
基于邻域粗糙集与支持向量极端学习机的瓦斯传感器故障诊断*
2016-10-21 11:32单亚峰汤月任仁谢鸿
传感技术学报 2016年9期
单亚峰,汤月,任仁,谢鸿
(辽宁工程技术大学电气与控制工程学院,辽宁葫芦岛125105)
基于邻域粗糙集与支持向量极端学习机的瓦斯传感器故障诊断*
单亚峰*,汤月,任仁,谢鸿
(辽宁工程技术大学电气与控制工程学院,辽宁葫芦岛125105)
针对于瓦斯传感器故障诊断速度慢、诊断精度不高的问题,以常见的冲击型、漂移型、偏置型和周期型传感器输出故障作为研究对象,提出一种基于邻域粗糙集(NRS)和支持向量极端学习机(SVM-ELM)的故障诊断方法。首先对瓦斯传感器的特征属性值进行归一化处理,然后利用NRS信息约简理论降低属性维度,提取出影响瓦斯传感器的关键属性构成约简集。将约简集作为SVM-ELM的输入进行训练,利用训练好的SVM-ELM对测试样本进行模式识别。最后通过实验对比验证该方法具有训练速度快、分类精度高的特点,辨识正确率在95%以上,能够显著提高故障诊断的速度和准确性。
瓦斯传感器;邻域粗糙集(NRS);支持向量极端学习机(SVM-ELM);故障诊断
EEACC:7230doi:10.3969/j.issn.1004-1699.2016.09.018
瓦斯传感器作为煤矿安全监测系统中的关键部件,它肩负着检测矿井瓦斯浓度的重任,它输出的信号正确与否直接关系到整个煤矿瓦斯安全监测系统的安全水平的高低和性能好坏[1],然而煤矿井下高温、高压等恶劣的环境,常常导致瓦斯传感器输出失真,灵敏度下降,准确性、可靠性降低,从而导致误报的情况[2]。作为煤矿安全检测系统中重要部件,瓦斯传感器发生故障后及时准确地对其做出诊断和修复,可以有效地保护人们生命财产的安全,因此,对瓦斯传感器进行故障检测与诊断的研究是具有重要意义的。近年来,众多学者在故障诊断领域做了大量研究,并取得了一定的研究成果,采用的算法无非也是神经网络、支持向量机等,但经实践证明,这些方法存在一定的缺陷,文献[3]将神经网络应用于变压器的故障诊断中,尽管该方法一定程度上提高了诊断的准确性,但在小样本学习训练上具有局限性,而瓦斯传感器故障诊断训练样本有限,无法达到分类精度高的要求。文献[4]将支持向量机应用于滚动轴承的故障诊断中,虽然解决了小样本问题,弥补了神经网络的不足,但其性能对参数选择的依赖性很高,在一定程度上影响了瓦斯传感器故障诊断的速度。Huang等提出的极端学习机算法是近几年应用比较广泛的新型机器学习方法[5],吸引了许多学者的目光,然而传统的极端学习机存在隐含层节点个数选择困难问题,本文有效结合支持向量机中的核函数映射,构建支持向量极端学习机模型算法,克服了传统极端学习机的缺陷[6],为机器学习提供了理论依据。为了提高瓦斯传感器故障诊断的精度和效率,有必要对提取的冗余特征信息进行属性约简。邻域粗糙集数值型属性约简算法[7]能够直接处理数值型属性,快速准确地提取出关键属性,无须对其进行离散化处理,无论在选择特征数量和分类精度方面都有较大的优势。
通过上述分析,本文将邻域粗糙集与支持向量极端学习机有机结合,充分发挥两者的优势,提出一种有效的瓦斯传感器故障诊断方法,通过MATLAB仿真实验对比分析验证该方法具有收敛速度快,分类精度高的优点。
1 邻域粗糙集属性约简算法
1.1邻域粗糙集理论
邻域粗糙集是胡清华[8]等人利用邻域模型对经典粗糙集理论的一种拓展模型,该模型以实数空间中的每一个点形成一个邻域δ,δ邻域族构成了描述空间中任一概念的基本信息粒子。经典粗糙集只能处理完备的信息,还要对样本数据进行离散化,这就不可避免地对数据的准确性造成一定的信息影响,计算结果往往取决于离散化的效果。而邻域粗糙集的最大优点在于,可以直接处理数值型属性,不需要进行离散化,这样就使得邻域粗糙集在属性约简和分类器的构造上都有更大的优势。
1.2前向贪心数值属性约简

邻域粗糙集中前向搜索算法可以保证重要的属性优先被加入到约简的行列汇总,不损失重要的特征,而后向搜索就很难保证这样的结果,因此就会使一些冗余特征的决策系统的一些重要属性被删除,从而致使系统的区分能力降低,因此文中选取前向贪心数值属性约简算法。属性的重要度由属性本身、属性相对属性子集、决策变量组成的函数。此算法是根据属性的重要度指标来构造贪心式属性约简算法,简单地说就是以空集为起点,计算全部剩余知识属性的属性重要度,取最大重要度数值的属性加入到约简集合中,直到剩余属性的重要度全部为0时就不再加入新的属性,即系统的依赖型函数不再发生任何变化。基于邻域粗糙集模型的数值属性约简算法如下:

在瓦斯浓度检测过程中,瓦斯传感器的输出由风速、风量、温度、CO2及其临近测点的瓦斯浓度值共同决定[9],这些数据有着不同的工程单位,各变量的大小在数值上差异也很大,直接使用原始测量数据进行计算可能丢失信息和引起数值计算的不稳定,因此要对各参数进行归一化处理。所谓对数据的归一化处理是对数据进行尺度变换和预处理。尺度变换常常将它们变换到[-1,0]或[0,1]的范围,这里数据的归一化采用如下算式[10]:
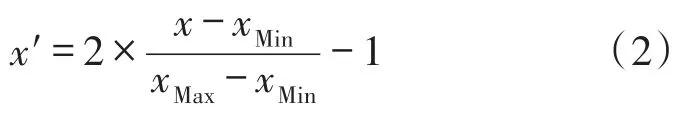
式中,x,x′为归一化前、后数据,xMax、xMax为归一化前数据的最大和最小值。
归一化后的数据可以消除由于不同特征因子的量纲不同和数量级不同所带来的影响。
2 NRS-SVM-ELM故障诊断模型
2.1极端学习机(ELM)理论
ELM是一种新的前馈神经网络模型[11],克服了收敛速度慢,易陷入局部最优等缺陷,其输入权值和隐含层偏置值随机生成且在训练中保持不变,仅需采用线性回归的方法确定输出权值,极大的提高了网络泛化能力和学习速度,其结构如图1所示。
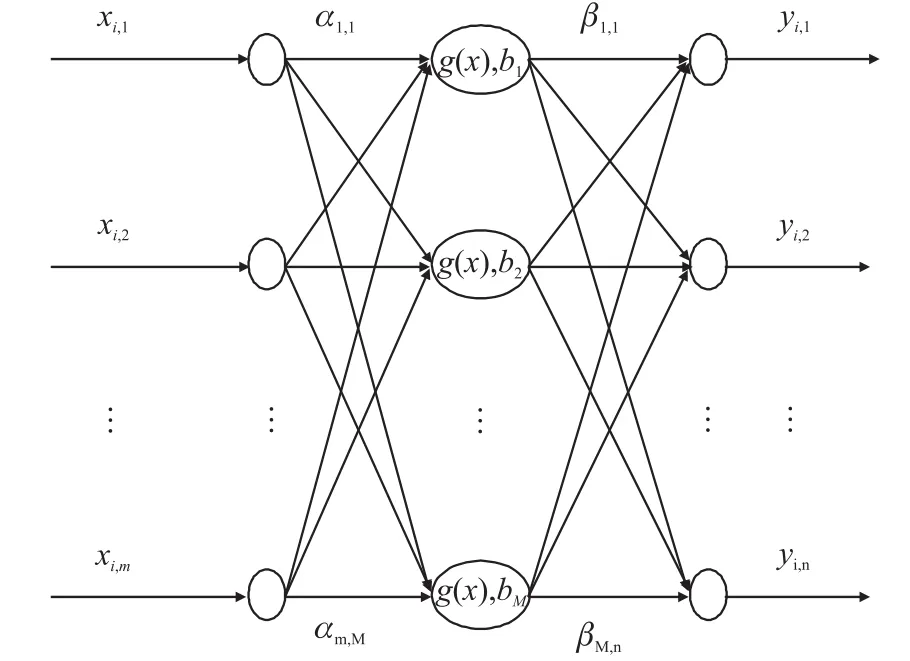
图1 极端学习机结构示意图
ELM数学表达式为:
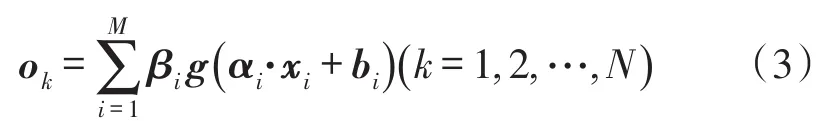
式中:m,M,n分别为网络输入层、隐含层和输出层的节点数;g(x)为激活函数,一般取Sigmoid函数。设由N个不同的样本(xi,yi),(1≤i≤N),其中yi=[yi,1,yi,2,…,yi,n]T∈Rn,ok=[ok,1,ok,2,…,ok,n]T为网络输出,αi=[α1,i,α2,i,…,αm,i]为输入层和第i个隐含层的连接权值,bi为隐含层阈值,βi=[βi,1,βi,2,…,βi,n]T为第i个隐含层和输出层的输出权值。如果一个有M个隐含点的SLFNs能以接近于0的误差来逼近这N个样本,则存在αi,βi,bi有:
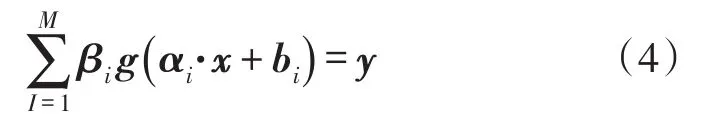
简化为:Hβ=Y式中:H为网络隐含层输出矩阵;β为输出权值矩阵;Y为期望输出矩阵。表示如下:
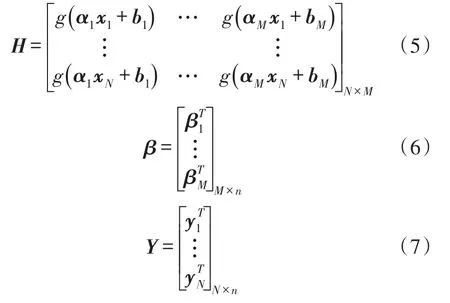
在训练开始时,输入层到隐含层的连接权值α和隐含层阈值b随机生成并保持固定,仅需训练确定输出权值β。通常采用伪逆算法一步计算得

式中:H*是矩阵H的MP广义逆。对ˆ求解后,完成对ELM的网络训练过程。
2.2极端学习机算法改进
影响极端学习机建模性能的一个重要参数即隐含层节点个数,通常需要根据训练任务的不同,采用较为繁琐的交叉验证方法进行选择[12]。Schrauwen和Williams等学者已经证明:具有无穷个隐节点的神经网络与支持向量机方法是等价的,而具有有限隐节点的神经网络可看作是支持向量机方法的低维逼近。为避免极端学习机模型中隐节点选择问题,本文将传统极端学习机的隐含层节点映射h(x)扩展为核方法中的核函数映射φ(x),对支持向量机进行低维逼近,以此构建支持向量极端学习机模型(SVM-ELM)。该模型有效结合了极端学习机训练简便和核方法的泛化性能好的优势,且表现出较传统极端学习机更好的学习能力。
在该极端学习机的特殊实现中,隐含层特征映射h()
x可以是未知的,可对极端学习机定义如下核矩阵:

因此,输出函数为
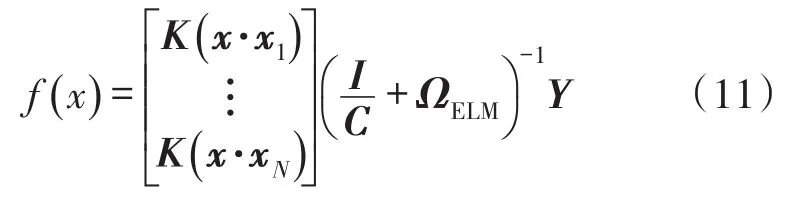
式中C为正则化系数,以平衡模型精度和模型复杂度。
核函数的选择有以下3种:一是利用专家经验选择核函数;二是核函数的选取时,分别适用不同的核函数,比较出误差最小的核函数就是最好的核函数;三是采用由Smits等提出的构造混合核函数方法。根据长久经验及实践证实,径向基核函数是目前应用较广泛的一种核函数,本文选用该函数作为支持向量极端学习机的核函数。
NRS-SVM-ELM模型算法步骤:
步骤1 根据式(2)利用MATLAB软件对各类传感器采集的样本数据进行归一化处理;
步骤2 运用邻域粗糙集方法,按照上述步骤进行属性约简;
步骤3 确定K(u,v),初始化支持向量机极端学习机;
步骤4 给定训练样本集N,激活函数g(x)以及隐含层节点数M,随机生成输入层到隐含层的连接权值α和隐含层阈值b,根据伪逆算法确定输出权值β,进行训练;
步骤5 判断

是否成立,若成立转步骤6,否则转步骤4;
步骤6利用训练好的支持向量极端学习机对测试样本上进行故障识别;
3 实验验证与结果分析
3.1实验配置
实验选取山西某煤矿正常工作面的传感器采集到5类状态下的各60组实测数据,将前40组数据作为训练样本集,后20组数据作为测试样本集。用U={}1,2,…,60来表示60个样本集合,以风速V、温度T、CO2浓度C、上隅角传感器T0、回风巷瓦斯传感器T1、T2、T3、T4和进风巷瓦斯传感器T5作为样本集合U上的特征属性A,A={V,T,C,T0,T1,T2,T3,T4,T5},以识别类型冲击型、漂移型、偏置型、周期性和正常型作为决策属性D,D={di},i=1,2,3,4,5。经查阅文献,通过长久经验将前40组数据进行预处理得到约简后的关键属性集red={V,T,C,T1,T2},将约简集对应的数据作为SVM-ELM的输入进行编码和训练,完成网络训练,然后用另外的20组测试样本进行测试。
另外,将支持向量极端学习机的输出层节点设定为4,这5种状态对应关系如表1。根据约简集red可知输入层节点个数为5,将隐含层节点数设定为6,则该支持向量极端学习机采用5-6-4的结构。

表1 传感器状态与模型输出映射关系
3.2结果分析
取5类状态下的各20组实测数据进行测试,由于篇幅限制只列出部分输出结果,见表2,全部样本诊断识别后的分类情况如图2所示,可以看出每种故障的识别率都在95%以上,符合辨识分类的要求。因此,本文的设计方法可以有效地诊断出瓦斯传感器的故障类型,达到了最初的设计目的。

图2 样本识别的分类结果

表2 实验输出结果
3.3对比实验
为了验证本文提出的NRS和SVM-ELM相结合的故障诊断模型的的优越性,进行了如下对比实验,分别将约简前后的原始数据输入到OS-ELM[13],PCA-PSO-ELM[14]和SVM-ELM模型中,得到故障诊断结果对比见表3。其中极端学习机的输入输出节点个数及参数设置与文中3.1小节保持一致,同样选取40组训练样本,20组测试样本,将训练时间,诊断时间和诊断正确率作为评价标准,进行分析。

表3 不同模型的属性约简前后诊断结果对比表
从表3可以看出,支持向量极端学习模型与传统的极端学习机和经粒子群优化的极端学习机算法相比,尽管在训练时间和诊断时间上并没有太明显的优势,但诊断的准确率明显提高,无论是采用OS-ELM、PCA-PSO-ELM还是SVM-ELM模型,经NRS进行属性约简后,三种模型的精度都有所提高,而且还极大的缩短了训练和诊断时间,诊断速度显著提升。实验数据表明,本文提出的基于NRS与SVM-ELM的故障诊断模型算法要明显优于传统的极端学习机,具有更好的泛化能力,可应用于其他工程领域。
4 结论
本文将邻域粗糙集与支持向量极端学习机相耦合,充分发挥两者的优势,提出一种能够快速、准确识别出故障类型的模型算法。邻域粗糙集属性约简算法相比于其它属性约简算法能够快速提炼出影响故障诊断精度的关键属性,缩减了支持向量极端学习机的输入空间规模,极大地减少了计算量,具有很好的泛化能力。支持向量极端学习机故障诊断模型克服了传统极端学习机隐含层节点选择困难的缺陷,使诊断速度更快,诊断精度更高。NRS与SVM-ELM两种方法的结合不仅能够扩大系统处理信息的广度,同时丰富了系统处理信息的方法,极大地提高了瓦斯传感器故障诊断的准确率,具有一定理论研究价值和工程应用意义。
[1]黄凯峰,刘泽功,王其军,等.基于ASGSO-SVR模型的瓦斯传
单亚峰(1968-),男,副教授,辽宁阜新人,辽宁工程技术大学硕士研究生导师,1991年毕业于哈尔滨建筑工程学院电气自动化专业。多年来一直工作在科研和教学第一线,近年来发表论文10余篇,参编教材2部,主持承担科研课题多项。主要研究方向为检测技术及其应用,shanyf68@163.com;

汤月(1992-),女,辽宁锦州人,硕士研究生,主要研究方向为现代传感技术,764406729@qq.com。
Gas Sensor Fault Diagnosis Based on Neighborhood Rough Set Combined with Support Vector Machine and Extreme Learning Machine*
SHAN Yafeng*,TANG Yue,REN Ren,XIE Hong
(College of Electrical and Control Engineering,Liaoning Technical University,Huludao Liaoning 125105,China)
In order to solve the problem that the gas sensor diagnosis speed is slow and the diagnosis accuracy is not high,this paper takes the common type gas sensor fault such as impact,drift,bias and periodic fault as research ob⁃ject and proposes a pattern classification and identification of the fault diagnosis of gas sensor method based on neighborhood rough set(NRS)combined with support vector machine and extreme learning machine(SVM-ELM).First of all,normalize the feature attribute of the gas sensor,the reduction set is formed via reducing the attribute di⁃mension with NRS information reduction theory,including key attributes of the gas sensor.Train SVM-ELM taking the reduction set for input data and recognize the fault patterns using test samples.Finally,through experiment con⁃trast analysis,this method has the features of fast training speed,high accuracy of classification,and the identifica⁃tion correct rate is more than 95%.It can significantly improve the effectiveness and accuracy of the fault diagnosis.
gas sensor;neighborhood rough set;Support Vector Machine and Extreme Learning Machine(SVMELM);fault diagnosis

TP212;TP181
A
1004-1699(2016)09-1400-05
项目来源:国家自然科学基金项目(51274118);辽宁省科技攻关基金项目(2011229011);辽宁省教育厅基金项目(L2012119)
2016-03-14修改日期:2016-04-16
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06
成都信息工程大学学报(2019年2期)2019-08-28
测控技术(2018年11期)2018-12-07
测控技术(2018年10期)2018-11-25
自动化学报(2018年2期)2018-04-12
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
制造技术与机床(2017年4期)2017-06-22
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
