
LDA模型在网络视频推荐中的应用*
2016-09-26 08:27卢盛祺韩景倜
网络安全与数据管理 2016年11期
卢盛祺,管 连,金 敏,韩景倜
(1.上海财经大学 信息管理与工程学院,上海 200433;2.上海财经大学上海市金融信息技术重点实验室,上海 200433;3.复旦大学 软件学院,上海 200433;4.国际商业机器(中国)有限公司,北京 100101)
LDA模型在网络视频推荐中的应用*
卢盛祺1,2,3,管连4,金敏3,韩景倜1,2
(1.上海财经大学 信息管理与工程学院,上海 200433;2.上海财经大学上海市金融信息技术重点实验室,上海 200433;3.复旦大学 软件学院,上海 200433;4.国际商业机器(中国)有限公司,北京 100101)
视频推荐系统最主要的功能就是从用户的历史行为中发现用户兴趣偏好,然后找出其可能感兴趣的视频并展示给用户。该文针对用户的视频选择过多、视频转化率较低等问题,提出了一种基于LDA模型的电影推荐方法。首先将视频的评论文本集转化为评论-主题-词语的三层贝叶斯模型,提取每个视频的评论关键词,再基于目标用户的历史行为发现其偏好的视频关键词集合,最后利用杰卡德相似系数,预测用户可能感兴趣的视频,以实现基于内容的个性化视频推荐服务。实验表明,该方法可以提高视频推荐的精度,使得视频转化率得到较好的提升。
LDA模型;用户偏好;视频推荐;电子推荐;贝叶斯模型
引用格式:卢盛祺,管连,金敏,等. LDA模型在网络视频推荐中的应用[J].微型机与应用,2016,35(11):74-79.
0 引言
随着互联网的快速发展和网民数量的迅速上升,人们正处在信息过载的时代。尤其在网络视频领域,各种视频数据正在以惊人的速度增长。例如,YouTube视频分享网站目前已经拥有超过1.5×108个视频[1],国内的专业视频网站优酷土豆、腾讯视频、搜狐、爱奇艺等,视频播放量和浏览次数也每日剧增。面对海量的视频信息,用户很难找到自己感兴趣的内容,而视频提供商又迫切地需要将优质的视频准确地推送给用户,以提高视频转化率和用户停留时间。推荐系统被认为是行之有效的方法,其可以建立用户与用户、用户与视频之间的关系,因而成为近几年来视频领域的研究热点。
目前在视频网站中使用的推荐方法主要有相关性推荐和个性化推荐两大类,相关性推荐就是把用户正在观看或浏览的相关视频推荐给用户,个性化推荐是根据用户的历史行为推断用户的兴趣爱好,并以此推荐用户可能感兴趣的视频列表。在90年代中期,美国人工智能协会春季会议(AAAI)、ACM智能用户接口会议(ACMIUI)、国际人工智能联合大会(IJCAI)等国际会议上发表了多篇有关个性化推荐系统的论文[2],此后,推荐系统在电子商务、网络视频等领域得到深入研究。例如,在2006年,美国著名的电影租赁公司Netflix就推出了关于推荐系统研究的比赛,在2005~2009年间,更多的推荐算法[3-6]被提出,并取得令人瞩目的研究成果。从视频推荐的研究技术上看,目前主流的视频推荐方法有基于协同过滤的推荐和基于内容的推荐。协同过滤推荐[7]的核心思想是通过发现具有相似喜好的用户群体,或评分相似的视频集合,将用户可能感兴趣的视频推荐给用户。例如,美国视频网站YouTube,由于其视频内容繁多、视频标签不规则、存储周期不确定等原因,采用的就是最简单的协同过滤算法。参考文献[8]详细介绍了YouTube推荐算法的实现。参考文献[9]提出使用基于群组内其他用户信息预测用户兴趣点的方法;参考文献[10]采用基于社会化网络的视频推荐方法,认为社交网络中的好友也应该具有相似的视频偏好。参考文献[11]将不同源网站针对某部电影的相关推荐聚合起来,结合语义知识从中按照相似度高低进行推荐。基于内容的推荐[12]核心思想是通过分析用户历史行为来获取用户兴趣特征,然后推荐与用户偏好视频内容相似的视频。比如网站Jinni定义了描述电影基因的900多个标签(类型、剧情、评分等),然后人工标注每部电影的这些标签,最后根据专家标注的向量空间做出推荐。此外,PARK J等人提出基于视频关键词的个性化推荐方法[13],YANG B等人提出线性组合描述视频相关性的方法[14]。
人工标注电影标签耗时又耗力,在实际应用中无法大规模应用;基于关键词的视频特征描述是可行的方法,最常用的关键词提取方法是TF-IDF,该方法是一种基于词频的统计方法,但是局限于字面匹配,缺乏语义理解。LDA(Latent Dirichlet Allocation)则是近些年兴起的比较热门的文本挖掘技术,主要用于文本语义层面的分析处理,由BLEI D M等人在 2003 年提出[15],用来发现大规模文档的主题分布情况。目前,该技术在视频推荐领域也得到良好的应用。例如,美国的视频网站Hulu,搭建了Hadoop集群来处理用户兴趣行为,包括观看、搜索、评论以及用户对推荐系统的反馈行为等,其推荐引擎的离线部分,用于计算一系列的关联矩阵,例如视频之间的两两相似度、视频主题与视频之间的关联等,其使用的关键技术之一就是LDA模型。
本文基于LDA模型,研究其在电影推荐系统中的应用。以视频的用户评论为数据基础,识别出每个视频的影评关键词序列,再结合目标用户的历史行为视频列表,建立用户兴趣模型,最后利用杰卡德相似系数(Jaccard Similarity)方法[16],发现影评内容相关的视频列表,为用户提供相关性视频和个性化的视频推荐服务。
1 基于LDA模型的网络视频推荐
1.1影评数据预处理
基于LDA模型的网络视频推荐中,用户历史行为包括视频观看、视频下载和视频收藏等。这些视频列表可以看作为该用户的偏好视频集合,集合中每个视频对应一个影评数据集。在对影评数据集进行LDA建模前,需对每个数据集进行中文分词、词性标注、新词识别、停用词过滤等预处理操作,以降低文本空间的维度,提高LDA建模效率。
一般的中文分词方法有正向最大匹配法、逆向最大匹配法和双向最大匹配法,其主要原理就是将文本划分为单字或单词串,再与词库进行匹配,直至划分成功。本文对中科院的NLPIR分词系统[17]进行二次开发,实现对影评数据集的中文分词和词性标注。每个词都指派合适的词性,标注格式表示为名词(/n)、动词(/v)、形容词(/a)、数词(/m)、量词(/q)、副词(/d)、标点符号(/w)等。
在分词过程中,系统还需识别新词,这些词是字典中未收录过的词语。比如在句子“力挺赵又廷”中,“赵又廷”是个词, 如果要计算机识别,最终结果可能是划分成3个单独的字。目前,新词识别是评价分词效果的重要指标之一,解决这个问题的简单方法是创建用户词典。本文创建的典型用户词典有影视明星词典、影视名称词典、影视流行语词典等,创建方式主要是从网络词库载入,或手动输入添加。
分词后的评论文本中,包含大量的无用词,比如代词、方位词、介词、限定词、 助词、叹词、连词、拟声词等,这些字或词没有特别的含义,不仅对主题发现的语义层面的分析没有太大帮助,而且还会降低 LDA 建模的效率,因此需要将这些词过滤掉。本文首先根据词性将代词、介词、连词等过滤掉,再导入停用词表对评论文本进行二次过滤,以提高分词效果。
1.2影评LDA建模过程
本文利用MCMC方法中的Gibbs Sampling算法对每部电影的用户评论数据集进行参数估计,也就是估计文本集的影评-主题概率分布Θ和主题-词项概率分布Φ。LDA模型是一个文档、主题、单词三层的贝叶斯模型,应用到视频推荐系统中,可转化为影评集、影评潜在主题、影评词项三层用户评论模型,其矩阵模型图如1所示。

图1 基于LDA模型的视频用户兴趣模型的矩阵示意图
其中,D表示一部电影用户评论集合,dm是第m条影评;Θ表示每条影评的主题分布,zk是第k个隐含主题;Φ表示每个主题在所有词项上的概率分布,wn是第n个词项。分词后的影评数据集,对应矩阵图中的文本集D,算法的目标就是估计模型中后两个矩阵的参数分布。
Gibbs Sampling算法就是每次选取概率向量的一个维度,通过给定其他维度的变量值来采样当前维度的值,不断迭代该运行过程,直到待估计的参数收敛[18]。其计算公式如下:

(1)

在视频推荐系统中,影评数据集的LDA训练过程为:
(1)对影评数据集中每条影评中的每个词语w,随机分配一个主题编号z(该z是隐含变量,即每个单词所对应的语义是未知的);
(2)重新扫描影评数据集,对集合中的每个词项w,按照Gibbs Sampling公式,重新采样词语w的主题z,并在集合中进行更新;
(3)重复上述影评数据集的重新采样过程,直至Gibbs Sampling收敛,即每条评论下的主题分布和每个主题下的词项分布收敛;
(4)统计影评数据集的主题-词项和影评-主题的共现频率矩阵,该矩阵就是LDA的生成模型。
上述LDA模型的训练,预设参数有α和β,一般β取默认值 0.01,α等于50/K,K为影评数据集的主题数目[19]。本文采用perplexity(困惑度)来确定最佳主题数量,即设定不同的K值,对影评数据集进行LDA模型的训练,直至模型的困惑度尽量低[20]。困惑度计算公式如下:
(2)
上式中,D为某视频的影评数据集,dm={w1,w2,w3,…,wNn}表示第m条用户评论,一条评论看成一篇文档,N为数据集中的评论文档个数,Nm为评论文档d中词语的个数,P(dm)为评论文档dm相似性,dm的似然值为:
(3)
其中n(wn,d)为文档d中词w出现的次数。
1.3影评关键词提取
视频推荐系统的一个首要任务是根据用户历史行为发现用户的兴趣偏好,也就是从用户偏好的视频列表中,提取每部视频的影评数据集的关键词,其提取过程依赖LDA生成模型的两个重要分布:影评-主题概率分布Θ和主题-词项概率分布Φ。词语的重要度由主题生成该词语的概率和该主题在影评数据集中的重要度共同决定[21]。
首先,基于影评-主题分布计算影评数据集中每个主题的重要度。该分布是每行一条用户评论、每列一个隐含主题的概率矩阵。其计算公式为:
(4)
其中,N为影评数据集用户评论的个数,T为文档集中主题的个数,dn表示第n条用户评论,zi表示第i个主题。
然后,基于主题-词项分布计算影评数据集合中每个词语的重要度。该分布是每行一个主题,每列一个词语的分布,表示了每个词语在不同主题上的概率值,其计算公式为:
(5)
其中,T为主题个数,P(w|zi)为词语w在主题zi上的概率值,而 P(zi|D)表示zi在影评数据集D中主题的重要度。
最后,将词语按词语重要度从大到小排序,取权重较大的前i个词语作为该视频的影评关键词集合{kw1,kw2,kw3,…,kwi},其中kwi表示该视频的第i个关键词。
1.4个性化视频推荐
视频推荐系统的最终目的是根据用户的兴趣偏好进行个性化的视频推荐,也就是根据目标用户偏好的视频集合,将影评主题相似的视频推荐给该用户。本文利用杰卡德相似系数(Jaccard Similarity)方法,衡量两部视频间的相似度,实质是计算两个视频的影评关键词集合的相似度,系数越大,说明这两部视频的内容越相似。电影的关键词集合可以表示为U{a1,a2,a3,…,ai},其中ai表示该电影的第i个关键词。
本文个性化视频推荐的主要流程为:
(1)从用户偏好视频列表中取出一部视频,其影评关键词集合为U。
(2)从待匹配视频列表中取出一部视频,其影评关键词集合为V;使用 Jaccard Similarity方法计算这两部视频影评之间的相似度,即集合U和V的交集元素在U和V的并集中所占的比例,用符号Jr(U,V)表示:
(6)
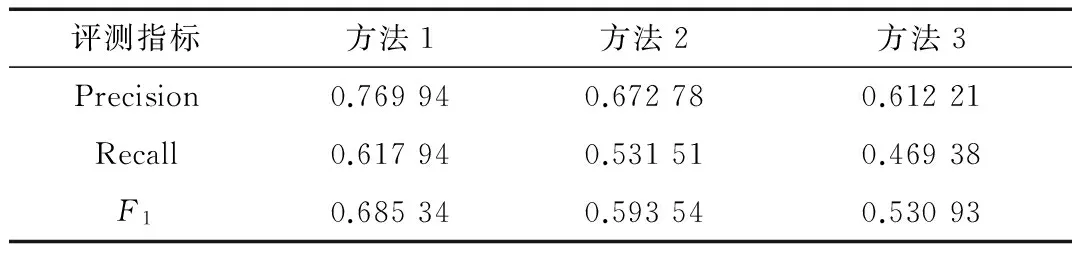
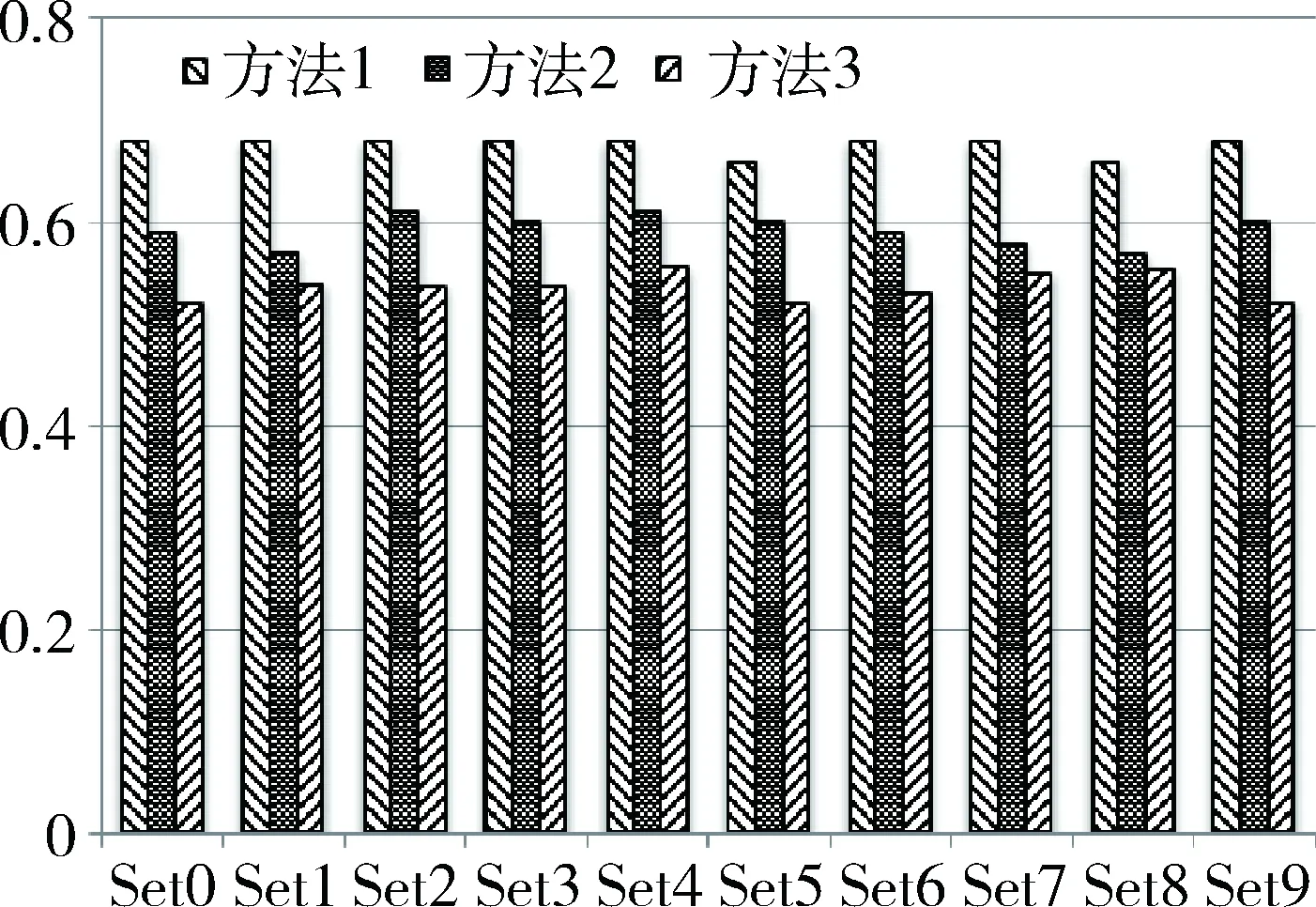
(3)计算这两部视频的类型之间的相似度,假设这两部视频的类型集合分别为A和B,同样利用JaccardSimilarity方法计算类型相似度,记作Jt(A, B)。为影评相似度Jr和类型相似度Jt分配权衡因子p(0 J=p×Jr(A,B)+(1-p)×Jt(A,B) (7) 其中,p的取值要通过反复试验和专家评审最终确定,初始化为0.1。计算视频间的相似度J,每次以0.1为单位在定义域范围内递增赋值,重新计算视频间的相似度。再根据不同p值下的视频相似度系数,由专家指定最佳p值。一般视频类型有“动作”、“爱情”、“魔幻”、“剧情”等。之所以添加这一特征项,是考虑到如果同时有多部电影与目标电影的相似度系数接近,那么同一类型的视频应该优先被推荐。 (4)从待匹配视频列表中取出下一部视频,按照上述步骤(2)和(3),计算新取的视频与目标视频的相似度,直至待匹配视频列表为空。 (5)从用户偏好视频列表中取出下一部视频,重复上述步骤(2)、(3)、(4),分别计算待匹配列表L中每部视频与该视频的相似度,直至用户偏好视频列表为空。 图2 用户偏好视频列表M与待匹配视频列表L之间的相似度矩阵 (6)至此,已经建立了用户偏好视频列表与待匹配视频列表的影评相似度矩阵,如图2所示,其中,用户偏好视频列表为M,待匹配视频列表为L。假设个性化推荐列表为G,其格式为G{视频ID:相似度系数},系统根据视频间的相似度矩阵,为M中的每个视频从L中提取相似系数较大的前n个视频,添加到G中生成该用户的个性化视频推荐列表,如果待添加的视频在G中已经存在,但相似系数较大,则在G中更新该视频的相似系数;否则,添加下一部匹配的视频,即: (8) 其中,f(i)=Ji,k-Ji,t,Ji,k表示L中第i个视频与M中第k个视频的相似度,Ji,t表示L中第i个视频与M中第t个视频的相似度。在个性化推荐列表最终生成后,还需按照相似系数从大到小对视频进行排序,排序后的格式为{ID1:J1,ID2:J2,…,IDi:Ji},J1>J2>J3>…>Ji,系统选取相似系数较大的前n个视频推荐给用户,完成个性化视频推荐服务。 2.1实验基本流程 从某专业视频网站中随机选取500名活跃用户,每个用户的历史行为记录中平均包含100部左右的电影,实验将每个用户的偏好视频列表分为两个部分:60%的视频作为训练集,用来训练最佳LDA主题模型,发现用户的兴趣偏好特征(影评关键词的提取),并使用JaccardSimilarity方法推导用户可能感兴趣的视频集合;40%的视频作为测试集,用于评估和检测本文提出的推荐系统的性能。图3显示的是训练集中部分用户的历史行为数据。 图3 视频网站部分用户偏好电影列表 实验数据准备好后,按照本文介绍的视频推荐方法分别对这500个用户的训练集中用户偏好视频的影评数据集合进行分析处理,生成个性化视频推荐列表。步骤如下: (1)提取训练集视频列表中每个视频的影评内容,包含电影ID、用户ID、评论文本、用户评分、评论时间等,提取每部电影的所有评论数据,一条评论看作一篇文档,n条评论构成该视频的一个影评数据集。然后对每个数据集分别进行中文分词、词性标注、新词识别、停用词过滤等预处理操作,将数据集的噪音降到最低,并转化为标准的LDA词袋矩阵(如图1中的D)。 (3)根据每个影评数据集的LDA生成模型中的影评-主题概率分布Θ和主题-词项概率分布Φ,利用式(4)计算各个隐含主题的重要性,图4是某个影评数据集的LDA生成模型中的部分主题概率分布图;然后利用词语重要性计算公式(5),提取影评数据集的关键词,记作Vi{t1,t2,t3,…},Vi表示第i部视频的关键词集合。 (4)对于每个目标用户,其视频偏好列表中每个视频的关键词集合为{V1,V2,…,Vi,…,Vj},每个集合中大概包含50个关键词,偏好视频数目平均为60个,所有偏好视频的关键词集合构成了该目标用户的兴趣偏好特征集合,利用Jaccard Similarity方法,建立待推荐视频与偏好视频的相似度矩阵。实验训练集中共有3 480部视频,除去目标用户的偏好视频列表M(大约60部),将剩下的3 420多部视频表示为待匹配视频列表L,该列表中的每一部视频有其自身的影评关键词序列,利用式(6)和(7)分别计算L中每个视频与M中偏好视频的相似度,建立相似度矩阵,其中,权衡因子p取值0.7(实验过程中发现,该值的权衡效果最好)。 (5)根据相似度矩阵,利用式(8)从待匹配视频列表L中选取相关性系数较高的视频,添加到匹配视频列表G,并不断更新G中每部视频的权值直至列表完全生成,再从大到小按序将前30部电影推荐给该目标用户,完成个性化视频推荐服务。 2.2实验结果评测 判断一个推荐系统的质量和性能,常用的评测指标有:准确度、覆盖率、召回率、多样性、新颖性、惊喜度等[22],本文从准确率和召回率两个角度评测本文推荐算法的性能。 (1)准确率和召回率 准确度Precision用于度量一个推荐系统预测用户行为的能力,描述的是推荐视频列表中正确视频的条数与推荐列表条数的比值。召回率Recall描述的是推荐视频列表中正确视频的条数与测试集视频列表条数的比值,衡量的是查全率。F1是Precision和Recall的加权调和平均,用于综合反映整体指标。 (2)实验结果分析 为了说明本文推荐算法的性能特点,实验中每次随机选取10个用户作为1组,共生成10个分组,然后分别使用本文的推荐方法(方法1)、基于item的协同过滤方法(方法2)、基于user的协同过滤方法(方法3),生成视频推荐列表,然后分别对实验结果进行评估,以证明本文推荐算法的良好应用效果。方法2和方法3都是以评分为数据基础,前者参照的是该用户对与某视频相似的多个视频的已有评分值,后者参照的是与该用户相似的多个用户对某视频的已有评分值。表1所示为3种推荐方法在10个用户分组上的平均准确率、召回率和F1值。 表1 3种推荐方法在10个用户分组上的平均 图5分别显示了3种推荐方法在不同用户分组上的准确率和召回率分布情况,图6显示了3种推荐方法在不同用户分组上的F1值分布情况。 图5 不同推荐方法在用户分组上的准确率和召回率分布情况 图6 不同推荐方法在用户分组上的F1值分布情况 从评测结果中可以发现,不管在准确率还是召回率上,本文的推荐算法都要优于基于user的协同过滤算法和基于item的协同过滤算法,其主要原因在于:(1)基于user的协同过滤方法考虑的是用户间的相似度,但在实际的项目应用过程中,用户间的相似性会受到多种因素的影响,具有极大的不稳定性和不可靠性;而基于item的协同过滤算法中视频相似度的计算,仅仅依靠用户对视频的打分情况来判断,并不能取得很好的效果,还可能导致推荐视频并不是目标用户所感兴趣的,反而降低用户体验。(2)基于内容的视频推荐方法的实质是计算两个视频之间内容或主题上的相似度,为用户推荐主题相关的视频,这种方法具有稳定性和确定性,极大地提高了推荐视频的用户观看转化率。但是,这种方法存在无法为用户推荐从未涉及过的领域,即冷启动的缺点,这也是本课题今后研究的重点。 本文应用LDA语义分析过程,首先对视频系统中每部电影的影评数据集进行关键词提取,然后基于用户历史行为,构建偏好视频的所有关键词集合,最后利用杰卡德相似系数,将影评主题相关的视频推荐给目标用户。实验证明,本文的推荐方法是行之有效的,而且极大地提高了推荐精度。 在网络视频这个开放性的平台,用户历史行为是推荐系统的重要依据之一,但是并非所有历史记录中的电影都是用户喜欢的,还需要根据观看时长、评论文本情感倾向等多方面判断用户真正偏好的视频。此外,用户的兴趣爱好具有阶段性,不同的时间点可能偏向不同类型的视频;社会化网络的发展,使得用户的兴趣爱好还可能会受到朋友圈的影响;用户对于系统推荐的视频,所表现出的在线反馈行为等,这些问题都是本文下一步的研究重点。 [1] SKRISHNAPP, D K, ZINK M, Griwodz C. Cache-centric video recommendation: an approach to improve the efficiency of YouTube caches[C]. In Proceedings of the 4th ACM Multimedia Systems Conference, 2013: 261-270. [2] McSHERRY F, MIRONOV I. Differentially private recommender systems: building privacy into the net[C].In Proceeding of the 15th ACM SIGKDD Dnternational Conference on Knowledge Discovery and Data Mining, 2009: 627-636. [3] LEMIRE D, MACLACHLAN A. Slope one predictors for online rating-based collaborative filtering[C]. In SIAM Data Mining, 2005: 1-5. [4] BELL R, KOREN Y, VOLINSKY C. Modeling relationships at multiple scales to improve accuracy of large recommender systems[C]. In Proceeding of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2007: 95-104. [5] BELL R M, KOREN Y. Scalable collaborative filtering with jointly derived neighborhood interpolation weights[C]. In Proceedings of the 2007 Seventh IEEE International Conference on Data Mining, 2007: 43-52. [7] LINDEN G,SMITH B,YORK J. Amazon.com recommendations: item-to-item collaborative filtering[J]. Internet Computing, IEEE, 2003, 7(1): 76-80. [8] DAVIDSON J, LIEBALD B, LIU J, et al. The YouTube video recommendation system[C]. Proceedings of the Fourth ACM Conference on Recommender Systems, 2010: 293-296. [9] SU C R, LI Y W, ZHANG R Z, et al. An adaptive video program recommender based on group user profiles[M]. Berlin, Heidelberg: Springer, 2013: 499-509. [10] DIAS A S, WIVES L K. POI enhanced video recommender system using collaboration and social networks[C]. Proceedings of the 8th International Conference on Web Information Systems and Technologies, 2012: 717-722. [11] 周文乐,朱明,陈天昊. 一种基于网站聚合和语义知识的电影推荐方法[J]. 计算机工程,2014, 40(8):277-281. [12] PAZZANI M J. A framework for collaborative, content-based and demographic filtering[J]. Artificial Intelligence Review, 1999, 13(5-6): 393-408. [13] PARK J, LEE S J, LEE S J, et al. Online video recommendation through tag-cloud aggregation[J]. Multimedia IEEE, 2011, 18(1):78 - 87. [14] YANG B, MEI T, HUA X S, et al. Online video recommendation based on multimodal fusion and relevance feedback[C]. Proceedings of the 6th ACM International Conference on Image and Video Retrieval, 2007: 73-80. [15] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003,3(7): 993-1022. [16] Wikipedia. Jaccard similarity[EB/OL].[2016-02-14].http://en.wikipedia.org/wiki/Jaccard_index. [17] ICTCLAS2016. Natural language development platform [EB/OL].[2016-02-14].http://ictclas.nlpir.org/. [18]HAN X, STIBOR T. Efficient collapsed gibbs sampling for latent dirichlet allocation[C]. ACML, 2010: 63-78. [19] STEYVERS M, GRIFFITHS T. Probabilistic topic models[J]. Handbook of Latent Semantic Analysis, 2007, 427(7): 424-440. [20] CAO J, XIA T, LI J, et al. A density-based method for adaptive LDA model selection[J]. Neuro Computing, 2009, 72(7): 1775-1781. [21]ARORA R, RAVINDRAN B. Latent dirichlet allocation and singular value decomposition based multi-document summarization[C]. Proceedings of Eighth IEEE International Conference on Data Mining, 2008: 713-718. [22] RESNICK P, VARIAN H R. Recommender systems[J]. Communications of the ACM, 1997, 40(3): 56-58. The application of LDA in online video recommendation Lu Shengqi1,2,3,Guan Lian4,Jin Min3,Han Jingti1,2 (1.School of Information Management and Engineering, Shanghai University of Finance and Economics, Shanghai 200433, China; 2.Shanghai Key Laboratory of Financial Information Technology, Shanghai University of Finance and Economics, Shanghai 200433, China; 3.Software School, Fudan University, Shanghai 200433, China; 4.International Business Machine China Co., Ltd., Beijing 100101, China) Video recommendation system is used to develop user preferences based on their activity on the site, and generate personalized sets of videos to audiences. This paper presents an online movie recommendation method based on Latent Dirichlet Allocation Model, owing to excessive choices of users and lower conversion rates of videos. By simply merging video reviews, and formulating a review-topic-word Bayesian model, keywords of each video can be extracted. Then constructing user preferences from history behaviors, and predicting relevant sets of videos to targeted users by Jaccard Similarity, the personalized video recommendation of content-based is implemented finally. Experiments show that the proposed method can achieve higher accuracy and video conversion rate in personalized recommendation program, comparing with traditional collaborative filtering. Latent Dirichlet Allocation; user preferences; video recommendation; e-recommendation; Bayes model 国家自然科学基金(71271126);教育部博士点专项科研基金(20120078110002) TP311 A 10.19358/j.issn.1674- 7720.2016.11.023 2016-02-14) 卢盛祺(1978-),男,博士研究生,主要研究方向:数据挖掘、电子推荐。
2 实验设计与结果评测

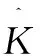

3 结束语
猜你喜欢
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
商用汽车(2016年11期)2016-12-19
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
Coco薇(2016年2期)2016-03-22
中学生数理化·中考版(2015年10期)2015-09-10
Coco薇(2015年1期)2015-08-13
小雪花·成长指南(2015年7期)2015-08-11
小雪花·成长指南(2015年4期)2015-05-19
