
面向浏览器不兼容性的自动化测试的研究
2016-09-26 07:27吴小东裴颂文
计算机应用与软件 2016年3期
吴小东 裴颂文,2
1(上海理工大学计算机科学与工程系 上海 200093)2(中国科学院计算技术研究所计算机体系结构国家重点实验室 北京 100190)
面向浏览器不兼容性的自动化测试的研究
吴小东1裴颂文1,2
1(上海理工大学计算机科学与工程系上海 200093)2(中国科学院计算技术研究所计算机体系结构国家重点实验室北京 100190)
随着Web应用技术的快速发展及浏览器和平台数量的不断增长,跨浏览器的不兼容性问题显得越来越突出。尽管现有的浏览器不兼容性测试工具较多,但是大多数的测试工具是手工测试,耗时过长,容易出错,而且国内对于跨浏览器不兼容性的自动化测试问题缺乏系统性研究。因此基于爬虫工具生成应用程序的导航模型,以及等价性检查技术和自动化测试系统(ATS)提出一种检测跨浏览器不兼容性问题的方法,并结合已有的测试工具进行比较。实验结果表明,该方法能够有效地自动识别和测试跨浏览器不兼容性问题。
跨浏览器不兼容性爬虫工具导航模型等价性检查自动化测试系统
0 引 言
随着互联网技术在全球范围内的快速发展,Web应用程序的使用在我们的日常生活中变得越来越广泛。现代的Web应用程序内容比较丰富,交互能力强及 AJAX和 Flash技术的发展,在客户端为终端用户提供了更强大的功能和应用。而且近一些年来出现的浏览器及计算平台越来越多,各具特色。当Web应用程序在不同的浏览器和平台上运行时,Web应用程序在外观、结构和行为上将会产生一些差异。因此跨浏览器不兼容性越来越受到许多开发者及用户的普遍关注。
早期的一些测试工具主要是在不同的客户端平台上为浏览Web应用程序提供仿真环境,比如Microsoft Expression web和 Adobe BrowserLab。虽然这些工具提供了一些仿真和可视化的基础设施,但是识别和比较行为差异仍然需要用户去做。Eaton等[1]提出了识别Web页面有问题的HTML标签的方法并手动分类正确和错误的页面,但是现代Web应用程序不仅局限于页面的HTML标签,还包括HTML结构、CSS样式和DOM的动态特征,显然不能满足测试的需要。Tamm[2]提出了一个使用DOM和视觉信息的方法,找出单一页面的布局问题。在截图过程中它要求用户手动改变页面,因此这种技术不适用于动态生成页面。
在国外,一些CBI自动化测试工具应运而生。Choudhary等[3]提出了WEBDIFF工具,结合页面DOM结构和基于计算机视觉技术的视觉比较来检测CBI的结构差异,但它并没有提出检测CBI行为差异的方法。Mesbah等[4]提出了 CROSST工具,使用自动化爬虫工具和导航模型比较来检测CBI的行为差异。Roy Choudhary等[5]提出了CROSSCHECK工具,它结合了WEBDIFF和CROSST的两种方法,利用基于错误检测的机器学习[6]技术,更好地检测了CBI的行为和结构差异。在国内,随着我国经济的飞速发展,软件行业对于软件自动化测试的需求与标准越来越高,市场上对出现的软件自动化测试工具日益增多。但是市场上对浏览器兼容性进行自动化测试的工具并不多见,已有的学术研究也没有对CBI检测问题进行过系统性的研究。因此本文基于现有的一些方法对CBI测试提出CBI的方法和框架,并结合我们以前研究的自动化测试工具ATS[7],较好地完成跨浏览器不兼容性自动化测试的工作。
1 背 景
1.1Web应用程序和Web浏览器
Web应用程序是一种通过互联网能够让Web浏览器和服务器通讯的计算机程序。终端用户可以通过Web浏览器与Web应用程序的客户端进行交互,比如看网页、输入数据和执行操作等。这些交互操作通过客户端向服务器发出请求,然后服务器响应这些请求来更新当前Web网页。Web网页由HTML或XML脚本语言编码而成。它还包括其他的相关资源,比如CSS样式表、客户端代码(JavaScript)、图像、FLASH等。最后Web网页被渲染后显示在浏览器上。
Web浏览器是由大量组件构成的相当复杂的应用程序。Grosskurth等[8]提出了几个Web开源浏览器的相关架构。在浏览器所有的组件中,布局引擎是最重要的浏览器组件。它结合了页面的HTML的结构信息和CSS样式表的格式信息,负责渲染Web页面。浏览器在内存中保存页面的DOM表示以便让客户端脚本去动态修改Web页面。布局引擎是跨浏览器不兼容性问题的主要来源之一,因为同样的HTML/DOM和CSS在不同的浏览器中可能产生不同的页面。第二个组件是事件处理引擎或DOM引擎,它主要负责处理用户操作和执行基于浏览器DOM-API的变化。由于各个浏览器的事件处理算法的不同以及支持的DOM-API不同,它也是跨浏览器不兼容性问题的来源之一。因此,同样的用户操作可能引起不同的DOM变化。第三个引起跨浏览器不兼容性问题的来源是JavaScript引擎即执行浏览器JavaScript代码的运行时环境。因为不同的浏览器的JavaScript引擎存在着微妙而明确的差异, 会产生不同的行为差异。
1.2DOM,Crawljax和ATS
DOM[9]即文档对象模型,是面向HTML和XML的应用程序接口(API)。该模型定义了HTML文件和XML文件在内存中的文档结构,提供了对HTML和XML文件的访问、存取方法。DOM将整个HTML页面文档或XML数据文档规划成由多个相互连接的节点级构成的文档,文档中的每个部分都可以看作是一个节点。这样一个节点的集合看作是一个DOM文档树,通过这个DOM文档树,开发者可以对文档的内容和结构拥有强大的控制力, 同时使用DOM API可以在文档树里十分方便地遍历、添加、删除、修改和替换节点,由此生成丰富的应用形式。DOM与平台和语言是无关的,因而可以在各种平台和语言上实现。
Crawljax爬虫工具是由Java语言编写而成的开放源代码软件,能够自动捕捉和抓取基于AJAX技术的Web应用程序。Crawljax通过一个动态爬行引擎驱动来探测任何基于 Ajax Web应用程序。它能够根据DOM状态和状态之间的转换来创建一张状态图。这张推论出的状态图为各种类型的测试分析和测试技术提供了一个强大的工具,比如:测试生成、基于变量的测试、检测失效链接、非功能测试、检测未使用的代码等。Mesbah等[10]详细介绍了Crawingjax的算法和方法并讨论了Crawljax测试工具的具体实现。
ATS是一个与测试业务无关的平台,可以用于任何测试(如功能测试、性能测试等)及测试任何对象,也可以用于软件自动化黑盒测试。ATS支持测试脚本、支持任意的测试项目组合及时间调度、支持在不同的服务器上分布式地运行测试脚本和提供统一友好的用户界面。ATS服务器采用纯Java实现,具有跨平台性特性。ATS是基于J2EE的Struts[11]理论的MVC模式开发,服务器采用了Tomcat服务器技术,客户端采用JSP技术构建Web页面,后台事务处理采用Java Beans技术。ATS采用Web网页编写界面,用户在ATS界面上所有的操作请求发送给Web服务器来处理并采用Struts来构建Web网页及请求处理器,通过Hibernate[12]来进行数据库操作,从而加强ATS系统的健壮性、可维护性、易扩展性。
2 CBI的测试方法
本文的研究方法包括三个步骤:(1) 在不同的浏览器运行环境下通过Crawljax爬虫工具自动抓取或捕捉目标Web应用程序,并生成导航模型。这些模型可能包括Web应用程序的一系列的用户交互信息、下载信息、显示内容、窗口布局、链接切换等。(2) 比较两个不同浏览器应用程序的生成模型,发现它们之间的差异。(3) 生成CBI报告提交给Web应用开发者,让他们确定原因并解决这些问题。
2.1导航模型
导航模型(记为M)是由爬虫工具捕捉Web应用程序生成的,也称为有限状态机。它的状态和转换分别表示终端用户在Web浏览器上所观察到的页面和用户操作(例如点击控件)。每一个状态由可编程语言来表示,每一个转换由用户操作的名称来标记。对于每一个观察到的状态和相应的页面,导航模型记录了页面的截图、页面的DOM表示、页面的每一个DOM元素的可视化表示等。为了有效地比较多个导航模型,我们提出了从层次化角度来查看和分析这个导航模型。它的顶层是有限状态机的图表示,我们称它为状态图,它主要捕捉一系列页面操作痕迹比如交替用户操作序列及页面转换。它的每一个状态对应着终端用户在浏览器中所观察到的一个页面。每一条边对应着两个状态之间的转换,由用户操作(例如点击)和转换引起的元素标记。第二层是每个状态(页面)的完整可编程语言表示,我们称它为页面模型,它描述了每一个浏览器页面的详细信息。以下分别对状态图、页面模型进行了定义。
定义1(状态图)状态图G是一个带有标记的有向图并包含一个特定的始点。它由五元组G(V, E, O, L,F)表示:
V:顶点集合
E:有向边集合
O:特定始点
L:字母标记
F:标记函数
G具有以下的具体特征:
(1) 每一个标记至多出现在所给定顶点的一个出边上,即在整个图中,尽管有同样的标记出现在几个边上,但没有一个顶点会有两个或多个同样标记的出边。
(2) 图G可以有多重边,即e1,e2∈ E : s(e1)=s(e2)和d(e1)=d(e2)。
(3) 每一个节点可由根节点r到达,即图G由单一连结组件组成。
(4) 图可以是环状的。
特定结点O通常表示始点或Web应用程序的页面。对于边e=(u,v),我们用s(e)表示一个源顶点u,d(e)表示一个目的顶点v;In(v)和Out(v)分别表示顶点V的一组入边和出边。
定义2(页面模型)页面模型是一个带有根节点的有向标记树。它由五元组T(Q,D, R,T,F)表示:
Q:顶点集合
D:有向边集合
R:根节点
T:标记集合
F:标记函数
页面模型是构成Web页面的DOM树结构的抽象表示。此模型包括客户端状态的许多信息比如JavaScript 变量值或CSS的属性等。参数Q、D和R在DOM树中有明显的含义。一个特定节点的标记就是DOM节点的HTML标签名。一组名-值对表示DOM节点的属性。我们使用单一标记对数据进行抽象的表示,以便将这个模型形式化并对其进行等价性验证。
2.2等价性检查
从导航模型的层次角度分析,我们将等价性检查分为行为等价性检查和页面等价性检查。它对不同浏览器的生成模型进行匹配比较找出行为差异。以下详细讨论了行为等价的概念及行为等价性检验算法。
定义3(行为等价)给出两个状态图G1(V1,E1,o1,L,F1)和G2(V2,E2,o2,L,F2),若G1与G2行为等价,记为G1≡G2,当且仅当存在一个双射函数M: V1→V2以下都是正确的:
(1) ∀u,v∈V1,(u, v)∈E1⟺(M(u),M(v))∈V2
(2) ∀e1(u1,v1)∈E1,e2(u2,v2)∈E2,M(u1)=u2&&M(v1)=v2⟹F1(e1)=F2(e1)
(3) M(o1)=o2
算法1是匹配一对导航模型M1和M2的整个算法。函数StateGraph返回底层状态图,它的值作为输入值传递给函数TraceEquivCheck。如果状态图G1和G2不等价,则返回错误。函数OutTraceDiff(G1,G2)从注释状态图中提取行为差异。TraceEquivCheck(G1,G2)算法实现了两个状态图G1和G2作为一个同构检查的行为等价性检查。OUT(v)返回顶点V的一组出边,LABEL(e)返回边e的标签。函数Lookup(l,edgeSet)返回带有标签l的一个边,如果它不存在,则返回null。Dest(e)返回边e的目的顶点。在G1和G2中,假定每个边的匹配字段初始化是false,每个顶点的访问字段初始化都是null。整个算法是深度优先遍历和线性时间的一个简单变体。
算法描述如下:
算法1ModelEquivCheck(M1,M2)
G1← StateGraph(M1)
G2← StateGraph(M2)
if (TraceEquivCheck(G1,G2) = false)
then OutTraceDiff(G1,G2)
TraceEquivCheck(G1,G2)
procedure Match(u1,u2)
u1.visited←true
u2.visited←true
u1.match←u2
u2.match←u1
For each e1∈Out(u1)do
e2←LOOKUP(Label(e1),Out(u2))
if (e2≠null) then
v1←Dest(e1)
v2←Dest(e2)
if ((v1.visited=false)&
(v2.visited=false))
then
e1.match←true
e2.match←true
edgeCt+= 2
Match(v1,v2)
else if((v1.match=v2)&
(v1.visited=true)&
(v2.visited=true))
then
e1.match←true
e2.match←true
edgeCt+= 2
main
global edgeCt
edgeCt←0
o1←StartVertex(G1)
o2←StartVertex(G2)
Match(o1,o2)
if (edgeCt=|E1|+|E2|)
then return(true) comment:G1≡G2
else return(false) comment:G1≠G2
2.3CBI比较
我们在算法2中给出了对跨浏览器不兼容性问题检测的整体方法。算法的输入值包括目标应用程序打开页面的url,两个被测试的浏览器Br1、Br2。算法的输出值是CBI的列表L。
2.3.1抓取和捕捉模型
这一阶段是在两个不同的浏览器Br1和Br2中。我们通过爬虫工具Crawljax抓取应用程序和记录终端用户所观察到的行为,分别记为导航模型M1、M2,它们由函数genCrawlModel(url, Br1,Br2)实现。Mesbah等[10]详细介绍了Crawingjax爬虫工具的具体功能实现。
2.3.2模型比较
这一阶段比较导航模型M1和M2并记录它们之间的差异。主要有以下的四种不同的CBI比较:

p=0.7×c+0.2×d+0.1×e
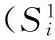
结构CBI比较为了比较结构CBI(布局CBI),我们可以使用Roy Choudhary 等人在参考文献[13]中提到的方法。他们定义了一个模型叫排列图记为A。主要执行两个步骤:(1) 分别从两个不同的浏览器的页面布局中提取排列图A1,A2;(2) 用等价性检验算法比较两个排列图找出它们之间的差异性。在算法2第8行中由函数diffLayout()实现的(详细算法请参阅文献[13]中的算法1和算法2)。
算法2CBI 整体算法
输入url:URL of target web application Br1,Br2: Two browsers
输出L: List of CBI
1 begin
2 (M1,M2)←genCrawlModel(url, Br1,Br2)
//比较状态图
3 (T, PageMatchList)←TraceEquivCheck(M1,M2)
// 比较页面匹配对
//视觉CBI比较
//结构CBI比较

9end
10end
//生成CBI报告列表
11 L←computeCBI(T, V, B, PageMatchList)
12 return L
13 end
3 CBI的实现和实验结果
3.1CBI的架构
如图1所示,本文的CBI架构主要包括三个组成部分:模型收集器、模型比较器和报告生成器。

图1 CBI架构
模型收集器接受一个Web应用程序,使用现有的网络爬虫 (Crawljax)工具从多个浏览器提取其导航模型。模型比较器主要是执行各个不同的CBI的比较。报告生成器以HTML的格式生成CBI报告给Web开发者,让他们能够发现CBI并及时找出原因。
3.2CBI的自动化测试结构
CBI的体系结构主要由分布执行服务器、屏幕捕捉服务器和Web服务测试三部分组成,如图2所示。分布执行服务器是整个体系结构的核心部分,主要负责测试脚本执行和测试任务分配。分布式执行引擎主要实现自动化测试、Web服务测试的交流信息和屏幕捕捉信息的交互。屏幕捕捉服务器主要实现捕捉浏览器的接口和组件,然后将消息递交给分布执行服务器。这些信息储存到屏幕捕捉服务器中,并通过消息传递接口传送给分布式执行引擎,经过分析然后将测试内容递交给测试人员,从而了解到浏览器的不兼容性问题。
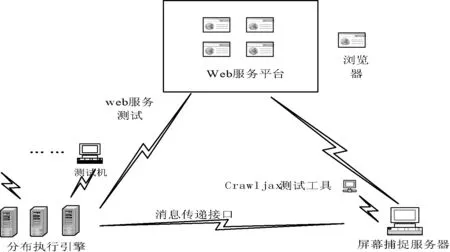
图2 CBI自动化测试系统结构图
3.3实验结果
在实验中, 本文选择了两个不同的浏览器:火狐浏览器(版本24)和IE浏览器(版本 8.0),它们都在 Microsoft Window 7 环境下运行。我们随机选取了五个不同的应用程序,它们分别来自不同领域的类型网站,这样能够使测试数据更加合理。如表1所示,它包括名称、网址和类型。我们利用现有的WEBDIFF和CROSST测试方法分别对以下不同的应用程序测试。

表1 测试对象
表2给出了三种测试方法的测试数据。这些测试数据由报告生成器生成,并由我们人工统计得出列表2。第一列显示了测试对象的名称,其他几列给出了浏览器不兼容性问题的个数,包括行为差异、视觉差异、结构差异和总数差异。由表2的实验结果比较表明,我们发现对于WEBDIFF和CROSST测试工具都不能完全地测试应用程序的行为、视觉和结构差异;而CBI的测试方法能够很好地自动测试和识别跨浏览器不兼容性的行为、视觉和结构差异,并且该方法还能节省大量的时间。例如表2所示的hupu应用程序,它包括1个行为差异、1个视觉差异和16个结构差异,共18个差异,而WEBDIFF测试仅共有11个差异,CROSST测试仅共有1个差异。

表2 WEBDIFF、CROSST和CBI的测试结果
4 结 语
跨浏览器不兼容性对于Web应用开发者来说是一个常见的问题,研究它们具有重要的现实意义。本文结合现有的一些技术提出了检测浏览器不兼容性问题的方法,并结合以前研究的自动化测试框架,设计出了浏览器不兼容性测试的结构。最后通过实验数据来验证了这一方法,达到了比较好的验证效果。
在未来的工作中,我们将会进一步改进自动化设计系统(ATS)结构,提高工作效率,更好地满足开发者和客户的工作需要。今后也可以在不同的平台上(桌面平台、移动平台等),对跨平台的不兼容性进行研究。
[1] Eaton C,Memon A M.An empirical approach to evaluating web application compliance across diverse client platform configurations[C]//International Journal of Web Engineering and Technology,USA,2007:227-253.
[2] Tamm M.Fighting layout bugs[EB/OL].http://code.google.com/p/fighting-layout-bugs/.
[3] Roy Choudhary S,Versee H,Orso A.Webdiff:Automated identification of cross-browser issues in web applications[C]//Proc of the 26th IEEE International Conference on Software Maintenance (ICSM’2010).Timisoara,Romania,2010:1-10.
[4] Mesbah A,Prasad M R.Automated cross-browser compatibility test[C]//Proc of the 33rd International Conference on Software Engineering (ICSE’2011).NewYork,USA,2011:561-570.
[5] Roy Choudhary S,Prasad M R,Orso A.Crosscheck:Combining crawling and differencing to better detect cross-browser incompatibilities in web applications[C]//Proc of the IEEE Fifth International Conference on Software Testing (ICST’2012).Montreal,Canada,2012:171-180.
[6] Nataliia Semenenk,Marlon Dumas,Tõnis Saar.Browserbite:Accurate cross-browser testing via machine learning over image features[C]//Proc of the 29th IEEE International Conference on Software Maintenance (ICSM’2013).San Francisco,USA,2013:528-531.
[7] 裴颂文,余强,吴百锋.一种新的基于J2EE技术的软件自动化测试系统的研究与实现[J].清华大学学报,2007(6):51-56.
[8] Grosskurth A,Godfrey M W.A reference architecture for web browsers[C]//Proc of the 21st IEEE International Conference on Software Maintenance (ICWE’2005).Waterloo,Canada,2005:661-664.
[9] Keith J,Sambells J.DOM Scripting:Web Design with Javascript and the Document Object Model[J].Friends of Ed,2010.
[10] Mesbah A,Bozdag W,van Deursen A.Crawling ajax by inferring user interface state changes[C]//Proc of the 8th International Conference on Web Engineering (ICWE’2008).Vancouver,Canada,2008:122-134.
[11] 孙卫琴.精通Structs:基于MVC的Java Web设计与开发[M].北京:电子工业出版社,2004.
[12] 夏昕,曹晓钢,唐勇.深入浅出Hibernate[M].北京:电子工业出版社,2005.
[13] Roy Choudhary S,MukulR Prasad,Alessandro Orso.X-PERT:Accurate Identification of Cross-Browser Issues in Web Applications[C]//Proc of the 29th IEEE International Conference on Software Maintenance(ICSM’2013).San Francisco,USA,2013:702-711.
RESEARCH ON AUTOMATED TESTING FOR INCOMPATIBILITY OF CROSS-BROWSER
Wu Xiaodong1Pei Songwen1,2
1(DepartmentofComputerScienceandEngineering,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China)2(StateKeyLaboratoryofComputerArchitecture,InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing100190,China)
With the rapid development of Web application technology and constant growth in numbers of new browsers and platforms, cross-browser incompatibilities (CBI) problem becomes more and more noticeable. Though current testing tools for browsers’ incompatibilities are not just few, however most of them are in manual operation with time consuming and being error-prone, and there lacks the nationwide systematic researches on automated testing approach for CBI. Therefore, based on the navigation model of generating application with crawler tool, the equivalence checking technology and the automatic test system (ATS), we put forward a method of cross-browser incompatibility detection, and compare it among the existing testing tools. Experimental results show that the proposed method can effectively and automatically identify and test the cross-browser incompatibility problems.
Cross-browser incompatibility (CBI)Crawler toolNavigation modelEquivalence checkingAutomated testing system (ATS)
2014-08-19。
计算机体系结构国家重点实验室开放课题项目(CARCH201206);上海理工大学国家级项目培育基金项目(12X GQ07)。
吴小东,硕士生,主研领域:软件测试,安全测试。裴颂文,博士。
TP311.13
A
10.3969/j.issn.1000-386x.2016.03.004
猜你喜欢
电脑报(2019年12期)2019-09-10
电子制作(2019年10期)2019-06-17
中国计算机报(2018年30期)2018-11-12
网络安全和信息化(2018年4期)2018-11-09
科学与财富(2017年3期)2017-03-15
环境与生活(2016年6期)2016-02-27
单片机与嵌入式系统应用(2015年1期)2015-03-26
计算机世界(2009年34期)2009-11-17
计算机世界(2009年29期)2009-08-14
网络传播(2009年5期)2009-05-26
