
基于类别条件的受限玻尔兹曼机改进设计
2016-09-10 08:23:41贺鹏程
计算机与数字工程 2016年8期
贺鹏程
(海军装备部驻重庆地区军事代表局 重庆 400042)
基于类别条件的受限玻尔兹曼机改进设计
贺鹏程
(海军装备部驻重庆地区军事代表局重庆400042)
针对受限玻尔兹曼机(RBM)在进行无监督训练时易出现特征同质化导致泛化能力较差的问题,设计了将类别条件引入RBM训练中,从而提出了基于类别条件的RBM(lCRBM)。针对RBM的训练,将类别信息作为模型隐单元训练条件,参与到隐单元后验激活概率计算中;并将该模型作为深度玻尔兹曼机(DBM)的底层结构,应用于深度学习中。通过手写数字识别集合测试,该模型在训练速度和特征提取有效性上均有较大改善,并且能够提高深度模型的特征学习能力。
受限玻尔兹曼机; 深度学习; 监督学习; 对比散度
Class NumberTP393
1 引言
作为人工神经网络的一种结构,基于能量模型的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[1]具有网络形式简单、模型收敛速度快等优势。因此,RBM已经被广泛应用于文本聚类[2]、图像去噪[3]、手写数字识别[4]、语音识别[5]以及协同过滤[6]等机器学习问题,并在其基础上形成了新的领域——深度学习[7]。
但RBM的训练属于无监督学习的一种,存在模型训练单纯依靠无标签数据,易出现特征同质化,导致模型泛化能力较差的问题。因此,对RBM模型结构进行改进,将标签信息引入到RBM训练中,设计一种结合标签信息的RBM能够进一步加速模型训练,提高模型数据泛化能力。
文献[8]在RSM的基础增加了类别信息处理,并提出了基于监督的RSM-sRSM,但存在类别信息重构的问题,导致训练易发散。因此,本文以RBM为基础设计了基于类别条件的RBM(label Condition RBM,lCRBM),针对sRSM缺陷,通过将类别信息作为RBM训练参数更新条件,避免了类别信息需要重构的问题,并将其应用于深度学习模型中。实验结果表明,基于类别条件的RBM提取的特征对于分类效果更好,且训练效率也有所提高。
2 受限玻尔兹曼机及对比散度算法
2.1受限玻尔兹曼机
受限玻尔兹曼机是在玻尔兹曼机(Boltzmann Machine,BM)的基础上,通过限制BM中层内单元连接,使得在给定同单元状态下临近层单元激活概率条件独立,其结构如图1所示。作为无向图模型,RBM中的可见单元层V,表示观测数据;隐单元层H,表现为特征检测器,其结构如图1所示。
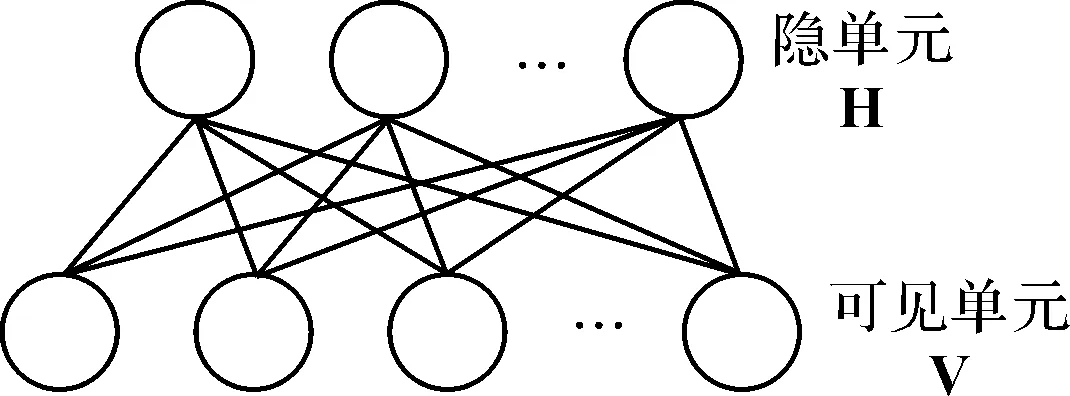
图1 RBM单元连接图
设定RBM模型的可见单元个数为N、隐单元个数为M,且所有单元均符合伯努利分布。在给定状态(v,h)下,RBM的能量定义如式(1)所示。
(1)
式中:vi代表第i个可见单元状态,hj为第j个隐单元状态,Wij代表可见单元i与隐单元j之间的连接权值,bi为可见单元i偏置,cj为隐单元j偏置。
鉴于RBM所有层间单元的激活状态为条件独立。则隐单元和可见单元的后验激活概率,如式(2~3)所示。
(2)
(3)
式中:σ(x)=1/(1+exp(-x))。
2.2对比散度算法
RBM的训练通过最大化数据似然概率实现,属于无监督训练。鉴于RBM训练时难以计算模型数据平均期望,因此文献[9]提出了对比散度(Contrastive Divergence,CD)算法,使用吉布斯采样值作为模型期望值。CD算法首先通过执行吉布斯块采样(block Gibbs Sampling)以各个训练数据作为初始状态,进行k次状态转移;然后将转移后的数据作为样本对RBM训练时Negative Phase的估算均值来实现参数更新。
实验证明,在应用中仅需要一次状态迭代就能保证模型的良好学习效果。则给定训练数据v(n)下,连接权值W.j的更新如式(4)所示。
ΔW.j=P(hj=1|v(n))·v(n)-P(hj=1|v(n)-1)·v(n)-
(4)
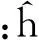
3 标签条件的受限玻尔兹曼机
3.1模型结构
不同于文献[8]中将类别信息作为额外的可见单元参与模型,本文所设计的lCRBM将标签单元作为RBM的条件单元。因此,lCRBM模型结构如图2所示。

图2 lCRBM单元连接图
从图2中可以看出,lCRBM共由三种单元组成,分别是可见单元V、隐单元H和类别条件单元L;同时隐单元层、可见单元层和类别条件层之间层与层互连接,且同层单元不连接;其中W代表隐单元层与可见单元层之间的连接权值,D代表隐单元层与类别条件层之间的连接权值。
则在给定各单元状态(v,h,l)下,lCRBM模型的能量定义如式(5)所示。
(5)
式中:l为类别条件单元,Dij为隐单元hj与类别条件单元li之间的连接权值,L为类别条件单元总数。
通过lCRBM模型的能量函数,能够推导出lCRBM中可见单元的后验激活概率,如式(6)所示。
(6)
同理,lCRBM中隐单元的后验激活概率如式(7)所示。
(7)
从式(7)可以看出,lCRBM中隐单元与式(3)不同之处在于,类别单元参与隐单元后验激活概率的计算,这也是lCRBM将类别信息引入到模型训练中,从而使训练具有类别针对性,弱化RBM无监督训练时易出现的特征同质化问题,进而提高数据拟合度的方法。
3.2训练方法
lCRBM的训练目标同样为最大化数据似然概率,因此可以借助CD算法实现模型训练。鉴于类别单元参与到隐单元后验激活概率计算中,因此lCRB的训练方法如下所示。
对于一条训练数据x=(x1,x2,x3,…,xn)和对应的类别数据l=(0,0,…,1,…,0)其中“1”值代表数据对应的类别。
设定:学习速率η,隐单元与可见单元之间的连接权值W,隐单元与类别单元之间的连接权值D,可见单元偏置b,隐单元偏置c。
1) 对于所有隐单元i,依据式(7)计算基于x和l的隐单元的后验激活概率Q(hi=1|v,l);
2) 依据Q(hi=1|v,l)采样隐单元状态h+i∈{0,1};
3) 对于所有的可见单元j,依据式(6)计算P(x-j=1|h+);
4) 依据可见单元后验概率P(x-j=1|h+)采样得到x-j∈{0,1};
5) 由X-和l计算Q(h-i=1|X-);
6) 更新权值:
W=W+η(H+X+-Q(H-=1|X-)X-)
b=b+η(X+-X-)
c=c+η(H+-H-)
D=D+η(lH+-lQ(H-=1|X-))
从lCRBM的训练方法可以看出,类别单元参与到模型训练中。作为模型提取的特征,隐单元在训练过程中从样本数据和对应的类别信息中学习到初始数据和类别数据的组合特征。
3.3深度模型实现
深度模型的构建通常采用的形式是将多个RBM进行叠加再通过BP算法对整个模型参数进行精调。因此,可以将lCRBM模型作为底层RBM,再通过叠加RBM组成新的深度模型。
类似于深度玻尔兹曼机(Deep Boltzmann Machine),构建深度模型lCDBM。以三层结构为例,lCDBM模型如图3所示。

图3 lCDBM单元连接图
4 MNIST实验结果及分析
为了验证所提出的lCRBM模型性能,选用MNIST手写数字识别集作为实验对象。MNIST手写数字识别集包含了0~9共10个手写数字图像,共有70000幅图像,大小均为28×28。
实验设置:为了分析lCRBM特征提取能力,设计了两个实验,分别测试lCRBM作为浅层模型时所提取的特征用于手写数字分类时的准确率和作为深度结构DBM底层模型时对深度特征提取能力的影响。
1) 实验1
实验1用于比较RBM与lCRBM提取特征的有效性。实验设置RBM中可见单元个数为784,隐单元个数为200,学习速率η=0.01,循环次数不超过500。在训练过程中,两种模型的重构误差如图4所示。

图4 两种RBM训练重构误差对比
从图4可以看出,lCRBM的重构误差下降速度要快于RBM,表明lCRBM对训练样本的学习速率较快。
经训练后,在完成手写字特征提取以后,选择LIBSVM[10]提供的径向基支持向量机(RBF-SVM)作为最终分类器,其中参数均采用默认设置。则采用RBM和lCRBM模型的隐单元值作为RBF-SVM的分类数据,得到的分类准确率如表1所示。
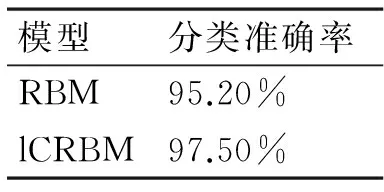
表1 MNIST手写数字分类准确率
从表1可以看出,由lCRBM提取的特征用于数字识别的分类准确率较好,约有2%的提升,符合之前对模型的分析,也可以看出将类别条件引入模型训练时对特征提取具有的优势和性能特点。
2) 实验2
实验2用于测试选用lCRBM作为深度模型的基础结构对提取特征的影响。因此设置了三层DBM作为实验结构,其中可见单元-第一隐单元-第二隐单元个数分别为784-500-300。实验的模型分别为lCRBM-DBM(以lCRBM为基础结构)和标准DBM(以标准RBM为基础),模型的训练方法按照文献[11]所述,并同样以RBF-SVM为分类器进行手写数字的识别,其分类准确率如表2所示。

表2 MNIST手写数字分类准确率
从表2可以看出,基于lCRBM的深度模型DBM分类准确率达到了99%,相比于标准DBM,有了较大提升,因此采用lCRBM作为深度模型的基础结构对于提高深度模型特征提取能力和促进模型对数据的泛化能力有较大帮助。
5 结语
本文构建出RBM的改进模型-lCRBM,实现了将类别信息引入到RBM训练中。相比于标准RBM,该模型能够较快地实现模型收敛和对训练数据的学习,并且由于类别信息的影响,使得所提取的特征对于分类也较为有效;与此同时,也研究了以lCRBM为基础的深度模型性能。实验结果表明,lCRBM对手写数字识别较为有效,并且将类别信息作为RBM训练条件的思想还可以应用到文本聚类、图像识别等领域。未来lCRBM的改进对于其他领域应用,也具有较好的指导作用。
[1] Hinton G E. A practical guide to training restricted Boltzmann machines[R]. Toronto: Machine Learning Group University of Toronto,2010:129-136.
[2] Srivastava N, Salakhutdinov R R. Multimodal learning with deep boltzmann machines[C]//Advances in Neural Information Processing Systems,2012:2222-2230.
[3] Tang Y, Salakhutdinov R, Hinton G. Robust boltzmann machines for recognition and denoising[C]//Computer Vision and Pattern Recognition, 2012 IEEE Conference on. IEEE,2012:2264-2271.
[4] Srivastava N, Salakhutdinov R R, Hinton G E. Modeling documents with deep boltzmann machines[C]//Proceedings of the 29th Conference on Uncertainty in Artificial Intelligence. Piscataway, NJ: IEEE,2013:222-227.
[5] Dahl G, Mohamed A, Hinton G E. Phone recognition with the mean-covariance restricted Boltzmann machine[C]//Advances in Neural Information Processing Systems,2010:469-477.
[6] Salakhutdinov R, Mnih A, Hinton G. Restricted Boltzmann machines for collaborative filtering[C]//Proceedings of the 24th International Conference on Machine Learning. ACM,2007:791-798.
[7] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation,2006,18(7):1527-1554.
[8] 刘凯,张立民,张建廷,等.基于监督的RSM改进研究[J].计算机工程与设计,2014,35(4):1429-1432.
LIU Kai, ZHANG Limin, ZHANG Jianting, et al. Improvement of RSM based on supervised learning[J]. Computer Engineering and Design,2014,35(4):1429-1432.
[9] Hinton G E. Training products of experts by minimizing contrastive divergence[J]. Neural Computation,2002,14(8):1771-1800.
[10] CHANG C C, LIN C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology,2011,2(3):27-33.
[11] Salakhutdinov R, Hinton G E. Deep boltzmann machines[C]//Proceedings of the 12th conference on Artificial Intelligence and Statistics. Brookline: Microtome Publishing,2009:448-455.
Improvement of RBM Based on Label Condition
HE Pengcheng
(Military Representative Bureau of Naval Equipment Department in Chongqing Area, Chongqing400042)
In order to overcome the poor generalization resulted by characteristic homogeneity for unsupervised training of restricted boltzmann machine, the label condition is introduced to the training of RBM to design a new model named label condition RBM. Training for RBM, the label information is treated as training condition for RBM and involved in the calculation of hidden units’ posterior probability. The model is applied in deep learning which designed as the underlying structure of deep Boltzmann machine. Through a collection of handwritten numeral recognition test, the model’s training speed and the effectiveness of feature extraction are greatly improved, and the characterized learning ability of deep learning model is also improved.
restricted Boltzmann machine, deep learning, supervised learning, contrastive divergence
2016年2月11日,
2016年3月21日
贺鹏程,男,硕士,工程师,研究方向:军事装备学。
TP393
10.3969/j.issn.1672-9722.2016.08.009
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10 21:55:57
四川师范大学学报(自然科学版)(2023年2期)2023-03-31 20:43:01
故事作文·低年级(2021年12期)2021-12-21 23:04:39
装备制造技术(2020年4期)2020-12-25 05:25:58
作文成功之路·小学版(2020年7期)2020-08-24 08:19:18
工程数学学报(2020年3期)2020-07-06 07:38:40
长治学院学报(2019年2期)2019-07-24 07:14:04
电子制作(2018年18期)2018-11-14 01:48:08
雷达学报(2017年6期)2017-03-26 07:53:04
邵阳学院学报(自然科学版)(2015年1期)2015-06-05 09:13:16
