
北斗卫星信号仿真器的GPU速度优化
2016-10-22 09:05胡铁乔赵小龙
中国民航大学学报 2016年3期
胡铁乔,赵小龙,陈 明
(1.中国民航大学智能信号与图像处理重点实验室,天津 300300;2.北京一朴科技有限公司,北京 100080)
北斗卫星信号仿真器的GPU速度优化
胡铁乔1,赵小龙1,陈明2
(1.中国民航大学智能信号与图像处理重点实验室,天津300300;2.北京一朴科技有限公司,北京100080)
针对卫星信号软件仿真器耗时长的问题,提出基于图形处理器(GPU)的速度优化方法并介绍了现有卫星信号仿真器的特点。在分析仿真器结构的基础上给出了结构调整方案,介绍了不同GPU存储器的特点及优化方法。基于计算统一设备架构(CUDA)实现了北斗卫星信号仿真器的数据实时生成。对速度优化后的仿真器进行了速度测试和性能验证。介绍了仿真器程序优化过程,优化后的仿真器大大提高了信号生成速度和科研效率,对程序优化具有一定的借鉴意义。
仿真器;图形处理器;计算统一设备架构
除了美国的GPS导航系统和欧洲的伽利略导航系统,中国也发展了自己的导航系统,即北斗卫星导航系统(BeiDou Navigation Satellite System)[1]。卫星信号仿真器在全球导航卫星系统(GNSS)接收机的开发过程中起着重要作用。相对于利用真实卫星信号,软件模拟器提供可控场景,提高接收机的研发效率[2-3]。基于硬件的仿真器相对复杂,技术难度比较大[3],而基于PC平台的软件模拟器则具有结构灵活、开放、低成本等优点[4-6]。但由于软件仿真器在生成中频数据的过程中需进行大量数据计算,在CPU上进行串行计算需消耗的时间比较长,不能产生实时信号,因此计算速度成为影响仿真器效率的关键因素。
在利用软件仿真器进行场景仿真时,通用的做法是先将生成的数据进行存盘,使用时再去读取文件。GPU是一种高度并行化的众核处理器,可以利用大量处理单元进行并行计算,CUDA是由NVIDIA在2006年提出的利用CPU实现通用计算的编程模型,研发人员可以使用熟悉的C语言编写CUDA并行程序[7],为仿真器的速度优化提供了便利,也为仿真器实时生成中频数据提供了可能。使用实时化仿真器生成信号并通过硬件回放卡实时回放信号,完全可以达到与硬件仿真器同样的效果,同时具有容易扩充、方便调整的优点。实时化仿真器可大大缩短信号生成时间,显著提高科研效率。
1 北斗卫星信号仿真器
1.1北斗卫星信号结构
B1、B2信号由I、Q两个支路组成,信号由“测距码+导航电文”正交调制在载波上。B1、B2信号表达式分别为
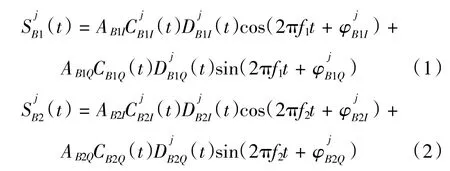
其中:上标j表示卫星编号;下标B1I表示B1频点I支路,B1Q表示B1频点Q支路,B2I表示B2频点I支路,B2Q表示B2频点Q支路;A表示振幅;C表示测距码;D表示调制在测距码上的数据码;f1表示B1信号载频;f2表示B2信号载频。
1.2总体功能
仿真器功能模块包括:卫星位置和用户位置计算模块、伪随机码生成模块、导航电文生成模块、随机噪声生成模块、误差仿真模块和信号生成(调制)模块。信号仿真器总体流程如图1所示。

图1 卫星信号仿真器流程图Fig1 Simulator flow chart
配置参数由配置文件获取,配置文件中记录了配置的信号频率(B1频点、B2频点)、中频频率、采样率、载噪比、前端带宽、量化位数、是否正交输出、是否仿真误差、轨迹文件路径等参数。程序需要从文件中读取用户设置的起始仿真时间、仿真时长、用户速度、用户轨迹类型等参数。为了加快仿真速度,用户位置提前计算好,使用时再进行查表。仿真器每次仿真0.1 s的数据,在0.1 s时间内判断一次可见星,每颗可见星计算一次码延时(Tp)和载波相位延时(Tc)、进行一次信号调制(信号生成),添加随机噪声并进行一次量化,最后写入文件。如果设置的仿真时长全部完成,则结束程序[4-6]。
1.3仿真器结构调整
信号仿真器的速度优化瓶颈是信号生成部分,由于计算量较大,因此该部分是优化的重点。信号生成部分是一个循环结构,该部分的伪代码为

为适应并行化计算,程序结构需适当调整,并且为了与信号回放卡连接,信号生成部分的速度要足够快。因此为尽量降低该部分的工作量,将判断可见星的计算放在信号生成模块之外,使用时进行查表。同时,卫星信号的码延时和载波相位延时计算(Tp、Tc真值的生成及插值计算)比较耗时,因此该部分也调整到了信号生成模块之外(提前生成真值)。
2 仿真器的GPU优化
2.1CUDA编程模型
在CUDA编程模型中,PC机的CPU称为主机(Host),GPU称为设备(Device),二者协同工作。在一个完整的程序中,CPU主要处理串行计算和逻辑性较强的事务,而GPU则负责执行高度线程化的并行处理任务[9]。在GPU上运行的CUDA并行计算函数称为内核(kernel),一个完整的CUDA程序由主机端的串行处理函数和一系列设备端的内核并行处理函数共同组成,如图2所示。
在CUDA架构下,线程(Thread)是GPU执行的最小单位,若干个线程组成线程块(Block),若干个线程块构成一个网格(Grid),一个网格对应一个内核函数。
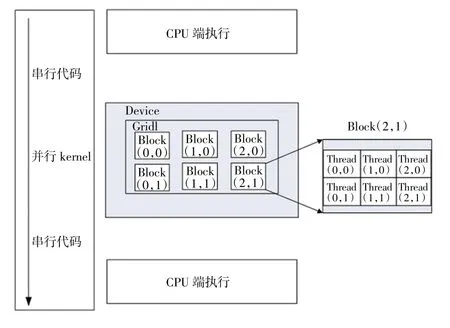
图2 CUDA编程模型Fig2 CUDA programming model
2.2仿真器的GPU优化
2.2.1存储器优化
CUDA程序在运行前需将数据从主机端复制到显存中,计算结束后将数据从显存复制回内存。全局存储器位于显卡的显存中,CPU和GPU都能对其进行读写访问。同时,所有线程都能读写其任意位置,一般用于存储大型的公用数据,如仿真器中用到的时间数组,以62 MHz采样率为例,每次计算0.1 s,则时间数组有6.2 M个double型元素,共占用49.6 M存储空间,故该变量只能位于全局存储器。此外,生成调制信号用到的正弦和余弦表、星历参数等数据量较大的参数都位于全局存储器。在计算能力3.5的显卡上,全局存储器具有缓存,如果遵守全局存储器的对齐要求,就可避免分区冲突,有效利用带宽,否则会导致较低的访问效率[7]。
常量存储器(constant memory)顾名思义就是存储常数的存储器,是另一种具有缓存的存储器,GPU生成信号过程中用到的参数如采样率、中频频率等可以存储在常量存储器。
使用页锁定存储器(pinned memory)可以明显提高主机内存和设备全局存储器的数据传输速度。如生成的卫星信号位于全局存储器,同时在内存上使用cudaHostAlloc(void**pHost,size_t size,unsigned int flags)函数分配一段页锁定存储器,并且flags参数配置为cudaHostAllocMapped,即在内存上分配的空间可以映射到显存。使用cudaHostGetDevicePointer(void** pDevice,void*pHost,unsigned int flags)函数可以获得该内存空间映射到显存的地址指针,这就意味着映射的页锁定存储器有两个地址指针,一个位于内存,另一个位于显存。这样CPU和GPU都可以访问该空间,并且没有显式的数据传输,速度较一般的数据拷贝方式要快[11-12]。
此外,共享存储器(shared memory)的使用可以显著提高数据访问速度。Shared memory位于GPU片内,访问速度仅次于寄存器,同一个块内的线程都可以访问,是Block内线程通信的一种理想方式,一般用于存储Block线程公用数据。在没有存储体冲突(bank conflict)的情况下其速度可达到寄存器的速度[7]。Shared memory是以bank为单位组织的,在32位模式下bank以4字节为单位组织,相邻的4字节位于不同的bank;在64位模式下,bank以8字节为单位组织,相邻的8字节位于不同的bank。在32位模式下,以32×32的float型数组为例介绍共享存储器的访问特点,如图3所示。

图3 32×32 float型数组Fig3 32×32 float array
1)1个 warp内的 32个线程同时访问 32个bank,其特点是每次只能响应1个线程的访问请求,因此32个bank同时响应32个线程,没有访问冲突;
2)32个线程同时访问共享存储器中的1个bank,由于CUDA的广播机制,该bank中的数据会一次广播给warp中的所有线程,因此也没有访问冲突;
3)当所有warp中的所有线程同时访问同一列时,由于同一列属于1个bank,而1个bank每次只能相应1个线程的访问请求,因此有冲突。
2.2.2部分算法的改进
为了适应并行计算,在不影响仿真器性能的条件下,部分算法进行了改进。以Tp、Tc的插值算法为例,原来使用了三阶内插算法,计算相对耗时且不利于并行计算,现改为线性内插算法,使用y=kx+b式近似推出所有采样点的Tp、Tc值。信号生成的周期是0.1 s,Tp、Tc真值的生成周期是1 ms,因此在1个信号生成周期内有100个真值,每个块处理fs/100个点。
以tp[100]表示提前生成的真值,因为有100个真值,因此在GPU上需要分配100个Block,每个Block的大小根据需要分配,如可分配128个线程。每个Block计算1个斜率kbid,下标bid代表每个Block的ID。在CPU上串行执行的线性内插部分代码为

该并行计算模型如图4所示。
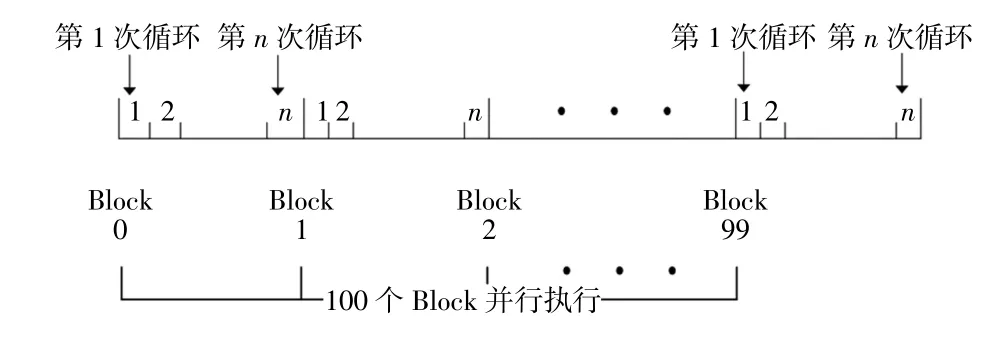
图4 100个Block并行运行示意图Fig.4 100 Blocks run in parallel
这样在GPU上就有100个Blcok同时执行,计算速度大大加快。
2.2.3加噪和量化函数的优化
加噪函数(AddNoise())仅仅做了一次加法运算,并且CPU生成的随机噪声在信号生成模块之前已经复制到显存,对全局存储器的访问满足对齐要求,因此在GPU上完成加噪功能速度很快。由于量化函数(Quantization())在计算过程中需使用所有数据的和,故在量化函数中使用了并行规约求和思想[10],并行规约算法适合在GPU上并行执行。加噪函数和量化函数分别在CPU和GPU上的运行耗时对比如表1所示。
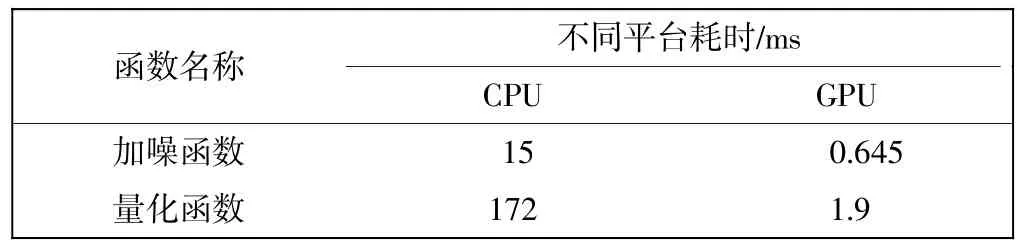
表1 两个函数并行化前后速度对比Tab.1 Speed contrast before and after parallelization
其他优化手段包括指令优化等,如求模运算每次需要32个时钟周期,而改为等价的乘法指令则只需要4个时钟周期[9]。数据的存储精度对速度同样会有较大的影响,由于仿真器量化后的存储类型是char型,故在不影响精度的情况下,可将生成信号的类型由double型改为float型,这样精度没有损失,但却增加了运算吞吐量,因此运行速度也会加快。
3 优化后的仿真器速度及性能测试
对仿真器进行优化的主要目的是提高信号生成速度,同时又不损失性能,以下将分别验证。
3.1速度测试
信号生成部分的调制过程与在CPU上计算没有差别,不同的是在CPU上是单线程计算,而在GPU上同时有大量线程计算。由于对存储器的访问进行了细致的优化以及对仿真器结构的调整,因此信号生成速度大大加快。测试时长设置为10 s、50 s、100 s,分别使用优化前的CPU版本和优化后的GPU版本进行测试。采样率为80 MHz,中频频率为29.52 MHz,测试用的PC平台为HP Z820工作站,运行程序的显卡为GTX TITIAN Black高性能游戏显卡,该显卡核心为英伟达GK110,具有2 880个流处理单元,核心频率为889 MHz,板载6 G容量的GDDR5显存,显存位宽384 Bit,采用PCI-E 3.0接口,计算能力为3.5。测试结果如表2所示。
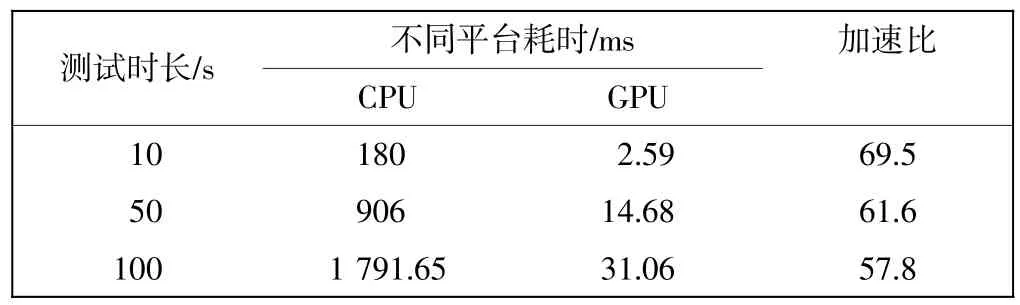
表2 优化前后速度测试对比Tab.2 Speed contrast before and after parallelization
由表2可知,仿真器速度已达到实时要求,加速比达到60左右,并有一定冗余量,这为连接硬件回放卡奠定了基础。
3.2性能测试
用软件接收机(SDR)对仿真器生成的数字中频文件进行验证。测试使用北京一朴科技有限公司的GNSS仿真验证软件,该软件由GPS-L1及北斗B1、B2、B3频点的仿真和验证功能部分组成。
用实时化后的仿真器生成数字中频数据文件,测试频点为BD2-B3频点,初始WGS84坐标为(40,120,100),初始ENU速度为(3,4,0),载噪比设置为43。
在GNSS仿真验证软件菜单栏选择“系统类别”中的“接收机”选项,再点击“参数设置”配置接收机参数,本次测试的参数配置如图5所示。
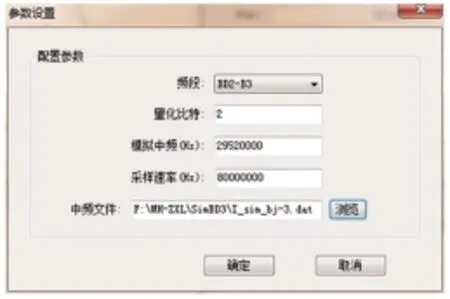
图5 参数设置Fig.5 Parameter setting
点击菜单栏“运行”后,GNSS仿真验证软件运行界面如图6所示。软件主界面分星空图、位置信息、图表信息、通道信息4部分,仿真器位置及速度在位置信息部分会显示。由图6可看出位置及速度解算均正确,证明仿真器经CUDA速度优化后,性能没有损失。
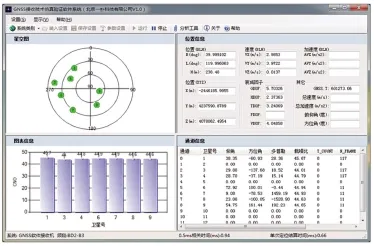
图6 软件接收机Fig.6 GNSS SDR
4 结语
针对基于CPU的卫星信号仿真器生成信号速度慢的缺点,基于GPU利用CUDA架构对仿真器进行优化,使其速度大大提高,满足实时生成信号的要求,为连接回放卡实时回放信号提供了基础。经接收机验证,没有性能损失。后续研究将通过进一步提高GPU对资源的利用率来提高计算速度,同时研究利用GPU实时生成多天线信号。
[1]北斗卫星导航系统网站.北斗卫星导航系统简介[EB/OL].(2015-05-02)[2015-09-02].http://www.beidou.gov.cn.
[2]王帅.GNSS多频段卫星信号模拟器关键技术研究及其实现[D].桂林:桂林电子科技大学,2014.
[3]王军.GPS卫星信号模拟器的硬件实现[D].西安:西安理工大学,2011.
[4]傅金梅.GNSS中频卫星信号的仿真研究 [D].西安:西安电子科技大学,2014.
[5]熊智华.GNSS中频卫星信号的仿真研究 [D].南京:南京理工大学,2012.
[6]侯博,谢杰,范志良,等.多模卫星信号模拟器设计与实现[J].计算机测量与控制,2012,20(1):170-172.
[7]NVIDIA.CUDACProgrammingGuidv7.0[EB/OL].(2015-03-05)[2015-08-30].http://www.signal-pro.org.cn/CN/column/column106.shtml.
[8]王颢.GNSS卫星信号模拟器的软件设计与实现 [D].西安:西安电子科技大学,2013.
[9]刘金硕,邓娟,周峥,等.基于CUDA的并行程序设计[M].北京:科学出版社,2014:92-108.
[10]MARK HARRIES.Optimizing Parallel Reduction in CUDA[EB/OL].(2015-03-05)[2015-09-02].http://docs.nvidia.com/cuda/samples/6_ Advanced/redu-ction/doc/reduction.pdf.
[11]NVIDIA.CUDA RunTime API v7.0[EB/OL].(2015-03-05)[2015-08-31].http://docs.nvidia.com/cuda/cuda-runtime-api/index.html.
[12]NVIDIA.CUDACBestPracticeGuidev7.0[EB/OL].(2015-03-05).[2015-09-02].http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/.
(责任编辑:党亚茹)
Speed optimization of Beidou satellite signal simulator based on GPU
HU Tieqiao1,ZHAO Xiaolong1,CHEN Ming2
(1.Intelligent Signal and Image Processing Key Lab of Tianjin,CAUC,Tianjin 300300,China;2.Beijing YIPU Technology Co.,Ltd,Beijing 100080,China)
The existing Beidou satellite signal software simulator is time-consuming,a method of program performance optimization based on GPU(graphic processing unit)is proposed.Introducing the features of existing satellite signal simulator,the structure adjustment plan is given after analyzing the simulator structure.Characteristics and optimization methods of different GPU memory is introduced and the real-time signal generator based on CUDA(compute unified device architecture)is realized.The performance and speed of optimized simulator are tested and verified with detailed optimizing process.The optimized simulator speeds up the signal generation and improves the efficiency of science research.The current method has a certain referencial significance on program optimization.
simulator;graphics processing unit;unified compute device architecture
TN96;V241.52
A
1674-5590(2016)03-0033-05
2015-09-06;
2015-10-16
国家自然科学基金项目(61271404,61471363);中央高校基本科研业务费专项(3122014D008)
胡铁乔(1970—),男,河南洛阳人,副教授,硕士,研究方向为自适应信号处理、阵列信号处理、硬件系统的设计与实现.
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
空军工程大学学报(2021年2期)2021-05-29
中国计算机报(2020年9期)2020-03-25
通信电源技术(2020年2期)2020-02-22
制导与引信(2018年2期)2018-11-09
汽车文摘(2014年9期)2014-12-13
火控雷达技术(2014年1期)2014-06-23
环球时报(2014-06-18)2014-06-18
空间控制技术与应用(2010年3期)2010-12-23
空间控制技术与应用(2009年3期)2009-01-20
