
基于改进正则表达式规则分组的内网行为审计方案
2016-09-29 18:41俞艺涵付钰吴晓平
计算机应用 2016年8期
俞艺涵 付钰 吴晓平


摘要:针对网络安全审计中对应用层协议审计能力不足的问题,提出一种基于改进正则表达式(RE)规则分组的内网行为审计方案。首先,通过正则表达式对需审计的协议进行描述,并设置相关参数,使内网中出现频率高和审计中相对重要的协议状态在正则表达式描述集中取得高优先级;然后,在正则表达式交互值小的前提下,尽可能地将高优先级协议状态表达式构建到相同自动机分组中以生成审计引擎;最后,根据审计需求,改变相关参数,实现对内网行为的安全审计。实验结果显示,所提出的自动机构建算法在转化时的状态数缩减为经典非确定有限状态自动机(NFA)转化算法Thompson的10%~20%,检测时的吞吐量约为传统自动机分组引擎的8到12倍;所提审计方案能够满足对应用层协议进行安全审计的需求,具有较高的准确性和效率。
关键词:正则表达式;协议状态;安全审计;自动机分组;需求选择
中图分类号:TP309.7
文献标志码:A
0引言
随着网络时代的到来,信息化进程不断加速,计算机网络规模越来越大,网络信息安全也越来越受到人们的关注。相对于外部网络而言,计算机内部网络具有更强的私密性和可操作性,许多政府部门、大型公司等机构都建有自己的内部网络。在内部网络中,用户可以根据自身需求制定相关的规则来达到内网信息一定的需求,如军用内网中,用户通过加密技术来保证内部通信的私密性。同时,由于内部网络中所包含的信息往往存在巨大的价值(如商业机密),内部网络受到了越来越多的安全威胁。
在大规模网络环境下,攻击者的攻击手段日趋复杂,多种网络攻击行为在宽时间域上交互实施,单一的入侵检测技术已不能满足防护需求。特别是近年来,具有应用技术手段高超、潜伏时间长、目的明确等特点的高级持续性威胁(Advanced Persistent Threat, APT)[1]的活动越来越频繁,其针对内网的攻击往往运用多种攻击方式在多个层面上进行,且不仅单一通过网络攻击技术对内网实施入侵,还往往运用社会工程学等知识来实施攻击[2-4]。所以,内网的网络安全防护措施在应对传统网络攻击技术的同时,还需要对内部人员和内部操作行为进行审计。
针对网络安全审计技术的研究国内外起步都比较晚,且由于网络应用发展的日新月异,当前并不存在一套通用的网络安全审计系统,现有的网络安全审计产品往往是为满足某个特定的安全审计需求而设计的。分析研究国外的网络安全审计系统(如NitroViewLogCaster)以及国内的网络安全审计系统(如TOPSECAuditor)可以发现,现有的网络安全审计产品对于网络应用层协议的审计能力有限,大大影响了其审计效果。
文献[5]提出了一种通过采集内网监控日志信息、受控终端日志信息和受控终端配置及操作信息,进行关键词匹配建立索引信息来进行安全审计的方案。该方案充分利用了内网采集日志信息的便利性,对相关数据进行了收集与分析,通过对比验证来对内网网络进行审计。该方案的优点在于其数据源合理,能够充分反映出内网网络状态,但其数据的采集与处理过程过于复杂,效率不高。
文献[6]提出了一种基于改进信息熵的攻击检测算法,并由此设计了一种多Agent网络安全审计模型。该模型有效地提高了网络安全审计的效率与日志分析的智能性,但是其数据来源为简单的网络数据流,并不能摆脱数据流统计特性所带来的局限性。
文献[7]提出了一种基于人工神经网络和规则匹配相结合的安全审计方案,其将系统部署在网络的进出口,旨在通过对网络进出口处的数据交换模式进行审计,实现了对网络入侵的准确检测。然而,其审计的重点只停留在了数据流表层,并没有对数据流的深层内涵进行审计,存在一定的安全隐患。
为了解决目前网络安全审计中存在对网络应用层协议审计能力有限的问题,本文提出了一种基于改进正则表达式(Regular Expression,RE)规则分组的内网行为审计方案,其主要特点在于:采用了将应用层协议行为与正则表达式自动机构建分组结合的思想,提出了一种基于协议行为加权分组(Weighted Grouping of Protocol Behavior,WGPB)的自动机构建方法,将网络中出现频率高和相对重要的应用层协议行为构建到相同的自动机中,并赋予其高的优先级,合理地将技术描述与应用层协议的实际情况结合起来,在技术层面缓解了自动机存储空间膨胀问题的同时更具有可靠性;提出了一种基于需求选择(Demand Choice,DC)的安全审计策略,将审计对象的重要程度与审计策略结合起来,提供了一种可选择的安全审计方式,在审计策略层面提高了审计效率。
1相关知识
正则表达式是使用单个字符串来描述、匹配一系列符号某个句法规则的字符串,具有很强的描述能力。对正则表达式的匹配需要使用有穷自动机来完成,有穷自动机分为非确定有限状态自动机(Nondeterministic Finite Automaton, NFA)和确定有限状态自动机(Deterministic Finite Automaton, DFA),NFA和 DFA在实际应用中有不同的优点和缺点[8-9]。
NFA的优点是其状态转移空间复杂度比较低,因为NFA的状态数目与正则表达式的长度成线性关系。然而在处理每一个字符时,由于必须逐个处理活动状态集合中的多个状态,因此匹配效率非常低;若将多条规则编译到同一个NFA中,虽然可以在处理过程中同时匹配所有正则表达式的公共前缀,但在实际应用中却会形成更大数量的活动状态集合,处理一个字符的时间复杂度和将每个正则表达式编译成单独一个NFA的时间复杂度相同。
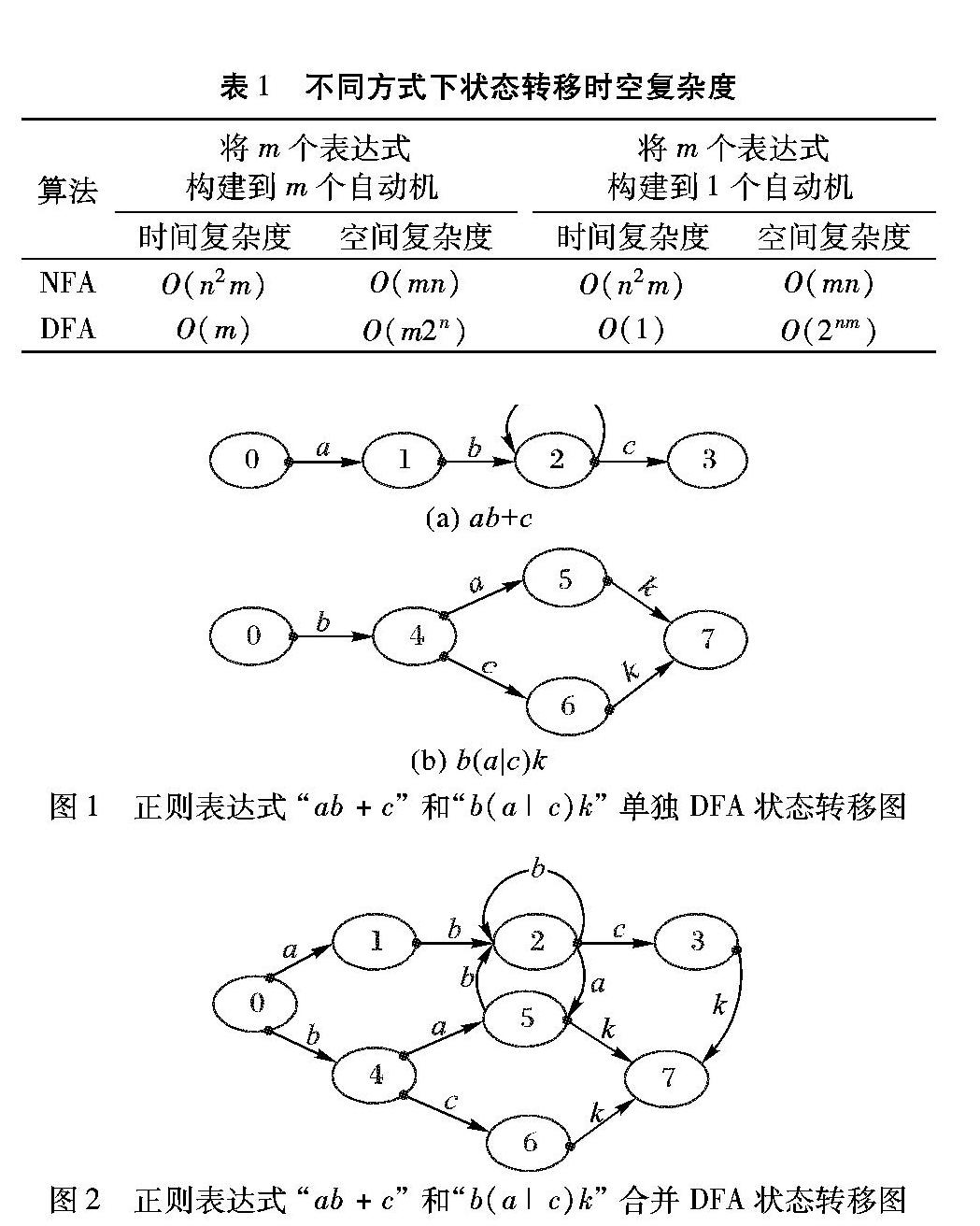
相比之下,虽然DFA处理一个字符只需要访问一个状态,但若将每条正则表达式编译成单独的DFA,其状态转移时间复杂度同样将随着规则数目的增多而增大;而将所有的正则表达式编译成一个混合DFA时,则会导致其空间需求大大增加,以当前的硬件条件将无法满足如此大的内存需求。使用不同的方法和策略进行匹配时所需要的状态转移空间复杂度和处理一个字符的状态转移时间复杂度见表1。
由表1可知,将多条正则表达式构建到同一个DFA中的状态转移时空复杂度最优;但将多条正则表达式构建到同一DFA中,存在因为正则表达式的交互而使状态数急剧增多的情况,从而造成存储空间不足的问题[10]。如正则表达式“ab+c”和“b(a|c)k”,它们单独构建DFA的状态转移图如图1所示,将它们合并构建到一个DFA中的状态转移图如图2所示。
可以看出相比于单独构建DFA自动机,两个表达式在构建到同一个DFA自动机时将造成因交互而带来的状态数增加。
对正则表达式进行规则分组是解决这一问题的一种有效的办法。
目前对正则表达式进行规则分组的一般方法[11-12]是:
1)通过计算判断正则表达式直接是否存在引起“膨胀”的交互;
2)以每一个正则表达式为顶点,用一条边连接相应的两个顶点,构建关系图;
3)设定分组阈值;
4)以最小相关原则的次序将正则表达式加入DFA中,直到达到阈值;
5)创建新的分组重复4),直到所有正则表达式都被分配完毕。
通过这样的规则分组,大大降低了两个正则表达式之间交互的可能性,缓解了将正则表达式编译到DFA中所带来的存储空间不足问题。但是,这样简单的分组将会由于DFA数量的增多而使匹配效率降低,若分为S组,效率降为原来的1/S。
另一方面,虽然应用层协议的种类十分繁杂,但在实际网络数据流中不同应用层协议的使用频率有很大的差异。我国2014年核心网络协议分布统计如表2所示。
特别是针对一些有特定功能的内网,往往会出现某些协议在数据流中频繁出现而某些协议却几乎不出现的情况。
同时,对于相同一个应用层协议来说,其在实现其协议功能的全过程中存在多个状态,不同的状态所对应的正则表达式描述也不一样。在安全审计中,并不需要用正则表达式将整个协议描述出来,只需将有审计价值的协议状态描述出来。如对TNS(Transparent Network Substrate)协议进行描述的正则表达式[12]中,通过“.*SERVICE_NAME=([a-zA-Z0-9_\.]+)”可以找出服务名;通过“(alter[]+database)[]+(close).*$”可以判断用户关闭数据库的行为;通过“\\x00\\x00(?:\\x01|\\x00)(.{1,2})(select.+?)(\\x01+?)(\\x00+?)”可以判断用户做了哪些查询操作;通过“(select) (.+?) from ([a-zA-Z0-9_\.]+)( )?(where)?.*$”可以判断用户对哪些数据表进行了操作。
2基于WGPB的自动机构建
若根据简单规则分组所构建的DFA在匹配过程中将根据线性时序对分组进行顺序匹配,最坏情况下(高频出现的协议对应的正则表达式被构建到DFA分组的末端)将造成匹配效率十分低下。基于上述网络流量中应用层协议所存在的频率与状态特征,本文提出了构建一种基于WGPB的自动机结构来应对将描述协议的正则表达式构成DFA带来的存储空间不足的问题,以及协议行为在网络中出现频率不均衡的问题。具体步骤如下:
步骤1建立描述协议的正则表达式集合R,包括内网中所有应用层协议的正则表达式。集合R中的元素为Rfi(f、i属于正整数)。其中: f代表表达式Rfi所描述的协议出现频率在所有协议中的排序,若有10个协议,则出现频率最高的f=1,出现频率最低的f=10;i代表表达式Ρfι所描述的协议行为状态在该协议所有状态中的重要程度,若该协议有10个行为状态,则最为重要的i=1,反之i=10。
3基于DC的安全审计方案
对于内网的安全审计方而言,根据内网的实际情况制定合适的安全审计策略能大幅提高审计的效率。本文提出了一种基于DC的安全审计方案,旨在利用对于内网应用层协议的充分可知性,分析内网的安全需求;利用对于内网应用层协议出现频率的可统计性,对协议的正则表达式描述集进行排序;利用对于同一应用层协议的状态可分性,依据审计需求对同一协议的不同状态的正则表达式描述集进行排序;通过改变和设定相关参数,实现对于内网的选择性审计。具体审计过程如图3所示。
审计数据生成模块:利用数据抓包软件对内网数据流进行数据采集;通过相应的固定规则对数据流进行底层协议的解析;生成审计数据以报文流的形式作为输入发送给审计引擎。
审计引擎生成模块:内网审计方通过对内网应用层协议频率进行统计和对每个应用层协议的不同状态进行需求分析来确定R集中元素f、i的值;在参数设定模块中,根据需求设定适当的D、F,并设定审计阈值Q;根据D、F将内网中协议的正则表达式描述集进行基于行为状态加权分组的自动机构建;由审计阈值Q控制审计引擎中所生效的自动机分组数对审计数据进行匹配,最终输出审计结果。
审计方审计需求的可选择性在于:
1)可以根据审计内容需求设置f、i的值。如对于协议A,审计方希望重点对其进行审计,则可将其对应的正则表达式描述集的下标f设为1,取得协议A对于其他协议的优先;同时,若审计方认为协议A中的某个状态值得着重审计,则可将其对应的正则表达式描述集的下标i设为1,取得在协议A中该状态对于其他状态的优先。在第二章的基于协议行为状态加权分组的自动机构建过程中,采取的是协议频率先导的原则,即在分组时f的优先级大于i。根据实际审计需求,对于特定的协议可以采取协议状态先导的原则,即在分组时i的优先级大于f。
2)可以根据审计效率需求设置D、Q的值。D为自动机分组中各个表达式集的交互程度阈值, Q为审计引擎中所生效的自动机分组数阈值。D的值越低,每一分组中正则表达式交互程度越低,其DFA状态数的增长就越小;但D的值过低不利于分组中正则表达式数量的增加,即达不到阈值F便构建新的分组,使分组数M增多。
分组数M越大,则匹配效率越低,Q值的设定一方面将缓解由于M过大带来的匹配效率降低;另一方面,由于自动机分组之间存在优先级关系,审计方可以通过Q值来选择审计的范围。但Q值越小,审计的命中率则越低。如审计方对于内网的安全审计只针对某些特定协议,则可将D、Q值降低,将审计集中在高优先级。
4评估与分析
首先分析构建基于WGPB的自动机性能,通过模拟内网数据流对HTTP等几个常用协议进行编译,与经典NFA转化算法Thompson[13]进行对比,比较Thompson算法与WGPB算法在构建自动机时的状态数,结果如图4所示。从图4可以看出,在编译HTTP等协议时,采用基于WGPB的自动机构建方法相比Thompson算法将状态数分别降低了85.50%、82.70%、54.80%、75.20%和79.30%。
同时,采用频率差分的HTTP、DNS(Domain Name System)、QQ、SMTP(Simple Mail Transfer Protocol)四个协议模拟内网实际数据流(100MB,共356189个报文),其中HTTP所占频率最大,接下来依次为DNS、QQ和SMTP,对基于简单分组的自动机引擎与基于WGPB的自动机引擎进行匹配效率对比,结果如图5所示。从图5可以看出,基于WGPB的自动机引擎在性能上相比 基于简单分组的自动机引擎具有明显优势,吞吐量有显著提高。
最后,将HTTP协议的访问目的地址、QQ协议的通信时间戳、TNS协议的数据库关闭这三个协议的三个行为状态设为审计优先级,审计命中率如表3。
表3的测试结果表明,构建基于WGPB的自动机能够大幅度缓解将多个正则表达式编译到相应DFA中所带来的状态数急剧增加的情况,相比Thompson构造算法具有明显优势。特别是在实际网络中各协议出现频率不均衡的情况下,基于WGPB自动机匹配的吞吐量相比基于普通分组自动机的匹配吞吐量具有很大的优势,呈现出对于数据流中出现频率越高的协议匹配速度越快的特点。在此基础上提出的基于DC的内网安全审计方案在高效的同时也具有极高的准确性。
5结语
本文提出的基于改进RE规则分组的内网安全审计方案,针对的是内网中应用层协议的安全审计。通过基于WGPB的自动机构建对有穷自动机DFA进行结构改进,并提出基于DC的内网安全审计方案,做到了根据内网的实际安全需求对内网行为的安全审计,达到了预期效果。然而,在日益复杂的网络环境与多种高新网络攻击手段威胁下,单一的安全防护技术不能满足防护需求,将本文提出的安全审计方案与入侵检测等安全防护技术相结合对内网进行成体系的安全防护是下一步需要做的工作。
参考文献:
[1]付钰,李洪成,吴晓平,等.基于大数据分析的APT攻击检测研究综述[J].通信学报,2015,36(11):1-14. (FU Y, LI H C, WU X P, et al. Detecting APT attacks: a survey from the perspective of big data analysis[J]. Journal on Communications, 2015, 36(11): 1-14.)
[2]CHEN P, DESMET L, HUYGENS C. A study on advanced persistent threats [C]// CMS 2014: Proceedings of the 15th IFIP TC 6/TC 11 International Conference on Communications and Multimedia Security, LNCS 8735. Berlin: Springer-Verlag, 2014: 63-72.
[3]VIRVILIS N, GRITZALIS D A. The big four — what we did wrong in advanced persistent threat detection? [C]// ARES 13: Proceedings of the 2013 International Conference on Availability, Reliability and Security. Washington, DC: IEEE Computer Society, 2013: 248-254.
[4]YANG G, TIAN Z, DUAN W. The prevent of advanced persistent threat [J]. Journal of Chemical and Pharmaceutical Research, 2014, 6(7): 572-576.
http://jocpr.com/vol6-iss7-2014/JCPR-2014-6-7-572-576.pdf
[5]XIA Q. Log-based network security audit system research and design [J]. Advanced Materials Research, 2010, 129-131: 1426-1431.
http://xueshu.baidu.com/s?wd=paperuri%3A%28eda56fad603f84741f0a01c931f5ca56%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fwww.scientific.net%2FAMR.129-131.1426&ie=utf-8&sc_us=2224052801561460832
[6]L T, LIU P. Multi-Agent network security audit system based on information entropy [C]// SWS 2010: Proceedings of the 2010 IEEE 2nd Symposium on Web Society. Piscataway: IEEE, 2010: 367-371
[7]HUANG X, HUENG X, QUAN P. Research on firewall system for confidential network [J]. Advanced Materials Research, 2012, 434-440: 4279-4283.
http://xueshu.baidu.com/s?wd=paperuri%3A%28acbe264444054dcd5c37b8ed816b2b83%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fwww.scientific.net%2FAMR.433-440.4279&ie=utf-8&sc_us=2535543053782017323
[8]张树壮,罗浩,方滨兴.面向网络安全的正则表达式匹配技术[J].软件学报,2011,22(8):1838-1854. (ZHANG S Z, LUO H, FANG B X. Regular expressions matching for network security[J].Journal of Software, 2011, 22(8): 1838-1854.)
[9]邵妍.正则表达式匹配算法并行化技术研究[D].北京:北京邮电大学,2013:15-18. (SHAO Y. Parallelization technology of regular expression matching algorithms [D]. Beijing: Beijing University of Posts and Telecommunications, 2013: 15-18.)
[10]YU F, CHEN Z F, DIAO Y L, et al. Fast and memory-efficient regular expression matching for deep packet inspection [C]// ANCS 06: Proceedings of the 2006 IEEE/ACM Symposium on Architectures for Networking and Communications Systems. New York: ACM, 2006: 93-102.
[11]蔡良伟,程璐,李军,等.基于遗传算法的正则表达式规则分组优化[J].深圳大学学报(理工版),2015,32(3):281-289. (CAI L W, CHENG L, LI J, et al. Regular expression grouping optimization based on genetic algorithm[J]. Journal of Shenzhen University (Science and Engineering), 2015, 32(3): 281-289.)
[12]张运明.协议行为审计关键技术研究与实现[D].长沙:国防科学技术大学,2010: 11-13. (ZHANG Y M. The research and implementation of the key technology of protocol behavior audit [D]. Changsha: National University of Defense Technology, 2010: 11-13.)
[13]陈曙晖,苏金树.基于内容分析的协议识别研究[J].国防科技大学学报,2008,30(4):82-87. (CHEN S H, SU J S. Protocol identification research based on content analysis [J]. Journal of National University of Defense Technology, 2008, 30(4): 82-87.)
