核中文件操作的实现,将在后文作详细讲解。
3.2.1两级双缓冲的实现
因为每次DMA的数据量小而中断频率较高,为避免频繁向硬盘写入小文件,提高硬盘存储速度。可在内核内存申请两个较大的缓存来转存DMA数据,大缓存容量是DMA写缓存的N倍,本系统取DMA缓存大小为4 MB,因为大缓存只需内存逻辑地址连续不需要物理地址连续,所以可以使用vmalloc函数分配内存,一次最大可分配1 GB[7]。考虑到系统总内存大小和SSD最佳速度对应的文件大小,大缓存大小取40 MB。
乒乓缓存的数据流图如图4所示,每个周期大小为一次DMA时间间隔,进入中断后通过对标志位的取反来标识周期1和周期2的交换。数据在周期1时以DMA的方式将数据传送到DMA写缓存1,在周期2时通过memcpy将数据转存入大缓存,并用memset函数清零DMA写缓存。反之在周期2时将数据存入DMA写缓存2,周期1进行转存,从而形成乒乓缓存。在N个周期中转存的数据都存入大缓存1,而在另外N个周期中都存入大缓存2,从而形成以N为周期的大周期乒乓缓存,降低了写频率,增大了每次写文件的大小,使得DMA和存储速度均连续且平稳。

图4 两级双缓存数据流图
3.2.2内核中写硬盘的实现方法
在驱动模块中,用户空间的open、read、write等文件操作函数都是不可以使用的,而应该使用内核中对应的函数。在早期版本中可以使用sys_open、sys_read和sys_write完成文件操作,但是在较新的版本中不再由EXPORT_SYMBOL导出这几个符号[8],因此新版本中不能再使用。分析sys_open可知调用do_sys_open后调用了filp->open,因此使用filp文件指针搭配struct file里的read和write即可完成对文件的读写操作。filp->f_op->read和filp->f_op->write都会对参数buf进行合法性检查,如果不在用户空间则会拒绝访问。因此需要设置FS(取USER_DS、KERNEL_DS两值)来增大寻址范围。这些函数定义在asm/uaccess.h。关键代码如下:
struct file *w_filp;
mm_segment_t org_fs;
w_filp = filp_open(filename, O_RDWR|O_APPEND| O_CREAT, 0644);
//新建追加属性的文件并打开
if(IS_ERR(filp))
{
printk("open file error… ");
return;
}
org_fs=get_fs();
//保存FS的原始值
set_fs(KERNEL_DS);
//将buf寻址范围增大至内核空间
//多次写循环,根据标识位切换BUF
w_filp->f_op->write(filp, big_write_buffer_N(N=0,1), BIG_BUF_SIZE,&filp->f_pos);
//将大缓存中数据写入文件
//判断写次数是否达到,本系统取值50,单文件约为2 GB,达到后
//关闭文件,并打开新文件继续传输
set_fs(org_fs);
//将buf寻址范围恢复为原值
w_filp_close(filp,NULL);
3.3速度测试
本系统PowerPC提供SATA2.0接口,经Linux dd命令无格式写SSD速度最大值约为260 MB/s,写Ext3格式文件最大速度约为115 MB/s,速度降低的主要原因是较低性能的CPU需对文件系统信息生成和写入。对两种方法实现的驱动在同一系统下进行对比测试,测试方法为FPGA自动生成图像数据,保证DMA数据随时准备好。因此系统的存储只与驱动的效率和稳定性有关,为减少对系统的影响,系统每隔一分钟通过gettimeofday函数得到存储一百帧图像所用时间,并将时间存入另一文件中,从而可以计算出存储速度。存储两小时,采用Matlab画出速度曲线如图5和图6所示。可以看出,新方法实现的驱动不仅稳定存储速度达到了100 MB/s以上,而且还十分稳定。而传统驱动稳定速度只有60 MB/s上下,速度波动也剧烈得多。应用中对内核多线程直接存储实现的系统连续写入512×512@200 Hz的14位灰度图像,即速率为100 MB/s。测试5次,每次两小时,均未发生丢帧和错帧现象。而采用常规驱动的本系统在速率为60 MB/s时即出现明显丢帧;当速率提高到80 MB/s时,丢帧会更加频繁,而且基本都是连续丢帧。由此可见采用内核多线程多缓存直接存储的驱动具有明显的优势,存储速度更快也更稳定。

图5 常规方法速度曲线

图6 本文方法速度曲线
4 结 语
本文介绍PCIE驱动的一般实现方法和步骤,针对其不足提出了在内核中直接用多线程多缓冲存储的方法。阐述了其实现的原理和流程,并对关键步骤和关键点作了详细分析。该系统的瓶颈主要在于SSD的写入速度,后续实现适合大量数据连续写入的RAID3 SSD阵列后,速度将有较大提升。该存储驱动实现方法显著地提高了存储速度及稳定性,具有较高的工程实践及借鉴意义。
[1] Ravi Budruk,Don Anderson,Tom Shanley. PCI Express 系统体系结构标准教材 [M]. 田玉敏,译. 北京:电子工业出版社,2005.
[2] 孙科林,周维超,吴钦章. 高速实时光纤图像传输系统的实现 [J]. 光学 精密工程,2011,19(9):2230-2233.
[3] 博韦,西斯特. 深入理解 Linux 内核[M]. 陈莉君,张琼声,张宏伟,译. 北京:中国电力出版社,2007:557-594.
[4] 周小波. 嵌入式 Linux 下 PCIE 数据采集卡驱动开发[D]. 成都:电子科技大学,2013.
[5] 宋宝华,何昭然,史海滨,等.精通 Linux 设备驱动程序开发[M].北京:人民邮电出版社,2012.
[6] 雷雨,周维超,舒怀亮. 基于 ATR 结构的嵌入式NAND Flash 图像记录系统[J]. 光电工程,2014,41(3):49-54.
[7] 杨阿锋,吴帅,刘凯,等. PCIe 接口高速数据传输卡的驱动程序开发[J]. 中国测试技术,2008,34(2):67-69.
[8] 科比特,鲁宾尼,哈特曼. Linux 设备驱动程序[M]. 魏永明,耿岳,钟书毅,译. 北京:中国电力出版社,2007:458-490.
DESIGNING KERNEL MULTITHREAD DIRECT STORAGE PCIE DRIVER
Wang Shiming1,2Yan Fabao3Xu Zhiyong1Fu Chengyu1
1(Key Laboratory of Beam Control, Institute of Optics and Electronics, Chinese Academy of Sciences, Chengdu 610209,Sichuan,China)2(UniversityofChineseAcademyofSciences,Beijing100039,China)3(SchoolofGeosciencesandInfo-Physics,CentralSouthUniversity,Changsha410083,Hunan,China)
In Linux system, high-speed storage drive will copy large amounts of data from kernel space to user space for storage, and this results in the decrease of storage speed and sharp volatility. Aiming at the problem, in combination with the self-designed and developed PCIE interface high-speed image storage system, we analyse the general composition of PCIE drive under Linux and its implementation, and put forward a method to realise multithread multi-buffer direct storage in driver. First, it transfers the ping-pong DMA of image data to double DMA buffer, then it saves the data ping-pong to double big buffer of kernel space, and finally directly writes them to SSD by kernel thread. After optimised with this method, SSD storage speed reaches more than 100 MB/s and gains over 65% improvement compared with conventional methods. In practical projects, by inputting 14 bits gray image with 512×512 @ 200 Hz, SSD can achieve stable storage, this avoids previous phenomenon of frame loss, the performance is stable as well, and achieves good optimisation result.
Image storagePCIEDMALinuxDriveMultithread
2015-03-12。国防实验基金项目(YJ14K015)。王仕明,博士生,主研领域:高速图像存储系统,Linux操作系统驱动和应用开发。严发宝,博士生。徐智勇,研究员。付承毓,研究员。
TP316.1TP311
A
10.3969/j.issn.1000-386x.2016.09.056
猜你喜欢
今日农业(2021年9期)2021-07-28
哈尔滨轴承(2020年2期)2020-11-06
发明与创新·大科技(2019年12期)2019-03-17
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
通信技术(2018年11期)2018-11-07
时代英语·高二(2017年4期)2017-08-11
解放军健康(2017年5期)2017-08-01
新农业(2016年23期)2016-08-16
中国教育信息化(2015年12期)2015-08-24
