
基于局部密度估计的聚类个数确定研究
2016-09-26 02:07:47龙章勇
河南科技 2016年9期
龙章勇
(南京铁道职业技术学院,江苏 南京 210031)
基于局部密度估计的聚类个数确定研究
龙章勇
(南京铁道职业技术学院,江苏南京210031)
随着人工智能和数据挖掘技术的兴起,聚类分析已被广泛应用于通信、文本数据统计、生物信息学和图像处理中。对于非监督聚类分析,聚类的分类数目是决定聚类质量的关键因素。通常聚类个数事先无法确定,随即选择的初始聚类中心容易使聚类结果不稳定。针对此,基于聚类中心具有高局部密度且距高局部密度聚类中心距离较远的特点,提出一种基于局部密度估计的聚类个数的估计方法。经过仿真实验,验证了该算法具有良好的有效性和鲁棒性。
聚类个数;密度峰值估计;聚类有效性;聚类分析
随着计算机和互联网应用的普及,信息和数据爆炸似的增长,复杂的多种信息数据也可以作为很重要的研究内容。从海量数据的研究和挖掘中提取出互有关系的信息变得非常重要,甚至决定了社会科技的发展。聚类算法作为数据分析的主要工具,已在多方面被广泛地研究和应用。
1 聚类有效性分析与聚类个数估计
1.1聚类有效性分析
现在常用的估计聚类个数的有效性评价方法大概有3种:有效性指标、检测稳定聚类结构的稳定性方法和系统演化方法。其中,有效性指标在实际中应用广泛,包括Silhouette指标、Davies-Bouldin指标、Calinski-Harabasz指标、加权的类间类内相似度比率和Homogeneity-Separation指标等。
1.1.1平均Silhouette(Sil)指标。设a(t)为聚类Cj中的样本t与类内所有其他样本的平均不相似度或距离,d(t,Ci)为样本t到另一个类Ci的所有样本的平均不相似度或距离,则b(t)=min{d(t,Ci)},i=1,2,……,k;i≠j[1]。Sil指标计算每个样本与同一聚类中样本的不相似度以及与其他聚类中样本的不相似度,其每个样本t的计算公式如下:
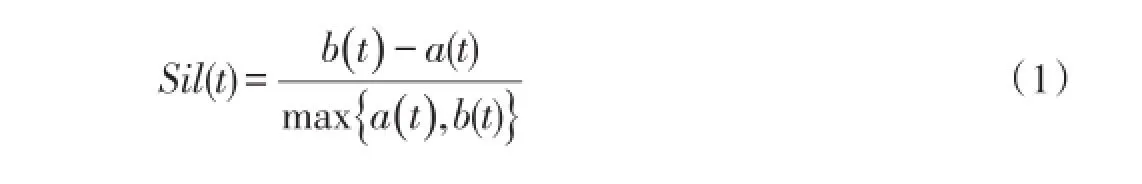
一般以一个数据集的所有样本的平均Sil值来评价聚类结果的质量,Sil指标越大,表示聚类质量越好,其最大值对应的类数作为最优的聚类个数。
1.1.2Davies-Bouldin(DBI)指数。DBI指数是基于样本的类内散度与各聚类中心间距的测度,进行类数估计时其最小值对应的类数作为最优的聚类个数。设DWi表示聚类Ci的所有样本到其聚类中心的平均距离,DCij表示聚类Ci和聚类Cj中心之间的距离,则DB指标如下:

1.1.3Calinski-Harabasz(CH)指标。CH指标(伪F统计量)是基于全部样本的类内离差矩阵与类间离差矩阵的测度,其最大值对应的类数作为最优的聚类个数,则CH指标如下:

其中,SSB和SSw分别表示类间离差矩阵和类内离差矩阵,k为聚类数目。类间离差矩阵SSB定义如下:

其中,mi,m分别表示第i个类的中心和类内平均,||mi-m||定义了向量之间的欧式距离。类内离差矩阵SSw的定义如下(也称为Hartigan指标):

其中,x,Ci分别表示数据点和第i个类。
从定义可以看出:好的聚类结果,是希望SSB越大越好和SSw越小越好。因此,CH(k)的值越大,选择的k值越接近最优。
1.2聚类数目对有效性的影响
对于盲聚类分析,聚类数目和聚类初始中心对于结果的影响很明显,因为目前采用的聚类算法,类似于K-均值聚类,都对类数和初始聚类中心敏感。
不失一般性,对同一组数据集合,分别采用目标类数为3~5进行K-均值聚类,仿真的对比结果如图1所示。

(a)采用k=3聚类的结果

图1 不同类数下的K均值聚类结果
为了对比不同聚类数目下的聚类结果的性能指标,对上述实验数据,分别采用2.1节中的指标进行评估,结果如图2所示。从图2可以看出,前3种指标显示,选择类数为4最接近最优的聚类目标。但是采用Hartigan指标,其结果不然。

图2 4种有效性指标估计结果
上述实验中,不同的指标所侧重的测度是不一致的,从而适用的应用场景也是有区别的。另外,从相邻类数下指标的走势可以看出,K-均值算法对于类数敏感性显而易见。因此,在聚类之前,能够确定有效的聚类数目是非常必要和重要的。
2 基于局部密度估计的聚类个数确定
给定点集S,对于每一个样本点i,为其定义2个属性参量:局部密度ρi和距离高密度点集的距离δi。样本点i的局部目的ρ定义如下:

其中,dij为样本点i和样本点j之间的“距离”度量,并且满足三角不等式;dc是常数参数,定义为截止距离,其物理意义是控制样本点的影响最远距离。式(6)中函数R(x)的定义如式(7):

其中,ρi表示距离i的距离小于dc的样本点数量。i的参数δi计算如下:

其中,max(ρ)为点集S的最大局部密度。从式(8)可以看出,对于非最大局部密度样本点,δi定义为样本点i距离其他任意更高局部密度样本点的最小距离;而对于最大局部密度样本点,δi定义为其他点到此点的最大距离。
通过对点集S中的样本经行二维空间的处理,以 ρi和δi两个指标对点集降维处理。其中,ρi用来限制点集在多维测度空间内的局部密度,而δi用来度量局部密度较大的多维点集在测度空间内的相对聚类。距离其他高局部密度较“远”的点,称为在决策图上的“孤点”。“孤点”的个数即是聚类的估计类数。在局部密度的估计中,截止距离dc的选择非常重要,其影响了局部密度测度空间的边界。对于dc的选择准则,还需要进一步的理论分析,但是多次实验证明,dc的选择需要保证局部密度的最小取值不小于点集总数的1%~2%。
3 实验结果与分析
对于2.2中所采样的同样的数据数据集合,使用2中介绍的基于局部密度估计的方法,计算点集中每个样本的ρi和δi两个指标,绘出决策图如图3所示。
从图3可以看出,在ρi和δi两个指标都很“突出”的区域有4个明显的“孤”点。所以,估计算法确定出的聚类数目为k=4。对于2.2节的结论,两者的结论是一致的。通过对多组数据的实验,该文所提出的算法估计出的聚类类数和Sil指标、DBI指标和CH指标的一致率分别是99.4%、99.1%和98.8%。

图3 基于局部密度估计的决策图
4 结论
从K-均值算法对于聚类个数和初始中心敏感的缺陷出发,基于聚类中心具有高密度且距高局部密度聚类中心具有较远距离的特点,提出一种基于局部密度估计的聚类个数的估计方法。经过仿真实验,验证了该算法具有良好的有效性和鲁棒性。
Cluster Number Estimation Based on Local Density Estimator
Long Zhangyong
(Nanjing Institute of Railway Technology,Nanjing Jiangsu 210031)
With the development of artificial intelligence and data mining technology,cluster analysis has been widely used in many fields,which range from communication to bioinformatics,bibliometrics,and image processing.For unsupervised clustering analysis,the number of clusters is the key factor to determine the quality of clustering.Usually the number of clusters can not be determined in advance,then the initial cluster center is easy to make that the clustering result is not stable.For this,based on the characteristic that the cluster centers have a high local density and a relatively large distance from the high local density clustering center,a new method for estimating the number of clusters based on local density estimation was proposed.The simulation showed that the proposed algorithm performance was effective and robust.
cluster number;density peaks estimator;cluster validation;cluster analysis
TP18
A
1003-5168(2016)05-0026-03
2016-04-18
中国职教学会轨道交通专业委员会科研基金(201419);全国教育信息技术研究十二五规划课题(136231366)。
龙章勇(1979-),男,硕士,讲师,研究方向:无线通信技术。
[1]Kaufman L,P J Rousseeuw.Finding Groups in Data:An Introduction to Cluster Analysis[M].Hoboken,NJ:John Wiley&Sons,Inc.,1990.
猜你喜欢
廊坊师范学院学报(自然科学版)(2022年3期)2022-10-11 04:32:06
北京航空航天大学学报(2022年8期)2022-08-31 08:58:24
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
科技视界(2021年4期)2021-04-13 06:03:56
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
