
基于半监督DPMM的新闻话题检测
2016-10-26 02:32姚冬冬
郑州大学学报(理学版) 2016年3期
姚冬冬 , 袁 方 , 王 煜, 刘 宇
(1.河北大学 计算机科学与技术学院 河北 保定 071000; 2.河北大学 计算机教学部河北 保定 071000; 3.河北大学 数学与信息科学学院 河北 保定 071000)
基于半监督DPMM的新闻话题检测
姚冬冬1,袁方2,3,王煜1,刘宇3
(1.河北大学 计算机科学与技术学院河北 保定 071000; 2.河北大学 计算机教学部河北 保定 071000; 3.河北大学 数学与信息科学学院河北 保定 071000)
基于狄利克雷过程混合模型(DPMM)这一非参数贝叶斯生成模型,从语义的角度入手,结合其自动确定聚类个数的特性进行话题检测,运用了聚类个数K值由大到小变化的采样策略,通过逐层递进的形式获取到较为准确的K值,并在此基础上对语义聚类的词频特性加以分析,引入一组名词实体作为“热点特征词”来引导聚类过程,从而给出了DPMM半监督模型.实验结果表明,所给出的话题检测方法在TDT4语料上取得了较好的检测性能.
话题检测; 狄利克雷过程; Gibbs采样; 幂律特性; 名词实体
0 引言
随着互联网的快速发展和移动媒体的广泛普及,网络成为人们获取信息的重要途径之一,如何有效地从杂乱的数据中获取话题信息一直是文本挖掘领域的研究热点.话题检测与追踪(topic detection and tracking, TDT)[1]最早由美国国防部高级研究计划署在1996年提出,其目的在于利用当时的技术发现和追踪新闻广播流中的新事件.在多家机构的共同努力下,TDT的研究内容和评测体系被正式确立并取得长足发展.话题检测是TDT中至关重要的环节,近些年的相关研究包括聚类算法的融合[2]、相似度的组合[3]、名词实体的引入[4]、主题模型的使用[5]等,并扩展至其他相关领域[6].
狄利克雷过程混合模型(Dirichlet process mixture models, DPMM)[7]作为非参数贝叶斯领域的基础模型,是一种定义在无限维参数空间上的贝叶斯模型.文献[8]通过引入一定的先验知识将DPMM应用于动词语义聚类.文献[9]综述了DPMM、扩展模型及其在机器学习等领域的应用.文献[10]将其引入到话题识别研究中,利用DPMM的特点解决话题识别任务中的参数设置问题.文献[11]通过改进空间约束使得DPMM在图像处理上更加简单便捷.应用于TDT工作时,DPMM与潜在狄利克雷分配模型(latent Dirichlet allocation, LDA)[12]一样,是一种具有文本主题表示能力的模型,在弥补VSM没有考虑词与词之间语义联系这一缺点的同时,也可以用来解决LDA模型存在的主题数目需要指定的问题,为聚类分析中K值确定这一基础性问题提供了解决方案,减轻了人工实验的负担.
本文在研究分析DPMM模型的基础上,对DPMM 模型进行了两个方面的改进:一是借鉴深度学习的基本思想,获取到较为准确的K值;二是分析语义聚类的词频特性,从词性和名词实体两个角度改进模型初始状态,引入的“热点特征词”给出了DPMM半监督模型.实验结果表明,改进后的DPMM模型具有更好的话题检测性能.
1 DPMM模型研究
伴随着语义分析在话题研究中的应用,主题模型将主题的概念引入到了话题研究之中.对于LDA等主题模型而言,文档是由若干隐性主题混合而成,而主题则需要借助词汇来描述.本节首先着重研究了狄利克雷过程及其构造方法,其次是深入分析采样公式,更加合理地将模型应用在话题检测之中.
1.1狄利克雷过程
狄利克雷过程(Dirichlet process, DP)[13]是狄利克雷分布在连续空间上的扩展,和狄利克雷分布一样具有共轭性[14].中国餐馆过程[15]是指一个新的顾客坐在已有餐桌的概率与该餐桌上人数nc成正比,坐在新餐桌上的概率与参数α相关,当此过程趋于无穷时,类簇个数最终会趋于一个平稳值,具体表示如公式(1)所示.它是一种常见的直观的DPMM描述方法,因此本文利用中国餐馆过程对DP进行构造.
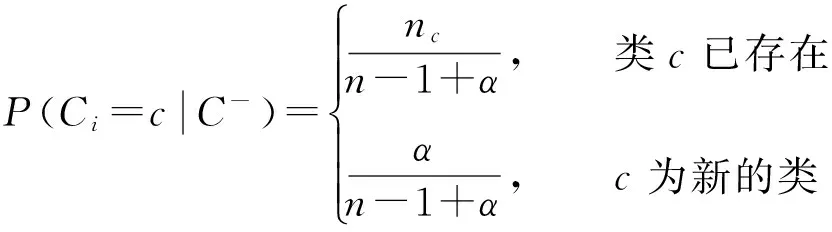
(1)
1.2DPMM模型
假设一组样本服从某种分布,分布的参数服从狄利克雷过程先验分布,参数的先验和后验分布采用狄利克雷过程构造方法推断,则该模型称为狄利克雷过程混合模型(DPMM)[10].鉴于狄利克雷过程的构造是概率和为1的离散分布,模型可以认为是可数的无限混合[16].
将DPMM引入到话题分析领域则可以构建如图1所示的生成模型[11],其中α和β为模型的超参数,θ和φ分别代表主题分布和词分布,z代表一个主题,w代表一个词.生成一个词的过程包括从一篇文档的主题分布中生成一个主题,然后从这个主题的词分布中生成一个词的两部分,m篇文档对应于m个独立的狄利克雷过程.这里的生成过程同LDA模型类似,区别在于生成主题的过程中,DPMM模型的主题数目K并不会预先指定,而会随着迭代过程变化修正.
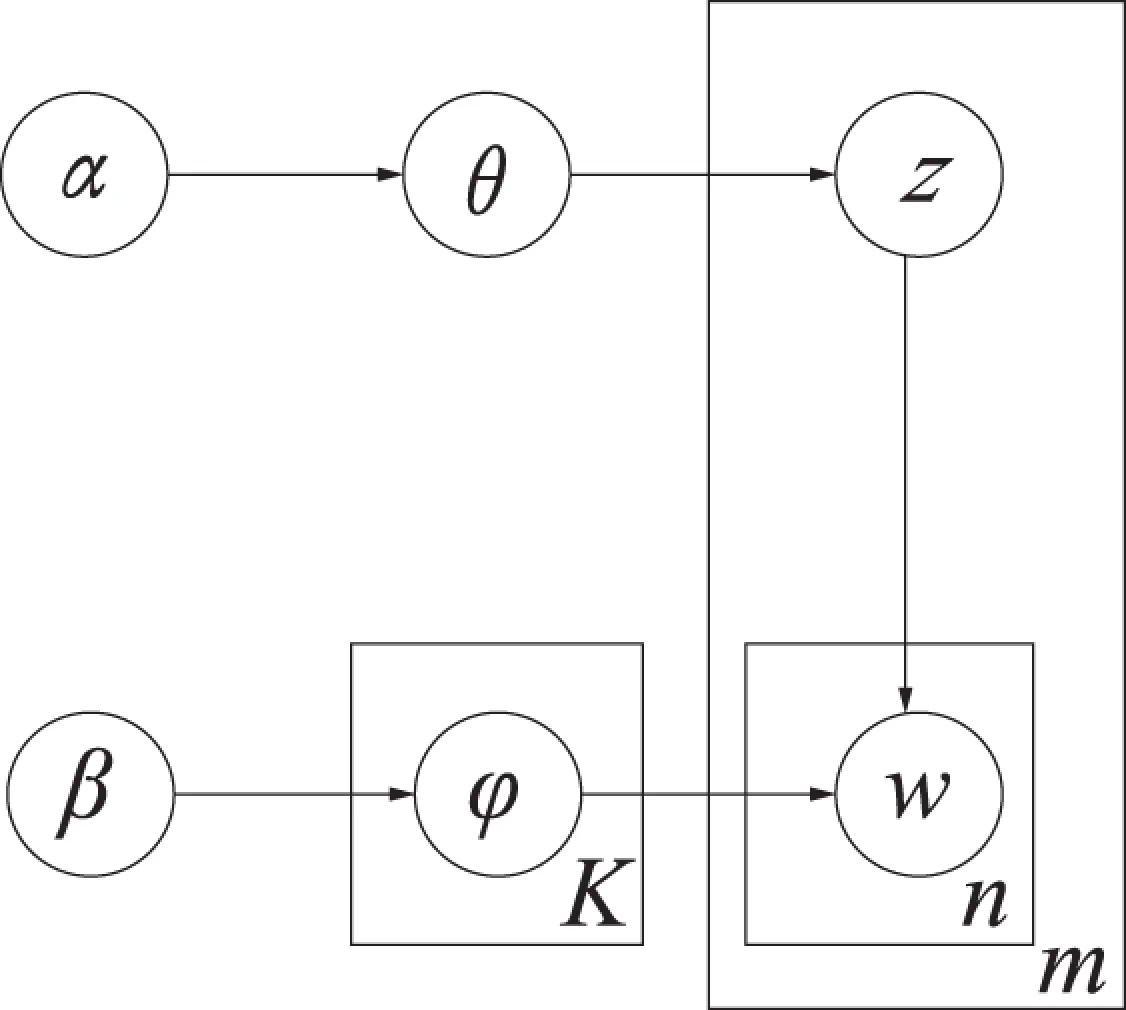
图1 DPMM模型Fig.1 DPMM model
后验计算方法一般采用积分的方式进行,考虑到模型的复杂程度,本文采用基于马尔科夫链蒙特卡罗(Markov chain Monte Carlo, MCMC)的吉布斯采样(Gibbs sampling)算法,根据贝叶斯理论可得采样公式(2).
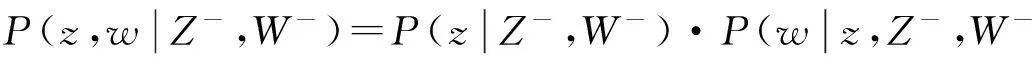
(2)
公式(2)的第一部分代表生成主题的概率,可以用中国餐馆过程来构造.本文根据文献[11,16-17]完善公式(1)得到公式(3),更加合理地将其应用在话题模型之中,
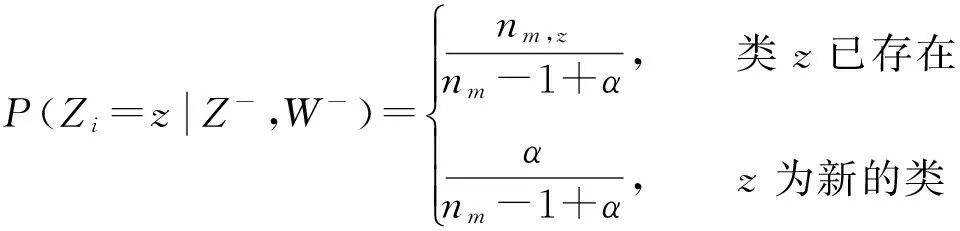
(3)
其中:nm,z代表文档m中属于主题z的词的个数,nm代表文档m中的词的总个数,此处可以简单理解为用主题将文档进行了划分,并且主题数目可变.
公式(2)的第二部分代表生成词的概率,是从一个已知主题中生成一个词,这其中的基本单位是该主题,包括该主题中的所有词,不存在可变的因素,所以同LDA模型一样,此处通常选取狄利克雷-多项式共轭过程,根据文献[18]可得
(4)
综合文献[11]、公式(4)和文献[17]给出的词分布公式,可得
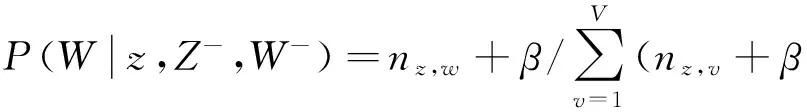
(5)
2 基于改进K值的半监督模型
依据DP的特性和TDT研究的前提,本文中将主题与话题的概念等同,K值并非是类似于LDA中的主题个数而是聚类个数,并在此基础上从优化聚类个数K和改善聚类结果两个角度进行了相应改进.
2.1DPMM模型的K值改进
DPMM模型为聚类个数K值确定这一基础性问题提供了解决方案,但鉴于话题结构的复杂性,自动确定的K值也必然存在一定的准确性问题,因此如何获取较为准确的K值是本文的研究重点.
由于语义分析的结果与类簇中语义信息量的大小有直接关系,因此,在采样策略的选择上,本文选取了聚类个数K值由大到小的变化方式,将初始K值设置为报道个数M,采样过程中K值逐渐减小.变化的整体流程如算法1所示.具体过程是Gibbs采样先将每篇报道中的各词随机分配到K个主题中,每次迭代依据采样公式对各词重新分配主题.在迭代过程中,如果某主题中词数为0则去掉该主题,对应K值减1;如果某词不属于现有主题,则将其分配到新的主题,对应K值加1,收敛或达到迭代次数即终止采样.
在一轮Gibbs采样收敛之后,数据显示最终的聚类个数K距离样本中话题个数有一定差距,聚类个数大于话题个数意味着将较大话题进行了拆分.由于不同话题的报道数量并不均匀,数据往往具有较大的不平衡性,因此需要优先考虑大话题即热点话题的聚类性能,适当增加初始类簇的语义信息量,减少初始K值的个数.本文采用了逐层递进的形式来获取较为理想的K值,即重复进行多轮采样,下一轮采样的初始K值设置为上一轮采样结束后得到的K值,具体描述见算法1.当K值上下浮动在2以内时,则认为其近似稳定.实验结果表明,K值在几轮采样后会趋于稳定.

算法1 改进K值的采样算法输入:报道集合D,初始类数M,分布参数α、β.输出:主题数目K,主题集合Φ.步骤:1WHILEK值不稳定DO2随机初始化:为每篇文档中的每个词w,随机赋一个topic编号z∈(0,K-1).3扫描语料库,按照公式(2)、(3)和(5)重新采样每个词w的topic编号z,K值变化.4重复步骤3,直到采样收敛,得到新主题数目K,新主题集合Φ.5ENDWHILE6RETURNK,Φ.
2.2DPMM半监督模型构建
由于采样时初始的词语分配是随机分配到各个主题,在相同条件下进行DPMM聚类实验得到的实验结果不尽相同.由于动词和名词对新闻话题的表达贡献程度较大,本文考虑首先去掉语料中除动词、名词以外的其他词语,用较少更具代表性的词语来代表报道.
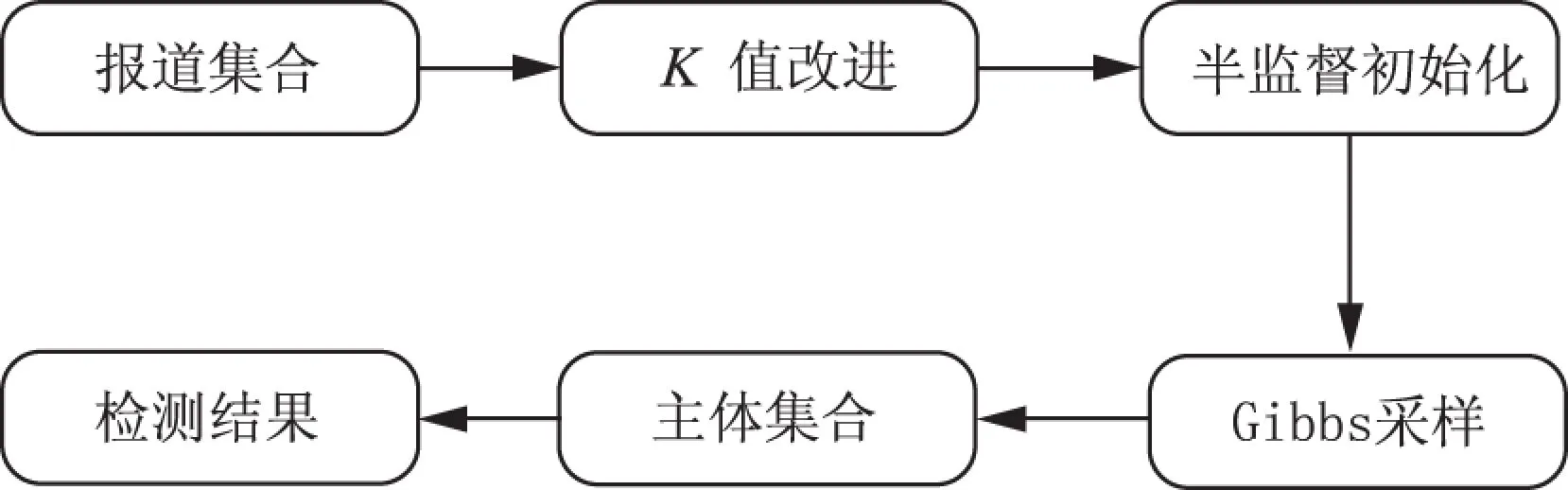
图2 半监督模型过程Fig.2 Process of semi-supervised model
根据Zipf定律,文档的词频分布符合幂律分布,在语义分析中这种幂律分布将导致大量的低频词受少量高频词的主题分布的影响[19].本文参考文献[8]的Cannot-link思想和文献[20]中成对约束信息的融入操作,在聚类的基础上加上少量先验知识,通过统计词频和人工分析的方式筛选出一组由人名、地名和组织名构成的名词实体作为“热点特征词”.组内各词在采样初始分配时不出现在同一个类中,而相同名词则聚集在一起,构建了DPMM半监督模型,所作改进并没有破坏DPMM模型的聚类特性.半监督模型的过程如图2所示,具体描述见算法2.

算法2 半监督模型构建算法
3 实验
为了验证所给方法的有效性,本节采用TDT4语料库中的中文新闻语料进行实验,对同一篇报道归属于两个话题的情况进行了去重操作,并根据实际需要,去掉了包含报道少于10篇的话题,采用具有较高普遍性的F值评测方法,进行了第2节中提到的K值改进和半监督两个方面的实验,并就实验结果进行了相关分析和比较.
3.1评测标准
F-measure评测方法[21]综合了信息检索中查准率(precision)与查全率(recall)的思想来进行聚类评价.一个分类i与相关聚类j的查准率P、查全率R和F值的定义为
P=preciseon(i,j)=(Nij/Nj);R=recall(i,j)=Nij/Ni;F(i)=2PR/(P+R),
(6)
其中:Ni表示分类i中的样例个数,Nj表示聚类j中的样例个数,Nij表示分类i与聚类j共有的样例个数.对分类i而言,取具有最大F值的聚类j作为其最终的关联聚类.因此对聚类结果来说,其总F值可由每个分类i的F值加权平均得到,
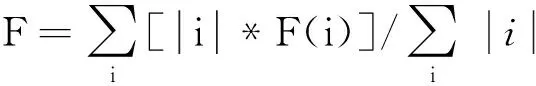
(7)
3.2K值改进实验
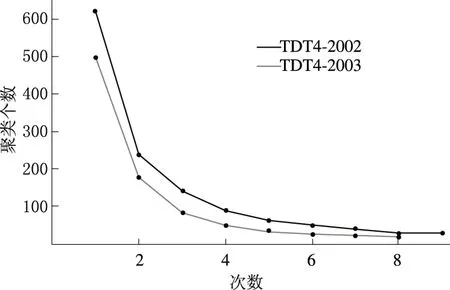
图3 聚类个数与递进次数的关系Fig.3 Relationship between cluster numbers and progressive times
为了充分发挥DPMM模型自主确定聚类个数K值的优势,本实验采用第2.1节中提到的递进方式来获得较为准确的K值,在DPMM无监督模式下进行,每轮采用的K值为多次实验的均值.具体如图3所示,聚类个数K随递进次数的增加呈下降趋势,对应于TDT4-2002和TDT4-2003的最终K值分别稳定在30和20左右,与已标注的话题个数较为接近.
3.3DPMM半监督实验
本实验首先去掉了语料中除动名词以外的其他词汇,适当弱化了不同报道之间的相似性;其次在先验知识的选择方面,本文以词频统计结果为依据,选择以地名为主、人名为辅的部分名词实体作为“热点特征词”来实现2.2节中所描述的操作,如表1所示,进而采用改进K值后的DPMM半监督模型来进行实验,并在相同语料上与DPMM基本模型、改进K值后的基本模型进行对比.

表1 热点特征词列表Tab.1 Hot key words list
表2列出了50次实验的平均值和最高值,DPMM表示基础模型,DPMM-K表示改进K值的模型,DPMM-S表示半监督模型.由于这3种方法在初始化时都存在较大的随机成分,因此其性能都不能简单地用平均F值来表示,而最大F值能够体现出模型的最佳潜能.从表2中不难看出单纯依靠DPMM模型无法实现较好的聚类效果,改进K值后的模型实验效果有所提升,而半监督模型在自动确定聚类个数的同时显著提高了模型的性能,有效保证了热点话题的检测结果.结合语料的构成对比TDT4-2002和TDT4-2003可知,基于语义分析的DPMM模型性能受语义信息量的影响,TDT4-2002中包含的话题和报道个数都要大于TDT4-2003,因此在性能上略有下降.
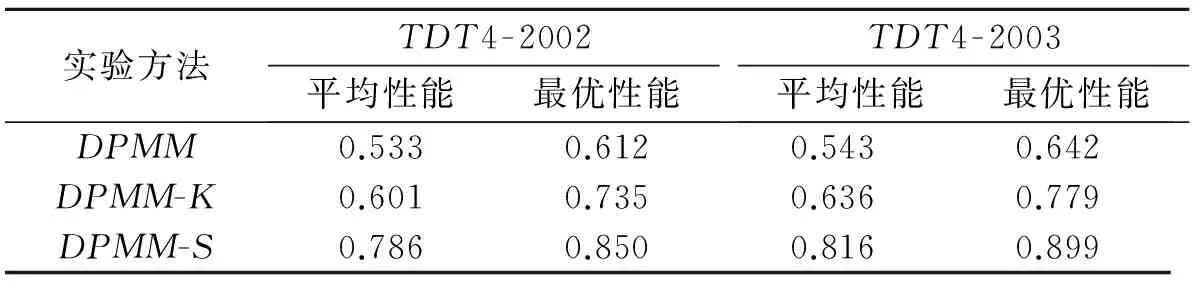
表2 不同方法的F值比较Tab.2 F value comparison of different methods
4 结束语
本文在DPMM模型的基础上,完善了中国餐馆过程在模型中的运用,采用了K值由大到小变化的采样策略,并结合深度学习的思想使模型自动确定的K值更为准确.通过分析聚类结果,得出了聚类结果在一定程度上受初始语料的影响,并做了相应的研究和改进.本文提出的半监督模型,通过加入一定的先验知识,使得模型的话题检测性能有了显著的提高.在接下来的工作中,应继续优化模型,进一步研究增加报道间区分度的方法和识别小话题的方法,使得模型更为可行.同时,增大实验的数据量,丰富语料库,在TDT标准语料的基础上,结合各大权威新闻网站的新闻报道,使理论算法更具有实际意义.
[1]洪宇, 张宇, 刘挺, 等. 话题检测与跟踪的评测及研究综述[J]. 中文信息学报, 2007, 21(6): 71-87.
[2]李胜东, 吕学强, 施水才, 等. 基于话题检测的自适应增量K-means算法[J]. 中文信息学报, 2014, 28(6): 190-193.
[3]周刚, 邹鸿程, 熊小兵, 等.MB-SinglePass:基于组合相似度的微博话题检测[J]. 计算机科学, 2012, 39(10): 198-202.[4]张晓艳. 新闻话题表示模型和关联追踪技术研究[D]. 长沙: 国防科学技术大学, 2010.
[5]GUOX,XIANGY,CHENQ,etal.LDA-basedonlinetopicdetectionusingtensorfactorization[J].Journalofinformationscience, 2013, 39(4): 459-469.
[6]潘云仙, 袁方. 基于JST模型的新闻文本的情感分类研究[J]. 郑州大学学报(理学版), 2015, 47(1): 64-68.
[7]ANTONIAKCE.MixtureofDirichletprocesseswithapplicationstoBayesiannonparametricproblems[J].Annalsofstatistics, 1974, 2(6): 1152-1174.
[8]VLACHOSA,GHAHRAMANIZ,KORHONENA.Dirichletprocessmixturemodelsforverbclustering[C]//Icmlworkshoponpriorknowledgefortext&languageprocessing.Helsinki, 2008: 74-82.
[9]梅素玉, 王飞, 周水庚. 狄利克雷过程混合模型、扩展模型及应用[J]. 科学通报, 2012, 57(34): 3243-3257.
[10]王婵. 基于Dirichlet过程混合模型的话题识别与追踪[D]. 北京: 北京邮电大学, 2013.
[11]ZHANGH,JONATHANWQM,NGUYENTM.ImagesegmentationbyDirichletprocessmixturemodelwithgeneralisedmean[J].Ietimageprocessing, 2014, 8(8):103-111.
[12]BLEIDM,NGAY,JORDANMI.LatentDirichletallocation[J].Journalofmachinelearningresearch, 2003, (3): 993-1022.[13]FERGUSONTS.ABayesiananalysisofsomenonparametricproblems[J].Annalsofstatistics, 1973, 1(2): 209-230.
[14]徐谦, 周俊生, 陈家俊.Dirichlet过程及其在自然语言处理中的应用[J]. 中文信息学报, 2009, 23(5): 25-32.
[15]PITMANJ.Combinatorialstochasticprocesses[M].Springer,Berlin, 2006: 75-92.
[16]NEALRM.MarkovchainsamplingmethodsforDirichletprocessmixturemodels[J].JournalofcomputationalandgraphicalStatistics, 2000, 9(2): 249-265.
[17]SATOI,NAKAGAWAH.Topicmodelswithpower-lawusingPitman-Yorprocess[C]//Proceedingsofthe16thACMSIGKDDinternationalconferenceonknowledgediscoveryanddatamining.WashingtonDC, 2010: 673-681.
[18]HEINRICHG.Parameterestimationfortextanalysis[R].Germany:FraunhoferIGD, 2005.
[19]张小平, 周雪忠, 黄厚宽, 等. 一种改进的LDA主题模型[J]. 北京交通大学学报(自然科学版), 2010, 34(2): 111-114.[20]蒋文, 齐林. 一种基于深度玻尔兹曼机的半监督典型相关分析算法[J]. 河南科技大学学报(自然科学版), 2016,37(2): 47-51.
[21]STEINBACHM,KARYPISG,KUMARV.Acomparisonofdocumentclusteringtechniques[C]//Proceedingsofthe6thACM-SIGKDDinternationalconferenceontextmining.Boston, 2000: 103-122.
(责任编辑:王浩毅)
NewsTopicDetectionBasedonSemi-supervisedDPMM
YAODongdong1,YUANFang2, 3,WANGYu1,LIUYu3
(1. School of Computer Science and Technology, Hebei University, Baoding 071000, China;2. Department of Computer Teaching, Hebei University, Baoding 071000, China;3. College of Mathematics and Information Science, Hebei University, Baoding 071000, China)
BasedontheDirichletprocessmixturemodel(DPMM),combiningwiththemodel’sbasiccharacteristicofautomaticallylearningtheclusternumber,thelatenttopicinformationdetectionwasheldfromtheperspectiveofsemantics.AmoreaccurateK-valuewasobtainedwiththesamplingstrategyofK-value’schangingfrombigtosmallstepbystep.Afteranalyzingthetermfrequencycharacteristicsofsemanticclustering,agroupofnounentitieswereintroducedas“hotterms”toguidetheclusteringprocess,whichcouldbeconsideredastheDPMMsemi-supervisedmodel.TheresultsonTDT4corpusshowedthattheproposedtopicdetectionmethodwaseffective.
topicdetection;Dirichletprocess;Gibbssampling;powerlaw;nounentity
2016-04-07
河北省软科学研究计划项目(12457206D-11, 13455317D).
姚冬冬(1990—),男,河北邢台人,硕士研究生,主要从事数据挖掘研究,E-mail:ydd625@qq.com;通讯作者:袁方(1965—),男,河北安新人,教授,主要从事数据挖掘、社会计算研究,E-mail:yuanfang@hbu.edu.cn.
TP391.1
A
1671-6841(2016)03-0063-06
10.13705/j.issn.1671-6841.2016070
引用本文:姚冬冬,袁方,王煜,等.基于半监督DPMM的新闻话题检测[J].郑州大学学报(理学版),2016,48(3):63-68.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2021年9期)2021-10-14
开放教育研究(2020年2期)2020-03-31
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
铁道通信信号(2019年6期)2019-10-08
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
雷达学报(2017年6期)2017-03-26
中国修辞(2017年0期)2017-01-31
互联网天地(2016年1期)2016-05-04
