
以顾客需求导向的产品评价体系构建研究
2016-11-01 11:06徐海燕
工业工程 2016年4期
陈 晔, 曹 帅, 徐海燕, 卢 波
(南京航空航天大学 经济与管理学院,江苏 南京 211100)
以顾客需求导向的产品评价体系构建研究
陈晔, 曹帅, 徐海燕, 卢 波
(南京航空航天大学 经济与管理学院,江苏 南京 211100)
针对产品评价体系构建的问题,提出了一种通过对顾客评论信息的挖掘进行顾客需求的识别,进而应用数据聚类分析,自下而上地构建产品评价体系的方法。有别于传统多属性评价分析中大多通过自上而下(从概括到具体)方式进行评价体系构建的思路,该方法以顾客评价信息为导向,使最终构建出来的产品评价体系更具客观性,能有效为产品评价体系优化设计提供帮助,相关案例演算展示了方法的可行性。
多属性决策; 指标体系; 语言评价集; 逆向构建; 顾客需求识别
中国互联网络信息中心相关报告显示:截至2014年6月,我国网购用户规模达3.32亿,随着互联网广泛应用,各电商网站积累了大量产品或服务的客户评论,能在很大程度上影响消费者购买决策[1]。自2002年,评论挖掘研究逐渐兴起,如Turney[2]提出将语义倾向性应用在评论分类,将评论分为两类,推荐和不推荐。Dave等[3]开发了情感分析工具和针对给定产品评论区别其褒贬性的系统ReviewSeer。汉语评论挖掘研究起步较晚,如文献[4]通过数据挖掘手段发现产品主要特征,分析顾客对这些特征评价和态度;文献[5]采用共词分析和基于句法分析的极性传递法,构建了评论挖掘模型;李爱清等构建了手机产品评论挖掘实验数据集和可视化平台[6]。沿着应用评论挖掘思路,本文探索了自下而上构建指标评价系统的研究。
指标集和评价集构成了整个评价体系,是多属性决策的两个核心要素。现有对于评价体系构建研究,多采用自上而下的指标体系构建思路,即通过直观抽象分析,从概括到具体的正向逐层构建思路,从总目标出发,细化为子目标,通过层层分解,最后形成可量化的指标集。如层次分析法(AHP)为这一思路典型代表[7]。而针对评价集的构建,通常按照定性和定量指标两大类分别处理。其中定量指标可通过各种途径如统计文献直接获得客观数据,而定性指标则相对复杂,简单处理方法可通过邀请专家直接打分获取,如通过问卷调研,或者构建不同类型的基于语言评价集,如模糊语言[8]评价。

图1 多属性决策传统自上而下构建模式图

1 基于顾客需求分析的决策体系构建
1.1整体构建框架
传统自上而下的评价体系构建,主观因素多,无法有效反映备选方案自身的特征信息。而随着电子商务在深度和广度的应用,积累了大量顾客对产品的评价信息。鉴于此,依托于聚类分析方法[9],提出基于顾客需求[10]的评价体系逆向构建方法。
基本流程如下。1)顾客评价文本挖掘与处理:将分散的顾客评价信息,运用文本挖掘技术结合专家判断,根据频度、语义的前后关联程度以及评论语言的主观内容识别,整理成高频短语,即名词+形容词/副词形式。2)相似度判定及相似矩阵构建:上述高频短语中的名词设为基本指标元素,通过专家判断语义相似性,构建相似度矩阵,类似处理形容词/副词形成基本语言评价元素,构建基本语言评价相似度矩阵。3)基于聚类指标集和子目标集构建:对基本指标元素相似度矩阵的聚类分析,形成指标集,进一步对指标集构建相似度矩阵和聚类分析,从而获得子目标集。4)基于聚类评价集构建:对基本语言评价元素相似度矩阵的聚类分析,形成语言评价集。5)产品评价体系整合优化:通过整合以上获得的指标集、子目标集和语言评价集,实现自下而上的评价体系构建,可用以指导产品评价体系的优化,如顾客调查问卷的优化设计。
1.2顾客评价的挖掘和处理


表1 有效高频词组
1.3相似性判定及相似矩阵构建
邀请专家在充分理解评价者的真实表达意图基础上,针对基本名词单元集或者基本形容词/副词单元集分别进行两两相似性判断(用0~1之间的数值表示),形成相似矩阵。进一步,定义如下:基本词语的相似程度,S(nj,ni),为词nj与词ni的相似程度,0≤S(nj,ni)≤1,从定义易知,S(nj,ni)=S(ni,nj),构建如表2所示基本词语(以名词为例)相似矩阵。

表2 词语相似矩阵
2 基于聚类的决策体系逆向构建
2.1聚类算法概述
聚类分析是将数据划分或分组处理聚成不同的类的过程,同一个类中的对象间具有强相似性,而不同类间的对象具有强相异性。在分类过程中,不必事先给出一个分类标准,聚类分析能够从数据出发,客观地决定分类标准。主要的聚类算法有层次聚类分析(hierarchical cluster analysis)[13]和K-means算法[14]。
在层次聚类过程中,需要确定聚类过程中样本与类、类与类之间的距离度量方式,常用的距离度量方式[16]有最小距离(single-link)、最大距离(complete-link)、平均值距离(average-link)、均值点距离(mean-distance)及离差平方和(ward法)。本文采用层次聚类方法,通过聚类个数与相似性水平交互对比,将基本名词(形容词/副词)元素进行聚类,构建指标集和子目标集。
2.2基于聚类的指标(子目标)集构建
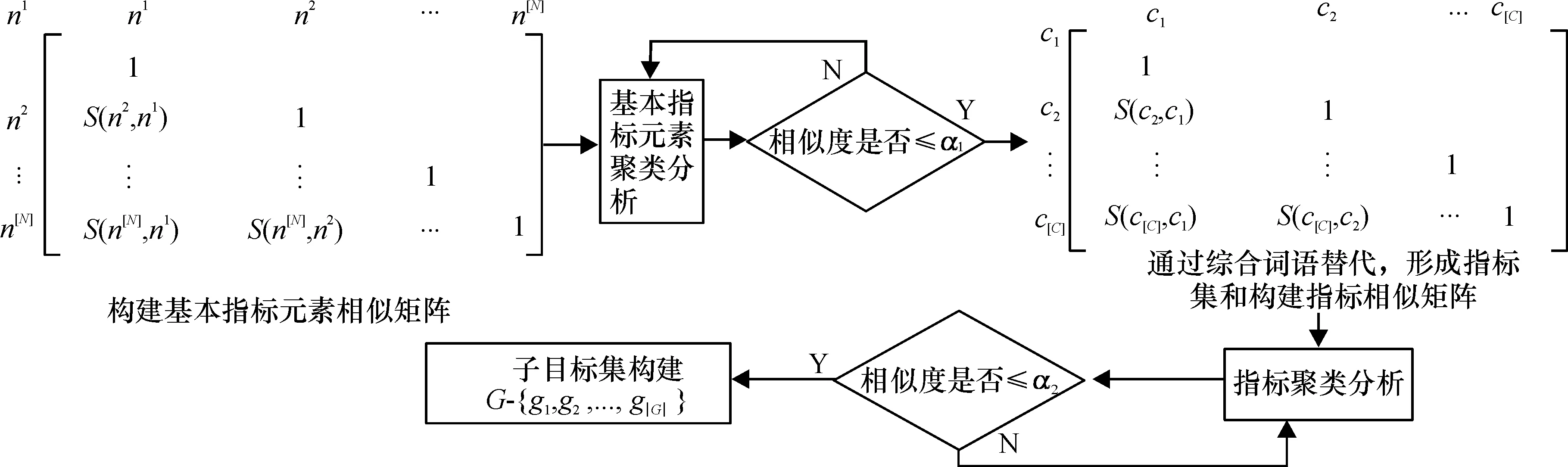
图2 基于聚类的指标(子目标)集构建流程图
图2为基于聚类的指标集和子目标集的构建流程图。


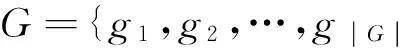
通过上述两轮聚类,依次完成从基本指标元素到指标集以及从指标集到子目标的逆向构建过程。
2.3基于聚类的语言评价集构建

图3 基于聚类的语言评价集构建过程

3 案例分析
为了验证方法有效性,选取京东商城作为实验载体,通过对其商品URL的规律抽取关键信息[15]:通过URL抓取页面源码,分析源码中所需信息的上下文环境,得到抽取规则,用正则表达式表示该规则,然后进行抽取。限于篇幅,本文选择近期受关注的国产手机锤子作为研究对象,进行算法演示分析。
3.1评价指标(子目标)集构建
1)基本数据的预处理。首先利用火车头数据采集平台来抽取网站评论页面的信息,截止实验时,锤子手机在售的3种不同型号的产品共计7 173条评论,考虑到用户隐私以及实际需要,本文只抽取了用户关于商品的评价语言。在评论语言中,会出现“外观”、“外形”、“看起来”、“样子”这种明显同义的名词,在完成分词处理之后,首先把这种明显同义的词语用出现频率最高那一个词语替代表示。
2)基本指标元素与相似度矩阵的构建。本文通过对锤子手机7 000多条评论语言的预处理,合并整理出20个高频名词用于本次试验的基本指标元素构建,即N={手机,外观,锤子(手机品牌),系统运行,老罗(该品牌创始人),手感,国产,包装,细节,设计,做工,后盖,UI,配置,硬件,拍照效果,按键,屏幕,音质,配件},之后通过邀请10名智能机资深用户进行名词间的相似度比较,构建基本指标元素相似度矩阵,受篇幅限制,本文只提供部分数据如表3所示。
3)基本指标元素聚类分析。本文选用Minitab进行聚类分析,选定离差平方和的联结规则,选择相关性作为距离量度,设定α1等于60,作为基本指标元素聚类的相似度阈值,处理后得出如图4的聚类结果。
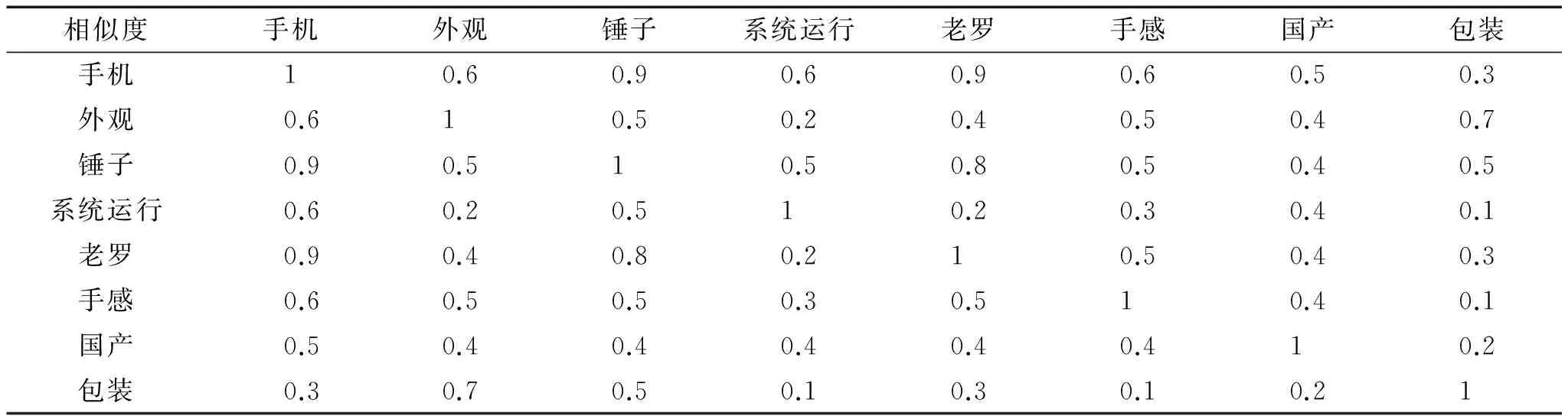
表3 基本指标元素相似度矩阵
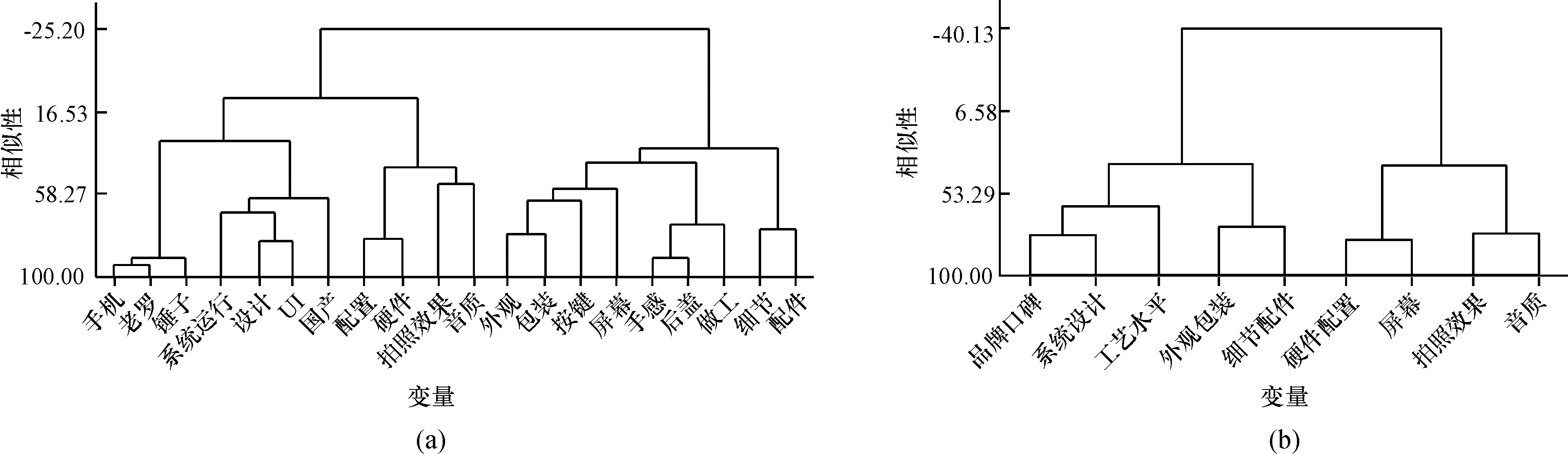
图4 基本指标元素聚类结果和指标集聚类结果
4)指标集和子目标集的构建。由树状图(图4a)可知最终共聚为9类,并用综合名词进行代表替换,即:c1={手机,锤子,老罗}→品牌口碑(即用品牌口碑作为指标整合代表手机、锤子和老罗3个基本指标元素),c2={外观,包装,按键}→外观包装,c3={系统运行,国产,设计,UI}→系统设计,c4={手感,做工,后盖}→工艺水平,c5={细节,配件}→细节配件,c6={配置,硬件}→硬件配置,c7={拍照效果},c8={屏幕},c9={音质},从而完成指标集的构建,即:C={c1,c2,…,c9}。
类似地通过构建指标集相似度矩阵,并设定α2=70,作为指标集聚类的相似度阈值,根据处理结果的树状图(图4b)显示进行类似综合名词代表,即:g1={品牌口碑,系统设计}→品牌与设计,g2={工艺水平},g3={外观包装,细节配件}→外观与细节,g4={硬件配置,屏幕}→硬件配置,g5={拍照效果,音质}→拍照与音质,从而完成子目标集的构建,即:G={g1,g2,g3,g4,g5}。
3.2语言评价集的构建
通过对顾客的评论挖掘,根据对词义的了解和分析,把表达的情感倾向程度十分相近的形容词/副词等用于评价手机的词语归为一类。如“赞”和“给个赞”归为一类,用“赞”代替表示。本文通过整理综合后,邀请资深用户进行基本语言元素的相似度判定,其相似度矩阵的部分数据如表4。选定离差平方和的联结规则,设定β=85,作为基本语言评价元素聚类的相似度阈值,处理后得出如图5所示的聚类结果,即o1={精致,人性化,非常好,大赞,流畅}→非常好,o2={很好,赞,好}→好,o3={还好,不错,还算可以}→还算可以,o4={一般,需要完善,凑合}→一般,o5={易留指纹,噪点很多,不适应,不方便,发热,不怎么耐用,不精准}→存在问题,从而完成语言评价集的构建,即O={o1,o2,o3,o4,o5}。
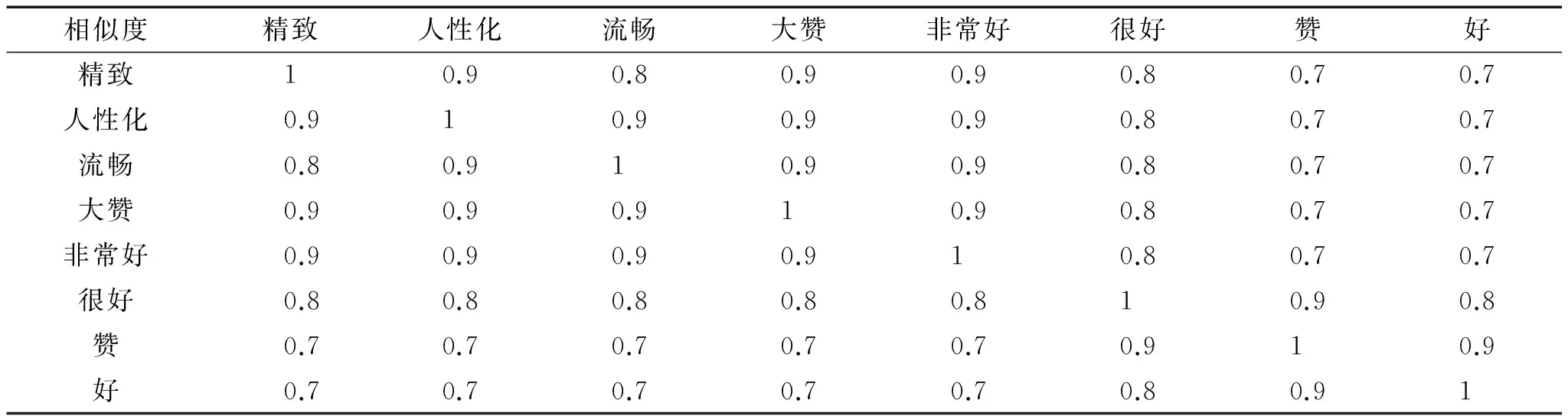
表4 基本语言评价元素相似度矩阵
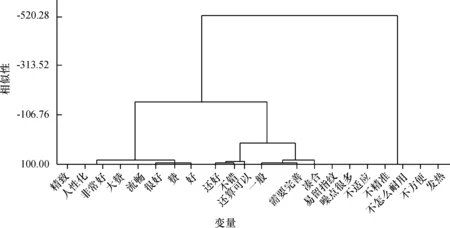
图5 基本语言评价元素聚类结果
3.3产品评价体系的整合优化分析
依托前文计算结果,以下给出该产品评价体系的优化设计建议。 1)评价指标体系设计:根据前文获得的指标集和子目标集,建议调查应该从5个大维度(对应5个子目标)进行总体设计,即:品牌与设计、工艺水平、外观与细节、硬件配置、拍照与音质;进一步,对品牌与设计维度,相关问题应该围绕:品牌口碑、系统设计(即分别对应每个子目标包含的指标集)。 2)评价的语言尺度设计:根据获得的语言评价集,建议语言评价应该从以下5个层级(对应5个语言评价集)进行设计,即:非常好、好、还算可以、一般、存在问题。
4 结论
随着互联网驱动的电子商务在我国蓬勃发展,在2013年已占我国GDP总量15%,其应用深度和广度日益拓展,积累了大量各类用户数据,如何有效地应用数据分析工具去识别顾客需求成为一个研究热点。本文通过挖掘顾客评论辨识顾客需求,以顾客需求为导向,利用文本挖掘与聚类思想和方法,构建产品评价体系。有别于传统自上而下的指标体系构建方法,所提方法使得评价体系构建更客观,更贴近真实的用户意图。由此设计的评价体系也更贴近顾客关注的价值,从而帮助决策者准确地把握产品反馈和市场动向。
[1]韩伟伟,王晶.从神经学角度评估分析消费者网略购物决策[J].工业工程, 2015,18(1):135-141.
HAN Weiwei, WANG Jing. Assessment from a neurological perspective analysis of consumer online shopping decisions[J].Industrial Engineering Jourmal, 2015,18(1): 135-141.
[2]TURNEY P. Mining the web for synonyms: PMI-IR versus LSA on TOEFL[C]. Proceedings of the 12th European Conference on Machine Learning,Berlin,2001:491-502.
[3]DAVE K, LAWRENEE S, PENNOEK D. Mining the peanut gallery: opinion exaction and semantic classification of product reviews[C]. In Proceeding Of WWW(World Wide Web)’2003, 2003:519-528.
[4]李实, 叶强, 李一军. 中文网络客户评论的产品特征挖掘方法研究[J]. 管理科学学报, 2009, 12(2): 142-152.
LI Shi, YE Qiang, LE Yijun. Product features of Chinese network customer review mining methods[J]. Journal of Management Sciences in China, 2009, 12(2): 142-152.
[5]唐晓波,肖璐.基于情感分析的评论挖掘模型研究[J].情报理论与实践,2013(7):100-105.
TANG Xiaobo, XIAO Lu. The model of information theory and practice in mining sentiment analysis based on the comments[J]. 2013(7):100-105.
[6]李爱清,何烁,郗亚辉.产品评论挖掘可视化试验平台的开发[J].河北大学学报(自然科学版), 2012, 32(2):212-217.
LI Aiqing, HE Shuo, XI Yahui. Product reviews of test platform for the mining development[J]. Journal of Hebei University of technology(Natural Science), 2012, 32(2): 212-217.
[7]许树柏.层次分析法原理[M].天津:天津大学出版社,1988.
[8]徐泽水.基于模糊语言评估及语言OWA算子的多属性群决策法[J]. 系统工程, 2002, 20(5):79-82.
XU Zeshui. Based on fuzzy linguistic assessments and linguistic OWA operator for multiple attribute group decision making method[J]. Systems Engineering, 2002, 20(5): 79-82.[9]廖勇,陈晔,徐海燕.基于优势粗糙集的中小企业二维绩效评价模型[J].工业工程,2015,18(2):119-127.
LIAO Yong, CHEN Ye, XU Haiyan. Two-dimensional performance evaluation of SMEs based on dominance rough set model[J]. Industrial Engineering Journal, 2015,18(2): 119-127.
[10]孙晓东,冯学钢.多顾客个性化需求下产品属性配置策略[J].工业工程, 2013,16(1):54-60.
SUN Xiaodong, FENG Xuegang. Multi-customer demand for personalized product attributes configuration policy[J]. Industrial Engineering Journal, 2013,16(1): 54-60.
[11]秦凯.Android开源社区应用项目开发的效率研究[D].广州:华南理工大学,2012.
Qin Kai.Study the development efficiency of android open source application project[D].Guangzhou:South China University of Technology,2012.
[12]张紫琼,叶强,李一军.互联网商品评论情感分析研究综述[J].管理科学学报, 2010,13(6):84-96.
ZHANG Ziqiong, YE Qiang, LI Yijun. Internet product reviews review of sentiment analysis[J]. Journal of Management Sciences in China, 2010,13(6): 84-96.
[13]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报(信息科学版), 2010,28(6):602-608.
TIAM Jiule, ZHAO Wei. Calculation of word similarity based on synonym word forest[J]. Journal of Jilin University(Information Science), 2010,28(6): 602-608.
[14]贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究, 2007(1): 10-13.
HE Ling, WU Lingda, CAI Yichao. A summary of clustering algorithm in data mining[J]. Computer Application Research, 2007(1): 10-13.
[15]王继成,潘金贵,张福炎.Web文本挖掘技术研究[J].计算机研究与发展, 2000, 37(5):513-520.
WANG Jicheng, PAN Jingui, ZHANG Fuyan. Web text mining technology research[J]. Journal of Computer Research and Development, 2000, 37(5): 513-520.
Customer Demand-oriented Product Evaluation System Construction
CHEN Ye, CAO Shuai, XU Haiyan, LU Bo
(College of Economy and Management, Nanjing University of Aeronautics and Astronautics, Nanjing 211100, China)
Aiming at the problem of product evaluation system, a bottom-up method of constructing evaluation system of product is proposed, which needs mining customer reviews, identifying the needs of customers, and then applying data to a clustering analysis. Unlike traditional multiple attribute evaluation and analysis of the most top-down (from generalization to specific) approach to the idea of building evaluation system, this method is customer demand-oriented, from bottom to top, layers forward, so that the final product evaluation system contains more objective features, thus helping to optimize the product evaluation design. Finally, a case study demonstrates the feasibility of the proposed method.
multiple attribute decision making; criteria set; linguistic evaluation set; reverse construction; customer needs' identification
2015- 05- 26
国家自然科学基金资助项目(71471087)
陈晔(1974-)男,江苏省人,教授,博士,主要研究方向为多属性决策与优化.
10.3969/j.issn.1007- 7375.2016.04.005
C934
A
1007-7375(2016)04- 0030- 06
猜你喜欢
佳木斯大学学报(自然科学版)(2022年2期)2022-08-24
铁道通信信号(2019年6期)2019-10-08
系统工程与电子技术(2018年12期)2018-12-10
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
系统工程与电子技术(2016年2期)2016-04-16
山东青年(2016年1期)2016-02-28
智能系统学报(2015年4期)2015-12-27
物理教学探讨(2015年7期)2015-08-05
中国洗涤用品工业(2015年6期)2015-02-28
