
基于长短期记忆多维主题情感倾向性分析模型
2016-09-29 18:41滕飞郑超美李文
计算机应用 2016年8期
滕飞 郑超美 李文


摘要:针对中文微博全局性情感倾向分类的准确性不高的问题,提出基于长短期记忆模型的多维主题模型(MT-LSTM)。该模型是一个多层多维序列计算模型,由多维长短期记忆(LSTM)细胞网络组成,适用于处理向量、数组以及更高维度的数据。该模型首先将微博语句分为多个层次进行分析,纵向以三维长短期记忆模型(3D-LSTM)处理词语及义群的情感倾向,横向以多维长短期记忆模型(MD-LSTM)多次处理整条微博的情感倾向;然后根据主题标签的高斯分布判断情感倾向;最后将几次判断结果进行加权得到最终的分类结果。实验结果表明,该算法平均查准率达91%,最高可达96.5%;中性微博查全率高达50%以上。与递归神经网络(RNN)模型相比,该算法F-测量值提升40%以上;与无主题划分的方法相比,细致的主题划分可将F-测量值提升11.9%。所提算法具有较好的综合性能,能够有效提升中文微博情感倾向分析的准确性,同时减少训练数据量,降低匹配计算的复杂度。
关键词:中文微博;情感倾向分析;长短期记忆;多层多维模型;主题标签
中图分类号:TP181
文献标志码:A
0引言
随着网络新媒体的飞速发展,大量用户已习惯于通过微博表达自己真实的想法和理念,从而产生了庞大的数据量和很多创造性的自由、随性的表达方式。这些新鲜的方式不仅表达了微博作者的态度和想法,还带有极高的商业、社会价值。为此,分析这些大量且复杂的微博信息中的情感已成为当下研究热点之一。
与传统文本的情感分析不同,微博有其独特的情感特征,其不仅需要明白表面意思,更需要分析字里行间的内在含义。这就需要从不同方面对微博信息的特征进行分析,否则很难准确判断它的情感倾向,更难以得出准确结果。其次,微博具有篇章短小精悍、语言结构口语化、存在表情符号和创造性语言的特征,增加了语言处理和分析的难度。
目前,循环神经网络(Recurrent Neural Network, RNN)模型正应用于各种机器学习所涉及的任务中,尤其适用于输入输出序列长度可变的环境中进行分类和生成任务;然而在实际应用中,由于长期目标依赖性导致训练难度极大。Socher等[1]使用张量形式的递归神经网络(Recursive Neural Network, RsNN)侧重于对整个句子的理解,但中文尤其是微博很少有完整的句子和完善的句法结构。Koutnik等[2]将循环神经网络的隐藏单元划分为组,采用不同频率时钟的发条循环神经网络(Clockwork Recurrent Neural Network, CW-RNN)模型跨时空链接信息;但不适用于正则文法表达,缺乏上下文的内在关联,使整条微博的识别性降低。近来相对有效的方法之一,是增加特殊控制单元来限制内存访问,即使用长短期记忆模型(Long Short-Term Memory, LSTM)来获得更持久的记忆,以及更轻松地捕获长期依赖项,减缓信息衰减的速率,增加深度计算的优势。Stollenga等[3]则是从线的角度出发进行扫描,代替了原先的点辐射的思想,提出金字塔型长短期记忆模型(Pyramidal Multi-Dimensional LSTM, PMD-LSTM);但其打破了上下文的关联,且复杂度较高,影响分类效果。Li等[4]在RNN的基础上增加了自动编码模型形成了一种按等级划分的自动编码模型HNA(Hierarchical Neural Autoencoder),是一种多维的LSTM模型;但其效率不高,每句话都要反复地进行编码和解码的工作。
针对以上问题,笔者根据中文微博的特性,提出了基于LSTM的多维主题模型(Multidimensional Topic LSTM, MT-LSTM),以提高微博情感倾向预测的准确率。它不依赖于句子的标签和形式,通过分层的方式增强词与词之间的联系,以及义群与义群、句与句之间的联系。最后,通过主题分类判断情感倾向,再将每一层结果进行加权求和得到最终的情感倾向。由此,增强了句子的特征,解决了因时间迁移导致数据模糊而无法计算的问题,降低了因长期记忆影响导致遗忘速率过快而对结果产生的不利影响,增强了分类的准确性,且更适用于口语化的中文微博。
隐藏序列和记忆序列的计算与传统RNN不同,通过Python予以实现[5]。本文通过输入序列得到标准RNN计算出的隐藏序列和记忆序列。由于目标类会与逻辑序列产生联系,所以这种表示不会产生逻辑衰退。实验表明,通过这种组合方式进行情感分析得到的结果准确率更高。
1相关工作
上述控制门和记忆细胞允许LSTM单元自适应地忘记、记忆和展示记忆内容。遗忘门的开闭可以同时发生在不同的LSTM单元。基于RNN的多重LSTM单元可以同时捕捉在网络中快速和缓慢移动的数据。
2构建模型
2.1模型架构
与英文相比,中文的语法不够严谨,而微博语言的随意性更强,使得依据细致的语法分析进行句子的倾向性分析比较困难。为此,考虑放弃复杂的语法分析,而对句子的内部构造进行整合。目前的研究多是将整条微博当成一个句子进行处理,或仅处理微博中的一句话。为此,可以将整条微博视作一个整体,探讨其内在的逻辑和最终的情感倾向;再加上对微博主题倾向的逻辑划分,形成细粒度的微博情感模型。以一条微博为例,其情感分析的框架结构如图1所示。
其中最底层的句子为预处理后的结果。由于计算时间会随着维度的增加呈指数级上升,为避免形成维数灾难,本文模型纵向传播采用三维长短期记忆模型(Three-Dimensional Long Short-Term Memory, 3D-LSTM),横向传播采用多维长短期记忆模型(Multi-Dimensional Long Short-Term Memory, MD-LSTM)。
图1给出了处理某一条微博的详细过程,其详细内容如下:
1)对语料库进行预处理,去掉无关部分。依照ICTCLAS分词系统将句子进行词语划分,并保留标点以及各种符号和符号集(多个符号组成的表情符号)。
2)通过谷歌的word2vec工具进行词语向量化表示,并将向量化的词语调整格式进行输入。
3)随时间推移,每条微博的处理方式:
a)向上传播:使用3D-LSTM模型,在不同句子粒度上进行分析;
b)向右传播:使用MD-LSTM模型,在不同句子层次上进行分析。
4)当分析完一整条微博后,根据原本的微博主题或人工分类的主题进行主题匹配,并根据高斯分布确定情感倾向。
5)对输出的所有情感倾向进行加权运算,得到最终的情感倾向。
2.2三维长短期记忆模型
LSTM虽然通过增加部分长期记忆元素可以解决RNN中重要的序列依赖问题,但在解决实际问题时,无论短期还是长期的记忆和遗忘都应该得到相同的重视,解决该问题的有效思路之一是缩短句子长度。为此,考虑将长句子拆分成短句,同时还可以减少反复记忆和遗忘的时间,提高处理速度。基于上述思路,考虑将微博语言数据扩展为3维进行处理,更加有效地利用图形处理器(Graphics Processing Unit, GPU)的处理功能。
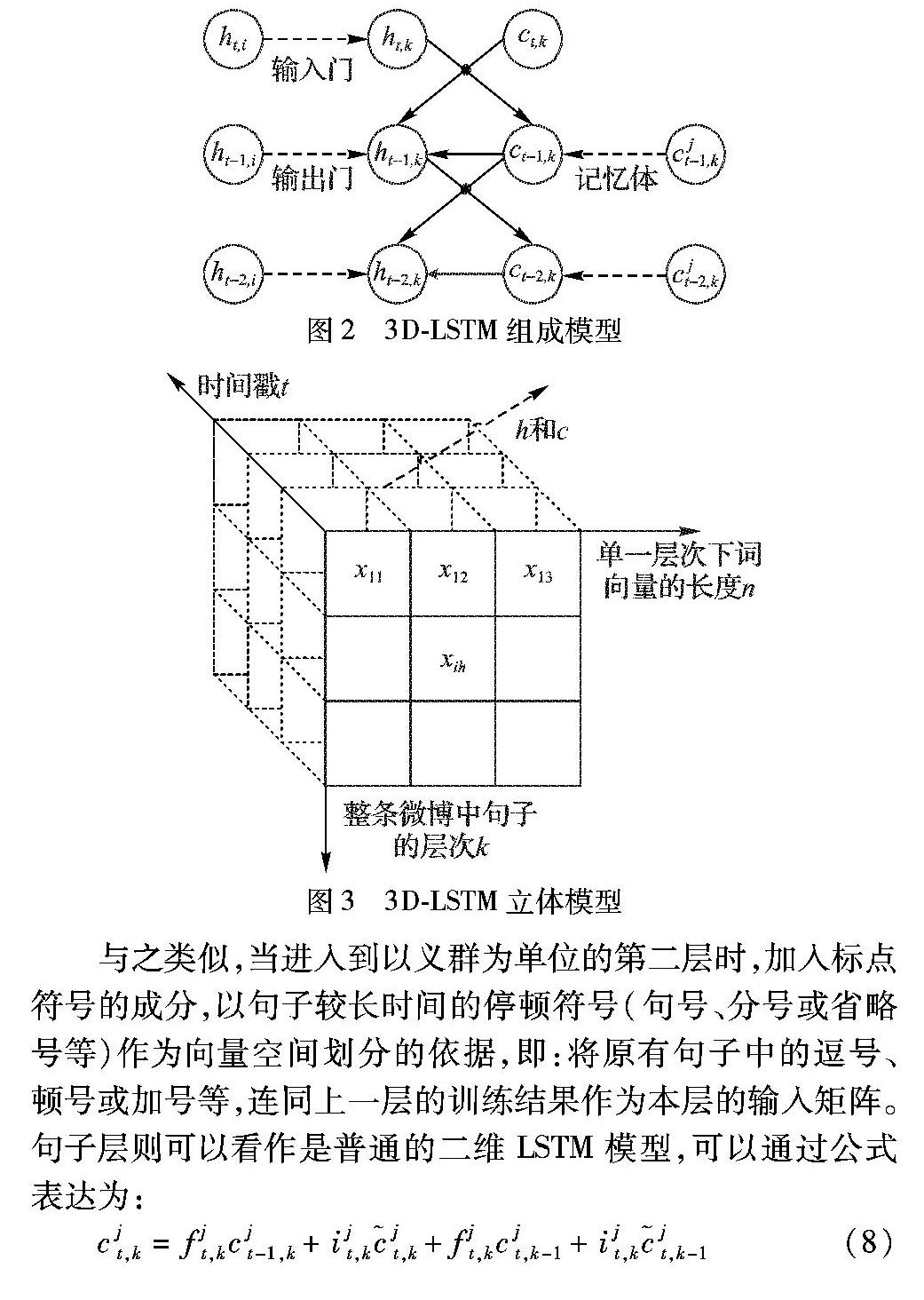
MT-LSTM中涉及的隐藏层和记忆单元可抽象表示为图2和图3。图2中不包括遗忘门的输入输出,仅为一层中的一次输入及其输出;图3为立体结构的整体模型示意图。以图3所使用的框架模型的第一层为例,将得到的词向量按照句子的标点将其划分成多个分句,以每个分句的长度作为向量空间的划分依据。第一层不考虑标点符号,只以分句为单位进行输出,则每一个分句都可以根据这种标准构成一个二维向量矩阵;再加上LSTM中的时间坐标,构成3维的长短期记忆模型。
与之类似,当进入到以义群为单位的第二层时,加入标点符号的成分,以句子较长时间的停顿符号(句号、分号或省略号等)作为向量空间划分的依据,即:将原有句子中的逗号、顿号或加号等,连同上一层的训练结果作为本层的输入矩阵。句子层则可以看作是普通的二维LSTM模型,可以通过公式表达为:
2.3多维长短期记忆模型
多维长短期记忆模型(MD-LSTM)不需要对整篇微博进行细致的划分。它是一个相对独立的模型,可以将总体模型中的某一层作为输入,直接得到该层对应的情感倾向。
MD-LSTM与3D-LSTM的区别是,MD-LSTM将一整条微博视为一个整体,更侧重对全局的考虑,故这里的多维度仅针对隐藏层进行设置。根据前面的经验公式,可以知道记忆单元的维度也会随着隐藏层维度的增加而增长,也就意味着记忆周期更长。为抵消短周期记忆的缺失,定义每个义群或句子中的标准输入为:
同样,以图3中第一次使用MD-LSTM模型的层为例。其中:xj为某一义群中的第j个词向量,n为该义群中全部向量的长度。中间第二次使用MD-LSTM模型时,xj为某一句子中得第j个义群。最后一次由于不存在群体概念,xj为其本身,此时MD-LSTM模型即为标准LSTM模型。
由式(14)可见,输入队列中每个词或义群与其周围词或义群相互之间的关系更加紧密,可以减轻MD-LSTM短期记忆的负担。
3实例分析
3.1实验数据
实验数据来自新浪网提供的应用程序编程接口(Application Programming Interface, API),根据主题获取微博,共随机获取到20个不同主题的微博,其中正向主题10个(如:“刚出生的双胞胎手牵手”),负向主题10个(如“每天一剂负能量”)。去除转发和无文字内容的微博,每类主题约有3000条微博进入预处理。同时由10人进行人工分类,每条微博的情感倾向均由3人评价打分的结果确定。最终得到的情感分类结果如表1所示,该结果作为实验中MT-LSTM与比较模型训练及检验的标准。
3.2预处理
由于微博更倾向于口语表达,存在较多噪声,因而需要预处理,其主要工作是对微博信息进行清洗,为此参考文献[9] 并根据最新微博版本进行调整,去掉微博中不存在情感的噪声数据,包括:话题、标题、回复、统一资源定位器(Uniform Resoure Locator, URL)、来源等。
此外,还需将表情符号改为文字,以便后续处理。其中,表情符号为微博官方表情符号库,转为文字形式时使用符号库中表情对应文字;不存在于官方表情库中的表情,如:“
_(:з」∠)_”,则以原格式保留,作为标点符号处理。
3.3使用词向量表示词语
使用词向量可以使模型变得更加客观,目标词向量不依赖RNN的权重。Turney等[10]使用词向量作为特征进行有监督的训练和测试,但词袋(bag-of-words)模型[11]已经不能准确地捕获词语的含义。为获取情感倾向性分析的基本依据,国内往往将整条微博进行拆分,仅保留已知的情感词作为整条微博情感倾向判断的依据。实际上,中文表达十分丰富,很多名词或网络用语也存在主观情感,如用“小凯”或“凯凯”作为对凯迪拉克轿车的称呼,表现了使用者喜爱的情绪,也是积极情感倾向的一种。
笔者使用中国科学院计算技术研究所开发的ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)分词系统[12]对已经预处理的文档进行分词;使用谷歌的word2vec工具[13]对完成分词的文档进行词向量转换工作;使用词向量表示词语。由此,摆脱了传统方法的束缚,更适用于微博这种灵活的语言形式,可以更全面地反映句子中存在的情感倾向。
3.4微博主题分类
在微博使用过程中,用户可以根据提示添加已有主题或自己添加主题。实验发现,一般情况下,同一微博话题下的情感倾向呈高斯分布。大多数带有主题的微博,其情感一般都趋近于相关主题,当主题情感为正向时,极少出现负向情感,反之亦然。
此外,虽然存在情感倾向的微博数量比例较高,而仅仅表达中性或无明确意义的微博相对存在数量较少,但在大数据的分析中也不能忽视。笔者采集多类不同主题的语料进行分析,发现详细的主题划分有助于微博情感倾向的判断。
为验证主题分类的有效性,使用不同方法将主题分为不同数量的类别,如表2所示。
由此可以方便地计算反向传播[14],并使用梯度下降训练网络。
根据文献[4]设置训练中用到的参数,具体细节如下:
1)统一初始化3D-LSTM和MD-LSTM中的参数,参数值设置区间为[-0.08, 0.08];
2)随机梯度下降使用固定学习速率0.1,训练了接近7个周期;
3)最低批处理文件数为20;
4)漏码率为0.2;
5)当梯度规模超过临界值5,进行梯度裁剪;
6)模型框架中每层的权重为[0.3, 0.4, 0.3]。
模型训练过程中使用单独GPU(Tesla K40m, 1 Kepler GK110B),处理速度约为每秒600~1200条微博。
3.6结果分析
为保证分析的客观性,选取目前公认较先进的四种模型与MT-LSTM进行比对,分析比对的主要性能评估指标为查准率和查全率。查准率定义为正确判别为该类的测试样本占判别为该类测试样本的比例,而查全率定义为正确判别为该类的测试样本占该类总测试样本的比例[15]。然而,这两个指标往往相互矛盾,为此一般采用F-测量值作为综合评估标准,其定义如下:
由表3数据可以看出,MT-LSTM可以较准确地查出微博的情感倾向,同时可准确全面识别50%以上的中性微博。
观察表4可以发现:通过第3层判断,即增加主题分类,可以有效提高微博情感倾向的准确率;适当增加第2层的权重,可以提升模型整体的查全率,对提升总体的F-测量值起到至关重要的作用。
实验中,分别采用10%和1%的训练数据占比(从实验数据中随机取样的训练数据比例)进行训练,并采用10折交叉验证技术,得到的F-测量值的结果如图4所示。
由图4可见,与四种先进模型相比,当训练数据占比为10%时,通过MT-LSTM进行情感分析得到的F-测量值与表现最好的HNA不相上下;当占比减少到1%时,MT-LSTM的F-测量则比其他模型至少提高了40.2%。值得注意的是,占比越小,意味着所需要的训练数据越少,还可以有效降低计算复杂度。当训练数据减少时,其他模型的F-测量值都相对较低且结果大致相同,应该是因为它们仅仅纵向使用模型,而未考虑到层次间的联系。
由图5可知,主题的细致划分有助于提高分类的准确性。当主题数量达到20时,与无主题分类(即主题数量为1时)相比,F-测量值提高了11.9%。
上述分析表明,MT-LSTM可以较准确地划定情感倾向,同时对中性微博有较强的分辨能力;而且当训练集数据较少时,结果依然令人满意;同时主题数量对F-测量值有较大影响。因此,与目前的几种先进模型相比,在对中文微博的情感倾向性进行分析时,MT-LSTM具有更好的综合性能。
4结语
本文在传统LSTM模型基础上提出了一个多层多维主题情感分析模型。与原序列模型相比,MT-LSTM模型对每条微博进行逐层分析,在增加词与词相关性的基础上,增加了义群与句子和句子与句子的逻辑结构;其次,在保留了句子的一致性和完整性的同时,增加了对主题的考虑,可以更真实地反映用户对热点事件的态度;第三,可以自动学习中文口语表述,在多个层次上对整条中文微博的情感倾向进行判断,提高了中文微博情感分类的准确性。值得指出的是,此模型还可以应用到更广泛的领域,如翻译和文字识别等。
虽然MT-LSTM模型可以根据上下文较准确地推断微博的情感倾向,但网络词语和较少出现的古代文体对准确率造成一定影响。在今后的工作中,希望构建一个不需要分词的神经网络模型,处理上下文关联较弱的文本内容。
参考文献:
[1]SOCHER R, PERELYGIN A, WU J Y, et al. Recursive deep models for semantic compositionality over a sentiment treebank [C]// EMNLP 2013: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013: 1631-1642.
[2]KOUTNIK J, GREFF K, GOMEZ F, et al. A clockwork RNN [C]// ICML 2014: Proceedings of the 31st International Conference on Machine Learning. [S.l.]: International Machine Learning Society, 2014: 1863-1871.
[3]STOLLENGA M F, BYEON W, LIWICKI M, et al. Parallel multi-dimensional LSTM, with application to fast biomedical volumetric image segmentation [C]// NIPS 2015: Proceedings of the Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015.
http://mrbrains13.isi.uu.nl/pdf/IDSIA.pdf
http://machinelearning.wustl.edu/mlpapers/paper_files/NIPS2015_5642.pdf
[4]LI J, LUONG M T, JURAFSKY D. A hierarchical neural autoencoder for paragraphs and documents [EB/OL]. [2015-11-09]. http://arxiv.org/pdf/1506.01057v2.pdf.
[5]SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// NIPS 2014: Proceedings of the Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 3104-3112.
[6]GRAVES A. Generating sequences with recurrent neural networks [EB/OL]. [2015-08-24]. http://arxiv.org/pdf/1308.0850v5.pdf.
[7]HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780.
[8]ZAREMBA W, SUTSKEVER I, VINYALS O. Recurrent neural network regularization [EB/OL]. [2015-08-24]. http://arxiv.org/pdf/1409.2329v5.pdf.
[9]袁丁,周延泉,鲁鹏,等.多方法融合的微博情感分析[C]//第六届中文倾向性分析评测报告.昆明:中国中文信息学会信息检索专业委员会,2014:35-39. (YUAN D, ZHOU Y Q, LU P, et al. Sentiment analysis of microblog combining multi-methods [C]// Proceedings of the sixth Chinese Orientation Analysis Evaluation Report. Kunming: China Computer Federation and Chinese Information Processing Society of China, 2014:35-39.)
[10]TURNEY P D, PANTEL P. From frequency to meaning: Vector space models of semantics [J]. Journal of Artificial Intelligence Research, 2010, 37(1): 141-188.
[11]PANG B, LEE L, VAITHYANATHAN S. Thumbs up?: sentiment classification using machine learning techniques [C]// EMNLP 02: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2002: 79-86.
[12]张华平.NLPIR汉语分词系统[CP/OL]. [2014-12-11]. http://ictclas.nlpir.org/. (ZHANG H P. Chinese lexical analysis system [CP/OL]. [2014-12-11]. http://ictclas.nlpir.org/.)
[13]Google. word2vec [CP/OL]. [2015-03-25]. http://word2vec.googlecode.com/svn/trunk/.
[14]WILLIAMS R J, ZIPSER D. Gradient-based learning algorithms for recurrent networks and their computational complexity [M]// Backpropagation: Theory, Architectures and Applications. Hillsdale, NJ: L. Erlbaum Associates Inc., 1995: 433-486.
[15]张启蕊,董守斌,张凌.文本分类的性能评估指标[J].广西师范大学学报(自然科学版),2007,25(2):119-122. (ZHANG Q R, DONG S B, ZHANG L. Performance evaluation in text classification [J]. Journal of Guangxi Normal University (Natural Science Edition), 2007, 25(2): 119-122.)
