
基于嵌入式浏览器CSS引擎并行化技术的研究
2016-09-26 07:20刘秀秀郭志川胡琳琳
计算机应用与软件 2016年3期
刘秀秀 潘 梁 郭志川 胡琳琳
1(中国科学院大学 北京 100190)2(中国科学院声学研究所国家网络新媒体工程技术研究中心 北京 100190)
基于嵌入式浏览器CSS引擎并行化技术的研究
刘秀秀1,2潘梁2郭志川2胡琳琳2
1(中国科学院大学北京 100190)2(中国科学院声学研究所国家网络新媒体工程技术研究中心北京 100190)
针对嵌入式浏览器CSS(CascadingStyleSheets)解析效率低下的问题,提出一种CSS引擎并行化处理方法。通过对CSS引擎资源预取、样式解析和选择器匹配功能的描述,分别介绍如何将资源预取、样式解析与网页解析并行执行,以及CSS选择器并行匹配。该并行处理方法可以克服嵌入式浏览器边解析边加载带来的网络延时以及串行处理带来的用户等待时间长的问题。通过对多种网页加载时间的仿真测试,页面的加载速度提高了很多,实验结果验证了该方法的可行性。
层叠样式表引擎并行化资源预取样式解析选择器匹配
0 引 言
层叠样式表CSS是由W3C定义和维护的标准,一种用来为结构化文档如HTML文档或XML应用添加样式(字体、间距和颜色等)的计算机语言[1]。
相对于传统HTML的表现而言,CSS能够对网页中对象的位置排版进行像素级的精确控制[2]。CSS规范的广泛使用和嵌入式浏览器的广泛使用,使CSS引擎成为嵌入式浏览器中必不可少的部分。CSS引擎完成的功能是将网页中的CSS样式描述准确无误地解析出来,并对每个DOM节点(文档对象模型,DOM树是由结构文档生成的树结构,DOM节点是DOM树中的节点)进行样式匹配、样式运用,最终使样式效果得以实现[3]。
随着互联网的发展,嵌入式浏览器的响应速度成为影响用户体验的一个重要因素。越来越多的厂商开始利用多核处理器,然而,当前的嵌入式浏览器并没有充分利用硬件并行化的优势,因此导致计算资源闲置问题。
为了利用多核优势,一些桌面浏览器如Chrome开始采用多进程的方式,一个标签页一个进程,在标签页很多的情况下加快了网页的处理速度。然而在嵌入式设备上,更多的用户需求体现在一个标签页的情况下网页加载速度问题,这就要求提高浏览器的处理速度。据统计CSS引擎的处理时间占浏览器总处理时间的近40%[4],所以对CSS引擎的处理采用并行化,可以大大加快网页的加载速度,同时可以充分利用硬件资源。本文针对目前嵌入式系统处理速度有限、内存受限以及多核处理器广泛发展的特点,提出了一种CSS引擎并行处理的方法。
1 CSS引擎结构
从整体上看,CSS引擎的输入是文档对象模型(DOM树)和一个CSS样式集,经过CSS引擎的处理,输出标注了CSS样式的一棵渲染树[5]如图1(a)所示。本文将CSS引擎分为CSS样式解析器、内部样式结构、样式分类和样式匹配4个模块,内部结构如图1(b)所示。

图1 CSS引擎结构
在页面解析过程中,HTML解析器遇到CSS样式描述,会调用CSS样式解析器对CSS样式描述进行解析,具体为经过词法分析、语法分析和语义处理得到内部样式结构,供程序内部使用。内部样式结构依据CSS规范而设计,具有严格的层次关系,从最高层到最底层有样式表(CSSStyleSheet)、样式规则(CSSStyleRule)、样式选择符(CSSSelector)、样式声明(CSSMutalStyleDeclaration)、样式属性(CSSProperty)和样式属性值(CSSValue)等,如图2所示,表示了将一个CSS描述进行词法解析的过程。其中,样式规则由样式选择符和样式声明成对组成。
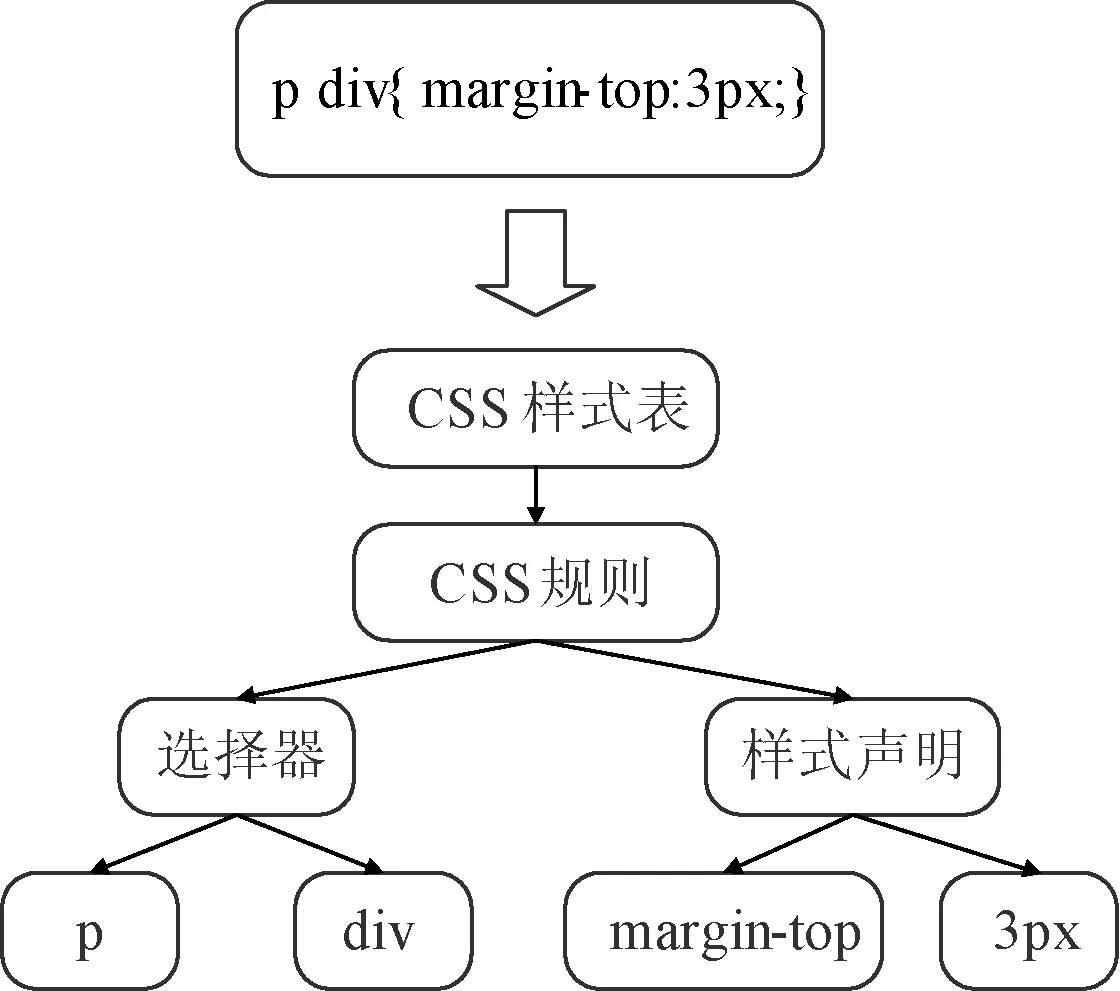
图2 内部样式结构
样式分类部分是对已解析得到的内部样式规则按照样式选择符类型进行分类,对于待匹配的节点,适用的样式选择符单元类型集是全部样式选择符单元类型的一个子集,在每次样式匹配前确定最小适用样式规则分类集,可以减少一些不相关样式规则的匹配。
样式匹配是将每个样式规则映射到DOM树上各个节点的过程。样式匹配在网页解析过程中调用次数非常多,匹配过程也较为复杂,需要消耗大量的时间,是CSS引擎的性能瓶颈。采用合适的样式匹配算法可以大大减少匹配的时间,优化网页的加载。
2 并行化CSS引擎处理方法
CSS引擎所做的主要工作包括CSS资源预取、CSS解析、CSS选择器匹配[6]。通过CSS引擎处理后,各个样式才能映射到DOM节点,确定每个节点的位置颜色大小等信息。下面通过CSS引擎的工作分别描述并行化算法具体的实施方式。
2.1CSS资源预取
如果在一个CSS样式表中引用了过多的外部CSS资源(如图片或CSS样式表),用户在请求资源下载时需要经历长时间的网络延时,为了减少下载资源所花费的时间,尽可能地从网络中预取所依赖的资源是非常必要的。
本文的方法是在HTML文档解析开始先进行文档的预扫描,如果发现有外部资源,就利用并行算法将其预取下来,即资源预取和页面解析是并行执行的,此时并不影响页面解析。如图3是未采用并行算法时页面解析过程中发现DOM节点中用到外部资源,页面解析阻塞,开始加载资源;图4是采用并行算法后,页面解析不受影响。
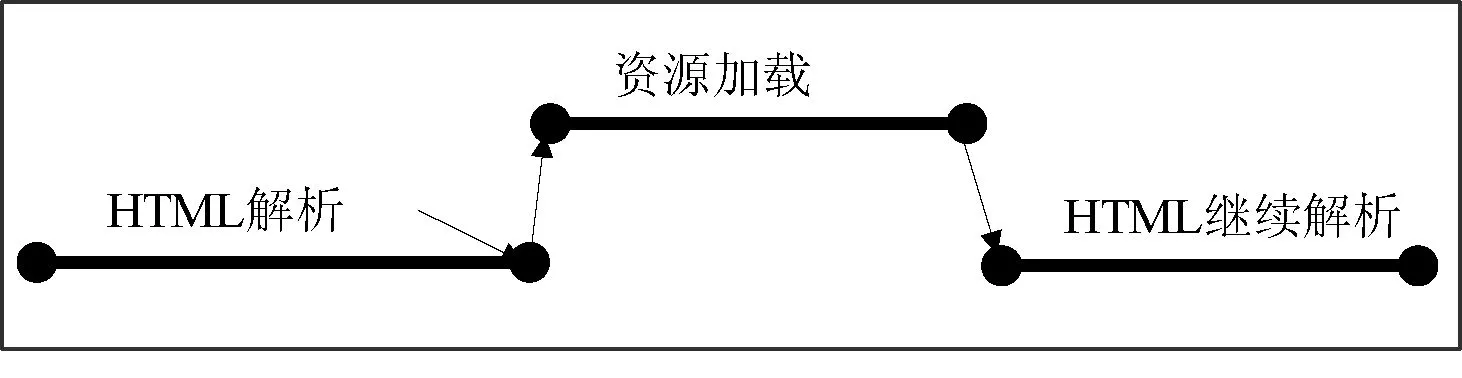
图3 CSS解析中资源加载

图4 CSS资源预取
下载足够的外部资源是非常重要的。如果加载资源过多会减慢页面加载的速度,增大网络的负担;如果加载资源不足,在CSS样式解析中需要重新加载外部资源,增大了网页解析的延迟。本文通过HTML预扫描器确定外部资源中选择符的ID或类属性是否都被预扫描器发现了,如果外部资源CSS选择符中所有的属性值都被HTML预扫描部分发现了,就开始加载此资源。这样经过判定后加载的资源在页面解析过程中会被使用,增大了加载资源的可用性。
2.2CSS解析
在本文的并行方法中,如果HTML解析过程中遇到样式描述符就将其分发给CSS解析器,每个样式解析分属不同的线程,这就意味着一旦有新的CSS样式,CSS解析会立即执行。然而为保证所有CSS样式规则的顺序与串行CSS引擎产生的规则顺序一致,本文中的方法是为每个解析任务分配一个独一无二的串行ID号,用来重排最初文档中的CSS样式表。图5所示是串行CSS资源解析的流程,遇新的CSS样式时页面解析会被中断,图6中所示当采用并行算法后,HTML页面解析不受影响。

图5 串行CSS解析

图6 并行CSS解析
CSS样式解析主要是将输入的CSS代码经过词法分析、语法解析生成计算机可以识别的语言。词法分析器,有时也被称作tokenizer,主要是将从样式表中输入的字符序列转换为单词序列,并对单词序列分类。词法分析器一般以函数的形式存在,供语法解析器调用。词法分析器通常不会关心每个单词之间的关系。例如有一个规则集div{color:red},当进行完词法分析后,一共得到6个有效的token:“div”,“{”,“color”,“:”,“red”,“}”。可见词法分析不依赖外部单词的信息,只依靠词法,比较简单。
语法解析器主要进行语法检查、并构建由词法分析器所返回的单词组成的数据结构,一般是语法解析树、抽象语法树等层次化的数据结构。例如上例中,如果网页书写人员将“red”写成了“rd”,语法解析器会报语法错误,此条规则会失效。
经过词法分析、语法解析后,CSS解析器输出一些CSS选择符和样式声明,为选择器匹配奠定基础。
2.3CSS选择器匹配
CSS匹配算法的功能就是将各个样式映射到DOM节点上。对于每个节点,CSS引擎必须找到所有匹配此节点的选择器或者规则。一个具体的CSS选择器匹配的例子如图5所示:ulem{color:blue},如图7所示是将em节点的颜色设置为蓝色,为了找到em的先辈节点,必须从底向上遍历DOM树,直到找到ul节点,此次匹配完成。

图7 CSS匹配示例
2.3.1根据CSS选择符的类型并行化处理
按照浏览器对CSS选择符书写规则带来的页面开销(从小到大)的顺序,CSS选择符的类型分为ID选择符(如#top{margin-top:50px})、类选择符(如id.x{font-size:12px})、类型选择符(如a{text-decoration:none;})、相邻兄弟选择符(如h1+h2{margin-top:50px} )、子选择符(如top>li{margin-top:50px} )和后代选择符(如topa{后代选择符,示例topa{}} )等[7]。本文的并行化方法是根据CSS解析后得到的CSS选择器的类型,将不同的选择器分在不同的线程中,与DOM节点进行匹配,如图8所示。图9为匹配算法执行的伪代码。其中idMatch(DOM),classMatch(DOM),tagMatch(DOM)和otherMatch(DOM)分别在不同的线程中,执行遍历DOM的操作,一直遇到匹配的DOM节点为止。
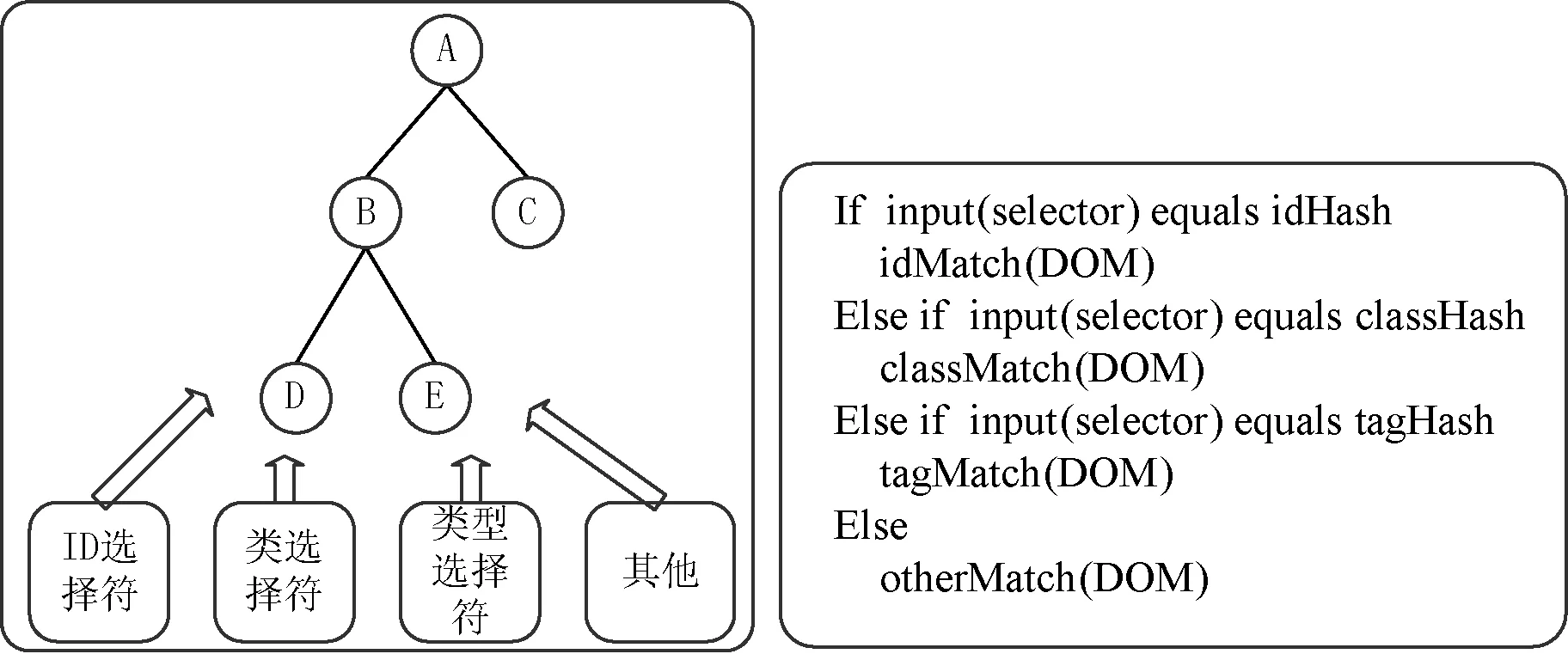
图8 根据选择符类型划分 图9 匹配伪代码
该算法首先根据不同的选择符类型建立哈希表,建立哈希表的具体方式利用了webkit中的策略[8-10],表中存放ID、类、标签名称或其他。如当输入选择器的类型为ID时,我们用idMatch线程处理,利用从右到左的匹配方式,逐级找到DOM节点。其他类型类似。例如对于“pimg”,我们首先找到“img”节点,然后遍历其DOM树,当在其祖先节点中找到“p”时才将此选择器的属性值应用到此节点,否则选择器不匹配。
2.3.2并行DOM遍历
对于2.3.1节,我们是根据选择器类型的不同进行了并行化处理,如果对于选择器的类型特别单一的网页,可以对DOM树结构进行并行化处理。首先将DOM树映射到一个节点数组中,本文利用work-stealing算法[11]将不同的数组块分给不同的核心处理。图10示出了并行化的具体实施方式。
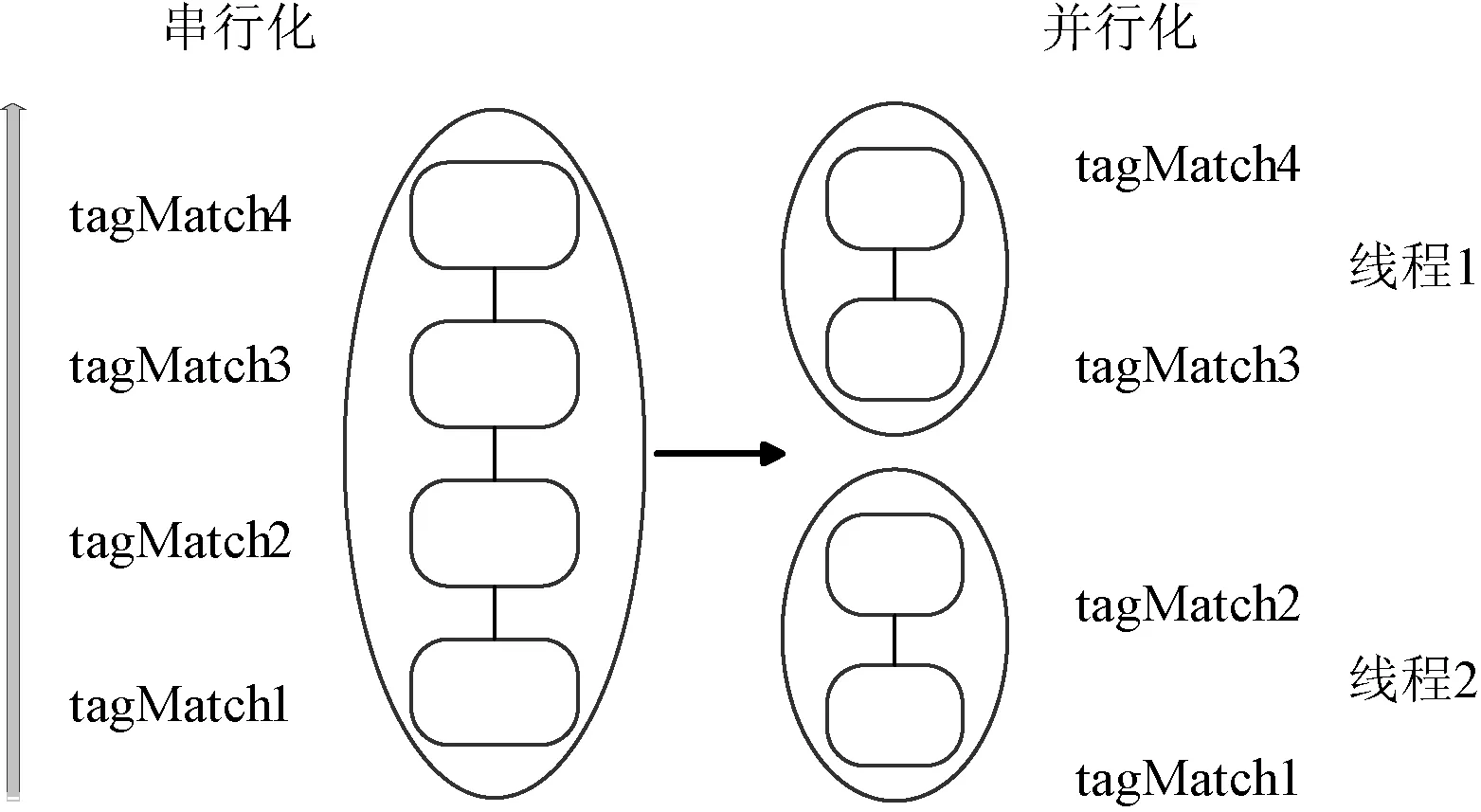
图10 并行DOM节点
对于不同的选择器不同的DOM节点,每个选择器匹配一个节点所花费的时间是不同的。DOM树中相邻的节点可能有相似的属性,所以匹配路线和处理时间也相似。相邻节点之间的这种相似性意味着在不同的子树上可能需要不同的处理时间,这就导致了静态分配不平衡性,从而增大了动态调整时间。为解决此问题,本文通过将不同的节点随机分配到不同的数组中,在一个并行循环中执行work-stealing算法,减少窃取的次数,加快了处理速度。
3 算法分析与验证
采用以上并行化CSS引擎处理算法在多核处理器环境下,可以充分利用硬件资源,效果更优。对于引用外部样式资源比较多的情况下,可以减少网络延时带来的影响。由于利用了多线程处理,增加了线程之间的通信;对资源的预加载以及CSS解析中增加了对空间的占用。这种牺牲空间换取时间的方式对于硬件处理来说是可行的。
考虑到不同的网页外部CSS样式表和图片的数量不同,本文基于不同的网页做了实验模型化,基于不同种类的网页进行仿真测试,测试结果如表1所示。结果表明,采用并行化算法可以明显提高加载速度,但是增加了空间的占用。而对于百度首页这种页面内容单一的网页,提升的效果并不明显。

表1 加载时间对比
4 结 语
本文对嵌入式浏览器CSS引擎的功能和结构进行了简要说明,主要介绍了并行化CSS选择器的三个方面:CSS资源预取、CSS解析和选择器匹配。另外选择器匹配中通过CSS选择
符并行化和DOM数据结构的并行化,详细介绍了并行化的实现方式。通过采用此方法,在多核处理器上可以大大加快网页的加载速度。由于CSS引擎相对独立,这种并行方法具有较强的可移植性。本文的研究对于将来多核处理器中CSS引擎并行化处理具有较好的参考价值。
[1]Mozilla.CSS[EB/OL].https://developer.mozilla.org/en-US/docs/CSS,Aug,2012.
[2] 罗智明.基于智能手机平台的CSS引擎优化与实现[D].电子科技大学,2012:8-14.
[3] 刘剑,桑楠,郭文生.嵌入式浏览器CSS引擎的研究与改进[J].计算机工程,2011,37(9):44-46.
[4]BadeaC,HaghighatMR,NicolauA,etal.Towardsparallelizingthelayoutengineoffirefox[C]//Proceedingsofthe2ndUSENIXconferenceonHottopicsinparallelism.USENIXAssociation,2010:1.
[5]MeyerovichLA,BodikR.Fastandparallelwebpagelayout[C]//Proceedingsofthe19thinternationalconferenceonWorldwideweb.ACM,2010:711-720.
[6]CascavalC,FowlerS,Montesinos-OrtegoP,etal.Zoomm:aparallelwebbrowserengineformulticoremobiledevices[C]//Proceedingsofthe18thACMSIGPLANsymposiumonPrinciplesandpracticeofparallelprogramming.ACM,2013:271-280.
[7] 田岭.深入理解CSS选择符的匹配方式[J].软件导刊,2012,10(12):37-38.
[8] 葛春良.嵌入式浏览器多线程机制的研究与实现[D].电子科技大学,2012:38-39.
[9]TheWebKitopensourceproject[EB/OL].[2011 -02 -10].http://www.Webkit.org.
[10] 赵经纬,周余,王自强,等.基于WebKit的嵌入式浏览器的研究与实现[J].电子测量技术,2009,34(3):135-138.
[11] 杨际祥,谭国真,王荣生,等.并行分治计算中的一种Work-stealing策略[J].小型微型计算机系统,2010,31(3):408-412.
RESEARCHONCSSENGINEPARALLELISATIONTECHNIQUEBASEDONEMBEDDEDBROWSER
LiuXiuxiu1,2PanLiang2GuoZhichuan2HuLinlin2
1(University of Chinese Academy of Sciences,Beijing 100190,China)2(National Network New Media Engineering Research Center,Institute of Acoustics,Chinese Academy of Sciences,Beijing 100190,China)
TosolvethelowefficiencyproblemofCSSparsinginembeddedbrowsers,thispaperproposesaCSSengineparallelisedprocessingmethod.ThroughtheresourcesprefetchingonCSSengine,thestyleparsinganddescriptionoftheselectormatchingfunction,werespectivelyintroducehowtoparallelisetheexecutionofresourcesprefetching,styleparsingandwebpageparsing,aswellastheparallelmatchingofCSSselectors.Thisparallelprocessingmethodcanovercomethenetworkdelayincurredbytheembeddedbrowsersloadingtheresourceswhileparsing,andthelongtimewaitingproblembroughtforthbyserialiseprocessing.Byavarietyofwebpagesloadtimesimulationtests,theloadingspeedofwebpagesraisedalot.Experimentalresultverifiesthefeasibilityoftheproposedmethod.
Cascadingstylesheets(CSS)engineParallelisationResourcesprefetchingStyleparsingSelectormatching
2014-05-07。刘秀秀,硕士,主研领域:嵌入式系统。潘梁,副研究员。郭志川,副研究员。胡琳琳,助理研究员。
TP393.092
ADOI:10.3969/j.issn.1000-386x.2016.03.053
猜你喜欢
天然气与石油(2022年4期)2022-09-21
天然气与石油(2021年5期)2021-11-06
天然气与石油(2021年1期)2021-03-08
科学与财富(2019年19期)2019-12-11
数码世界(2018年5期)2018-06-04
商周刊(2017年22期)2017-11-09
电脑与电信(2017年6期)2017-08-08
大学物理实验(2015年2期)2015-10-22
课堂内外(初中版)(2015年9期)2015-09-10
河南电力(2015年5期)2015-06-08
