
一种基于python语言的网络爬虫研究
2016-10-21 02:26刘洋崔翠李立新
科学与财富 2016年9期
刘洋 崔翠 李立新

摘要:随着Internet技术的不断发展,互联网已经成为人们获取信息的主要途径,搜索引擎从互联网中靶向性筛选出有用信息,而网络爬虫又是搜索引擎的基础构件之一。本文实现了一个基于python语言的并行网络爬虫,利用关键字匹配技术对目标网站进行扫描,得到敏感数据并抓取,分析网站数据结构和受恶意攻击的风险系数。
关键词:搜索引擎 网络爬虫 python 敏感数据
1引言
网络爬虫(Crawler)是搜索引擎(search engine SE)的基本构件之一,其直接面向互联网底层,它是搜索引擎的数据发源地,决定着整个系统的内容是否丰富、信息能否得到及时更新。它的性能表现直接影响整个搜索引擎的效果。网络爬虫的工作原理如下:从一个初始種子URLs出发,从中获取一个URL,下载网页,从网页中抽取所有的URLs,并将新的URLs添加到URLs队列中。然后,Crawler从队列中获取另一个URL。重复刚才的过程,直到Crawler达到某种停止标准为止。
搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。我们经常看到不同的网站发布着同样的新闻,很多就是通过网络爬虫的技术从其它的网站爬取信息,然后放在自己的网站发布。同样,这样的爬虫技术也可以用来帮助我们做安全扫描分析等工作,这也是本文研究的重点。
2国内外研究现状及相关核心技术
2.1现状
90年代出现了最早的搜索引擎,也就产生了网络爬虫。此时的爬虫在爬取整个网络的时候采取深度或广度优先的遍历方式。作为搜索引擎的信息资源采集的重要角色,网络爬虫的性能将直接影响整个搜索引擎索引网页的数量、质量和更新周期。于是出现后面的分布式网络爬虫。分布式网络爬虫可以看做是由多个集中式网络爬虫组合而成,分布式系统中的每个节点都可以看作一个集中式网络爬虫。分布式网络爬虫大大提高了爬取效率,目前分布式网络爬虫已近有了不少的应用,例如现在著名的Google和Alta Vista搜索引擎所采用的网络爬虫系统。
由于爬虫的重要性,Twisted使用python语言写了一个广受欢迎的爬虫事件驱动网络框架:scrapy,scrapy使用的是非堵塞的异步处理方式。scrapy能够爬取web页面,并从页面中提取结构化的数据。它可以用来数据挖掘、监测、和自动化测试。
scrapy流程图见图1。
2.2 Python
本系统用python脚本语言开发,python脚本语言与其它编程语言相比的优势在于它的语法简单、系统库强大、实现功能容易、高效率的高层数据结构、简单的面向对象编程、代码结构清晰易懂。如今python语言被广泛的应用于系统后台处理和web编程。由于python脚本语言有着这么多的优势,所以通过python脚本语言自己实现了一个爬虫、敏感文件扫描和日志分析程序。爬虫通过任务队列、线程池实现多线程并发爬取网页,在爬取了网页之后对网页进行解码分析,获取目录结构,对已知的目录结构进行敏感文件扫描。同时也通过脚本程序利用攻击规则库对用户请求的web日志进行安全分析,提取出日志中的sql注入攻击,xss跨站脚本攻击,可以利用这些方法发现网站的安全漏洞。
2.3并行爬虫技术
由于WEB网站群结构层次多,目录深度广,数据量很大,单进程的爬虫很难满足快速抓取大量数据的要求,因此本文爬虫进行了并行架构的扩展,实现了基于MPI的并行数据抓取功能。本文并行爬虫主要采用主从模式,主节点负责维护整个爬虫的抓取队列以及任务分配工作,从节点负责对自己的任务列表按照第l章中的抓取规则进行数据抓取。每个从节点都需要维护两个队列,一个是任务队列,另一个是新用户队列。当从节点完成了其任务队列后会将自己的新用户队列交给主节点,由主节点来处理合并用户的工作,同时,主节点会将新的任务队列发送到从节点,由从节点继续抓取新数据。
3系统设计与试验分析
3.1系统功能模块
本系统主要分为三个模块。整个系统功能模块结构见图2。
3.1.1程序主模块和线程池模块
程序主模块的主要功能是web爬取。通过用户提供的初始URL开始爬取。
线程池决定着整个程序的执行效率,创建太多的线程,有些线程又有可能未被充分的利用,程序将会浪费一定的资源。销毁太多线程,将导致之后浪费时间再次创建它们。创建线程太慢,将会导致长时间的等待,性能变差。销毁线程太慢,将导致其它线程资源饥饿。所以在程序的开发中,线程池相当的重要,应做到合理有效的利用。
线程池模块主要是用来创建线程,加载爬虫模块中的爬取url任务到任务队列,每个线程从任务队列中获取任务并执行任务。
3.1.2敏感文件扫描模块
网站中的敏感文件是不应被普通用户查看的,通常这些敏感文件一旦被暴露出来则有可能泄露服务器的一些敏感信息,比如用户名、密码、源代码、服务器信息、配置信息等。还有一些敏感文件则可能是网站的后台管理员管理地址,一些已经公开有漏洞的编辑器。这些都能被攻击者所利用,进而对网站实施攻击,获得网站控制权。
3.2试验分析
用户通过爬虫的入口向程序提供需要爬取的目标,爬取的深度和使用多少个线程爬取,如果没有定义线程数,程序会初始化为9个线程爬取。程序将爬取得到的网页类容进行解码分析,提取出里面的URL,并将这些URL做一些处理后加入队列进行下一步爬取。目标爬取完毕之后会将结果保存下来,然后再调用敏感文件扫描模块对这些目录下进行敏感文件扫描,对于存在的敏感文件会将结果保存下来。
3.2.1目标网页爬取
在目标爬取的测试过程中,程序在获得一个目标站点后开始进行爬取。首先将这个目标url加入urlQueue队列中,在start函数中从urlQueue队列中获取第一个url,随后调用线程中addJob函数将url和工作work函数同时加入线程池任务队列中。此时线程从线程池任务队列中获取任务,也就是获取到的url和work函数,随后线程开始开始执行work函数,work函数中开始对url进行爬取,将url加入已爬取的任务队列readUrls中。爬取方法是调用requests模块中的get函数对目标进行网页抓取:
html=requests.get(url),此方法返回一个html对象。
该对象中的content属性为网页内容:htmldata=html.content。
接下来是对返回的网页内容进行解析分析,本程序采用的是python的第三方模块Beautiful Soup对其解析。Beautiful Soup 是用python 写的一个 HTML/XML 的解析器,它可以很好的处理不规范标记并生成剖析树。通常用来分析爬虫抓取到的web文档。对于不规则的 Html文档,也有很多的补全功能,节省了開发者的时间和精力。通过Beautiful Soup对htmldata解析:
接着遍历allurl列表,如果列表中的链接没有在readUrls中,就将其加入urlQueue队列中。如此循环操作,直到最后达到爬取的深度停止任务,完成网页爬取。
爬取结果如图3。
3.2.2敏感文件扫描
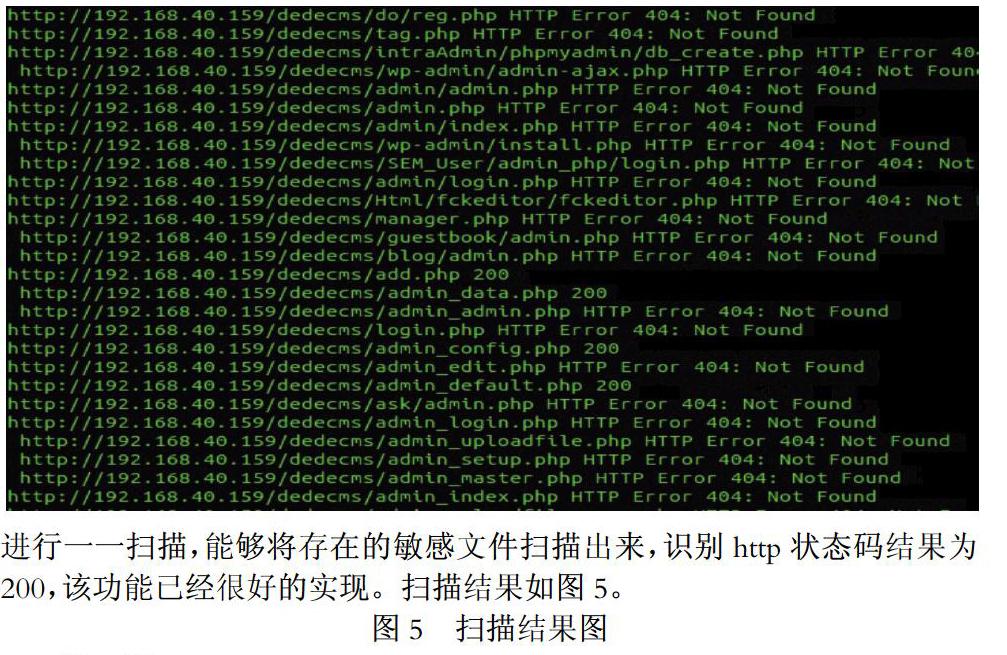
实现方法是通过python中requests类中get函数对url进行请求,通过http请求返回的状态码来识别url是否存在。
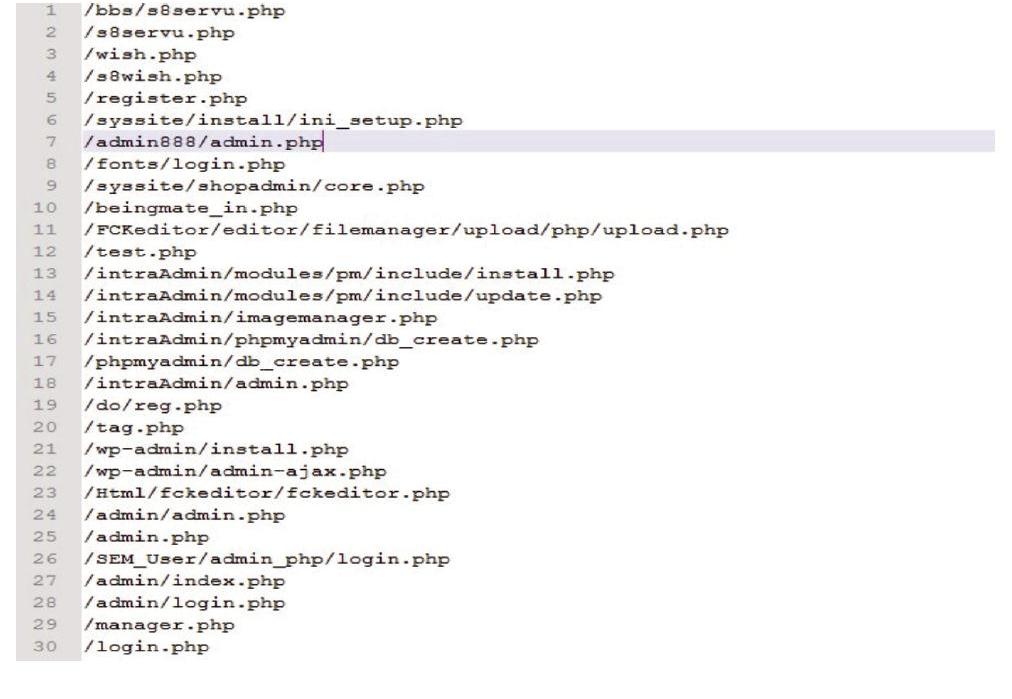
图4是定义好的部分敏感文件信息。
在利用获取到的网站目录结构进行敏感文件扫描,对黑名单中的文件进行一一扫描,能够将存在的敏感文件扫描出来,识别http状态码结果为200,该功能已经很好的实现。扫描结果如图5。
结 语
本文设计的并行网络爬虫通过将网页表单进行分类和检索提交,在这个爬虫的基础上实现一些安全分析的工作,最终可以发现并下载更多的网页内容和检测更多的网站数据漏洞。实验结果表明,和普通的网络爬虫相比,并行爬虫产生的索引文件更大,可以检索到更多的结果。其主要有以下几个特点:
1)使用方便。使用者只需提供相似关键字,就能利用一般爬虫抓取网站中的相关数据。
2)支持关键字匹配。使用者只需自定义感兴趣的关键字爬虫就能自动匹配相关内容并将符合条件的网站内容和目录保存到磁盘之上。
3)支持并行爬虫。对于需要集群式的网站数据,同时又需要快速获取数据的用户而言使用其并行功能,可以达到令人满意的效果。
然而,由于并行爬虫需要提取网页中的表单并进行分类、提交以及页面缓存和状态保持,这些都需要更多的时间和系统资源。因此,如何尽量减少额外的系统资源消耗以适合大规模爬行需要进行进一步的研究。另外,虽然并行爬虫发现了更多的网页,但是它并没有发现所有的深度网页,这是由于其所依据的决策树无法正确地对某些表单进行分类。而决策树的准确性取决于训练实例的特点和决策树生成算法,所以,选择更合理的训练样本和更合适的决策树生成算法应该是可行的。
参考文献:
[1]WELCH M J,SCHONFELD U,HE D,et al.Topical semantics of twitter links【C】//Proceedings of the Fourth ACM International Conference 0n Web Search and Data Mining. New York: ACM Press.2011:327—336.
[2] Sismanis Y,Deligiannakis A.Dwarf K Y.Shrinking the petacube[A].Proc ACM SIGMOD[C],Madison.Wisomin.2002 464—475
[3] ChunWJ, 吉广. Python 核心编程[M].人民邮电出版社, 2008.
[4]Boldi P,Codenotti B.Santini M.UbiCrawler:A Scalable Fully Distributed Web Crawler[J].Software:Practice&Experience。2004,34:711-726
[5]Lee Hsin-Tsang,Leonard D.IRLbot:Scaling to 6 BillionPages and Beyond[A]//Proceedings of the 17th International World Wide Web Conference[C].ACM Press,2008:427—436
[6] 李勇, 韩亮. 主题搜索引擎中网络爬虫的搜索策略研究[J].计算机工程与科学, 2008, 30(3): 4-6.
[7] 张红云, 刘炜, 熊前兴. 一种基于语义本体的网络爬虫模型[J].计算机应用与软件,2009, 26(11): 101-104.
[8] 刘世涛. 简析搜索引擎中网络爬虫的搜索策略[J]. 阜阳师范学院学报: 自然科学版, 2006,23(3):59-62.
猜你喜欢
上海电机学院学报(2022年4期)2022-08-29
网络安全和信息化(2020年6期)2020-06-20
周口师范学院学报(2019年5期)2019-10-16
网络安全和信息化(2018年12期)2018-12-24
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
中国卫生(2015年12期)2015-11-10
警察技术(2015年3期)2015-02-27
