
基于相似度和信任度的关联规则微博好友推荐
2016-09-29 18:41王涛覃锡忠贾振红牛红梅曹传玲
计算机应用 2016年8期
王涛 覃锡忠 贾振红 牛红梅 曹传玲


摘要:针对关联规则个性化好友推荐中规则挖掘效率及推荐有效性不高的问题,首先提出基于散列及位图的改进关联规则算法BHA。该算法通过引入散列技术,减少了频繁2项集挖掘所需的时间;利用位图及相关性质,压缩无关候选项,减少了数据集所需的遍历次数。另外,在BHA的基础上,提出基于相似度及信任度的推荐算法STA,利用出、入相似度定义信任度,有效解决了新浪微博未提供显示信任关系的问题,同时弥补了相似度推荐未考虑用户间远近层次关系的缺陷。采集新浪微博用户数据进行实验,在关联规则挖掘效率的对比上,BHA挖掘所需的平均时间仅为改进AprioiriTid算法的47%;在好友推荐的有效性上,推荐算法STA较SNFRBOAR算法在准确率及召回率上分别提升了15.2%和9.8%。实验结果表明,STA能够有效降低规则挖掘所需的平均时间,并使实际好友推荐的有效性得到提升。
关键词:好友推荐;关联规则;出相似度;入相似度;信任度
中图分类号:TP181
文献标志码:A
0引言
随着Web 2.0技术的发展,微博已经成为了继博客之后,一种新的交流共享平台。由此,基于微博的线上交友逐渐成为了一种流行的交友方式,用户可以利用它将现实生活中的人际关系搬至网络,也能建立单纯的线上好友关系。然而,随着社交网站用户呈现爆炸式的增长,如何为用户寻找合适的好友成为了基于社交网络的好友推荐需解决的重要问题。
目前,个性化推荐系统中常用的推荐技术主要有基于内容的推荐,协同过滤推荐,及关联规则推荐等[1]。其中基于关联规则的个性化推荐技术[2]具有能够发现用户的新兴趣点、无需领域知识和可实现“跨类型”的推荐等优点,在电子商务等领域得到了广泛应用。本文基于现有推荐技术,对目前关联规则好友推荐算法存在的规则挖掘效率较低及推荐有效性不高的问题展开进一步研究。
1相关工作
针对关联规则个性化推荐的研究主要围绕三个方面进行:1)个性化推荐关联规则算法的研究;2)推荐模型及策略等方面的研究;3)减少挖掘产生的冗余规则研究。其中对于关联规则算法的研究成为了当前研究的重点[3]。如文献[4]通过考虑各项目的重要程度,对关联规则算法进行改进。文献[5]提出了针对新兴趣点发现的协作算法。文献[6]首先利用模糊聚类进行数据预处理,在此基础上再进行频繁项集的挖掘。
根据不同的应用场景,基于关联规则的个性化推荐策略研究同样也是一个重要的研究领域。如文献[7]对面向大规模定制的个性化推荐的相关特性进行分析,提出了面向不同客户群体的关联规则个性化模型。文献[8]以电子商务为应用背景,提出了一套个性化的电子商务推荐系统。
针对基于社交网络的好友推荐,其推荐策略主要围绕两个方面展开:一方面是以用户间的关系作为推荐依据进行好友推荐[9-11];另一方面则是根据用户的社交资料或发布的相关消息,从中提取用户的兴趣倾向,推荐兴趣相似的好友[12-14]。本文以新浪微博好友推荐作为应用背景,首先针对规则挖掘效率较低的不足,通过基于位图的数据格式,引入散列优化技术,并利用相关性质删除无关候选项,对其进行了改进。其次,为提升关联规则好友推荐的准确性,围绕以用户间关系为主的推荐策略进行研究,通过计算用户的出相似度和入相似度,推荐与用户具有共同兴趣且微博社交关系较为相似的好友。在此基础上,结合信任度计算,使好友推荐在推荐结果的有效性方面有更进一步的提升。
2关联规则算法及改进
2.1关联规则算法
Apriori算法是一种逐层搜索的算法,该算法的基本思想是:首先通过预先设定的最小支持度和相关性质找出所有的频繁项集,由得到的频繁项集产生强关联规则。最后由设定的最小置信度,从结果中筛选出可信度较高的,形如:x→y的强关联规则,相关定义如下:
定义1设I={i1,i2,…,in}为项目的集合;D为所有事务的集合;{Tid, T}代表一个事务, T={i1,i2,…,ik}为某事务包含的项目集,每个事务有对应的标识符Tid。其中:TI,DI。
定义2包含k个项目的集合称为k项集,其中支持度计数为包含某k项集Ik的事务数,记为:Sup(Ik)。
定义3给定D和最小支持度min_sup,对IkI,若Sup(Ik) ≥min_sup,则称Ik为频繁k项集。
传统的Apriori算法存在如下不足:
1)在剪枝策略上,需要对数据集进行多次遍历;2)挖掘频繁项集的同时,会产生大量无关候选项占用系统资源等。
针对这些问题,本文提出了基于散列及位图的改进关联规则算法BHA(Bitmap and Hashing Algorithm),主要从降低数据集的遍历次数、压缩无关候选项占用的系统资源两方面进行改进。
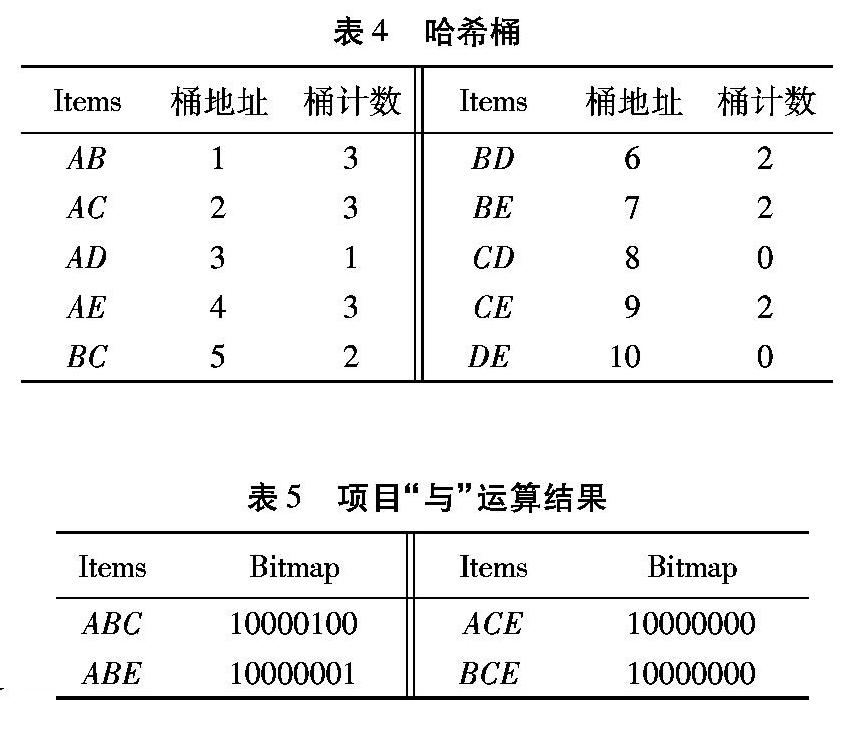
4)利用性质2,由L3={ABC,ABE},k=3可得:L3中包含的项集个数小于3+1,所以L4不存在。
本文提出的BHA利用位图数据间的“与”运算有效减少了对原事务数据库的遍历,提升了算法的计算效率,降低了算法的时间复杂度。对于传统Apriori算法,当事务数据库包含的事务及相应的项目较多时,算法的绝大部分时间消耗在了频繁2项集L2的生成上。通过利用计算散列函数的方法,将每个桶地址计数低于最小支持度的候选项集删除,有效地对候选2项集进行了压缩。在此基础上,由L2生成C3的过程中,利用性质1,删除了候选3项集C3中的无关项{ABD,ACD,ADE,BCD,BDE,CDE},当事务库较大时,可有效减少生成Lk(k>2)时所需的系统资源,降低算法的空间复杂度。
3BHA在微博好友推荐中的应用
基于关联规则的好友推荐,如文献[16],只考虑了用户的关注关系,并未结合微博用户的社交关系进行深入分析。因此,本文以进一步提高好友推荐的有效性为主要目的,基于微博用户的社交关系网络及用户间的连接关系,针对推荐策略展开进一步研究。
3.1相似度
首先由需要进行好友推荐的目标用户U1,U2,U3,U4,建立微博用户社交关系网络G=(U,E,A,F),如图1所示,其中,U为所有目标用户;E为有向边的集合;A为所有目标用户的关注用户集合;F为所有目标用户的跟随用户集合,集合U与集合A、F的关系是:UA,UF。每条边的箭头指向表示用户间的关系是关注还是跟随。
由社交网络的同质性理论[17],即用户双方互相关注是因为他们拥有共同的兴趣爱好。在此基础上考虑用户微博社交关系的相似程度,分别引入出相似度和入相似度概念,相关定义如下:
3.2信任度
由于目前基于信任的推荐方法大都只关注了用户间的显式信任关系,即由用户事先给定的值度量信任关系,忽略了有价值的隐式信任关系[18]。针对新浪微博等社交平台并未提供用户间的显式信任关系,且相似度推荐并未考虑目标用户间远近层次关系对推荐结果的影响,使信任度的引入变得很有必要。本文基于六度分割理论[19],结合信任网络的层次性,在已有出、入相似度定义的背景下,提出了基于相似度的信任度概念,改进了文献[20]中仅考虑用户间的关注相似,但未考虑用户间的跟随相似情况,使得信任度的计算在原有基础上更加精确。
4实验与分析
4.1实验环境及准备
本文实验的硬件环境为:core i5、主频2.6GHz、内存4GB、硬盘500GB,操作系统为Windows 7,实验工具为MySQL、Excel、Eclipse和JDK1.7。为验证算法的有效性,本文基于新浪微博,首先选取同一朋友圈的2位微博用户,将其作为初始目标用户,基于广度优先原则,遍历所有初始目标用户的关注及跟随情况。由于遍历后的数据中会有较多明星、企业等用户出现,为保证实验数据的典型性及实用性,仅考虑数据中跟随情况较为平均的用户,并将这些用户作为目标用户,继续进行遍历,以此类推,重复6次。得到的数据集中共包含6702位目标用户,其中有570351条关注数据和391401条跟随数据,最后将实验采集的数据集进行预处理后分为70%的测试集和30%的训练集。
4.2实验结果分析
由于数据集经过预处理后,关注数据和跟随数据的排列结构相似,因此,在关联规则挖掘效率的对比上,实验设定最小支持度为20,在关注及跟随数据中,分别选取500条数据,共1000条进行第一组实验。数据筛选的原则建立在数据稀疏程度的基础上,并保证每条事务中包含的项目个数大于30。接着,各取1000条数据,共2000条进行第二组实验,以此类推,直至10000条数据。将本文的BHA与文献[16]中的改进AprioriTid算法进行对比,实验结果如图3所示。另外给定7000条数据,在最小支持度min_sup=10,20,30,40,50的条件下进行实验,结果如图4所示。
由图3可知,在给定最小支持度的条件下,BHA算法挖掘所需的平均时间仅为前者的47%,主要原因是改进AprioriTid算法对事务集的重复遍历极大地增加了关联规则算法的时间复杂度,并且没有对产生的无关候选项集进行有效的压缩,使得算法在数据较多的情况下,挖掘所需的时间明显上升。
由图4可知,随着最小支持度的增加,规则挖掘所需的运行时间都在不断减小,当最小支持度大于60时,没有挖掘出符合条件的强关联规则,两种算法的运行时间相似。
在推荐的有效性方面,首先对推荐算法STA的相似度及信任度进行验证,设定最小支持度为10,分别利用STA及SNFBOAR算法[16]进行好友推荐,最后取其TOP-5的推荐结果,具体如表6所示。
由表中数据可以看出,STA推荐结果中排名靠前的用户都距离目标用户较近,主要是从高信任度用户中选出相似度较高的好友。SNFBOAR算法排名前2的用户主要为相似度较高、但距离目标用户的层次较远的用户,由于SNFBOAR算法仅考虑了基于关注相似的相似度,使得推荐出的实际排名较为靠前的用户会在综合推荐度上低于STA所推荐的用户。
其中:n表示微博推荐用户集合(已成为好友的用户集合), r表示算法推荐用户集合。
选取推荐好友个数分别为10、20、30、40、50,对两种算法进行实验,最后得出实验结果如图5和6所示。根据图5、6可以看出,由于本文在相似度基础上考虑了信任度对推荐结果的影响,使得推荐算法能够在好友推荐个数发生变化时稳定保持较高的推荐准确率和召回率,相比SNFRBOAR算法,二者分别平均提升了15.2%和9.8%。
5结语
作为实际生活中朋友关系的补充,在线社交网络消除了现实中存在的距离等阻碍因素,为用户提供了更加方便和新颖的交友方式。本文将关联规则个性化推荐方法运用于微博的好友推荐中,通过对算法效率和推荐策略两方面的改进,使得规则挖掘所需的时间以及推荐的准确率、召回率都有所改善。下一步的工作主要有三点:
1)针对微博用户数据的特点,多角度改进关联规则挖掘算法;
2)基于本文的相关定义,对用户信任度展开深入研究;
3)对挖掘得到的推荐结果按强关系和弱关系用户进行筛选,进一步提升推荐的准确性。
1. 微博用户社交关系网络:G=(U,E,A,F),其中E为有向边集合
2. 用户-关注矩阵:UA 用户-跟随矩阵:UF
3. 用户-关注矩阵的转置:(UA)T用户-跟随矩阵的转置:(UF)T
参考文献:
[1]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15. (LIU J G, ZHOU T, WANG B H. Personalized recommender systems: a survey of the state-of-the-art [J]. Progress in Natural Science, 2009, 19(1): 1-15.)
[2]LIN W, ALVAREZ S A, RUIZ C. Efficient adaptive-support association rule mining for recommendation systems [J]. Data Mining and Knowledge Discovery 2002, 6(1): 83-105.
[3]李杰,徐勇,王云峰,等.面向个性化推荐的强关联规则挖掘[J].系统工程理论与实践,2009,29(8):144-152. (LI J, XU Y,WANG Y F, et al. Strongest association rules mining for personalized recommendation [J]. System Engineering — Theory & Practice, 2009, 29(8): 144-152.)
[4]易芝,汪琳琳,王练.基于关联规则相关性分析的Web个性化推荐研究[J].重庆邮电大学学报(自然科学版),2007,19(2):234-237. (YI Z, WANG L L, WANG L. Research on Web personalized recommendation based on correlation analysis of association rule [J]. Journal of Chongqing University of Posts and Communications (Natural Science),2007, 19(2): 234-237.)
[5]唐灿,唐亮贵,刘波.一个面向新兴趣点发现的模糊兴趣挖掘算法[J].计算机科学,2007,34(6):204-206. (TANG C, TANG L G, LIU B. A fuzzy interest data mining algorithm for new interest oriented [J]. Computer Science, 2007, 34(6): 204-206.)
[6]鲍玉斌,王大玲,于戈.关联规则和聚类分析在个性化推荐中的应用[J].东北大学学报(自然科学版),2003,24(12):1149-1152. (BAO Y B, WANG D L, YU G. Application of association rules and clustering analysis to personalized recommendation [J]. Journal of Northeastern University (Natural Science), 2003, 24(12): 1149-1188.)
[7]LI J, XU Y, WANG Y, et al. Strongest association rules mining for efficient applications [C]// Proceeding of the 2007 Fourth IEEE Conference on Service Systems and Service Management. Piscataway, NJ: 2007: 502-507.
[8]丁振国,陈静.基于关联规则的个性化推荐系统[J].计算机集成制造系统,2003,9(10):891-893. (DING Z G, CHEN J. Individuation recommendation system based on association rule [J]. Computer Integrated Manufacturing Systems, 2003, 9(10): 891-893.)
[9]陈克寒,韩盼盼,吴健.基于用户聚类的异构社交网络推荐算法[J].计算机学报,2013,36(2):349-359. (CHEN K H, HAN P P, WU J. User clustering based social network recommendation [J]. Chinese Journal of Computers, 2013, 36(2): 349-359.)
[10]王玙,高琳.基于社交圈的在线社交网络朋友推荐算法[J].计算机学报,2014,37(4):801-808. (WANG Y, GAO L. Social circle-based algorithm for friend recommendation in online social networks [J]. Chinese Journal of Computers, 2014, 37(4): 801-808.)
[11]王名扬,贾冲冲,杨东辉.基于三度影响力的社交好友推荐机制[J].计算机应用,2015,35(7):1984-1987. (WANG M Y, JIA C C, YANG D H. Social friend recommendation mechanism based on three-degree influence [J]. Journal of Computer Applications, 2015, 35(7): 1984-1987.)
[12]JECKMANS A, TANG Q, HARTEL P. Poster: privacy-preserving profile similarity computation in online social networks [C]// CCS 11: Proceedings of the 18th ACM Conference on Computer and Communications Security. New York: ACM, 2011: 793-796.
[13]PIAO S, WHITTLE J. A feasibility study on extracting twitter users interests using NLP tools for serendipitous connections [C]// Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2011 IEEE Third International Conference on Social Computing (SocialCom). Piscataway, NJ: IEEE, 2011: 910-915.
[14]唐晓波,祝黎,谢力.基于主题的微博二级好友推荐模型研究[J].图书情报工作,2014,58(9):105-113. (TANG X B, ZHU L, XIE L. Two-level microblog friend recommendation based on topic model [J]. Library and Information Service, 2014, 58(9): 105-113.)
[15]PARK J S, CHEN M-S, YU P S. Using a hash-based method with transaction trimming for mining association rules [J]. IEEE Transactions on Knowledge and Data Engineering, 1997, 9(5): 813-825.
[16]向程冠,熊世恒,王东.基于关联规则的社交网络好友推荐算法[J].中国科技论文,2014,9(1):87-91.(XIANG C G, XIONG S H, WANG D. Social network friends recommendation algorithm based on association rules [J]. China Sciencepaper, 2014, 9(1): 87-91.)
[17]张中峰,李秋丹.社交网站中潜在好友推荐模型研究[J].情报学报,2011,30(12):1319-1325. (ZHANG Z F, LI Q D. Latent friend recommendation in social network services[J]. Journal of the China Society for Scientific and Technical Information, 2011, 30(12): 1319-1325.)
[18]XING X, ZHANG W, JIA Z, et al. Trust-based top-k item recommendation in social networks [J]. Journal of Information and Computational Science, 2013, 10(12): 3685-3696.
http://www.joics.com/publishedpapers/2013_10_12_3685_3696.pdf
[19]KE X. A social networking services system based on the “six degrees of separation” theory and damping factors [C]// ICFN 2010: Proceedings of the 2010 2nd International Conference on Future Networks. Washington, DC: IEEE Computer Society, 2010: 438-441.
[20]XING X, ZHANG W, JIA Z, et al. Trust-based social item recommendation: a case study [C]// Proceedings of the 2012 2nd International Conference on Computer Science and Network Technology. Piscataway, NJ: IEEE, 2012: 1050-1053.
猜你喜欢
环球时报(2020-08-14)2020-08-14
新传奇(2018年8期)2018-05-14
环球时报(2018-01-23)2018-01-23
电子技术与软件工程(2016年22期)2016-12-26
移动通信(2016年20期)2016-12-10
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
IT经理世界(2014年5期)2014-03-19
