
一种基于云模型的融合相似度推荐方法
2016-10-25 07:55马建勇周宇红
广东通信技术 2016年9期
[马建勇 周宇红]
一种基于云模型的融合相似度推荐方法
[马建勇 周宇红]
云模型 协同过滤 推荐系统 相似度
马建勇
重庆邮电大学通信与信息工程学院,宇龙计算机通信科技(深圳)有限公司。
周宇红
重庆邮电大学通信与信息工程学院。
1 引言
最近邻协同过滤技术是当前最成功的推荐技术[1]之一,它基于评分相似的最近邻居的评分数据向目标用户推荐信息。随着电子商务系统规模的进一步扩大,用户数目和项目数据急剧增加,导致协同过滤技术的稀疏性问题越来越严峻,影响了推荐系统的推荐质量。
为解决数据稀疏性问题,一些学者采用对稀疏的用户-项矩阵进行填充的技术来提高相似度度量效果。处理过程如下:(1)采用预测评分的方式先估算出未评分项目的评分,将用户-项矩阵填充完整;(2)在得到的稠密矩阵上计算用户间的相似度,以最近邻算法进行推荐[2],由于该算法在计算项目相似性时仍然沿用传统的相似性计算方法,而且没有考虑项目的分类信息,从而影响了推荐质量。文献[14]引入了项目分类信息,采用修正的条件概率计算项目之间的相似性,并用于对用户没有评价过的项目进行评分估计,填充用户-项矩阵,进而根据填充了的用户-项矩阵计算用户相似性,取得了不错的效果。然而,该算法依然把用户对所有项目的评分作为单个向量进行用户相似度的计算和指导最近邻居的选择,在一定程度上影响了算法的效能。文献[3-4]提出基于云模型的相似性度量方法。文献[3]给出一种基于云模型的用户相似度比较方法(LICM)。文献[4]提出一种在知识层面比较用户相似度的方法,改善了传统相似度比较方法必须严格匹配对象属性的不足,且在一定程度上克服用户评分数据极端稀疏的负面影响。
本文采用云模型来计算相似度,并提出一种融合相似度推荐算法。从用户-项评分矩阵中挖掘出更多有用信息,在用户-项评分矩阵中的个体评分看作是对未评分项目的独立预测,个体与目标用户的相似度及与未评分项目的相似度作为个体预测的信任度。同时将用户相似度和项目相似度引入到用户-项评分矩阵中来,并将相似用户对相似项目的评分融合到算法中来,能够有效的解决数据稀疏性问题。
2 基于云模型的相似性度量方法
2.1 云模型
在传统的模糊数学和概率统计的基础上,李德毅院士提出表述定性定量互换的云模型[4]。云模型主要反映事物的模糊性和随机性。通过将这两种不确定性结合起来,使得可以用定量的数值表示出某个定性概念的含义,或者用定性的语言描述出定量的数值。U是一个定量的论域,C是一个定性值。隶属度CT(x),(CT(x)∈[0,1])是一个具有稳定倾向的随机数。它描述U中的元素x和T之间的定性关系。隶属度在论域上的分布称为隶属云,简称云。因此,云是从论域U到区间[0,1]的一个映射,即x∈U,x→CT(x)序对(x,CT(x))称为云滴。一个云滴是定性概念在数量上的一次实现,大量云滴组成云。尽管在不同的时刻产生的云滴不同,但是云的数字特征决定云的整体形态基本不变。云的数字特征由期望Ex,熵En,超熵He三个数值来表示,他们反映了定性概念上的定量特征。
2.2 基于云模型的用户特征表示
假定评分标准为5个级别:{很不满意,不满意,一般,满意,很满意},相应的分值分别为{1,2,3,4,5}。统计用户的评价情况,记为U(u1,u2,u3,u4,u5),其中u1~u5为评价的次数,称为用户评分频度向量,通过逆向云算法可以计算出用户评分特征向量,记为P =(Ex,En,He)。其中,期望Ex反映了用户对所有项目的平均满意程度,为偏好水平;熵En反映了用户投票的集中程度,为投票偏好的离散度;He为熵的稳定度。
2.3 基于云模型的相似性度量
为了对云模型表示的定性知识进行相似性比较,文献[2]给出了云的相似度定义:
定义:给定两个云i和j的数字特征组成的向量,Vi和Vj,它们之间的余弦夹角称为云i和j之间的相似度。
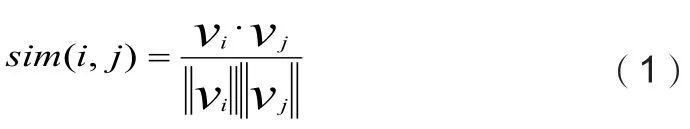
这种基于云模型的概念相似性比较方法记为LICM(Likeness Method based on Cloud Model)方法。
3 背景
3.1 基于用户的协同过滤
基于用户的协同过滤算法,通过相似用户对项目的评分来预测目标用户对未评分项目的评分[5],本文通过云的相似度计算用户之间的相似性。具体如下:
(2)计算用户相似度矩阵
用户相似度矩阵可以表示为:
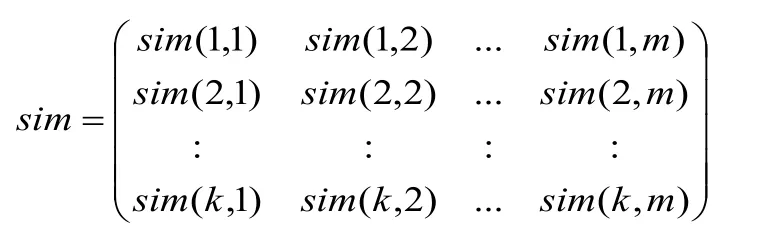
其中,sim(i,j)表示用户i和j的相似度,由式(1)可以计算得出。根据用户-项矩阵,用户相似度矩阵sim,对于目标用户Uk在整个用户空间中查找目标用户的N个最近邻居且该用户对目标项目有评价记录,得到最近邻居集BUk= {U1,U2,...,Un},其中,,且U1与用户的相似性sim(Uk,U1)最高,U2与用户Uk的相似性次之,依次类推。因此,目标用户Uk对于未评分项Im的预测评分可以表示如下:


3.2 基于项目的协同过滤
基于项目的协同过滤算法,通过相似项目的评分来预测未评分项目的评分[6],我们依然采用云模型来计算项目间的相似度。
(2)根据云的相似度计算公式(式(1))来计算未评分项目与其他项目的相似性。
将相似性最高的N个项作为对于未评分项Im邻居集BIm={I1,I2,...In},其中,且I1与未评分项Im的相似度最高,I2与未知项Im的相似度其次,依次类推[8-9]。因此,目标用户Uk对于未评分项Im的预测评分可以表示如下:

其中rk,b表示用户k对项目b的评分,因此我们定义“相似项目评分集合”如下:

4 相似度融合

将上面三种预测评分组合到协同过滤算法里面,用户-项评分矩阵中每个元素看作是独立的预测,其与目标项的评分相似度称为信任度。元素的预测评分与信任度的加权平均作为元素对目标项的预测评分。
4.1 预测评分
用户对项目的评分具有差异性,一些用户倾向于打很高的分数,因此有些物品因为一些极度活跃用户而获得评分远超过了它们的“真实评分”,为了消除评分的差异性,在预测之前对用户-项评分矩阵中的评分做归一化处理。减去用户和项的平均评分作为个体预测评分,如

pk,m(ra,b)表示用户k对目标项m的预测评分,其中,表示用户a和用户k的平均评分,,表示项目b和项目m所获得的平均评分。
4.2 概率融合

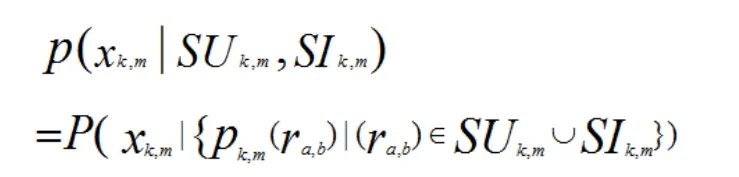


最后,下面等式给出了对未知评分的预测评分
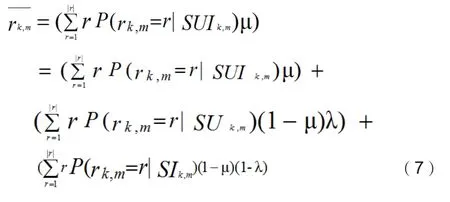
最后给出的模型,融合了最近邻评分预测三个不同的数据源,通过μ和λ控制评分的来源。
4.3 概率估计

其中,sim(a,b)计算如式(1)。
条件概率表示如下:
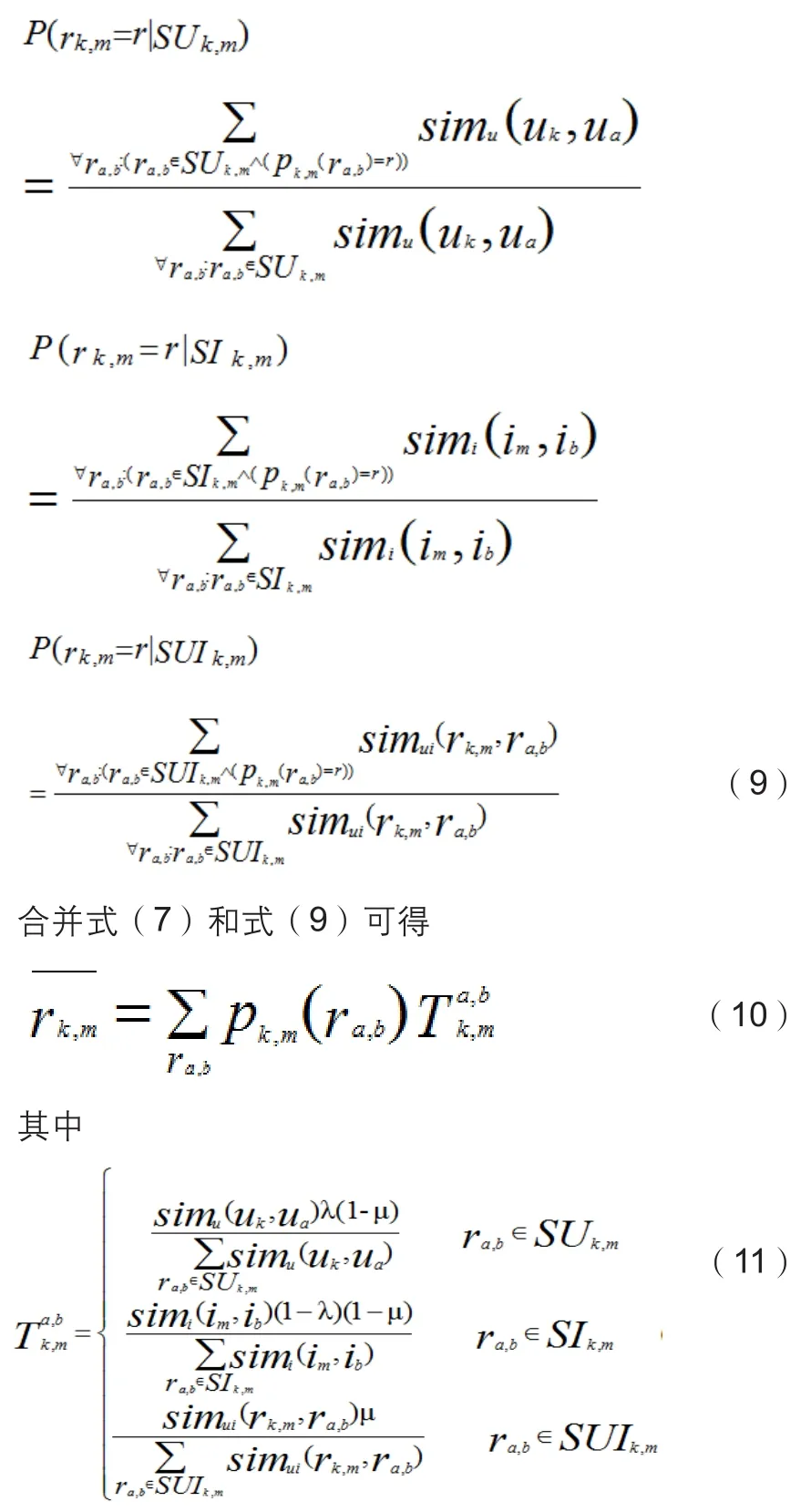
5 实验结果
5.1实验设计
本文使用MovieLens站点提供的测试数据集,该站点是一个基于Web的研究型推荐系统,用于接收用户对电影的评分并提供相应的电影推荐列表。从该站点下载1997年9月19日-1998年5月22日的数据集,包括943个用户对1 682个项目(影片)的10万条投票记录,把记录按照80%和20%的比例划分为训练集和测试集。
推荐质量的评价标准主要有两类:统计精度度量方法和决策支持精度度量方法[7-8]。本文通过平均绝对误差来度量预测的准确性,MAE越小,推荐质量越高。MAE可由下式计算

其中,L表示测试评分的数目。
5.2 参数影响
参数λ决定SUk,m和SIk,m的预测评分,参数μ平衡插入SUIk,m的预测评分。
首先,将参数μ设置为0,测试参数λ的敏感程度,称为SF1组合,融合了基于用户和物品的方法没有引入其他的背景信息。图1展示了MAE随着参数λ(从0到1)的变化情况,图表根据用户稀疏程度5和20,以及物品稀疏程度小于5和无约束四种情况划分成了4条曲线,明参数λ的值说明插入基于用户和物品的SF1推荐方法能够提升推荐系统的性能,当λ取值在0.6-0.9之间的时候,效果最佳,实验结果表明SIk,m的预测评分相比于SUk,m更可靠。图2展示了当参数λ取值为0.7,参数μ的敏感程度。与图1类似根据四种情况将图表划分成了四条曲线,参数μ从0到1变化。当参数μ非零时,SF1的结果经过SUIk,m平滑处理,我们称为SF2组合。通过观测图表我们可以发现,当最近邻评分数据稀疏时,μ取值0.8效果最佳。然而,当物品稀疏不被约束的时候在很大的一个取值范围内都是最优值,而且对MAE的提升并不明显。最近邻居的个数N也会影响到组合推荐方法的性能。图3显示了SF2推荐指标MAE随着邻居评分的数目变化情况,邻居个数在50到100之间,效果最佳。

图1参数λ对MAE的影响

图2 参数μ对MAE的影响
5.3 与其他方法比较
我们继续与其他推荐方法的结果进行比较。对于SF1,将λ设置为0.7,μ设置为0;对于SF2,λ=0.7,μ=0.7。分别与基于用户的方法,基于物品的方法比较。图4表明了SF1和SF2方法优于其他方法。

图4 不同推荐方法MAE随最近邻居数变化
6 结束语
本文提出了一个基于云模型的组合相似度推荐方法,通过融合基于用户和基于物品的协同过滤方法来克服数据稀疏性的限制,通过插入相似用户对相似物品的评分来平滑评分预测。实验表明,基于云模型的组合相似度推荐方法能够有效的提高推荐的准确性并且能够克服数据稀疏性问题。后期我们会深入分析挖掘更多的信息融入到相似度计算中来,比如社交关系等,以提高推荐的准确性。
1J Breese,D Heeh man,CKadie.Empirical analysis of predictive algorithms for collaborative filtering.In:Proc of the 14th Conf on Uncertainty in Artificial Intelligence(UAI98)San Francisco,CA:Morgan Kaufman,1998,43-52
2张光卫,康建初,李鹤松等.面向场景的协同过滤推荐算法[J].系统仿真学报,2006,18(2):595-601
3邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤算法.软件学报,2003,14(9):1621-1628
4李德毅,杜鹢.不确定性人工智能[M].北京:国防工业出版社,2005
5J.L.Herlocker,J.A.Konstan,A.Borchers,and J.Riedl.An algorithmic framework for performing collaborative filtering.In Proc.of SIGIR,1999
6J.Kittler,M.Hatef,R.P.W.Duin,and J.Matas.On combining classifiers.IEEE Trans.Pattern Anal.Mach.Intell.,1998,20(3):226-239
7Zhang BQ.A collaborative filtering recommendation algorithm based on domain knowledge.Computer Engineering,(in Chinese with English abstract),2005,31(21):7-9
8Sarwar B,Karypis G,Konstan J,Riedl J.Item-based collaborative filtering recommendation algorithms.In:Proc.of the 10th Int'l World Wide Web Conf.Hong Kong:ACM Press,2001. 285-295
9Y Koren,R Bell.Advances in collaborative filtering.Recommender systems handbook.Springer US,2011:145-186
10C Desrosiers,G Karypis.A comprehensive survey of neighborhoodbased recommendation methods.Recommender systems handbook.Springer US,2011:107-144
10.3969/j.issn.1006-6403.2016.09.006
2016-07-29)
传统协同过滤算法依据用户的共同评分来计算用户相似度,进而产生推荐。随着系统用户数目和商品数目的不断增加,用户共同评分的项目越来越少,甚至没有,因此传统的协同过滤算法对用户之间相似度的衡量将会越来越不准确,导致整个推荐系统的准确度降低。针对这一问题,本文提出一种基于云模型的融合相似度推荐方法,并使用云模型来计算相似度。实验结果表明,该算法能有效解决用户评分数据的稀疏问题,还能提高推荐系统的推荐质量。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
河北画报(2020年8期)2020-10-27
汽车观察(2019年2期)2019-03-15
中国卫生(2016年5期)2016-11-12
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
浙江大学学报(工学版)(2016年2期)2016-06-05
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
