
推荐系统:从个性化算法到算法的个性化1
2016-11-09 03:52尚明生
西华师范大学学报(自然科学版) 2016年1期
尚明生
(1.中国科学院 重庆绿色智能技术研究院,重庆4007142;2.电子科技大学 大数据研究中心,成都 611731)
推荐系统:从个性化算法到算法的个性化1
尚明生
(1.中国科学院重庆绿色智能技术研究院,重庆4007142;2.电子科技大学大数据研究中心,成都611731)
推荐系统已经得到广泛研究和应用并产生了巨大价值。作者提出推荐算法个性化的概念,并将推荐系统划分为非个性化系统、个性化推荐系统、算法参数个性化的推荐系统,以及推荐算法个性化的系统。指出了推荐系统两个全新的研究方向,并初步展示了其在推荐效果提升上的巨大潜力。
推荐系统;个性化推荐;算法参数的个性化;推荐算法的个性化
0 引 言
互联网技术的迅速发展使得大量的信息同时呈现在我们面前,例如淘宝上有8亿件商品,百度收录超过百亿的中文网页。面对如此众多的信息,用户往往很难快速地找到自己想要的内容,这就是信息过载问题。目前解决信息过载问题主要有两个技术:搜索引擎[1]和推荐系统[2]。搜索引擎往往被动地返回与用户给定查询关键字相关的内容,而推荐系统可以主动预测用户可能感兴趣的信息。事实上,目前搜索引擎在不断植入推荐技术,而且从长远来看,推荐系统将是解决信息过载问题的最终手段。推荐系统可以推荐的“信息”包括的种类很广,比如电子商务系统中的商品、社交网络中的朋友、约会网站中的相亲对象等等。为方便,本文后续将推荐的对象根据上下文分别称之为对象或者产品。
总的来说,推荐系统的发展经历了从非个性化到个性化的过程。在推荐系统中,推荐算法是最为核心和关键的因素。当前已经提出很多个性化推荐算法,很多学者也从不同的角度对推荐算法进行了分类。文献[2-3]对推荐系统进行了比较全面的综述,文献[4]对最近的一些工作进行了总结,特别是基于物理思想的推荐算法研究。推荐算法一般分为预测和排序两个阶段。最简单的推荐算法仅是一个排序算法,它根据一定的机制对所有商品排序后,将排队靠前的对象推荐给用户。这种算法不具有个性化,因为每个用户得到的推荐列表是一样的。稍微复杂的推荐算法,将用户的历史行为信息考虑在内,为用户推荐其未来可能关注的对象。在这种算法作用下,由于不同的用户其历史选择行为不同,所以得到的推荐结果也不同,用户由此得到了互不相同的个性化的推荐结果。
然而,在现有的推荐系统中,往往使用单一的推荐算法,或者即使采用多种算法进行整合,但经过各种参数调优后的推荐算法由于各个参数在使用时对所有用户都是固定不变的,仍然可以视为一个单一的推荐算法。然而研究表明不同用户在选择产品时往往具有不同的模式,例如文献[5]表明,经验丰富的用户善于发现小众对象,而新手往往选择流行产品。事实上,随着互联网技术的持续发展,用户变得越来越多元化,对系统中所有用户使用单一的算法,已经不能满足用户的需求。文献[6]提出一种个性化推荐算法,通过为不同的用户设置不同的参数来混合两个算法,相比固定参数而言,获得了更好的推荐效果。我们称其为算法参数个性化的推荐算法。
理想的推荐系统,应该是每个用户都采用最适合他们自己的推荐算法。基于此,本文提出了推荐算法个性化的概念。由此,我们将推荐系统划分为非个性化推荐系统、(传统的)个性化推荐系统、算法参数个性化的推荐系统,以及最终的,推荐算法个性化的推荐系统。本文将选择几个主流的推荐算法,在典型数据集上对几个主要评价指标进行对比,来展示算法个性化的推荐系统的巨大潜力。本文的结构安排如下:第2部分介绍各个推荐算法,第3部分对各个算法进行简单对比,最后给出总结和讨论。
1 推荐算法
本节中,我们将按照从非个性化推荐系统到算法个性化推荐系统的划分,选择各自代表性的推荐算法进行简单介绍。
1.1 非个性化推荐
在个性化推荐出现之前,已经在广泛使用推荐技术。例如,各种各样的排行榜事实上就起到了推荐的效果,报刊杂志还有各类的编辑推荐栏等等,其中最简单和典型的非个性化推荐算法是基于产品流行性的推荐算法(记为Popular)。Popular算法将当前被用户选择次数最多,也就是最受欢迎的产品推荐给用户。该算法的实现首先需要对产品的度(产品当前被选择的次数)进行统计,然后按照产品度从大到小的顺序进行排序,排除掉用户已经选择过的产品,将其他产品推荐给用户。
1.2 个性化推荐算法
非个性化推荐算法呈现给用户几乎一模一样的推荐列表,显然不能满足用户的个性化需求,于是个性化推荐算法登上历史舞台。目前已有很多个性化推荐算法被提出,例如基于用户的协同过滤[7](UCF)、基于产品的协同过滤[8](ICF)、基于热传导的算法[9](HeatS)以及基于物质扩散的算法[10](Diffuse)等。基于矩阵分解(Matrix Factorization)的算法也被大量提出和应用于推荐系统[11]。此外,有研究者试图将现有的推荐算法进行混合的推荐算法[11](HHP),在真实系统中,通常是若干算法的整合得到一个实用的推荐算法,其整合的参数通常基于学习得到,在应用中通常所有用户的算法参数是一样的。
最早的而且应用最广泛的推荐算法是协同过滤推荐算法。1994年提出的UCF算法的基本思路是“相似的用户喜欢相似的产品”。当预测目标用户对某产品的喜好程度时,UCF关注与目标用户相似的其他用户对该产品的喜好,将这些用户对该产品的喜好进行加权,预测目标用户对该产品的喜好,权重就是目标用户与其他用户的相似度。用户相似度的计算基于用户过去的选择行为,余弦相似度是一种常用的相似度计算方法。

其中,Γi表示用户i选择过的产品集合,ki是用户i的度,显然ki=|Γi|。求出目标用户与其他用户的相似度之后,即可进行预测评分。UCF为用户i预测产品α的得分为:

基于用户的协同过滤具有很好的可解释性,但在实际应用中,由于用户众多且数目经常变动,且用户评分的产品数目不多,因此基于用户的协同过滤推荐算法其实很难找到合适的兴趣相投的邻居。考虑到产品通常比较固定,文献[8]提出了基于产品的协同过滤推荐算法(ICF)。当预测目标用户对某产品的喜好时,ICF关注目标用户对与该产品相似的产品的喜好,将这些喜好值进行加权,形成目标用户对该产品的喜好,权重是其他产品与该产品的相似度。相似度的计算基于产品过去被选择的记录,常用的相似度指标有余弦相似度等。ICF首先计算产品之间的相似度并基于相似度进行预测评分。产品间的相似度定义为:

根据产品的相似度,即可进行预测评分

基于产品的相似度解决了系统中用户数目较多且经常变动的问题,然而,在考虑产品相似度时,简单考虑两个产品共同评分的用户数目,却没有对这些用户加以区分,事实上,不同的用户具有不同的特征,比如他们选择的产品数目不同。文献[9]提出了一种基于物理传播过程的推荐算法HeatS,文献[10]提出了与HeatS算法对应的Diffuse算法。HeatS算法和Diffuse算法在实质上仍然是一种基于产品相似度的推荐算法,但是在相似度的计算过程中,不仅考虑产品的度,还考虑了用户的度。
HeatS算法和Diffuse算法计算产品间相似度的公式分别为:

HeatS算法和Diffuse算法将用户对产品的偏好信息建模为二部图网络,推荐算法是资源在该二部图上的传播机制。目标用户被赋予一定的初始资源,而目标用户得到的最终资源反映了用户对产品的偏好程度。算法为用户预测产品的得分为:

1.3 算法参数的个性化
热传导算法和物质扩散算法在计算产品相似度时,同时考虑到了用户度和产品度,相比于协同过滤算法,具有更好的推荐准确性。然而经过仔细研究发现,从资源传播的角度讲,Diffuse算法只考虑了目标产品的度,而HeatS则只考虑了源产品的度。为了更全面地刻画用户和产品,文献[12]又提出了一种基于物质扩散和热传导的混合算法 HHP,通过调节混合参数 λ,可以设定两算法的权重。该算法则同时考虑了用户度,目标产品的度,源产品的度,此时产品相似度的计算公式为:

HHP算法通过调参为系统决策出唯一的混合参数,将一个固定的推荐模式作用于系统中的所有用户,没有对不同用户加以区分。事实上,系统中不同用户具有不同的个性,比如有的用户比较从众,偏好流行产品,有的用户则更偏好冷门产品[5]。原始的 HHP算法为系统中的所有用户设定一个固定的混合参数,并不能满足用户多元化的需求。如果为每个用户设置一个个性化的混合参数,应该可以得到更好的推荐效果。
在文献[6]中,提出了 UHHP算法,该算法为每个用户关联一个个性化的混合参数λi。通过研究发现,用户的个性化混合参数λi与用户选择产品的平均度di成正比。于是,设定UHHP中计算两产品相似度的机制为:
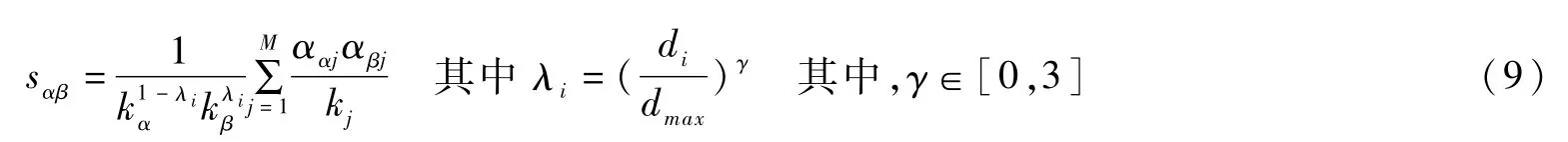
其中,di是用户过去所选择产品的平均度,dmax是最大产品度,γ是可调参数。UHHP算法将用户的最优混合参数λi与用户所选产品平均度di进行关联,从而为不同用户设定了不同的个性化混合参数,满足了用户的多元化需求。新提出的算法UHHP相比于HHP算法推荐效果得到显著改善。
1.4 推荐算法的个性化
在算法参数个性化部分,我们对单一算法HHP进行了研究,通过将 HHP中的混合参数进行用户级的个性化处理,推荐效果得到了显著改善,从而实现了对不同用于对应不同算法参数的个性化。事实上,用户可选择的算法并不局限于单一算法,系统中通常会存在多个算法。理想的推荐系统,应该是每个用户都采用最适合他们自己的推荐算法。
推荐算法的个性化的实现方式一般来讲有两大类:其一是是把选择权交给用户,系统提供某种机制让用户实现算法的自主选择;其二是系统通过深入挖掘每个人的行为模式,自动发现用户最佳的推荐算法,并提供一种机制让用户确认。
2 性能比较
本节将对上述方法进行对比,我们会看到,从非个性化算法到个性化推荐算法,以及到算法参数个性化到个性化的推荐算法演进获得的性能提升。
2.1 方法
我们使用基准数据集MovieLens数据集来测试推荐算法的性能。MovieLens(http://movielens.umn.edu)是一个电影推荐网站,用户对电影进行评分,评分等级从1-5。评分为1表明用户不喜欢该电影;评分为5表示用户非常喜欢该电影。MovieLens100K数据集包含943个用户对1 682部电影的10万条评分记录。本文中对MovieLens数据集进行粗粒度化处理,即忽略小于3分的评分,只关注用户喜欢的部分。处理后的数据集包含943个用户,1 572个电影,用户选择82 520项。该数据集可以用二部图来表示,网络中有两类结点分别是用户结点和产品结点,如果用户喜欢产品α,则在两个结点之间建立一条连边(i,α)。
为了测试不同算法的表现,将数据集划分为训练集ET和测试集EP,且ET∪EP,ET∩EP=∅。训练集作为算法的已知信息,以预测那些未知的评分;测试集则用于评估算法的表现。通常情况下,从评分记录中随机抽取出一部分数据作为训练集,其余数据作为测试集。本文按照训练集∶测试集=9∶1的比例对数据集进行了随机划分。我们进行了5次划分,最终的实验结果取5次实验的平均。
目前有很多指标用于刻画推荐算法的推荐效果,对于二部图结构数据来说,最重要的两个指标是排序准确度指标和分类准确度。排序准确度考查整个推荐列表中,用户喜欢的产品所在的位置,典型的例子如文献[7]提出的平均排序分(RS)。对于测试集中一条边(i,α),它的排序分定义如下:

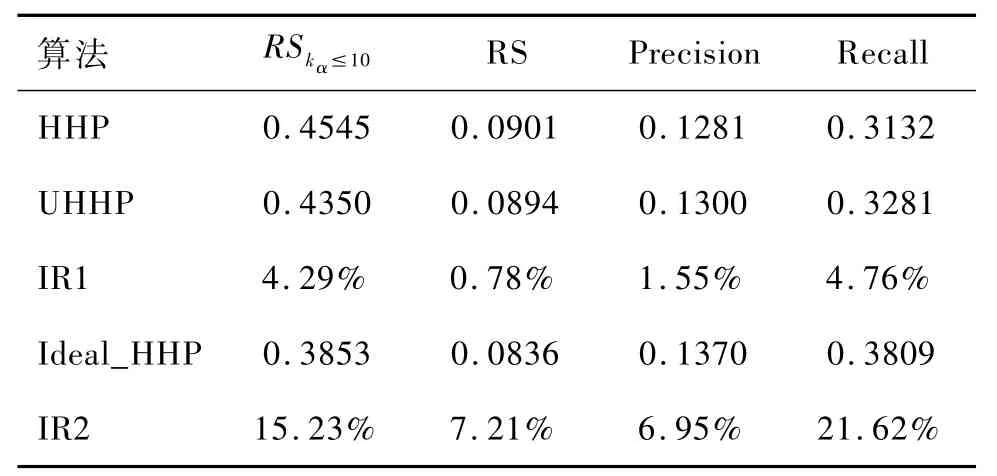
表1 UHHP算法与HHP算法性能对比
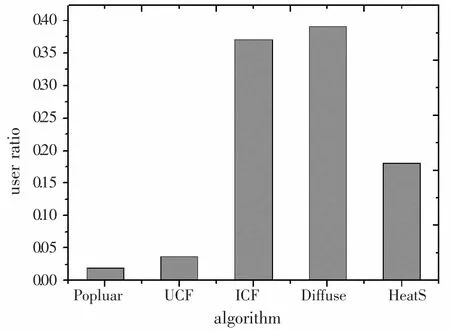
图1 不同推荐算法作为最佳算法的用户覆盖比例
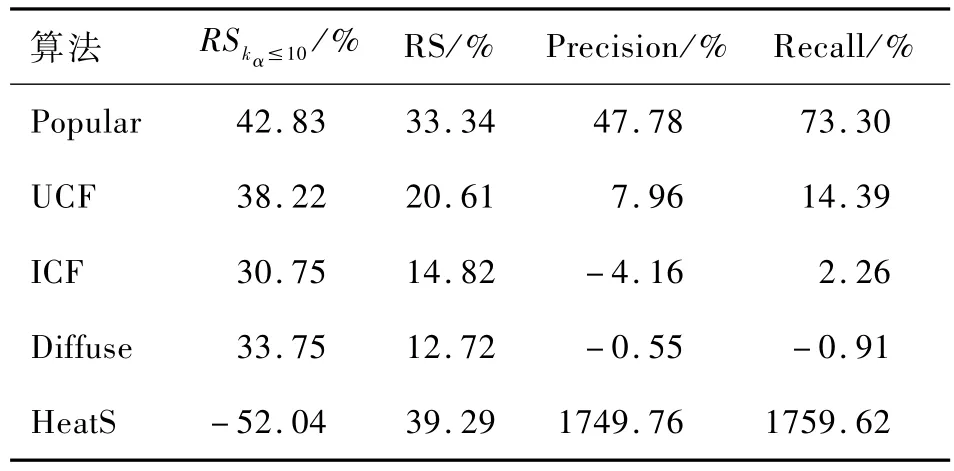
表2 最佳算法相对单一推荐算法的性能改进
其中,li,α表示在用户i的测试集中出现的产品α在推荐列表中的排序位置,Li是用户i的推荐列表的总长度。系统的RS是测试集中所有边的排序分的平均值。此外,RSkα≤x表示只关注小度产品(度不大于x的产品)的排序时,系统的平均排序分。根据经验[9],通常取x=10。同理,RSi表示用户i的平均排序分。显然RS越小,表明推荐效果越好。
分类准确度指标衡量的是推荐系统能够正确预测用户喜欢或者不喜欢某个商品的能力。目前最常用的类准确度指标[13]准确率(precision)、召回率(recall),这两个指标只关注推荐列表的前L个产品。Precision和recall越大,表明推荐效果越好。
对于某一用户i,其推荐准确率为系统推荐的L个商品中用户喜欢的商品所占的比例,则用户的推荐准确率如下。其中Hi(L)表示用户i的前L个推荐列表中,用户喜欢的产品个数。系统的推荐准确率为用户推荐准确率的平均。

召回率表示一个用户喜欢的商品被推荐的概率,定义为推荐列表中用户喜欢的商品与系统中用户喜欢的所有商品的比率。对于用户i,其召回率为如下,其中Li表示测试集中用户i喜欢的产品的数目。系统的召回率为用户召回率的平均。

我们将对比第2节提到的各个算法:Popular、UCF、ICF、Diffuse、HeatS以及 HHP,由于理想算法目前并未发现,我们考虑理想的情况,也就是前面5种算法中,对某个用户而言结果最好的算法设为其最佳选择算法,从而实现算法的个性化。我们首先考虑算法参数个性化情况下的推荐性能提升,为参照,也将最佳参数选择的算法进行对比;其次考虑最佳个性化算法时的性能。
2.2 结果与分析
2.2.1 参数个性化算法的性能
表1给出了参数个性化算法和原有混合算法的几个指标对比,其中Ideal_HHP为每个用户选择最佳参数的理想算法,IR1和IR2分别为UHHP算法和Ideal_HHP相对于原始算法HHP的改进率。由表1可以看出,UHHP相对原始 HHP算法在各个指标上都有所提升,注意到HHP算法已经是调优后的情况,而且 UHHP算法的参数仅仅是其中的一个试探,所以这个结果还是很不错的。进一步,如果考虑理想参数的情况,个性指标都有大幅提升。这个结果表明,参数个性化算法具有非常显著的性能改善。
2.2.2 算法个性化系统的性能
首先,图1统计了最佳推荐算法为以上算法的用户占所有用户的比例。从中可以看出,有接近40%的用户,其最佳推荐算法为Diffuse算法,超过35%的用户,其最佳推荐算法为 ICF算法,接近18%的用户,其最佳推荐算法为 HeatS算法,其余用户的最佳推荐算法为 Popular和 UCF算法。由此可见,不同的用户确实有不同的最佳推荐算法。
其次,表2给出了每个用户使用其最佳的推荐算法(称为 BestEnsemble)进行推荐时,推荐效果改善程度。从实验结果看出,如果每个用户都使用其最佳推荐算法进行推荐,相比于单一推荐算法,推荐效果能得到显著提高。尤其是对于RS类指标,最佳集成算法得到显著改善,但对于 precision和recall指标,则有小幅度的下降。
3 总结与讨论
本文提出了推荐算法参数的个性化,以及推荐算法的个性化的概念,并在典型数据集上对典型评价指标进行了对比分析,结果表明无论参数的个性化或者算法的个性化都能极大地提升原有推荐算法的性能,这为推荐系统领域的下一步发展开辟了新的方向。
依托本文的工作,还有很多重要的工作要做,比如在算法参数的个性化中,通过实验我们发现用户的最优混合参数与用户选择产品的平均度di具有正相关性,所以我们通过UHHP算法来模拟这种正相关关系。在UHHP算法中,通过建立用户的个性化混合参数λi与用户所选择产品的平均度di的关联关系,我们为不同的用户得到个性化的混合参数λi,但是λi与是有差别的,所以UHHP算法相比于 Ideal_HHP算法,提高幅度有限。如何更精确地模拟得到用户的最优个性化混合参数,从而推荐效果更接近Ideal_HHP算法,这个问题仍然值得继续研究。
另一方面,如果我们可以根据用户的特性建立用户与其最佳推荐算法的关联,将进一步解决算法的个性化使用问题。我们期望将系统中的所有用户按照其最佳推荐算法分成若干个群体。例如图1中,我们将用户按照Popular、UCF、ICF、Diffuse和HeatS分成了5个群体,其中用户群k(k=1,2,3,4,5)表示的是最佳推荐算法为算法k的用户集合。这需要我们首先找到类内用户的共同特点,以及类间用户的不同特点,这个内容有待继续研究。
致谢:本文实验由关远同学完成,在此致谢!
[1]SERGEY B,LAWRENCE P.The anatomy of a large-scale hypertextual web search engine[J].Comput.Netw.ISDN Syst,1998,30:107-117.
[2]ADOMAVICIUSG,TUZHILIN A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEE Trans.Knowl.Data.Eng,2005,17:734-749.
[3]EKSTRAND M D,RIEDL JT,KONSTAN JA.Collaborative filtering recommender systems[J].Foundations and Trends®in Human-Computer Interaction,2011,4(2):175-243.
[4]LÜL Y,MEDO M,YEUNG C H,et al.Recommender systems[J].Physics Reports,2012,519:1-49.
[5]SHANG M S,LÜL Y,ZHANG Y C,et al.Empirical analysis of web-based user-object bipartite networks[J].EPL,2010,90(4):48006.
[6]GUAN Y,ZHAO D,ZENG A,et al.Preference of online users and personalized recommendations[J].Physica A:Statistical Mechanics and its Applications,2013,392(16):3417-3423.
[7]RESNICK P,IACOVOU N,SUCHAK M,et al.GroupLens:an open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM conference on Computer supported cooperative work.New York:ACM,1994:175-186.
[8]LINDEN G,SM ITH B,YORK J.Amazon.com recommendations:item-to-item collaborative Filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[9]ZHANG Y C,BLATTNER M,YU Y K.Heat conduction process on community networks as a recommendation model[J].Phys. Rev.Lett,2007,99:154301.
[10]ZHOU T,REN J,MEDO M,et al.Bipartite network projection and personal recommendation Phys[J].Rev.E,2007,76:046115.
[11]BELL R,KOREN Y,VOLINSKY C.Modeling relationships atmultiple scales to improve accuracy of large recommender systems[C]//Proc.KDD.New York:ACM,2007:95-104.
[12]ZHOU T,KUSCSIK Z,LIU JG,et al.Solving the apparent diversity-accuracy dilemma of recommender systems[J].Proc.Natl. Acad.Sci,2010,107:4511.
[13]HERLOCKER J L,KONSTAN J A,TERVEEN K,et al.Evaluating collaborative filtering recommender systems[J].ACM T Inform Syst,2004,22:5-53.
Recommender Systems:From Personalized Algorithm to Individualized Algorithm
SHANG Mingsheng
(1.Chongqing Institute of Green and Intelligent Technology,Chinese Academy of Sciences,Chongqing 400714,China;2.The BigData Research Center,University of Electronic Science and Technology of China,Chengdu 611731,China)
Recommender systems have been widely studied and applied.In this paper,the concept of individual recommendation algorithm is proposed,and accordingly the recommender systems are classified into four types:the non-personalized system,the personalized recommender system,the algorithm parameters personalized recommender system,and the individual recommender system.This paper thus suggests two new research directions of the recommender systems,and shows preliminary potential for the considerable improvementin commercial use.
recommender system;personalized recommender system;individual recommender system
TP301
A
10.16246/j.issn.1673-5072.2016.01.009
1673-5072(2016)01-0061-06
2015-12-25
国家自然科学基金项目(61370150,61433014)
尚明生(1973—),男,重庆大足人,博士,教授,博士生导师,主要从事大数据相关的理论和应用研究。
尚明生,E-mail:msshang@uestc.edu.cn
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
文苑(2020年4期)2020-05-30
科普童话·学霸日记(2020年1期)2020-05-08
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小天使·一年级语数英综合(2019年2期)2019-01-10
小学生学习指导(低年级)(2018年11期)2018-12-03
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
现代防御技术(2016年1期)2016-06-01
